# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文作者肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,Robert Bamler 是图宾根大学机器学习方向的教授,Bernhard Schölkopf 是马克思普朗克-智能系统研究所的所长,刘威杨是马普所剑桥大学联合项目的研究员。

论文地址:https://arxiv.org/abs/2406.04344
在传统的机器学习场景如分类和回归问题中,给定训练数据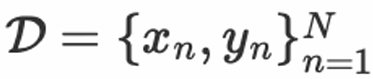 ,我们通过优化参数
,我们通过优化参数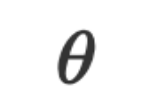 学到一个函数模型
学到一个函数模型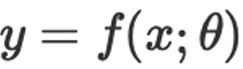 来准确描述训练集和测试集中
来准确描述训练集和测试集中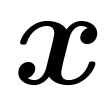 和
和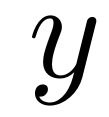 的关系。其中
的关系。其中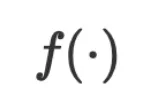 是基于数值的函数,它的参数
是基于数值的函数,它的参数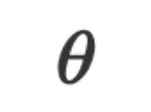 通常是连续空间中的数值向量或矩阵,优化算法通过计算数值梯度迭代更新
通常是连续空间中的数值向量或矩阵,优化算法通过计算数值梯度迭代更新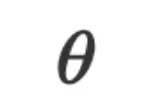 从而达到学习的效果。
从而达到学习的效果。
与其用数值,我们是否能用自然语言来表示一个模型?这种基于自然语言的非数值模型又该如何做推理和训练?
Verbalized Machine Learning (VML;言语化的机器学习) 回答了这些问题,并提出了一种基于自然语言的机器学习全新范式。VML 把大语言模型 (LLM) 当作自然语言空间中的通用近似函数 (universial function approximator) ,数据
,数据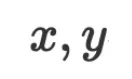 和参数
和参数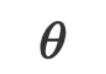 都是自然语言空间中的字符串。在做推理时,我们可以将给定的输入数据
都是自然语言空间中的字符串。在做推理时,我们可以将给定的输入数据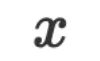 和参数
和参数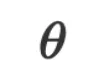 提交给 LLM,LLM 的回答就是推理的答案
提交给 LLM,LLM 的回答就是推理的答案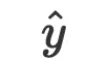 。
。
对于任意任务和数据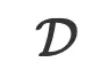 ,我们如何得到
,我们如何得到 ?在基于数值的传统机器学习中,我们通过计算损失函数的梯度,将现有的模型参数往损失下降的方向更新,从而得到
?在基于数值的传统机器学习中,我们通过计算损失函数的梯度,将现有的模型参数往损失下降的方向更新,从而得到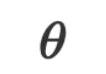 的优化函数:
的优化函数:
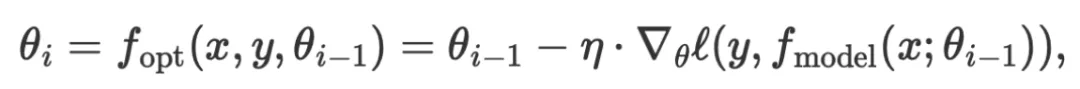
其中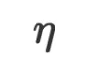 和
和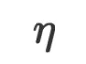 分别为学习率和损失函数。
分别为学习率和损失函数。
在 VML 的设定中,由于数据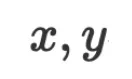 和参数
和参数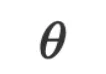 都是字符串且 LLM 被当作是黑箱的推理引擎,所以我们无法通过数值计算来优化
都是字符串且 LLM 被当作是黑箱的推理引擎,所以我们无法通过数值计算来优化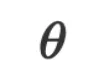 。但既然我们已经将 LLM 用作自然语言空间中的通用近似函数去近似模型函数,而
。但既然我们已经将 LLM 用作自然语言空间中的通用近似函数去近似模型函数,而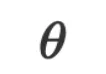 的优化器
的优化器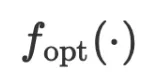 也是一个函数,我们为何不也用 LLM 去近似它?因此,言语化的
也是一个函数,我们为何不也用 LLM 去近似它?因此,言语化的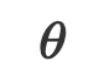 优化函数可写作
优化函数可写作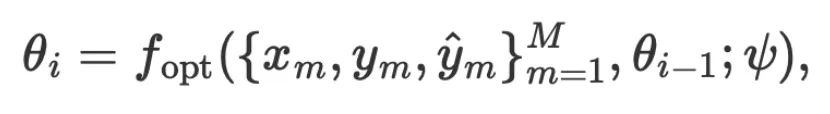
其中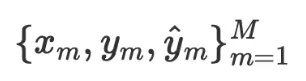 为一个数量为
为一个数量为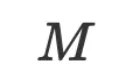 的批次的训练数据和模型预测结果,
的批次的训练数据和模型预测结果,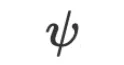 为优化函数的参数(同为自然语言)。
为优化函数的参数(同为自然语言)。

图 1:VML 的训练算法。
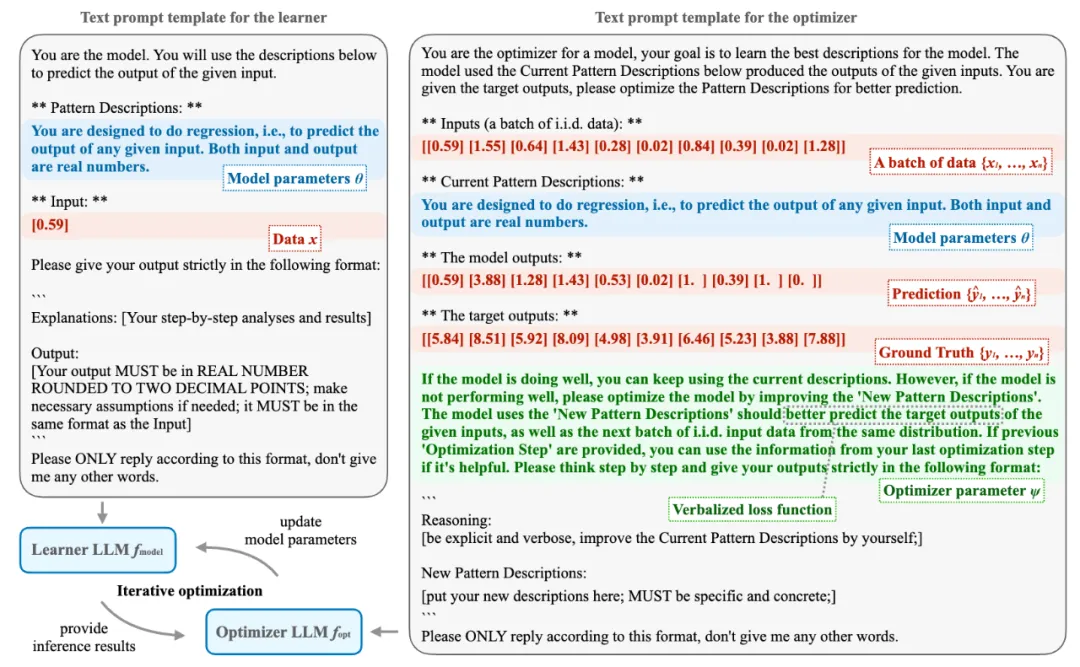
图 2:VML 中模型和优化器的自然语言模版样例。
图 1 显示了 VML 的完整算法。可以看见其跟传统机器学习算法基本相同,唯一的区别是数据和参数是在自然语言空间里的字符串, 以及模型 和优化器
和优化器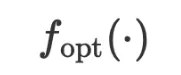 都是通过 LLM 在自然语言空间中进行推理。图 2 为回归任务中模型
都是通过 LLM 在自然语言空间中进行推理。图 2 为回归任务中模型 和优化器
和优化器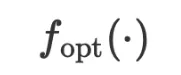 的具体模板样例。
的具体模板样例。
跟传统机器学习比,VML 的优势包括:(1)用自然语言简单的描述就可以对模型加入归纳偏置 (inductive bias);(2)由于不需要预设模型的函数族 (function family),优化器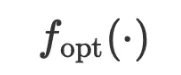 可以在训练过程中自动对模型的函数族进行选择;(3)优化函数对模型参数的每一步更新都会提供自然语言的解释,同时模型的描述和推理也是自然语言且可解释的。
可以在训练过程中自动对模型的函数族进行选择;(3)优化函数对模型参数的每一步更新都会提供自然语言的解释,同时模型的描述和推理也是自然语言且可解释的。
实验展示
多项式回归
如图 3 所示,模型的初始参数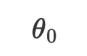 为线性回归的定义。在第一步优化时,优化器说它发现
为线性回归的定义。在第一步优化时,优化器说它发现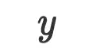 比
比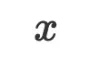 有更大的值域,且它们似乎存在正相关性,所以它决定将模型更新为简单的线性回归模型。
有更大的值域,且它们似乎存在正相关性,所以它决定将模型更新为简单的线性回归模型。
在第二步优化时,优化器说当前模型的不良表现让它意识到线性模型的假设过于简单了,同时它发现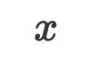 和
和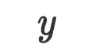 之间存在非线性关系, 因此它决定将模型更新为二次函数。
之间存在非线性关系, 因此它决定将模型更新为二次函数。
第三步优化时,优化器的关注点从函数族选择转换成二次函数的参数修改。最终模型学到了真实函数很接近的结果。
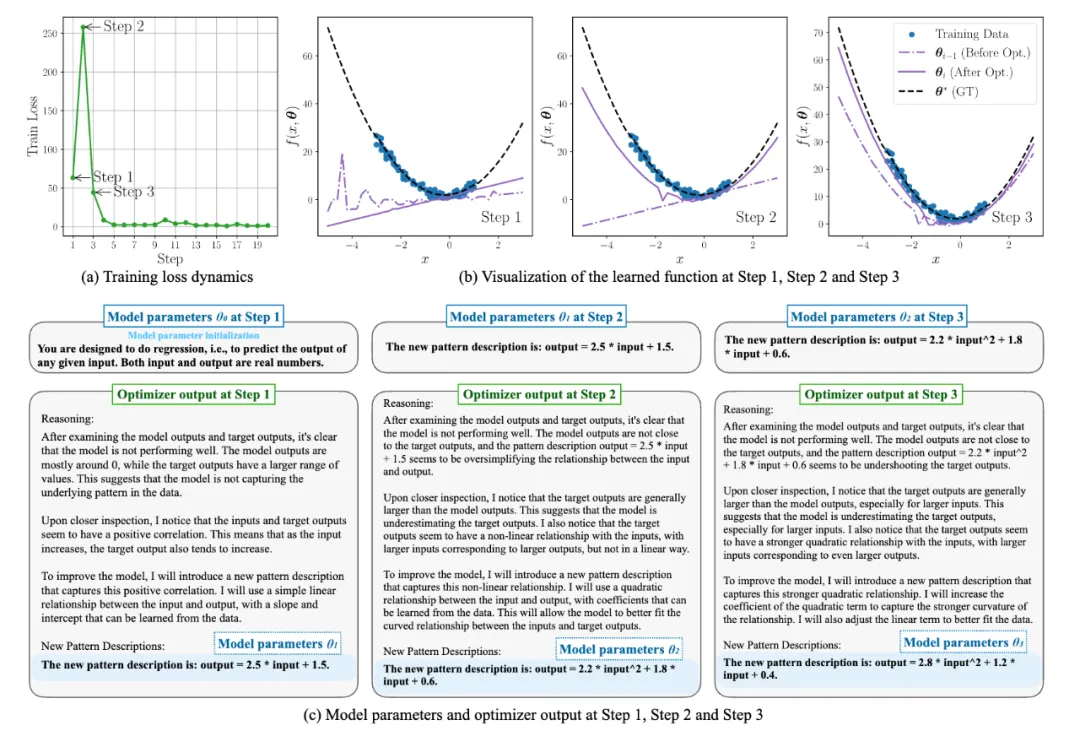
图 3: VML 在多项式回归任务中的训练过程记录。
非线性二维平面分类
如图 4 所示,模型的初始参数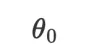 为二维平面二分类的定义,同时用了一句话「决策边界是个圆」加入归纳偏置。在第一步优化中,优化器说它基于提供的先验,将模型更新为了一个圆方程。接下来的优化步骤中,优化器都在根据训练数据调整圆方程的圆心和半径。直到第四十一步,优化器说当前模型似乎拟合得很好了,于是停止了对模型的更新。
为二维平面二分类的定义,同时用了一句话「决策边界是个圆」加入归纳偏置。在第一步优化中,优化器说它基于提供的先验,将模型更新为了一个圆方程。接下来的优化步骤中,优化器都在根据训练数据调整圆方程的圆心和半径。直到第四十一步,优化器说当前模型似乎拟合得很好了,于是停止了对模型的更新。
同时,我们也可以看见在不加归纳偏置的情况下,VML 也能学到一个基于决策树的不错的模型,但相比之下训练损失的波动更大。
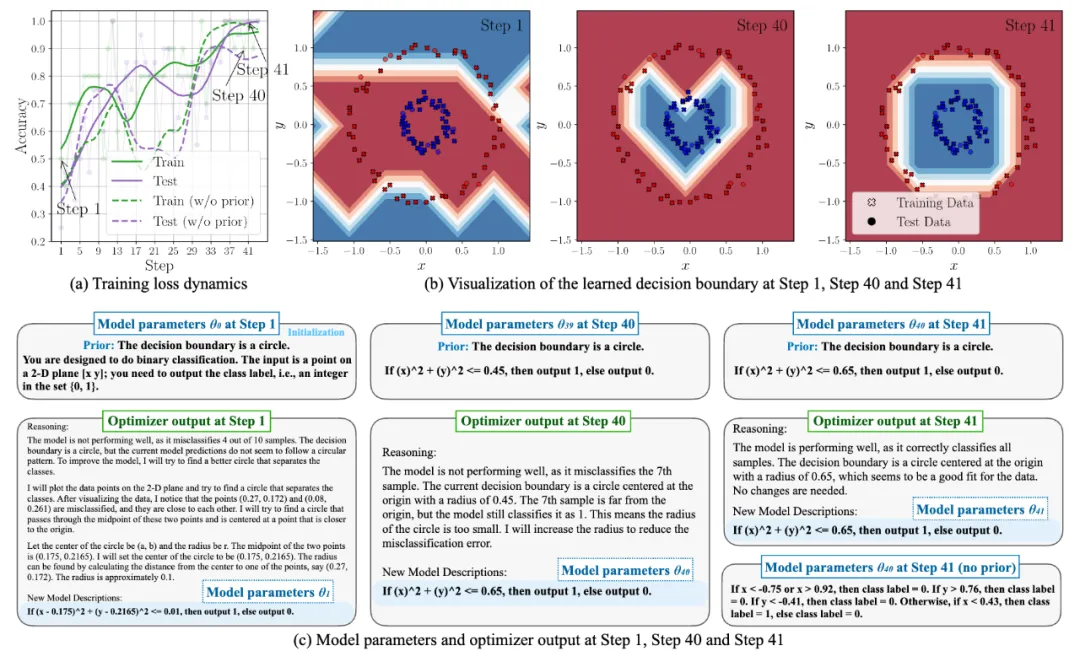
图 4: VML 在非线性二维平面分类任务中的训练过程记录。
医疗图像二分类
如果大模型接受多模态输入,如图片和文字,那 VML 也可以用在图片任务上。这个实验中,我们使用了 GPT-4o 和 PneumoniaMNIST 数据集,做了一个 X 光片肺炎检测的任务。
如图 5 所示,我们初始化了两个模型,模型的初始参数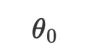 都为图片二分类的定义, 但其中一个添加了一句话「输入是用于肺炎检测的 X 光图片」的归纳偏置作为先验。在训练了五十步后,两个模型都达到了 75% 左右的准确度,其中有先验的模型准确度要稍微高一点点。
都为图片二分类的定义, 但其中一个添加了一句话「输入是用于肺炎检测的 X 光图片」的归纳偏置作为先验。在训练了五十步后,两个模型都达到了 75% 左右的准确度,其中有先验的模型准确度要稍微高一点点。
仔细观察第五十步后的模型参数,我们可以看到加了归纳偏置的模型描述中包含了很多与肺炎相关的医学词汇,比如「感染」、「发炎」;而没有加归纳偏置的模型描述中只有对肺部 X 光片的特征描述,比如「透明度」、「对称」。
同时,这些模型所学到的描述,都是可以被具备专业知识的医生验证的。这种可解释和人工检验的机器学习模型在以安全为重的医疗场景下十分有价值。

图 5: VML 在 PneumoniaMNIST 图片二分类上的训练记录。

该文章介绍了一种基于大语言模型的机器学习新范式 Verbalized Machine Learning (VML; 言语化的机器学习),并在回归和分类任务上展示了 VML 的有效性和可解释性的特点。
文章来源于“机器之心”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
