# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近两天,一篇入选 ACL 2024 的论文《Can Language Models Serve as Text-Based World Simulators?》在社交媒体 X 上引发了热议,就连图灵奖得主 Yann LeCun 也参与了进来。
这篇论文探讨的问题是:当前语言模型本身是否可以充当世界模拟器,并正确预测动作如何改变不同的世界状态,从而避免大量手动编码的需要呢?
针对这一问题,来自亚利桑那大学、纽约大学、约翰斯・霍普金斯大学、微软研究院、 艾伦人工智能研究所等机构的研究者在「基于文本的模拟器」上下文中给出了他们的答案。
他们认为:语言模型并不能作为世界模拟器使用。比如,GPT-4 在模拟基于常识任务(如烧开水)的状态变化时,准确率仅为约 60%。

x 地址:https://x.com/peterjansen_ai/status/1801687501557665841
Yann LeCun 对这篇论文的发现表示了认同,并认为「没有世界模型,也就没有规划。」

X 地址:https://x.com/ylecun/status/1801978192950927511
不过也有人表达了不同的观点:当前 LLM(没有进行针对性任务训练)的准确率可以达到 60%,这不就说明了它们至少是「一定程度上的世界模型」吗?并且会随着 LLM 的迭代而持续改进。LeCun 又表示,世界模型不会是 LLM。
回到论文中,研究者构建并使用了一个全新的基准,他们称为「ByteSized32-State-Prediction」,包含了一个文本游戏状态转换和随附游戏任务组成的数据集。他们首次使用该基准来直接量化大语言模型(LLM)作为基于文本的世界模拟器的性能。
通过在这个数据集上测试 GPT-4,研究者发现:尽管它的性能令人印象深刻,但如果没有进一步的创新,它仍然是一个不可靠的世界模拟器。
因此,研究者认为,他们的工作既为当前 LLM 的能力和弱点提供了新的见解,也为跟踪新模型出现时的未来进展提供了一个新的基准。

论文地址:https://arxiv.org/pdf/2406.06485
方法概览
研究者探究了 LLM 在基于文本的虚拟环境中充当世界模拟器的能力,在这种环境中,智能体接收观察结果并以自然语言提出操作以完成某些目标。
每个文本环境都可以正式表示为具有 7 元组 (S,A,T,O,R,C,D) 的目标条件部分可观察马尔可夫决策过程 (POMDP),S 表示状态空间,A 表示动作空间,T : S×A→S 表示转换函数,O 表示观察函数,R : S×A→R 表示奖励函数,C 表示描述目标和动作语义的自然语言「上下文消息」,D : S×A→{0,1} 表示二元完成指示函数。
大模型模拟器(LLM-Sim)任务
研究者提出了一个预测任务,称它为 LLM as-a-Simulator (LLM-Sim),用来定量评估语言模型作为可靠模拟器的能力。
LLM-Sim 任务是将一个函数 F : C×S×A→S×R×{0,1} 作为世界模拟器来实现。在实践中,完整状态转换模拟器 F 应该考虑两种类型的状态转换:动作驱动转换和环境驱动转换。
图 1 为使用 LLM 作为文本游戏模拟器的示例:打开水槽后,水槽中的杯子被水填满的过程。动作驱动转换是采取打开水槽的动作后,水槽被打开(isOn=true);而环境驱动转换是在水槽打开时,水填满水槽中的杯子。

为了更好地理解 LLM 对每个转换进行建模的能力,研究者进一步将模拟器函数 F 分解为三个步骤:
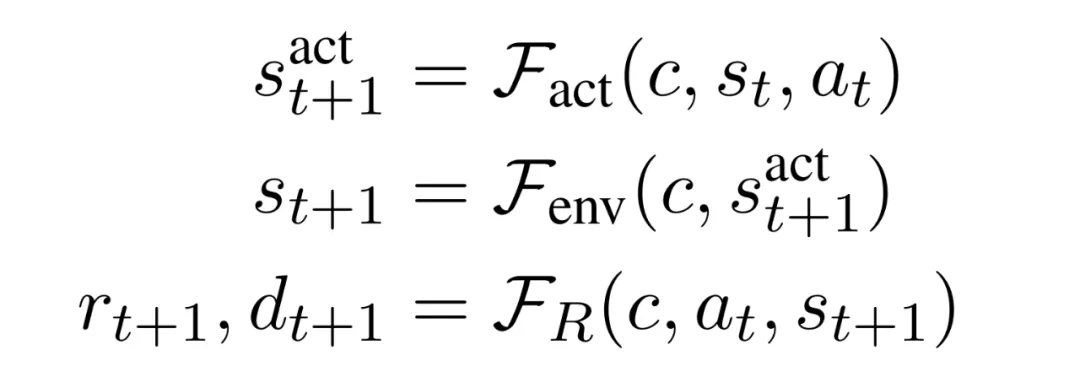
此外,研究者考虑了 LLM-Sim 任务的两种变体
数据和评估
为了完成这一任务,研究者引入了一个新的文本游戏状态转换数据集。该数据集为 「BYTESIZED32-State-Prediction (BYTESIZED32-SP) 」,它包含 76,369 个转换,表示为 (c,s_t,rt,d_t,a_t,s^act_t+1,s_t+1,r_t+1,d_t+1) 元组。这些转换是从 31 个不同的文本游戏中收集的。
下表 1 总结了额外语料库统计数据。

LLM-Sim 上的性能由模型相对于测试样本数据集上的真实标签的预测准确性来决定。根据实验条件,LLM 必须模拟对象属性(模拟 F_act、F_env 或 F)和 / 或游戏进度(模拟 F_R 或 F),定义如下:
研究者注意到,在每种情况下,LLM 都提供了 ground truth 先前状态(当函数为 F_env 时,先前状态为 s^act_t+1 )以及整体任务上下文。也就是说,LLM 始终执行单步预测。
实验结果
上图 1 演示了研究者使用上下文学习评估 LLM-Sim 任务中模型的性能。他们评估了 GPT-4 在完整状态和状态差异预测机制中的准确性。该模型接收先前状态(编码为 JSON 对象)、先前操作和上下文消息,并生成后续状态(作为完整的 JSON 对象或差异)。
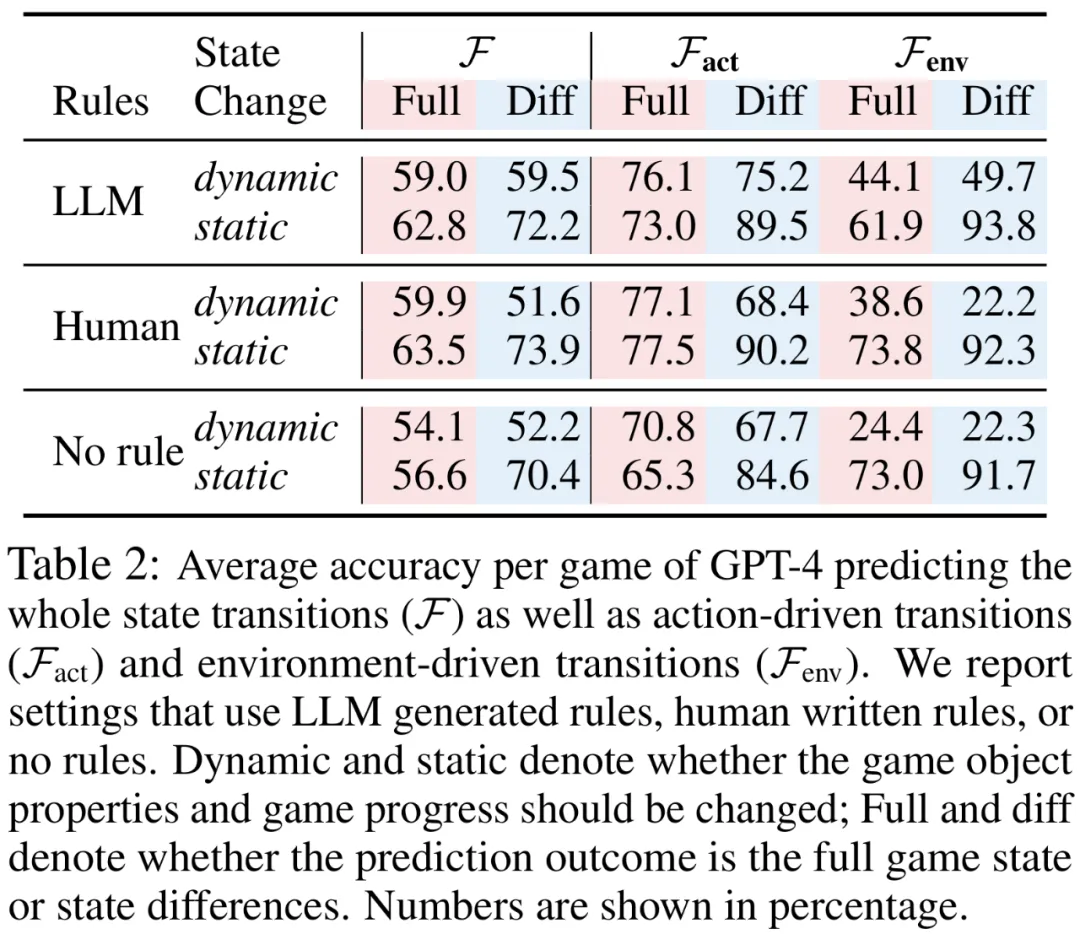
下表 2 展示了 GPT-4 模拟完整状态转换的准确性,以及单独模拟动作驱动转换和环境驱动转换的准确性。
研究者得出了以下几项重要发现:
预测动作驱动转换比预测环境驱动转换更容易。在最好的情况下,GPT-4 能够正确模拟 77.1% 的动态动作驱动转换。相比之下,GPT-4 最多只能正确模拟 49.7% 的动态环境驱动转换。
预测静态转换比动态转换更容易。不出所料,在大多数情况下,对静态转换进行建模比对动态转换进行建模要容易得多。
对于动态状态,预测完整游戏状态更容易;而对于静态状态,预测状态差异更容易。预测动态状态的状态差异可以显著提高模拟静态转换的性能(>10%),而模拟动态转换时的性能会降低。
游戏规则很重要,LLM 能够生成足够好的游戏规则。当上下文消息中未提供游戏规则时,GPT-4 在所有三个模拟任务上的性能在大多数情况下都会下降。
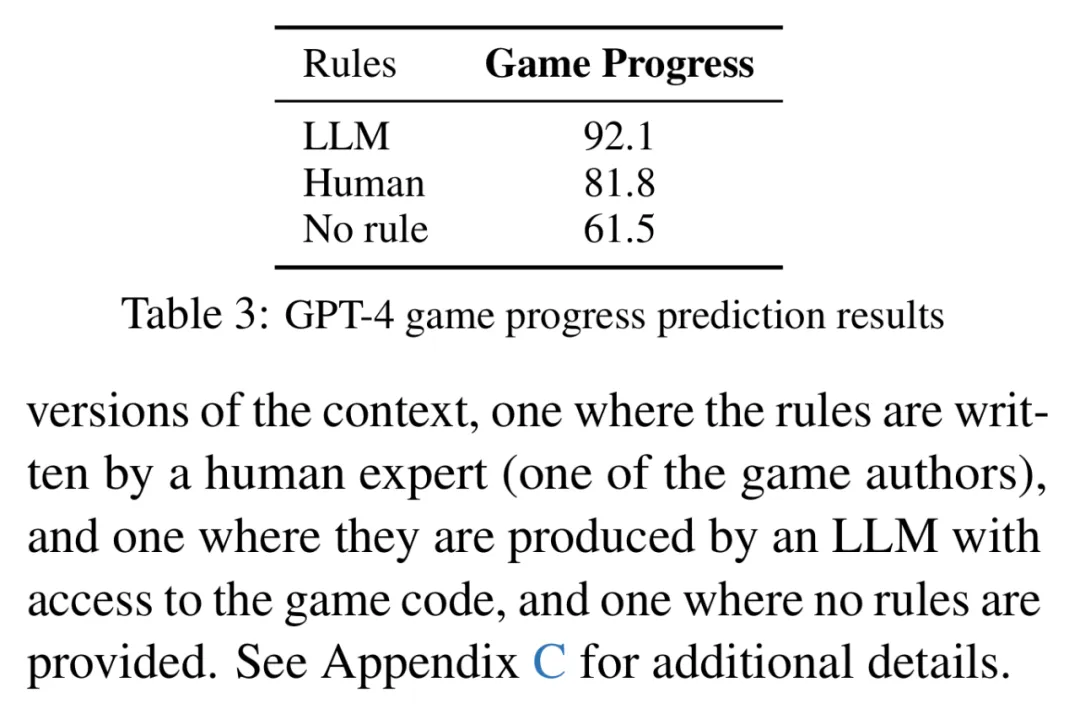
GPT-4 在大多数情况下都能预测游戏进度。下表 3 展示了 GPT-4 预测游戏进度的结果。在上下文中加入了游戏规则信息后,GPT-4 可以在 92.1% 的测试用例中正确预测游戏进度。这些规则的存在在上下文中至关重要:如果没有它们,GPT-4 的预测准确率会下降到 61.5%。
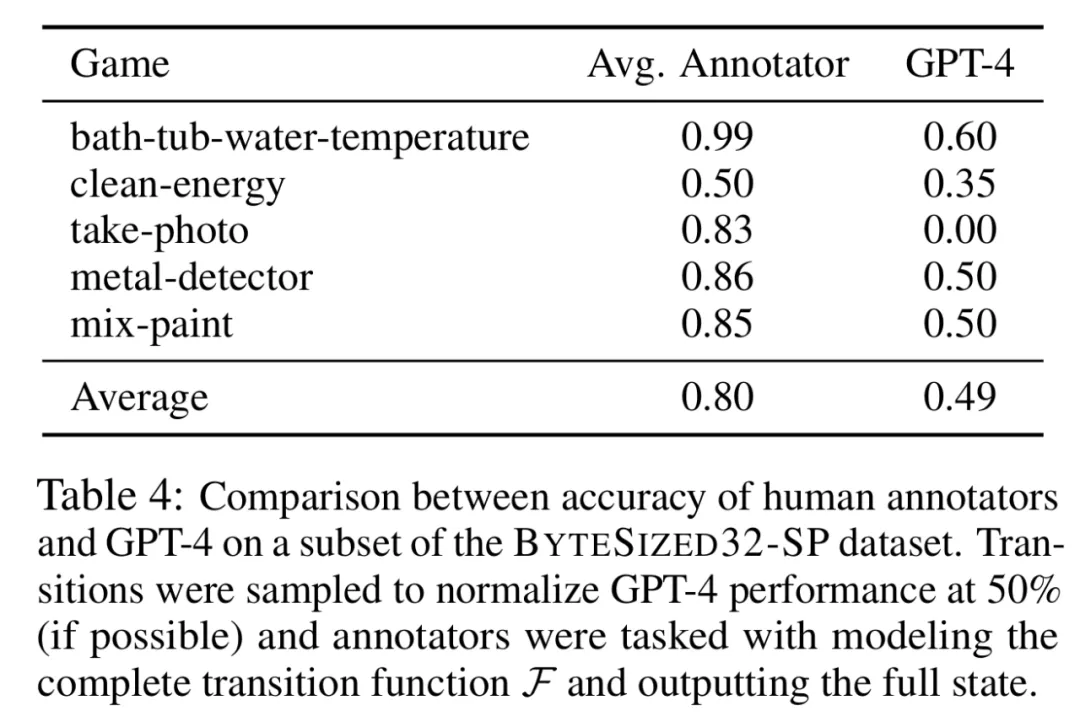
人类在 LLM-Sim 任务中的表现优于 GPT-4。研究者对 LLM-Sim 任务进行了初步的人类研究。结果见下表 4。
结果发现,人类的整体准确率为 80%,而采样的 LLM 的准确率为 50%,并且不同注释者之间的差异很小。这表明,虽然任务对于人类来说总体上是直观且相对容易的,但对于 LLM 来说仍有很大的改进空间。
GPT-4 在需要算术、常识或科学知识时更容易出错。下图 2 展示了在整体状态转换、动作驱动转换和环境驱动转换中,预测结果的正确比例、将属性设置为不正确值的比例或未能更改属性值的比例。
我们可以观察到,GPT-4 能够很好地处理大多数简单的布尔值属性。错误集中出现在需要算术(如温度、timeAboveMaxTemp)、常识(如 current_aperture、current_focus)或科学知识(如 on)的非平凡属性上。

更多技术细节和实验结果请参阅原论文。
文章来源于“机器之心”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
