# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在三维生成建模的研究领域,现行的两大类 3D 表示方法要么基于拟合能力不足的隐式解码器,要么缺乏清晰定义的空间结构难以与主流的 3D 扩散技术融合。来自中科大、清华和微软亚洲研究院的研究人员提出了 GaussianCube,这是一种具有强大拟合能力的显式结构化三维表示,并且可以无缝应用于目前主流的 3D 扩散模型中。
GaussianCube 首先采用一种新颖的密度约束高斯拟合算法,该算法能够对 3D 资产进行高精度拟合,同时确保使用固定数量的自由高斯。随后,借助最优传输算法,这些高斯被重新排列到一个预定义的体素网格之中。得益于 GaussianCube 的结构化特性,研究者无需复杂的网络设计就能直接应用标准的 3D U-Net 作为扩散建模的主干网络。
更为关键的是,本文提出的新型拟合算法极大地增强了表示的紧凑性,在 3D 表示拟合质量相似的情况下所需的参数量仅是传统结构化表示所需参数量的十分之一或百分之一。这种紧凑性大幅降低了 3D 生成建模的复杂性。研究人员在无条件和条件性 3D 对象生成、数字化身创建以及文本到 3D 内容合成等多个方面开展了广泛的实验。
数值结果表明,GaussianCube 相较之前的基线算法实现了最高达 74% 的性能提升。如下所示,GaussianCube 不仅能够生成高质量的三维资产,而且还提供了极具吸引力的视觉效果,充分证明了其作为 3D 生成通用表示的巨大潜力。
图 1. 无条件生成的结果。本文的方法可以生成高质量、多样化的三维模型。

图 2. 基于输入肖像进行数字化身创建的结果。本文的方法可以极大程度上保留输入肖像的身份特征信息,并且提供细致的发型、服装建模。

图 3. 基于输入文本创建三维资产的结果。本文的方法可以输出与文本信息一致的结果,并且可以建模复杂的几何结构和细节材质。

图 4. 类别条件生成的结果。本文生成的三维资产语义明确,具有高质量的几何结构和材质。

都什么年代了
还在用传统 NeRF 进行三维生成建模?
大多数先前的 3D 生成建模工作都使用了 Neural Radiance Field (NeRF) 的变体作为其底层的 3D 表示,这些表示通常结合了一个显式的结构化特征表示和一个隐式的特征解码器。然而在三维生成建模中,所有三维物体不得不共享同一个隐式特征解码器,这种做法在很大程度上削弱了 NeRF 的拟合能力。此外,NeRF 所依赖的体渲染技术具有非常高的计算复杂性,这导致了渲染速度缓慢,更需要消耗极高的 GPU 内存。近期,另一种三维表示方法高斯溅射(3D Gaussian Splatting,简称 3DGS)备受瞩目。虽然 3DGS 拟合能力强大、计算性能高效,还具备完全显式的特性,在三维重建任务中得到了广泛应用。但是,3DGS 缺乏一个明确定义的空间结构,这使得其在无法直接应用于目前主流生成建模框架中。
因此,研究团队提出了 GaussianCube。这是一种创新的三维表示方法,它既结构化又完全显式,具备强大的拟合能力。本文介绍的方法首先确保通过固定数量的自由高斯实现高精度的拟合,然后将这些高斯有效地组织到一个结构化的体素网格中。这种显式且结构化的表示方法让研究者能够无缝地采用标准的 3D 网络架构,例如 U-Net,无需进行使用非结构化或隐式解码表示时所需的复杂和定制化的网络设计。
同时,通过最优传输算法进行的结构化组织最大程度地保持了相邻高斯核之间的空间结构关系,使得研究者仅使用经典的 3D 卷积网络就能高效地提取特征。更为关键的是,鉴于先前研究中的发现,扩散模型在处理高维数据分布时表现不佳,本文提出的 GaussianCube 在保持高质量重建的同时,显著减少了所需的参数量,极大地缓解了扩散模型在分布建模上的压力,为 3D 生成建模领域带来了显著的建模能力和效率提升。
方法
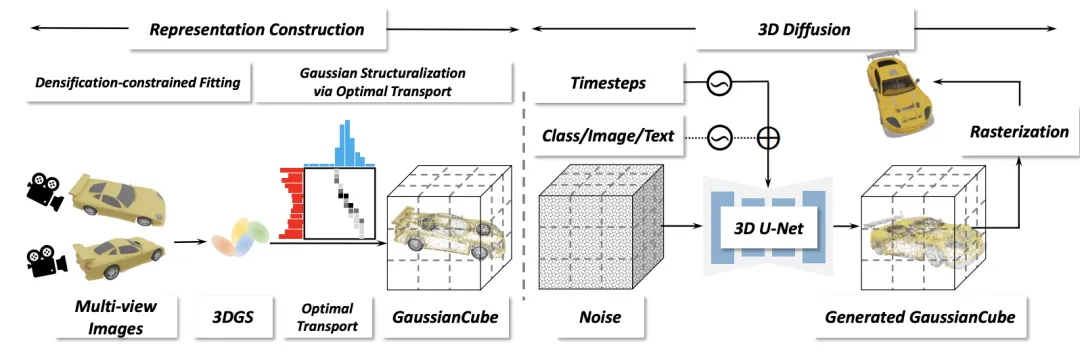
图 5. GaussianCube 框架总览
本文的框架包括两个主要阶段:表示构建和三维扩散。在表示构建阶段,给定三维资产的多视角渲染图,对其进行密度约束的高斯拟合,以获得具有固定数量的三维高斯。随后,通过最优化传输将三维高斯结构化为 GaussianCube。在三维扩散阶段,研究人员对三维扩散模型进行训练,以便从高斯噪声中生成 GaussianCube。

图 6. 密度约束的高斯拟合算法示意图
在表示构建阶段,研究人员需要为每个三维资产创建适合生成建模的表示。考虑到生成领域往往需要建模的数据有统一的固定长度,而原始 3DGS 拟合算法中的自适应密度控制会导致拟合不同物体所使用的高斯核数量不同,这给生成建模带来了极大挑战。一种非常简单的解决方案是直接去除自适应密度控制,但研究人员发现这会严重降低拟合的精度。本文提出了一种新颖的密度约束拟合算法,保留原始自适应密度控制中的剪枝操作,但对其中的分裂和克隆操作进行了新的约束处理。
具体来说,假设当前迭代包括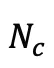 高斯,研究人员通过选择那些在视角空间位置梯度幅度超过预定义阈值 τ 的高斯来识别分裂或克隆操作的候选对象,这些候选对象的数量记为
高斯,研究人员通过选择那些在视角空间位置梯度幅度超过预定义阈值 τ 的高斯来识别分裂或克隆操作的候选对象,这些候选对象的数量记为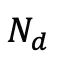 。为了防止超出预定义的最大值
。为了防止超出预定义的最大值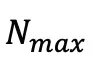 个高斯,从候选对象中选择
个高斯,从候选对象中选择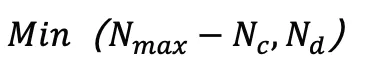 个具有最大视角空间位置梯度的高斯进行分裂或克隆。在完成拟合过程后,研究人员用 α=0 的高斯填充以达到目标计数
个具有最大视角空间位置梯度的高斯进行分裂或克隆。在完成拟合过程后,研究人员用 α=0 的高斯填充以达到目标计数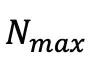 而不影响渲染结果。得益于此策略,可以实现了与类似质量的现有工作相比参数量减少了几个量级的高质量表示,显著降低了扩散模型的建模难度。
而不影响渲染结果。得益于此策略,可以实现了与类似质量的现有工作相比参数量减少了几个量级的高质量表示,显著降低了扩散模型的建模难度。

图 7. 密度约束的高斯拟合算法示意图
尽管如此,通过上述拟合算法得到的高斯仍然没有明确的空间排列结构,这使得后续的扩散模型无法高效地对数据进行建模。为此,研究人员提出将高斯映射到预定义的结构化体素网格中来使得高斯具有明确的空间结构。直观地说,这一步的目标是在尽可能保持高斯的空间相邻关系的同时,将每个高斯 “移动” 到一个体素中。
研究人员将其建模为一个最优传输问题,使用 Jonker-Volgenant 算法来得到对应的映射关系,进而根据最优传输的解来组织将高斯组织到对应的体素中得到 GaussianCube,并且用当前体素中心的偏移量替换了原始高斯的位置,以减少扩散模型的解空间。最终的 GaussianCube 表示不仅结构化,而且最大程度上保持了相邻高斯之间的结构关系,这为 3D 生成建模的高效特征提取提供了强有力的支持。
在三维扩散阶段,本文使用三维扩散模型来建模 GaussianCube 的分布。得益于 GaussianCube 在空间上的结构化组织关系,无需复杂的网络或训练设计,标准的 3D 卷积足以有效提取和聚合邻近高斯的特征。于是,研究者利用了标准的 U-Net 网络进行扩散,并直接地将原始的 2D 操作符(包括卷积、注意力、上采样和下采样)替换为它们的 3D 实现。
本文的三维扩散模型也支持多种条件信号来控制生成过程,包括类别标签条件生成、根据图像条件创建数字化身和根据文本生成三维数字资产。基于多模态条件的生成能力极大地扩展了模型的应用范围,并为未来的 3D 内容创造提供了强大的工具。
实验结果
研究人员首先在 ShapeNet Car 数据集上验证了 GaussianCube 的拟合能力。实验结果表明,与基线方法相比,GaussianCube 可以以最快的速度和最少的参数量实现高精度的三维物体拟合。
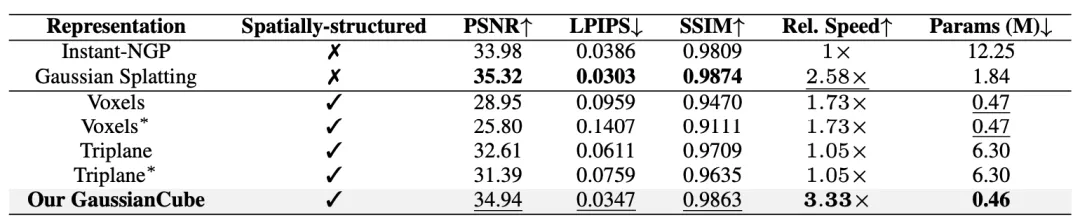
表 1. 在 ShapeNet Car 上不同的三维表示关于空间结构、拟合质量、相对拟合速度、使用参数量的数值比较。∗ 表示不同物体共享隐式特征解码器。所有方法均以 30K 次迭代进行评估。

图 8. 在 ShapeNet Car 上不同的三维表示拟合能力的视觉比较。∗ 表示不同物体共享隐式特征解码器。所有方法均以 30K 次迭代进行评估。
研究人员其次在大量数据集上验证了基于 GaussianCube 的扩散模型的生成能力,包括 ShapeNet、OmniObject3D、合成数字化身数据集和 Objaverse 数据集。实验结果表明,本文的模型在无条件和类别条件的对象生成、数字化身创建以及文本到 3D 合成从数值指标到视觉质量都取得了领先的结果。特别地,GaussianCube 相较之前的基线算法实现了最高达 74% 的性能提升。

表 2. 在 ShapeNet Car、Chair 上进行无条件生成和在 OmniObject3D 上进行类别条件生成的定量比较。

图 9. 在 ShapeNet Car、Chair 上进行无条件生成的定性比较。本文的方法可以生成精确几何和细节材质。

图 10. 在 OmniObject3D 上进行类别条件生成的定性比较。本文方法可以生成明确语义的复杂物体。

表 3. 基于输入肖像进行数字化身创建的定量比较。

图 11. 基于输入肖像进行数字化身创建的定性比较。本文的方法能够更准确地还原输入肖像的身份特征、表情、配饰和头发细节。

表 4. 基于输入文本创建三维资产的定量比较。推理时间使用单张 A100 进行测试。Shap-E 和 LGM 与本文方法取得了相似的 CLIP Score,但它们分别使用了数百万的训练数据(本文仅使用十万三维数据训练),和二维文生图扩散模型先验。
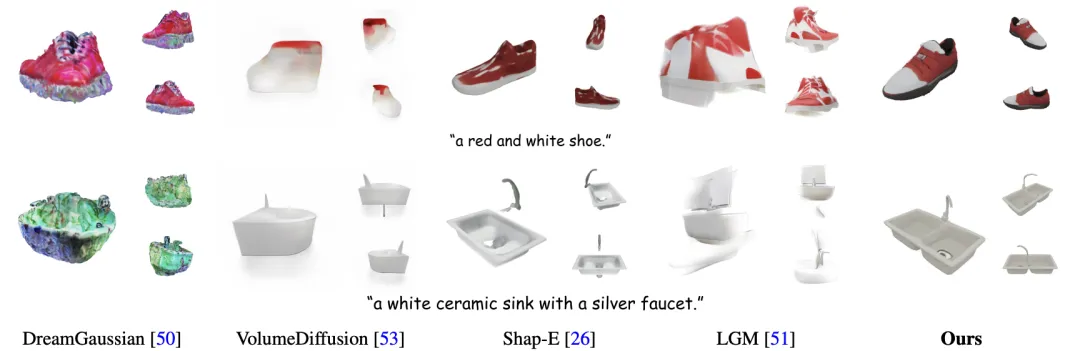
图 12. 基于输入文本创建三维资产的定性比较。本文的方法可以根据输入文本实现高质量三维资产生成。
文章来源于“机器之心”



