# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

今年的智源大会,依然是星光熠熠,干货满满,依然是北京乃至全国AI发展的学术名片。
智源研究院也不负众望地发布了多项学术成果。
这场国内最顶尖、最硬核的年度「AI春晚」,已经成功举办了5届,成为AI圈最不容错过的顶级盛会。
过去几年,共有11位图灵奖得主,1000多位世界顶尖专家,跨越了30+国家和地区,前来参会。

2024年的智源大会,前沿学术浓度完全不输往届,大模型领域的先锋再次集结。
这次,不仅再次邀请到了图灵奖得主姚期智,还有OpenAI、Meta、DeepMind、斯坦福、UC Berkeley等国际明星机构与技术团队代表。

以及,国内主流大模型公司,包括百度、零一万物、百川智能、智谱AI在内的CEO与CTO。
一共汇聚了200+AI顶尖学者和产业专家。

接下来准备好,即将登场的是一场非常硬核、密度超标的学术盛宴。
目前的技术路径,是正确的吗?
现在普遍认为,人类大脑的参数在一百万亿到一千万亿之间,而如今大模型与人类大脑的参数的差距,已经从相差一百万倍变成了去年的一百倍。
如果照这个发展速度,未来几年大模型的参数很可能就会赶超人类大脑。
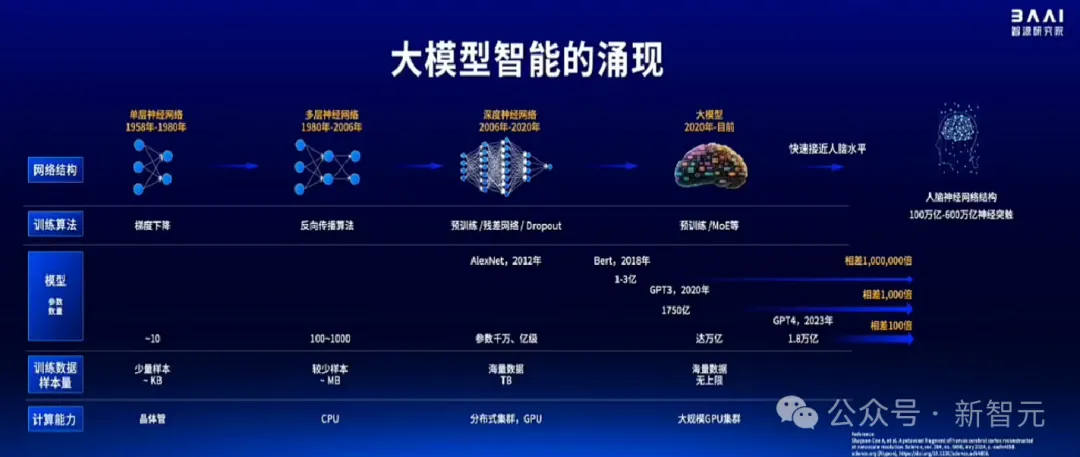
AGI时代,很可能就会在未来几年到来。
不过,我们最近正在走的,是一条正确的技术演化路径吗?
目前,学界已经就这方面提出了越来越多的质疑。
图灵奖得主LeCun曾多次表示,如今的LLM根本无法达到人类级别的AI,甚至连阿猫阿狗都不如。大模型仅具备语言能力且缺乏理解力,而一只家猫在通识和理解力上都要比LLM强太多。
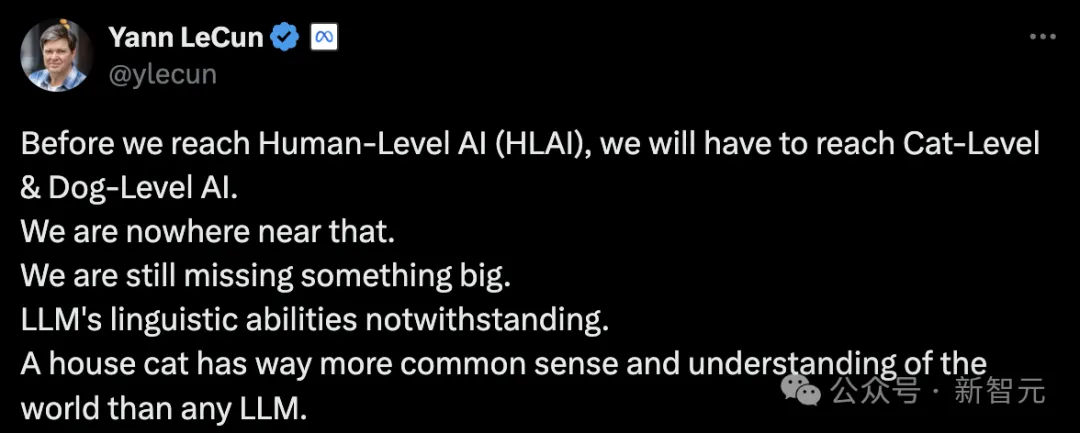
而且,他认为,LLM在通往人类级别AI的高速路上,只是一个出口。
具体而言,那些基于自回归预测下一个token的大模型,是AI发展路线图中的一个阶段,它们无法进行规划和推理。
不过,基于Transformer的自监督预训练模型,是实现这一最终目标的重要组成部分。
仅仅依靠Transformer预训练模型远远不够,还需要将其置于能够推理、规划,并学习底层「世界模型」体系之中,才能真正发挥作用。

的确,LLM的局限很明显——它依然是一种单模态的模型。然而除了文本数据之外,世界上还存在大量图像、视频、音频,数据量是文本的十倍、百倍乃至千倍。
对此,产业界也有针对多模态模型的研究,但这些研究的思路依然是针对不同模态,理解和生成也是分开的。
智源认为,从技术发展路径来看,我们最终会形成一种统一的多模态大模型。
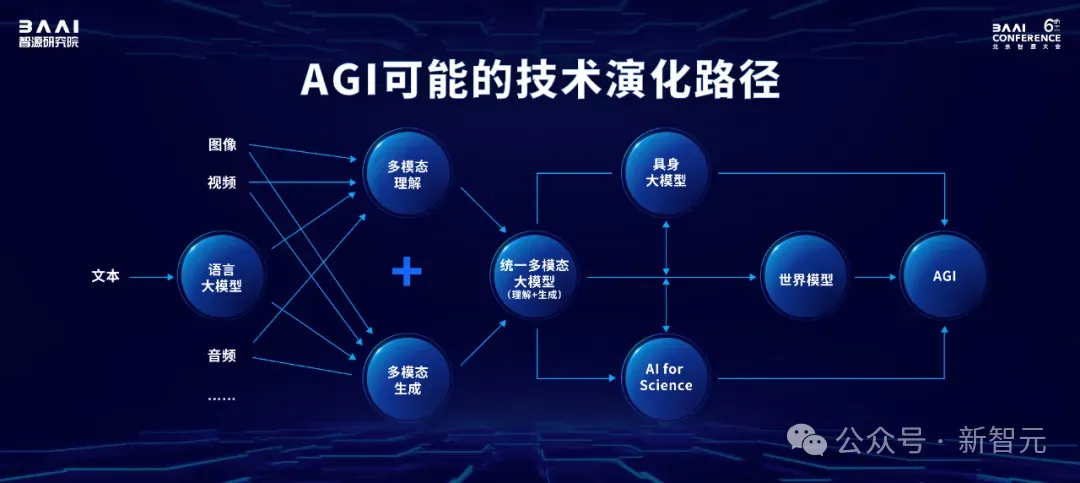
他们能将理解和生成统一,将不同的模态数据进行统一。
当多模态大模型能够理解和感知决策世界,就有可能进入到我们的物理世界。
如果进入物理世界跟硬件结合,这就是具身大模型的发展方向。
如果它进入到微观世界,去理解和生成生命分子,这就是AI for science。
而这些,都会最终推动人工智能向AGI方向发展。
大模型「全家桶」
基于这种技术路径判断的前提下,智源大模型全家桶应运而生。
具体包括语言大模型、多模态大模型、具身大模型、生物计算大模型,以及支撑这些大模型技术迭代的基座,即算力集群「操作系统」。
目前大语言模型训练中的一个核心关键痛点,就是算力消耗过高的问题。这也是目前所有公司共同面临的困境。
为此,智源研究院和中国电信人工智能研究院(TeleAI)基于模型生长和损失预测等关键技术,联合研发并推出全球首个低碳单体稠密万亿语言模型Tele-FLM-1T。
Tele-FLM-52B版本开源地址:https://huggingface.co/CofeAI/Tele-FLM
Tele-FLM-Chat试用(纯模型单轮对话版)地址:https://modelscope.cn/studios/FLM/ChatFLM
该模型与百亿级的52B版本,千亿级的102B版本共同构成Tele-FLM系列模型。
Tele-FLM系列模型实现了低碳生长,仅以业界普通训练方案9%的算力资源,基于112台A800服务器,用4个月完成3个模型总计2.3Ttokens的训练,成功训练出万亿稠密模型Tele-FLM-1T。
模型训练全程做到了零调整零重试,算力能效高且模型收敛性和稳定性好。
显然,在当前算力紧缺的大背景下,这个模型意义重大。
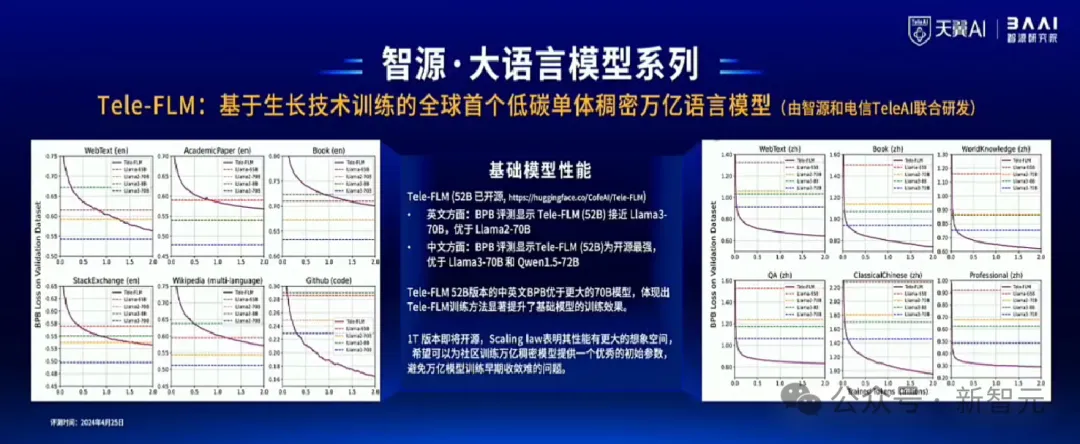
而评估结果也十分令人惊喜——
在基础模型的性能方面:BPB显示,英文能力上,Tele-FLM-52B接近Llama3-70B,优于Llama2-70B和Llama3-8B;中文能力上,Tele-FLM-52B为开源最强,优于Llama3-70B和Qwen1.5-72B。
在对话模型性能方面:AlignBench评测显示,Tele-FLM-Chat(52B)已经达到GPT-4中文语言能力的96%,总体能力达到GPT-4的80%。
目前,TeleFLM系列模型已经全面开源了52B版本,核心技术(生长技术、最优超参预测)、训练细节(loss曲线、最优超参、数据配比和Grad Norm等)均开源。
因此,对于开源社区和整个产业链,智源研究院都做出了重要贡献。
并且,Tele-FLM-1T版本也即将开源。
智源希望,可以为社区训练万亿稠密模型提供一个优秀的初始参数,避免万亿模型训练收敛难等问题。
而产业界人士,对于智源的BGE模型一定是耳熟能详。
BGE模型,是全球下载量最高的国产AI模型,也是最普及的开源向量模型。
团队基于创新性的监督预训练,和多阶段的对比学习,以及构建多语言关联文本的数据集cmtp,研发出了BGE模型。
它一经发布,就保持国际领先位置。因为又好用又是轻量级模型,它在开源社区广受好评,下载量持续攀升,还得到了Hugging face、LangChain等全球主流大模型应用框架的集成。
如今,多模态大模型依然处于持续的迭代和演进,技术路线还没有收敛。
而智源研究院在过去一年里,发布了多项引领整个开源社区的相关研究。
去年12月发布的Emu 2,截至目前依然是开源社区最大、性能最领先的生成式多模态大模型。
今年2月发布的EVA-CLIP-18B模型,依然是开源社区最大、性能领先的180亿参数视觉表征的CLIP模型,被用于许多多模态大模型中视觉编码器的部分。
虽然多模态大模型目前的发展现状非常火热, 但在智源看来,此多模态非彼多模态。
在行业里,各种模态的转换已经有了GPT-4V、DALL-E、Sora、GPT-4o等优秀模型。
然而以下这些问题,目前还没有答案。
在技术路线上来看,到底是使用diffusion model还是auto regressive?到底是单一的跨模态还是统一的多模态?理解和生成应该分开还是结合?是要组装式的多模态,还是原生的多模态?
智源的判断是,要坚定地走统一原生的多模态路线。
为此,就必须挑战整个行业里最难的技术路线。
如今,原生多模态「世界模型」Emu 3正在紧锣密鼓地正在训练中,
顾名思义,所谓「原生」,就是一开始就将多种模态融合,同时将生成和理解进行融合。
它统一了文字、图像、视频,使用自回归的技术路线,实现了图像、视频、文字的输入和输出,并且具备更多模态的可扩展性。
自回归的框架,让它能够进行持续的、可控的交互。
目前Emu3已经取得了一些进展。
比如,它已经具备了优秀的图像生成能力。
需要强调的是,它不是基于diffusion model,而是基于auto regressive自回归网络。

同样,它也能进行视频的生成,同样也是基于自回归网络。

从这些视频结果可以看出,Emu 3具备捕捉世界模型规律的能力。
而这个统一的多模态模型,甚至还具备对图像和视频的理解能力。
比如,模型会识别出左上角视频的主人公感到幸福和兴奋,而右上角的男人则显得很失望。
在左下角的图像中,如果提问最近的交通灯是什么颜色,它能够识别出红灯(即使图中红灯的信号非常微弱)。
它还能描述出,右下角的视频显示的是动态的天空中有很多云。

而以上我们看到的,都是同一个模型的结果。
虽然Emu3还在训练中,但智源已经开放了轻量级的图文多模态大模型Bunny。
它是一个基于灵活架构、能支持不同视觉编码器和不同语言基座的模型,模型本身以及训练代码,都全部开源。
此外,智源的更多视觉大模型的重要原创成果,都已经全部开源。
多模态大模型的出现,让计算机进一步感知和理解这个世界,更能化身为一个强大的智能体。
上个月,微软Build大会上官宣的Copilot+ PC,展示了AI助手在PC上自主完成任务的能力。
几天前,苹果在WWDC上发布的Apple Intelligence,同样让AI控制手机成为可能。
智源在过去的一年里,在这一领域,做出了一些突破性的成果。
团队研发的通用计算机控制的系统——Cradle,它可以操控一切软件,像人一样通过看屏幕,点击鼠标,完成计算机上的任务。
而且,Cradle还能进行自我反思,并对未来做出规划。
看得出,当一个Agent从数字世界,走向物理世界,便是「具身智能」。
基于具身智能是LLM技术路线重要发展节点的重要判断,智源在过去一年,也非常坚定在这一方向上持续投入。
具体来说,他们在机器人末端操作、具身大小脑、导航、硬件这些领域,全面开展研发。
这当中,也取得了一些亮眼成果。
首先是机器人抓取,称得上是每个机器人必备的「基操」。
以往泛化的抓取AI,在面对透明、反光的物体时,经常会任务失败。
对此,智源通过构建了一个大规模高质量的仿真系统,涵盖了千万量级场景,以及超过10亿的抓取数据,训出一个通用抓取模型。
值得一提的是,它能够在工业级真机中,能够实现超95%的成功率,创世界最高记录。
除了最基本的抓取能力之外,具身智能真正让人感到兴奋的是思考的能力。
这正是LLM的诞生,给机器人智能带来了全新的变化。
过去一年,智源研发了2个专模专用,各司其职的分级大模型系统:SAGE和Open6DOR。
其中,SAGE是一个可以反思,随机应变的操作大模型,基于3D视觉小模型+图文大模型打造,能够让其从失败反思,进一步规划尝试。
Open6DOR是一个全球首个开放指令6 DOF的取放大模型,而谷歌发布的RT大模型仅能实现3个自由度。
更多自由度,意味着能够实现更好的抓取能力。

因为机器人在抓取时,不仅需要考虑物体的「位置」,还需要考虑其「姿态」(比如横放,或树立等),才能变得实用。
当然了,机器人还应学会行走,因此,智源研发了一个面向技术终局形态的端到端具身导航大模型。
以往,机器人需要离线提前建好的地图,实现导航。但人类走路,完全是依靠视觉。
而具身导航大模型实现了纯视觉、纯Sim2Real的解决方案,也就是实现了「Video-Language in, Action out」。
下面这个机器人就是在虚拟世界中完成训练后,直接被投入智源大厦办公楼的真实场景中,进行泛化导航。
以上是智源在具身大模型方面的研究成果,若想让其真正实现落地,还需要机器人本体。
对此,智源与北京银河通用机器人公司开展合作,将具身大模型与其轮滑式机器人结合,推进在不同场景中落地。
在无人药店中,客户下单后,机器人可以去货架上,拿取正确的药物。
而在家庭服务的场景中,机器人还可以自动清理垃圾。
另外,机器人还需要思考。
比如,当告诉机器人「我渴了」。它会说,「好的,给你拿一瓶水」。

告诉它「我饿了」,它还会问你,「现在有香蕉橘子,你要哪个」?

这个机器人不仅能够基于用户指令去思考,还可以与用户交互,并且可以实现上述的泛化的抓取能力。
除了在无人药店、家庭场景外,智源的具身智能在医疗领域,也实现了重要的应用落地。
通过联合清华大学301医院,实现了全球首创的智能心脏超声机器人。
而且,在真人上,实现了全球首例的自主超声扫描。
在与301医院3位资深心脏超声医生的扫描结果进行对比,却发现,AI机器人在准确性、高效性上与人类医生基本持平。
但其稳定性、舒适性,显著高于人类医生。
更为重要的是,现在在全国,超声医生是非常缺乏的,患者看病排队经常排很久,智源AI机器人能够在提升医疗水平方面有着重要意义。
未来,具身智能依然面临诸多技术问题,还待解决。
智源研究院联手各大高校、企业,以及业内更多的生态合作伙伴,一起去推动具身智能的发展。
此外,智源研究院在生物计算大模型方面,也取得了诸多进展。
生成式AI已经推动了AI领域发展,当进入微观世界,我们是否可以用相似的技术,来解决生命分子的理解与生成的问题?
这便是,智源在研发生物计算大模型,进行的一个初步思考。
与此同时,它对于整个产业界意义重大。
在药物研发领域,存在一个「双十定律」,从新药研发到上市,通常需要耗费十年的时间,以及十亿美元的投入。
其中,30%-40%的时间和成本,大都用在了药物设计和临床阶段。
这便是AI可以发挥作用的地方,除了化合物筛选和预测之外,对于大分子结构建模预测,这也是AI在医疗领域可能会取得的突破。
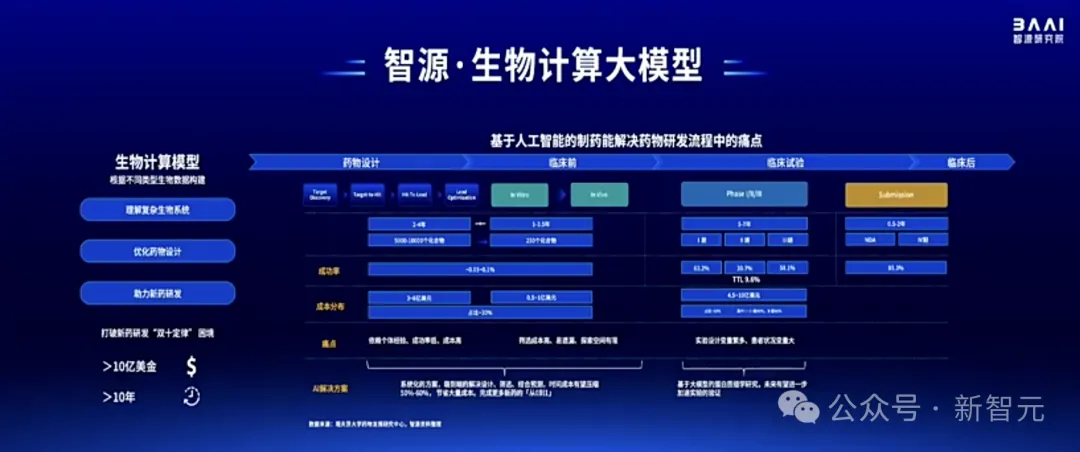
基于此,智源设计了一个OpenComplex 2全原子生物分子模型,是一个仅有「解码器」的模型。
具体研发规划是,通过构建统一的生物分子计算模型,打通像蛋白质、DNA、RNA小分子之间的壁垒,并且可以研究它们之间的关系。
OpenComplex 2在国际权威CAMEO榜单的评测中,连续26个月稳居第一。不论是精度,还是宏观结构方面,都优于同期模型,比如AlphaFold 2。
除了预测蛋白质,OpenComplex 2还能预测各种复合物。
预测结果显示,OpenComplex 2具备了通用预测能力,仅用少量GPU取得的精度竟达到超算的水平。
另外,智源还将这样的技术应用在实时孪生心脏计算建模中,实现了将心脏的生物秒和计算秒突破到了1:0.9,真正实现了临床应用的可能。
大模型时代新Linux
以上所有成果,都需要依赖一个强大的技术基座——FlagOpen。
它是一个面向异构芯片、支持多种框架的大模型全栈开源的技术底座,在一年时间里从1.0升级到了2.0。
FlagOpen中,有面向不同芯片的算子库,有面向异构AI计算的框架,有数据处理的工具,也有各种算法和EMU、BGE等模型。
因此,这个开源框架能够真正实现一栈式领先的高效应用的算法和工具。
同时,FlagOpen也和Linux、Hugging Face等全球主流的基金会合作。
同时,智源还构建了为大模型而生、支持异构芯片的算力集群「操作系统」FlogOS。
在过去20多个月内,它已经支持了超过50个团队训练大模型,能够支持8种AI芯片。

在FlagOpen中,一个核心部分就是面向大模型的开源Triton算子库。
其中大概有120多个主流通用的算子,目前实现了48%的全覆盖,能支持六大厂商的多种AI芯片。
而针对大模型专用的算子库,其中有6个FlagAttention算子,能够覆盖主流的attention。
同时依托智源在LLM方面的前沿研究,平台也能紧随算法前沿去打造创新的算子。
FlagScale是一个多元异构的并行训练框架,凭借这个框架,智源在业内首次实现了不同厂商跨节点RDMA直连以及多种并行策略的高效混合训练。
并且,智源实现了首个基于多元异构芯片、Scale-Up+Scale-Out两阶段高校训练的千亿语言模型,模型也已经在社区里开源。
新发布数据集
同时,智源还发布了两个开源数据集。
首先,是首个千万级中英文高质量指令微调数据集InfinityInstruct。
要知道,SFT阶段在激发大模型能力非常关键,而目前社区里依然非常缺乏高质量的SFT数据。
实验结果显示,这个数据集能让非常多开源社区的基座模型达到或接近GPT-4的水平。
此外,智源还将开源全球最大的中英文多行业数据集IndustryCorpus。
它覆盖18类行业,总计3.4TB。结果显示,它能显著提升通用基座模型在领域里的效果。
上月发布的FlagEval大模型评测榜单,也为业内打造了一把丈量模型能力高峰的「尺子」。
正是基于智源研究院的开源承诺,以及在社区持续做出的创新突破,FlogOpen系列的开源模型框架工具,在过去一年的全球总下载量,已经超过了4755万次,在国内的AI机构中属于绝对领先。

一年一度「追星现场」
2023年智源大会上的「AI安全论坛」上就有多位AI大佬汇聚,Hinton、Altman、Tegmark、Russell针对安全与对齐问题各抒己见。

AI教父Hinton「现身」的那一刻,直接上演了追星现场。

而今年3月由智源顾问委员会主任宏江博士发起,智源研究院主办的AI安全论坛上,不仅有Hinton,Bengio本人更是来到了现场,还有国内大佬姚期智、张亚勤、薛澜等人,共话AI安全。


这不,在2024北京智源大会上最先presentation的,便是一位重磅嘉宾——同时参与打造Sora和DALL·E的背后开发者。
大会邀请到了DALL·E作者之一Aditya Ramesh惊喜现身,他目前在OpenAI工作,是Sora模型团队的负责人。
更让人惊喜的是,在他演讲结束后,我们居然看到纽约大学谢赛宁教授上台,与Ramesh展开了一场深度对谈。
演讲中,Ramesh首先带领大家简要回顾了近年来生成式模型的发展。
2021年1月,DALL-E 1发布,他们最初的想法只是看到了Transformer在文本建模上的优秀性能,于是尝试着扩展到视频领域。

结果发现,Transformer架构建模视频的表现也相当之好,于是接下来的几年也是DALL-E系列模型不断扩展的进程。参数量不断增大,模型的功能也在逐渐扩展。
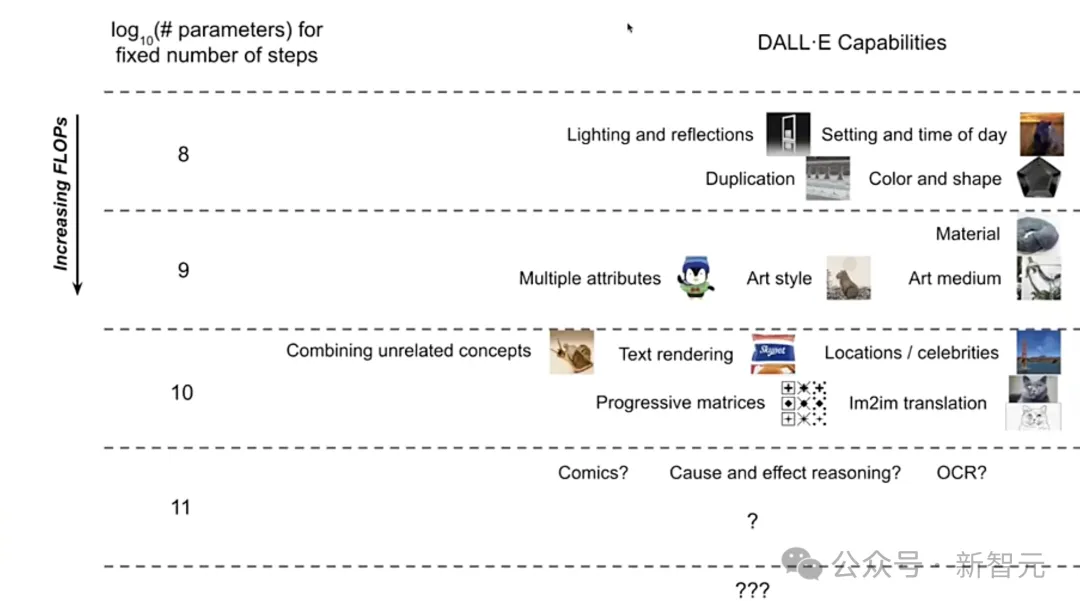
尽管效果很好,Ramesh却在反思,DALL-E 1这样的模型是否能真正学习到世界的压缩表征,能否通向AI智能。
在这个过程中,OpenAI另外两项工作给了他很多启发,一个是Mark Chen等人发表的iGPT,一个是 Alec Radford等人的CLIP。

CLIP的论文在Ramesh眼中,是一项有「范式转变」意义的工作。
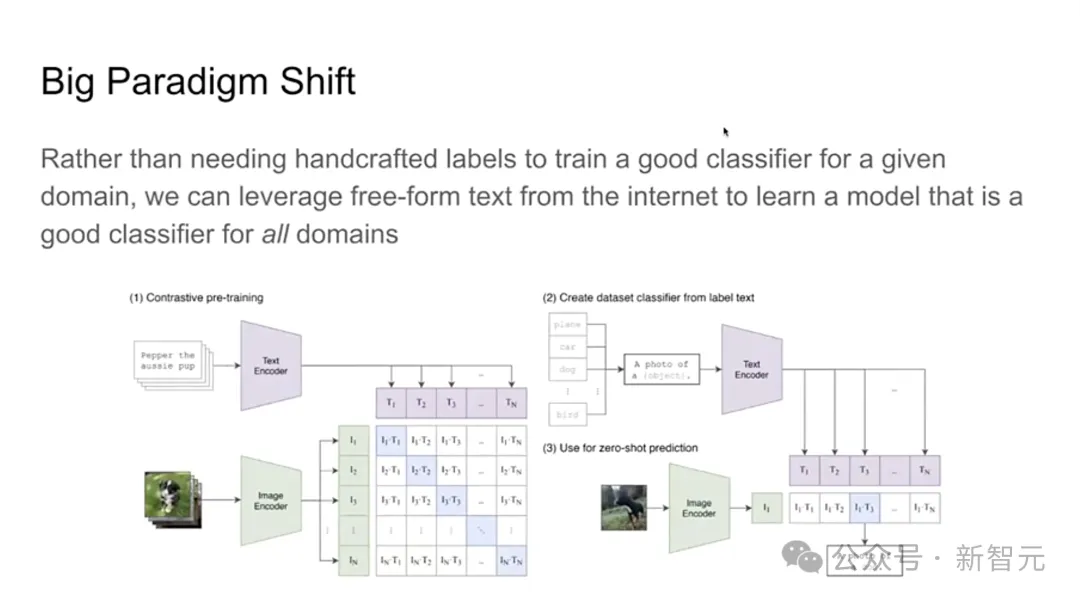
因为从CLIP开始,图像表征学习才真正开始进化。
从ImageNet中提取的类别特征,到CLIP提取的更通用的的文本/图像信息,再到2023年DeepMind提出Cap骨干模型,从视觉世界中重建自然语言。
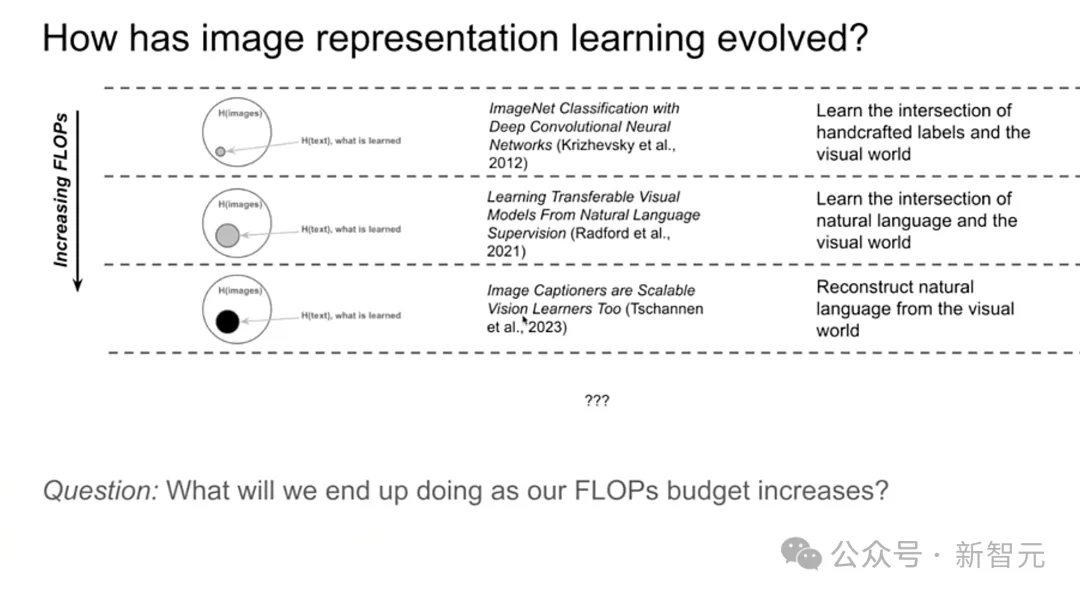
当任务定义变得越来越简洁,视觉表征学习的能力逐渐强大,我们的计算资源也在增加,那么下一步需要用算力来做什么?
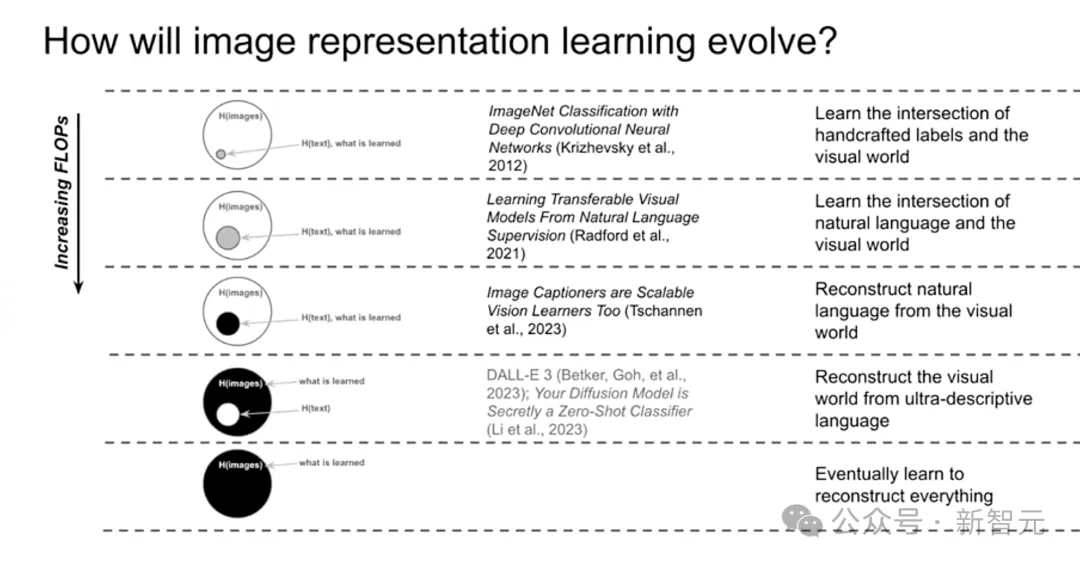
可以看到,语言的作用正不断被纳入视觉的范畴。Ramesh认为,接下来自然语言会逐渐成为类似「脚手架」的角色,帮助模型训练视觉能力。

到最后,类似Sora这种强大的视觉模型将不断吸取、压缩现实世界的信息,带来可行的「世界模拟器」。
中国的世界研究院,AI大佬怎么看?
成立于2018年,智源用了6年的时间,阐释了如何成为AI领域的兼具创新与活力的研发机构。
从模型发布开源,到构建部署模型全链技术栈,再到AI盛会,学术社区,无不体现着「智源模式」。
中国的世界研究院,也成为了其代名词。

对于这家研究机构,国内LLM初创公司的大佬们,纷纷给予了极高的赞誉。
月之暗面创始人杨植麟表示,智源在2020年就开始开发悟道模型了,是在亚洲地区最早投入大模型的机构。这种想法非常难得,非常领先。
而如今,智源的视野更宽了。显然,智源大会已经变成了一个非常好的平台,让业内公司都得到了极大收益。
百川智能CEO王小川提到,无论是大模型的思潮还是很多技术,都是从智源发展起来的。
如今中国的大模型已蜂拥而出,而智源在这些市场化的企业面前,就凭借着自身具备的技术高度扮演了智库的角色。因此在生态领域,智源能够帮助中国AI企业更加快速健康地发展。

智谱AI的创始人张鹏则将智源称为「国内甚至国际人工智能领域的一面旗帜」。
在他看来,智源起了一个好名字,这也是发布Flag系列产品的本意。在整个AI浪潮中,智源具有非常宏远的布局,智谱AI等企业也非常希望和智源长期在学术研究、落地应用、公共政策等方面合作。
面壁智能的CEO李大海则表示,如今大模型这个领域时刻发生快速的变化,有一些事情,是商业公司没有动力、也没有资源做的。
因此,大家就非常期待着智源的撮合和带领下,搭建一个更好的平台,协作做好一些需要做好的事。
相信在未来,坚持学术创新和AI前沿路线探索的智源研究院,将会给我们带来更多的惊喜。
文章来源于“新智元”,作者“新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
