# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型提示的「怪异世界」,首次如此详尽地被暴露在我们眼前。
最近,来自马里兰大学、OpenAI、斯坦福、微软等12所机构的30多名研究者,首次对LLM的提示技术进行了大规模的系统研究,并发布了一份长达75页的详尽报告。

论文地址:https://arxiv.org/abs/2406.06608

如今,提示已经无处不在,然而在整个生成式AI行业,仍然缺乏对已出现的数百种技术系统和彻底的调查。
在这项工作中,研究者通过结合人工和AI的力量,从arXiv、Semantic Scholar和ACL数据库中处理了4,797条记录,并通过PRISMA审查过程筛选出1,565篇相关论文。
由此,他们得到一种分类法,建立了包含33个术语的综合词汇表,一个包含58种文本提示技术的分类体系,以及40种其他模态的提示技术等。
这篇有史以来最全的提示技术报告,纷纷得到了业内大佬们的鼎力推荐。


这里需要明确三个概念——
提示,是指向GenAI提供提示,然后生成响应的过程。
提示技术,是一个蓝图,描述如何构造一个提示或多个提示的动态排序。它可以结合条件或分支逻辑、并行性或涉及多提示的架构。
提示工程,是指通过修改或更改正在使用的提示技术,来开发提示的迭代过程。
奇奇怪怪的大语言模型
有趣的是,在这个过程中,研究者发现了大语言模型一些奇怪的现象。
1. 重复某些话,LLM会给你惊喜
研究者发现,如果重复部分提示,会显著提高模型的性能。

比如,在一个关于自杀危机检测的案例中,因为意外,导致一封包含案例背景的邮件在提示中出现了两次,这就导致模型的性能大大提高。
删除掉重复内容后,模型的准确性就显著降低了。
这是什么原理?
对此,研究者也无法给出明确的解释。
2. 说出你的名字!
研究者在测试中发现的另一件有趣的事,就是在提示中包含人名也很重要。
比如在上面的邮件中,如果名字被匿名,或者替换为随机姓名时,模型的准确性也会下降。

为何LLM会对这种看似无关痛痒的细节如此敏感?对此,研究者们也没有答案。
往好处想,我们可以通过探索,来提供LLM的性能。
然而如果往坏处看,这也证明提示工厂目前仍然是我们人类难以理解的黑盒。在我们人类看来毫不相干的细节,LLM却出乎意料地敏感。
为此,研究者建议,知道如何控制模型的提示工程师,一定要和准确理解目标的专家之间密切合作。
因为,这些AI系统是被哄骗的,而非被编程的。
它们除了对所使用的特定LLM非常敏感,对提示中的特定细节也很敏感,但我们实在找不出任何明显理由,证明这些细节到底怎么重要了。

3. 示例的选择和顺序,LLM也很敏感
通常最有效的提示方法,就是少样本提示了,也即在提示中直接举例。
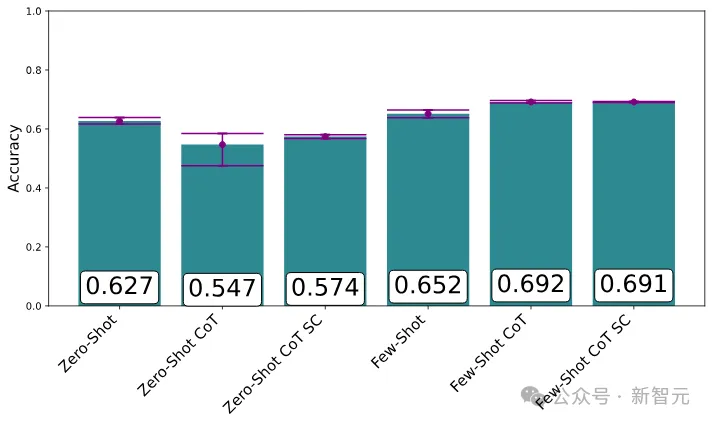
在语言理解MMLU基准测试中,带有示例的提示取得了最佳效果,尤其是与CoT结合时
不过,这其中也有一些奇怪的陷阱:LLM对示例的选择和顺序,竟然非常敏感。
同一示例以不同顺序出场,竟让模型的效果大相径庭,准确度可以低于50%,也可以高于90%。
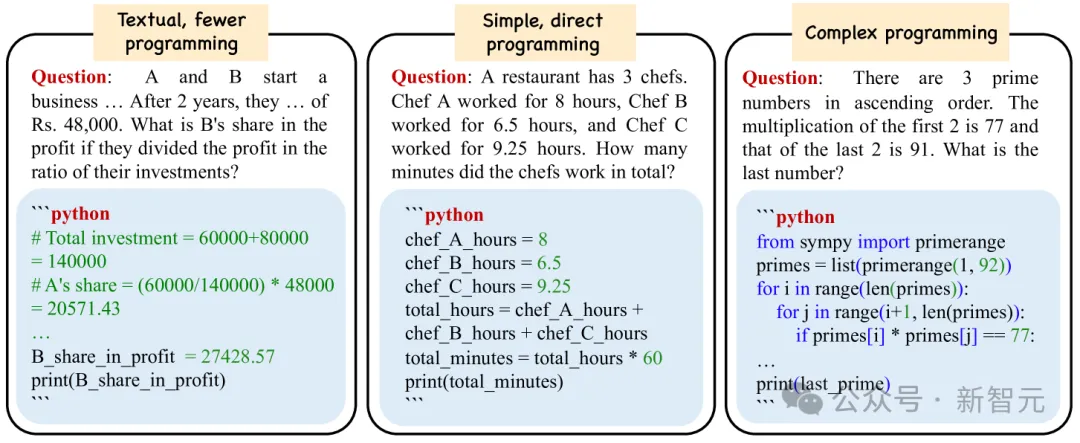
4. 代码辅助推理潜力巨大
目前在研究和行业中得到广泛应用,只有一小部分提示技术,最常见的是就是few-shot和CoT。
但「思维程序」(Program-of-Thoughts)之类的技术(代码被用作推理的中间步骤)也很有前途,但尚未广泛使用。
而且,在案例中,自动化取得了最佳结果。由于手动提示对我们往往是很大的挑战,因此自动化显然潜力巨大。
不过在研究人员看来,人类微调和机器优化的结合,可能会是最有前途的方法。
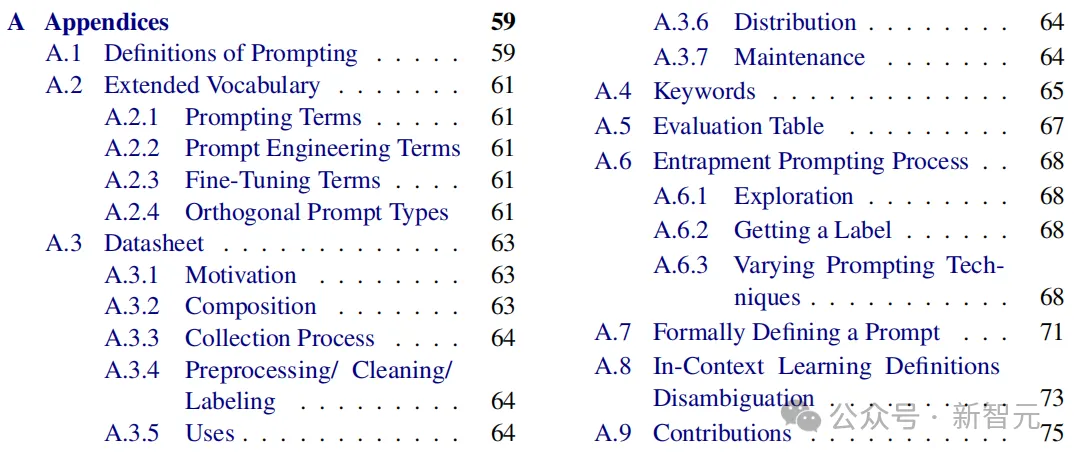
三大提示技术
论文中,研究人员提出了全面的分类提示技术——基于文本、多语言、多模态三大类。
在文本提示类中,整整涵盖了58种纯文本提示技术,如下图所示。
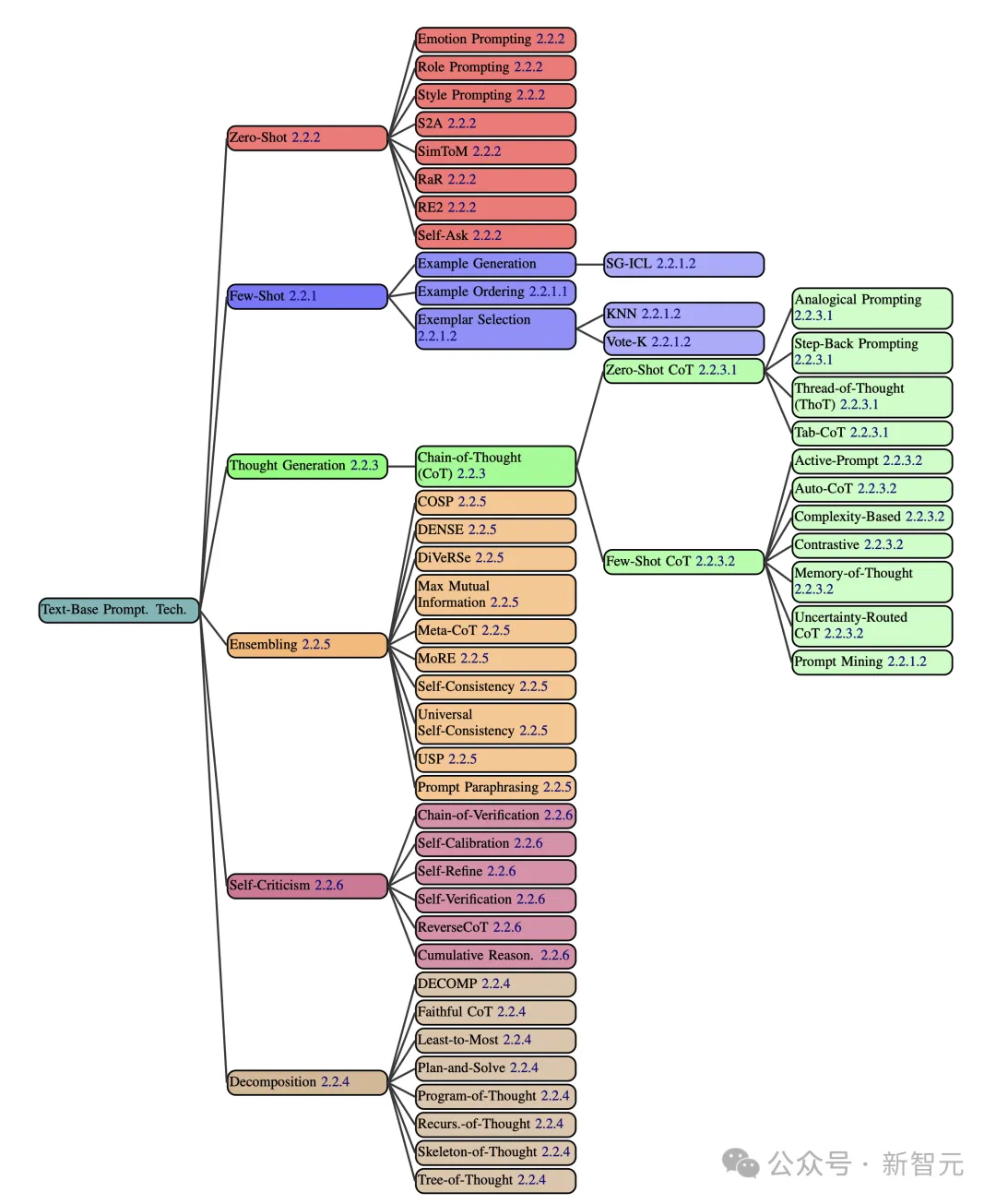
如下,将会列举几个基于文本提示技术的例子。
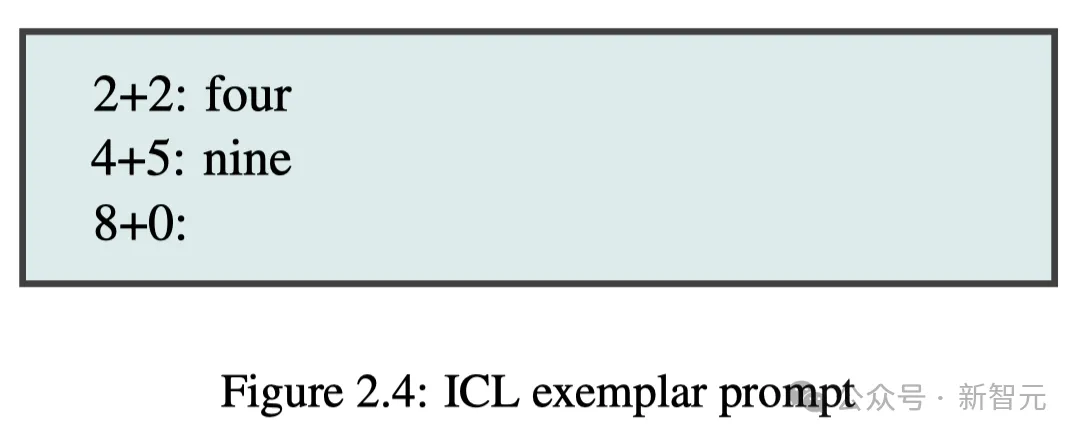
In-Context Learning(ICL)是指AI通过提示中的范例/相关指令,可以学习技能,无需更新权重再训练的能力。
比如,你给出2+2=4,4+5=9,然后8+0这样的提示之后,LLM便会从前两个算式中学习推算,进而解决任务。
再比如,给出指令,从以下文本中提取包含3个同样字母,以及至少有3个其他字母的所有单词:{TEXT}。
LLM通过理解指令,针对文本完成查找。

不过,「学习」一词或许有些误导。ICL其实可以被视为「指定任务」,可能这些技能并非是真正的学习,而早已存在训练数据之中。
就好比,你让LLM去把一个单词「奶酪」翻译成法语。

上图2.4中给出例子的提示,也称为「少样本」提示(Few-Shot Prompting),模型与此进行的是少样本学习。
这里,样本质量非常关键,决定着模型的输出性能。而且,样本的顺序也会影响模型的行为,进而导致LLM输出的准确率可能在50%以下,或90%以上不等。
对此,研究人员建议可以使用K-Nearest Neighbor(KNN)算法、Vote-K等方法,来提升样本质量。
此外,还可通过AI自生成上下文学习(SG-ICL)方法,让AI自动生成样本。作者表示,在训练数据不可用的情况下,它的效果要好于零样本场景。

作者总结了在设计少样本提示时的六个主要设计决策,如下图所示。

针对零样本,有很多我们熟知的提示技术,比如:
在「思维生成」上,CoT是其中最具代表性的方法,而「最纯净」的CoT是不需要任何示例,即零样本CoT。
仅需在提示语中,添加一个诱导思考的短语——让我们一步一步地思考,让我们一步一步地解决这个问题......
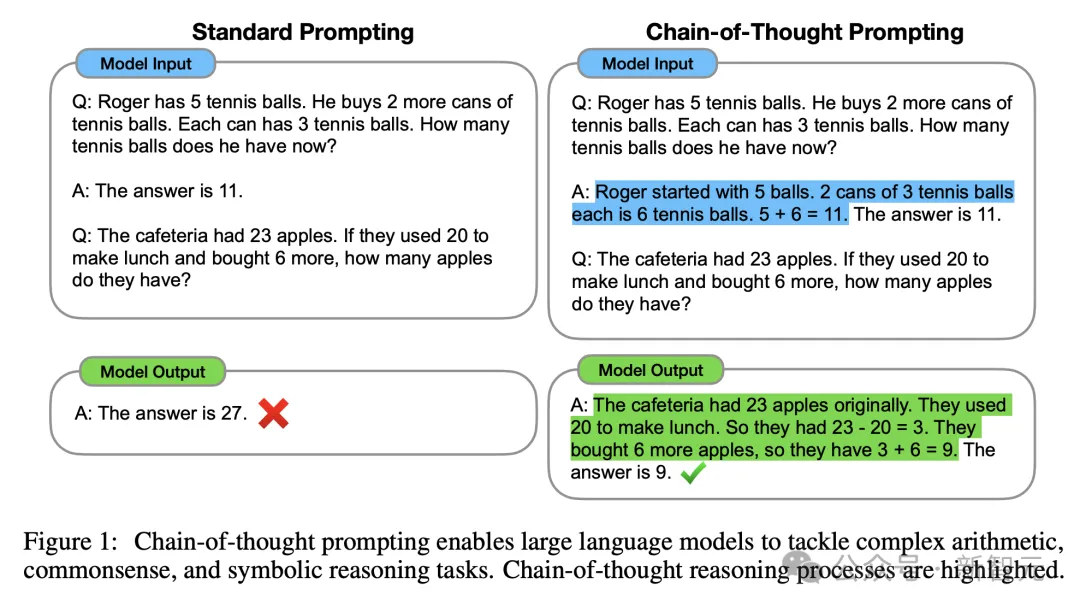
此外,CoT还可以是少样本CoT,顾名思义,就是为LLM提供一些样本,可大幅提升模型性能。

我们还可以通过分解(Decomposition)的提示策略,明确将问题分解,以提升模型解决问题的能力,其中就包括:

与「分解」相对应地,还有「集合」(Ensembling)策略,是指使用多个提示来解决同一问题,然后将这些回答汇总为最终输出的过程。
其中的方法包括,示例集合(DENSE)、推理混合专家(MoRE)、自洽、DiVeRSe、多种CoT元推理等等。
最后,还有自我批评(Self-Criticism)提示策略,包括以下几种技术:自我校准、逆转思维链 (RCoT)、自我验证、验证链 (COVE)、累积推理。
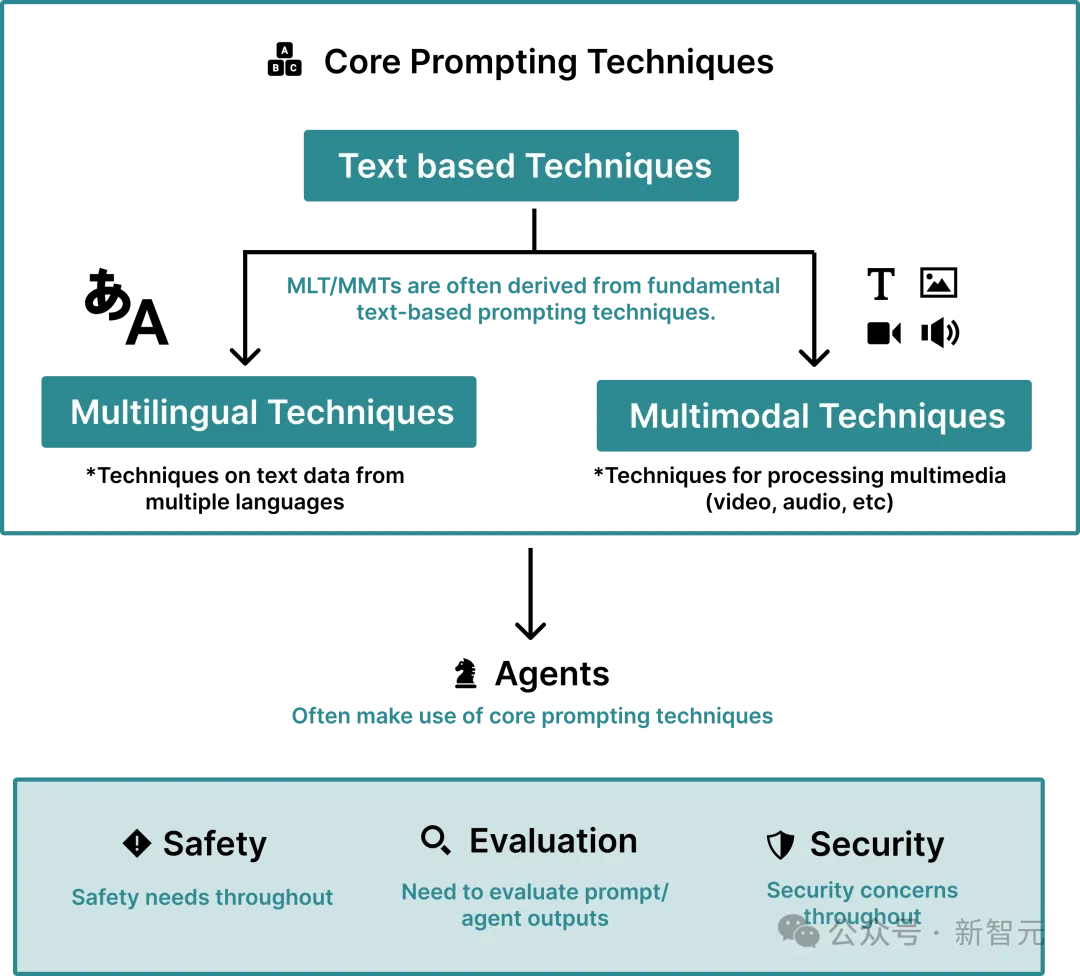
除了研究提示技术,研究人员还回顾了用于自动优化提示的「提示工程」技术。
提示工程过程包括三个重复步骤:1)在数据集上进行推理,2)评估性能,3)修改提示模板。

这是一个用于标注任务的LLM输出注释结果,展示了答案工程(Answer Engineering)的三个设计决策:答案形状的选择、答案空间和提取器。
由于这是一个分类任务的输出,答案形状可以限制为单个token,答案空间可以限制为两个token之一(「positive」或「negative」),尽管在这个图像中它们没有被限制。

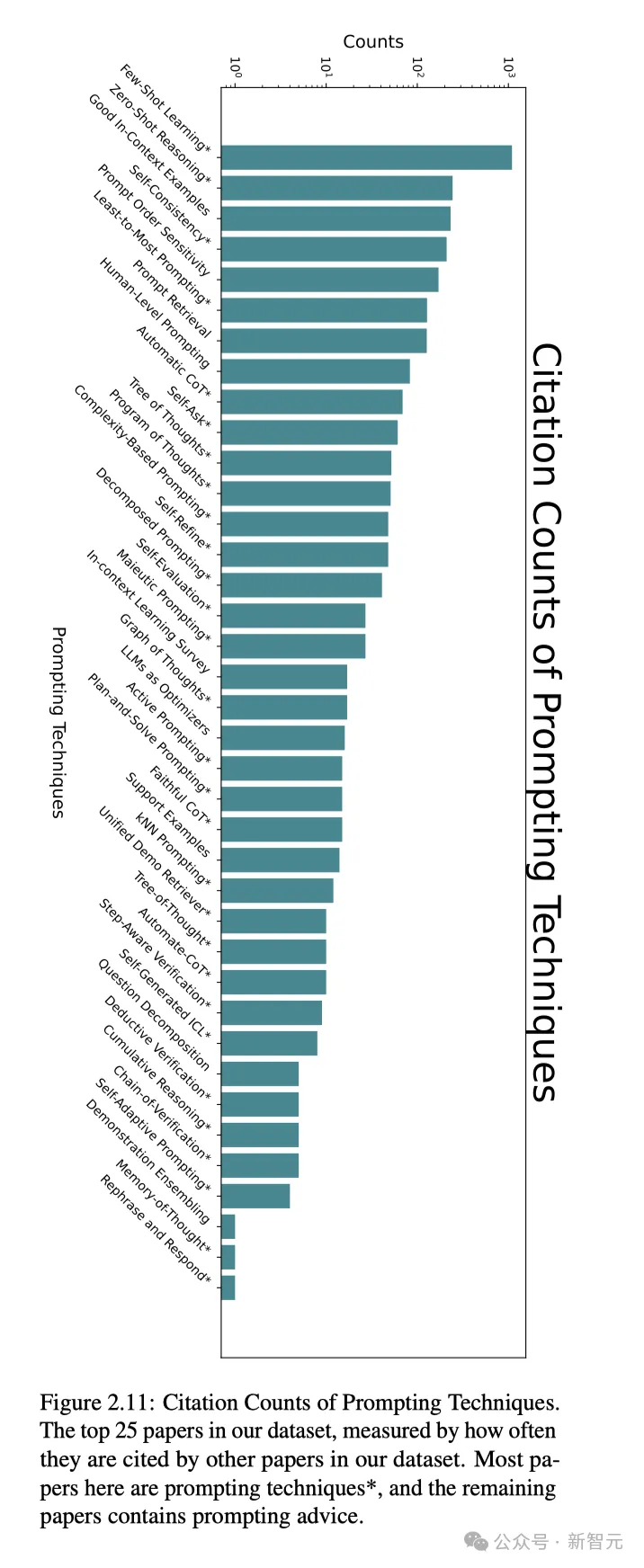
最后,研究者总结发现,在所有的提示技术中,少样本学习、零样本推理、高质量上下文提示示例,自洽,提示顺序敏感性使用率排在了前五。
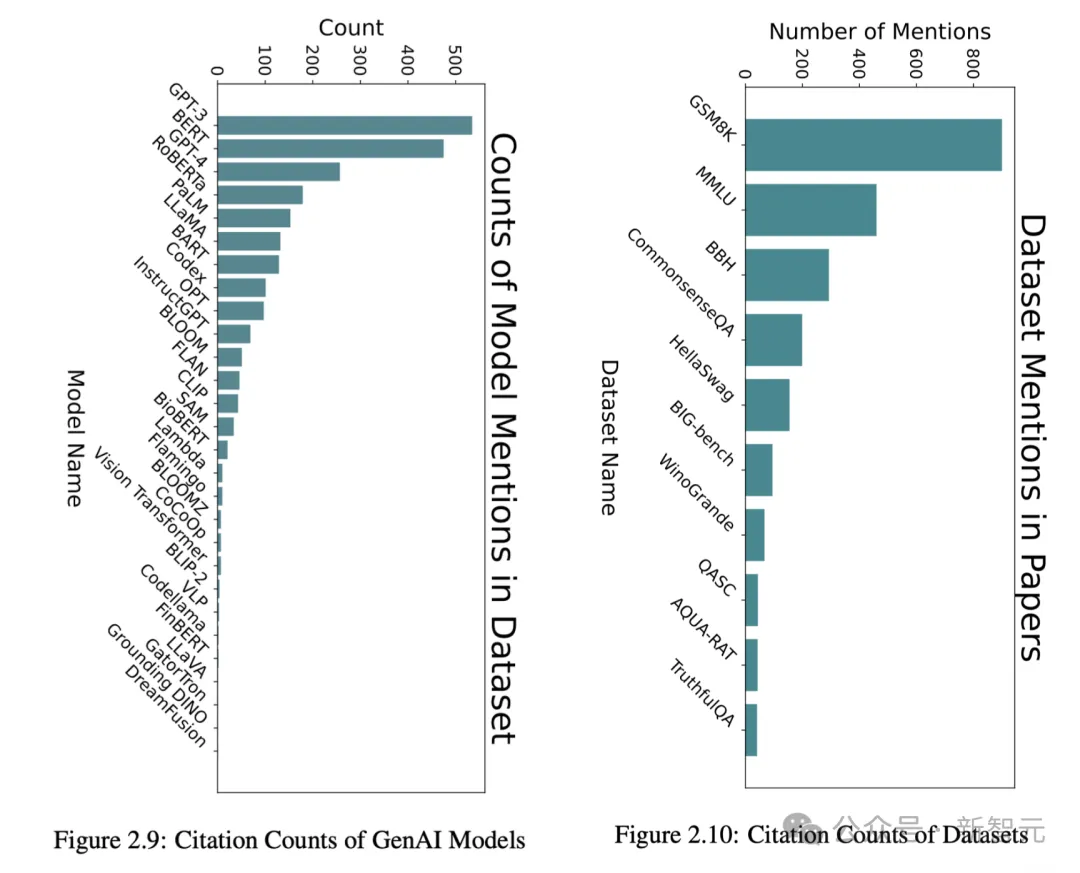
与此同时,我们还可以通过数据集中论文引用的基准数据集和模型次数,来衡量提示技术的使用情况。
在多语种提示技术中,研究人员主要介绍了CoT、Human-in-the-Loop、上下文学习、上下文示例选择、翻译提示、多语种技术、提示语言这几大要点。
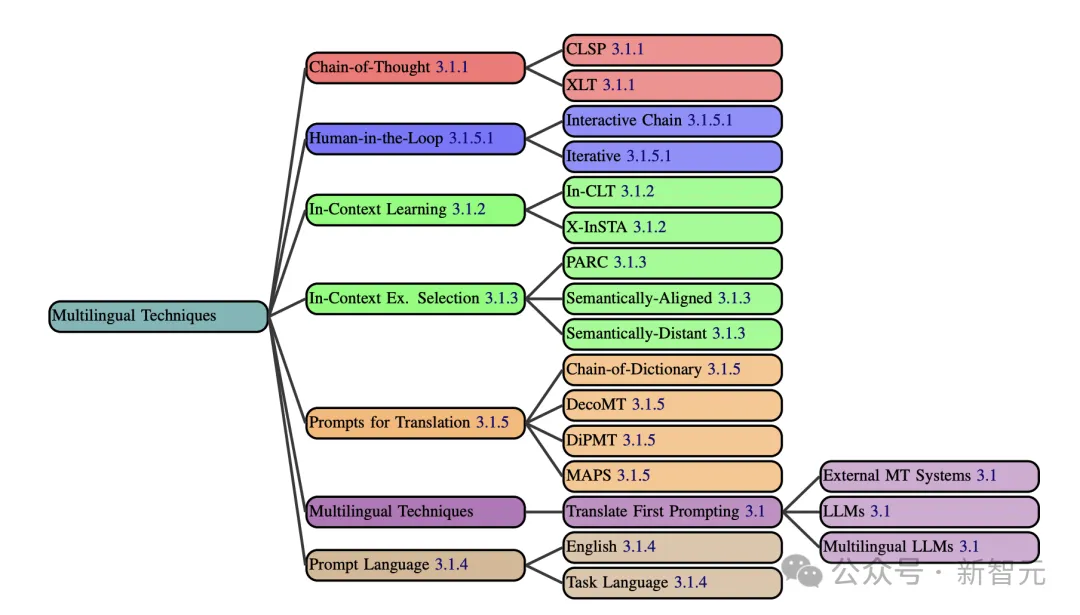
先翻译后提示,是最简单的策略。不过,有些提示技术,要比翻译性能速度来的要快。
比如CoT已经通过多种方法(XLT、CLSP),已扩展到了多语种环境中。

针对上下文学习的策略有:X-InSTA提示,以及跨语言翻译上下文提示(In-CLT)。同时,上下文示例选择对模型多语言性能也至关重要。
因此,需找与源文本语义相似的上下文示例,就成为一项技术活。有研究者曾提出了,PARC(通过跨语言检索增强提示)的方法。
Human-in-the-Loop包含了交互链提示(ICP)以及迭代提示两种方法。
另外,提示模板语言选择会明显影响模型的性能。在多语言任务中,用英语构建提示模板,往往比用任务语言更加有效。
这是由多数LLM在预训练期间,使用了大量的英文数据决定的。

顺便提一句,任务语言提示模板,则是针对特定语言使用情况来使用任务语言提示。
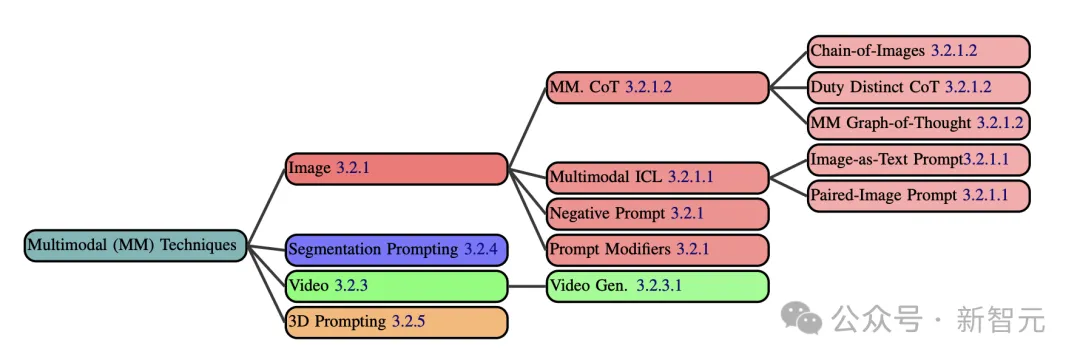
随着GenAI模型的发展,现今也出现了许多多模态提示技术。
比如图像形态的提示,包括照片、图画、屏幕截图等数据。
这个过程中,可以使用负面提示对某些提示中的某些术语进行数字加权,让模型更多或更少地考虑它们。
比如,如果对「错误的手」或「多余的手指」进行负权重,模型更有可能生成解剖学上正确的手。

如今,CoT已经以各种方式扩展到了图像领域。
比如一个简单的例子,就是包含数学问题的图像的提示,同时附有文本说明「一步步解决这个问题」。
另外,还有职责明确的思维链。

上面这道题,要求考虑每对磁铁的磁力,来判断以下陈述哪个是正确的。这个例子证明了,输入理由在多模态推理中是多么重要,以及理由在zero-shot和fine-tuning场景中的不同作用
它可以把从最少到最多的提示扩展到多模态设置,创建子问题,然后解决它们,将答案组合成最终响应。
比如这项任务中,要求模型选出图中的哺乳动物。

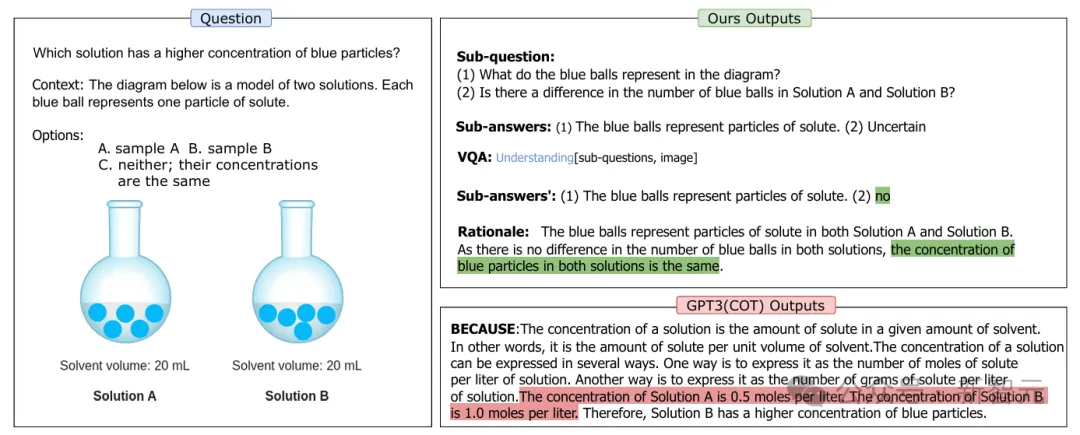
这项任务要求模型回答:哪种溶液中的蓝色颗粒浓度更高?
请问:这种杂交产生的大鼠是侏儒的概率有多大?

多模态思维图则是将Graph-of-Thought扩展到多模态设置中。
在推理时,输入提示会用于构建思维图,然后和原始提示一起使用,来生成回答问题的基本原理。
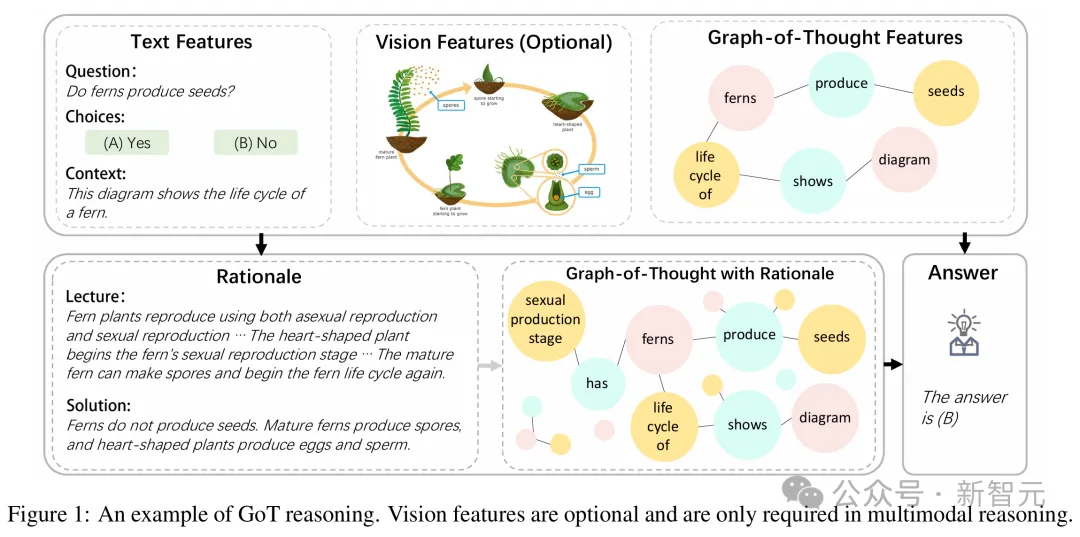
当图像与问题一起输入时,图像标注模型被用来生成图像的文本描述,然后在思维图构建之前,将其附加到提示中,以提供一种视觉的上下文。
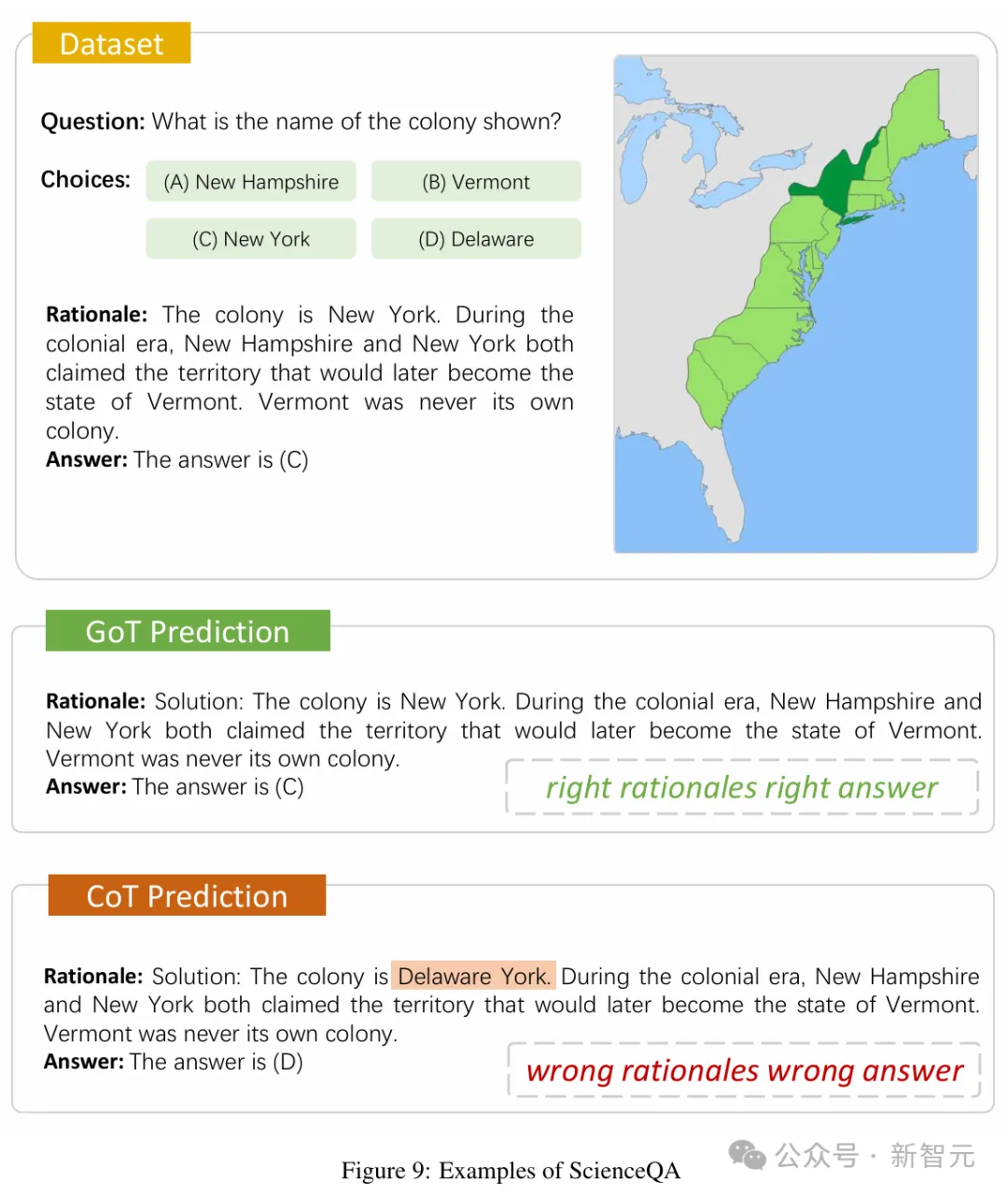

图像链(CoI)是思维链提示的多模态扩展,生成图像是其思维过程的一部分。
用「让我们逐个图像思考」来生成SVG,模型就可以用它进行视觉推理了。

具体来说,CoI的首要步骤,就是逐步生成图像。不过要求SD XL或Dall-E遵循复杂指令生成图像时,他们却遇到了困难。因此,研究者引入符号多模态LLM。当LLM提供各种文本提示时,它将生成不同格式(如SVG格式)的符号表示。

该图展示了SDXL(中)和 DALL-E 3(右)使用原始图像(左)中的标注生成新图像的过程

「一个女人正在等电梯,但电梯里的人却着火了。这种情况会在哪里发生?」
可以看出,在解决相同问题时,与纯文本推理相比,CoI的直觉性更强,能够用视觉常识知识来补充文本中缺失的细节,从而辅助推理过程。

除了图像之外,还有分解提示、视频提示,以及3D提示技术,可以显著提升多模态模型的响应性能。
案例研究:自杀危机综合症(SCS)的标注
在这项研究中,研究人者将提示技术应用于标注Reddit帖子是否表明自杀危机综合症(SCS)的任务。
通过这个案例研究,未来去展示提示工程在现实世界问题中的应用。
对此,研究人员使用了马里兰大学的Reddit自杀倾向数据集,并与一位专家提示工程师合作,记录了他们将F1分数从0提升到0.53的过程。
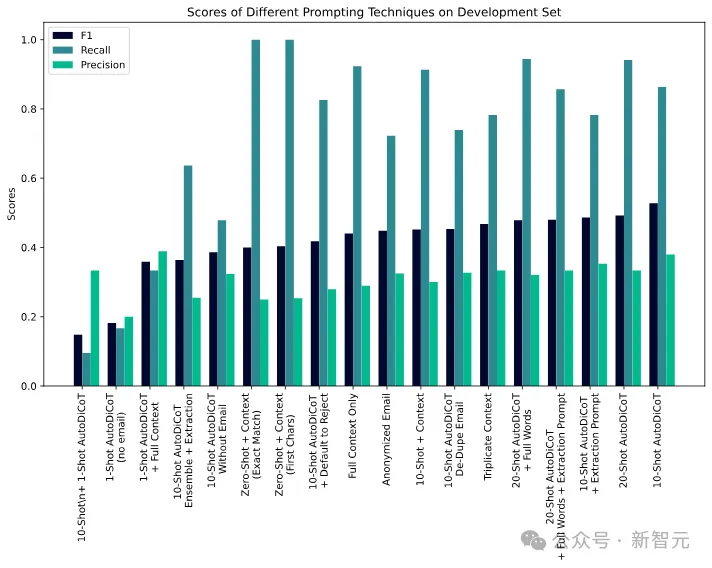
不同提示技术的陷阱分数
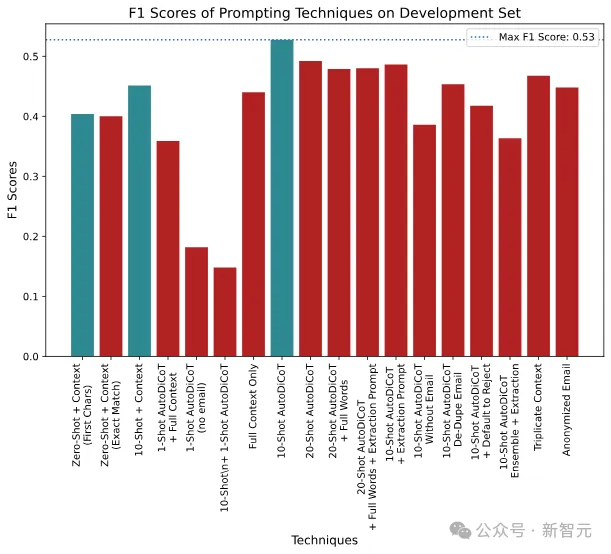
随着提示工程师的开发,不同提示技术的陷阱分数被绘制成图
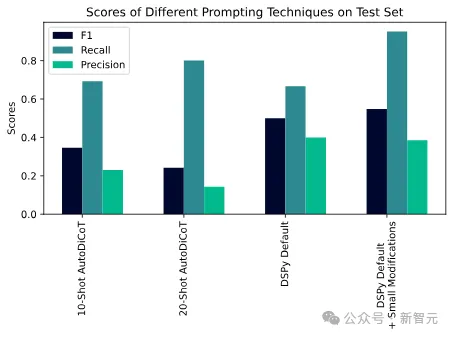
自动化技术(DSPy)能够击败人类提示工程师
PRISMA审查过程
论文的数据收集过程,遵循了基于PRISMA方法的系统审查流程。
首先,通过关键词搜索从arXiv、Semantic Scholar和ACL数据库中抓取数据。其中,包含44个术语,每个术语都与提示和提示工程密切相关。
然后,根据论文标题进行去重,通过人类和AI审查确定相关性,并通过检查论文正文中是否包含「prompt」一词自动删除不相关的论文。

文章来源于“新智元”,作者“新智元”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
