# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
苹果OpenAI官宣合作,GPT-4o加持Siri,让AI个性化生成赛道热度飙升。
其实,国内已有相关研究,一项基于大模型的个性化多模态内容生成技术,直接可让AI学会为用户“量身定制”输出。
例如在聊天软件中生成表情包,输入都是:
我通过了,很开心!
配备了个性化生成技术的聊天软件可以识别当前用户想表达的情绪并考虑用户的个性化偏好,自动生成表情库里没有的多个笑脸猫表情候选供用户点击使用:

相比而言,非个性化生成不会考虑每个用户之前的行为偏好,对用户无差别对待,就没那么懂用户了。
这项最新技术名为PMG(Personalized Multimodal Generation),由华为与清华大学联手打造。

PMG不仅限于即时通信软件,还可以广泛应用于电商、在线广告、游戏、创作辅助等领域,实现个性化背景、人体形态、颜色、表情、角色等内容的生成。
比如根据用户历史偏好提取关键词,生成T恤设计图:
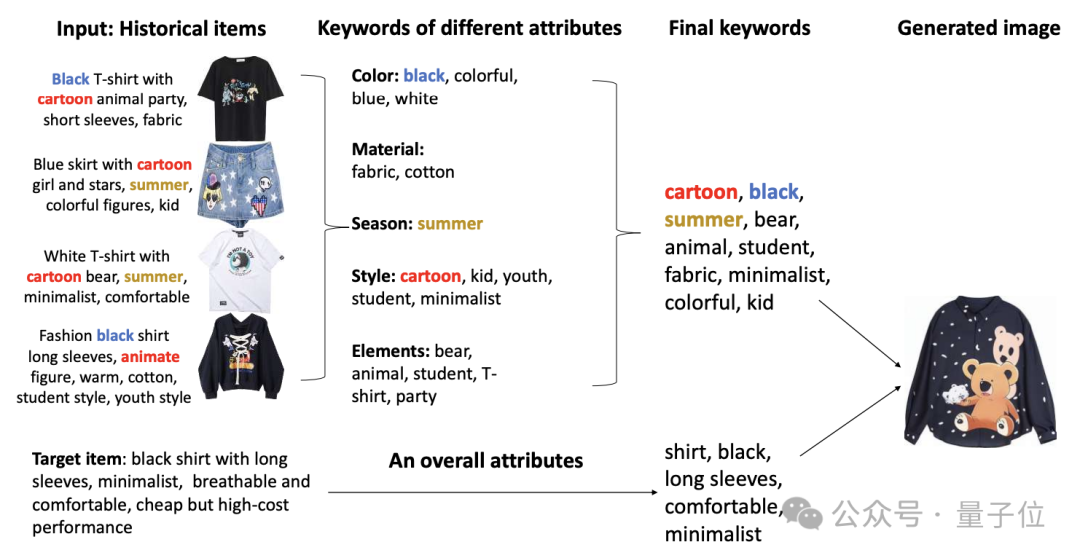
pMG是如何做到个性化生成的?
以个性化生成《泰坦尼克号》电影海报为例,下图展示了PMG的模型结构。

用户的观影和对话历史作为用户历史行为,电影泰坦尼克号真实的电影海报作为目标物品。研究团队利用大语言模型的推理能力,从用户历史行为中提取用户偏好。
具体包括两部分:
同时,他们将目标物品也通过大模型转换为显式关键词(称为“目标物品关键词”)作为目标项的描述信息。
最终,生成器(例如扩散模型或多模态大语言模型)通过整合和加权用户偏好和目标项关键词来生成既反映用户个性偏好、又符合目标物品的多模态内容,例子中为更具有灾难、惊悚风格的泰坦尼克号电影海报。
整个过程中有三个关键技术点:关键词生成、隐式向量生成、用户偏好和目标项的平衡。
下面我们逐一来看。
首先需要构造提示词指导大模型将用户偏好提取为关键词,该提示词主要包含三个组成部分:任务指令p、属性ai和任务示例e。
这些组件是针对每个场景人工设计的。
其中,任务指令p描述了需要大语言模型执行的任务,即“提取用户偏好”。
属性a=[a1,a2…]针对每个场景进行了定制,例如对于服装可以是“颜色、材质、形状”,对于电影可以是“类型、地区、导演”等等。
在每个问题中,大语言模型被指派回答与特定属性相关的用户偏好,并将这些答案进行组合。
示例e提供了期望的输出格式和示例关键词(例如“可爱”、“卡通”等),不仅有助于指导模型的回答,还使其遵循了标准化的输出格式,从而便于从生成的输出中提取关键词。利用这个提示,可以将模型为属性ai生成的用户偏好关键词kpi表示为:
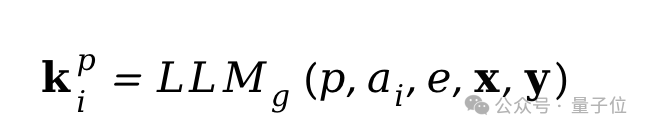
接下来,将每个属性的输出组合起来,并消除重复项,得到用户偏好关键词kp:
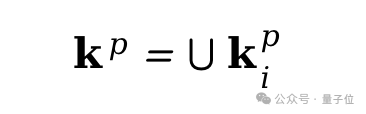
生成目标项目关键词kt的过程类似,但只有一个目标交互物品ht和相应的总结信息xt,同时在这种情况下,没有涉及到对话,其生成过程可以表示为:
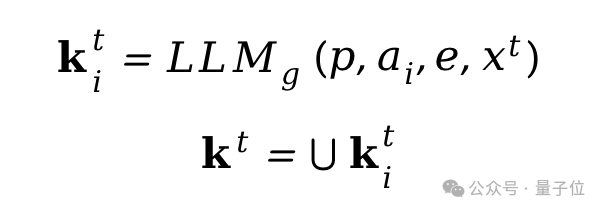
利用提取出的用户偏好关键词kp和目标项关键词kt,已经可以用于后续多模态内容生成,然而,作为一种离散化形式,自然语言表达能力有限。
另一方面,利用连续的隐向量能提供更丰富和精确的表示却需要大量的训练资源。因此我们采取以关键词为主,隐向量为辅两者结合的方式表征用户偏好,这些用户偏好向量有助于解决自然语言与实际用户偏好之间的不匹配问题,其训练过程如图3所示。
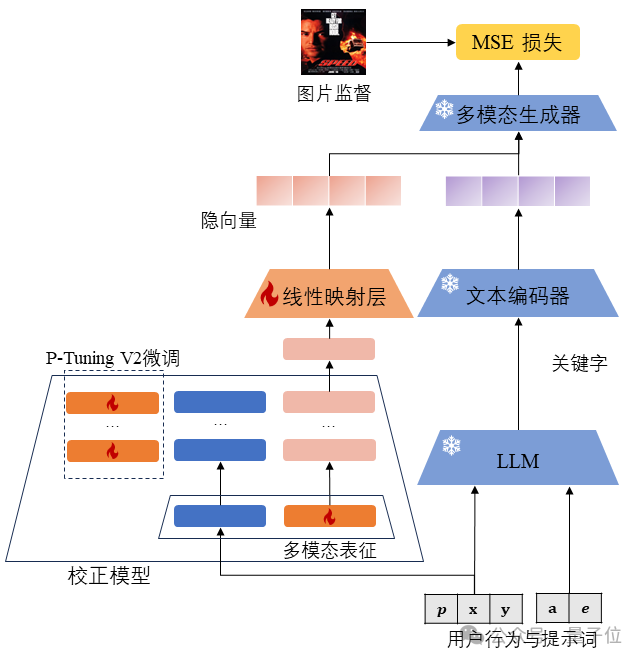
在用户行为与提示词的基础上,研究团队引入P-Tuning V2微调的偏差校正大模型,在其中使用额外长度为L的多模态表征M=[m1,m2…mL]来学习多模态生成能力。
这些多模态表征会被传递给大语言模型,并且它们在向量层中的对应参数是可训练的。
同时按照P-Tuning V2的方法,在每个Transformer层的自注意力机制中,将S个可训练的前缀向量t=[t1,t2…tS]前置到向量序列中。偏差校正大模型正向传播操作的结果输出向量可以表示为:
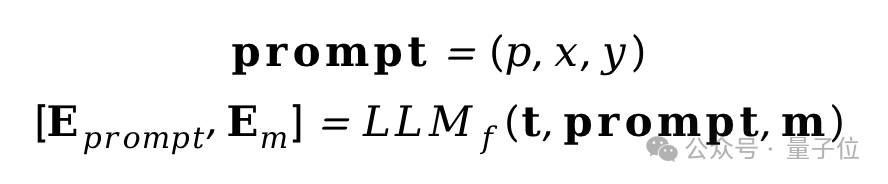
其中Eprompt和Em表示大语言模型的两部分输出,其中多模态表征的输出Em被作为偏好隐向量用于后续多模态内容的生成过程。生成器结合偏好隐向量、用户关键词生成的多模态内容会与监督信号计算MSE损失,并反向传播到偏差校正大模型中的可训练参数中进行训练。
在生成推理过程中,需要同时结合用户偏好和目标项。
然而,生成器往往具有较大的随机性,简单地组合可能导致对某一个条件的过度侧重,而忽略了另一个条件。为了解决这一问题,研究团队使用生成内容与偏好关键词之间的相似度来衡量个性化程度,称之为“个性化水平”。
同样地,生成结果与目标项关键词的相似度称为“准确度”,即目标契合指标。
通过这两个指标,可以从两个角度量化衡量生成效果。
这两个指标的计算方式为利用预训练的多模态网络(如CLIP),将生成结果M和关键词kp、kt转换为向量eM、ep、et,计算它们之间的余弦相似度,作为个性化水平dp和准确度dt。
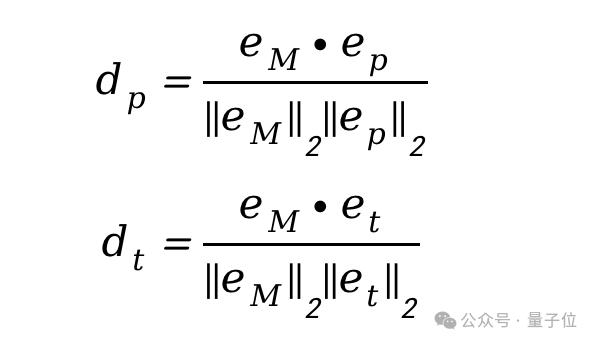
最后,优化目标为最大化dp和dt的加权和:
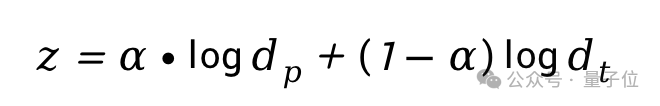
超参数α通常设置为0.5,可以根据使用场景和需求进行调整,以实现不同程度的个性化。
考虑到当前多模态生成器具有强大的并行生成能力,研究团队使用多个预定义的权重集合wp、wt进行生成,并选择得分z最高的一个作为最终生成结果。
研究团队通过以下三个应用场景来验证PMG:
使用Llama2-7B作为基础的大模型进行了实验,生成效果如下图所示。
在每个场景中,PMG都能够生成反映用户偏好的个性化内容。
它可以为男性和女性生成不同风格的服装图片:

为喜欢卡通片的观众生成卡通版电影海报:

为喜欢小动物的用户生成小猫表情包:

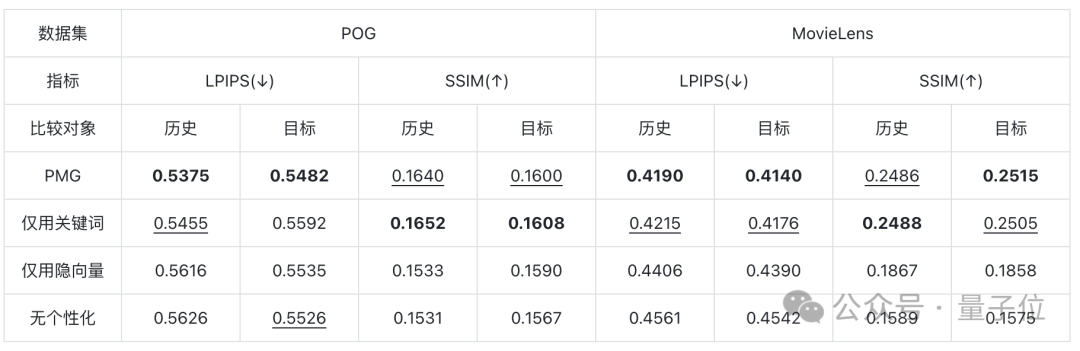
研究人员使用POG和MovieLens数据集对服装和电影海报这两个场景进行了量化评估。
评估方式是通过图像相似度指标LPIPS和SSIM计算生成结果与用户交互历史以及与目标物品图像之间的相似度,从而衡量其个性化程度以及与目标物品的符合程度。
PMG在这两个指标上都表现出色,测试结果如下表:
此外,研究人员展示了对偏好隐向量的Case Study分析。
如下,左图为仅使用关键词生成,右图为同时使用关键词和隐向量进行生成。

研究团队通过用户调研对该技术进行了评估,结果显示,PMG生成的内容得分远高于非个性化生成内容。
最后,团队表示,个性化多模态生成技术目前处于早期探索阶段,近期重量级的OpenAI与苹果Siri合作的核心竞争力之一就是通过Siri的用户数据来让AI生成加入个性化,个性化多模态生成技术将成为AI的关键热点趋势。
我们相信这项技术将在未来拥有广阔的应用前景和巨大的商业潜力,很快迎来爆发式增长。
文章来源于“量子位”,作者“星海”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
