# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作为创新工场联合创始人,汪华见证了移动互联网的全过程,以及当下 AI 的兴起。
「大家还是太焦虑了,大模型从开始到现在才一年多时间,整个的应用发展,本质上还是要随着模型的成熟和整个应用生态的构建逐渐发展。」对于当下的 AI 创业焦虑,汪华如此回应道。
「再过四五年,一定会有很多 AI 时代的成功创业者涌现出来。」
AI 的投资在向应用侧迁移、大模型的推理成本会持续下降、国内还正处于 ChatGPT Moment 的第一阶段,以及 AI 应用爆发需要哪些前提、AI 应用开发需要具备的能力等等,在 AGI Playground 2024 上,创新工场管理合伙人 & Co-CEO 汪华就这些话题,进行了一场干货信息满满的 AGI 创业攻略分享。

过去一年,大家在基础模型算力里面投了大量的资源和金钱,结果都把英伟达弄成了市值世界第一的公司了。
有很多同学跟我交流,有焦虑感,觉得在算力上花了这么多钱,但应用却没有爆发。那到底什么时候应用能爆发?将来应用到底能不能起来?
我先介绍下我的背景。创新工场应该是国内最早投资移动互联网企业的。我记得在 2010 年的时候,就跟大家宣传移动互联网应用一定会起来。我们也是国内、世界上最早投资 AI 的。
2012 年 AlexNet 发表的时候,我们就投资了旷视。2015 年 Google AlphaGo 火了之后 AI 还开始流行,我们在那之前就投资了旷视、第四范式,包括自动驾驶的地平线、 Momenta。我在 2020 年开始投资大语言模型,所以我完整的经历了整个移动互联网从 2010 年开始的应用崛起,以及 AI 的崛起。
我相信再过四五年,也会有很多在 AI 时代取得成功的创业者涌现出来。
先说一下海外,过去一年全球大量的投资投在 AGI 和大模型身上,将近有 200 亿美元。但是去年大部分投资,还是集中在算力、算法基础设施和底座模型上,投在应用里的钱只占一小部分。

但今年,事情开始发生变化。从 Q2 开始,投在应用上的金额比去年都有翻倍。大家可能觉得今年的投资冷下去了,但实际上投资开始集中在应用上了,尤其是 Q2 的投资比 Q1 有了更大幅的增长,甚至 Perplexity 融到了两三亿美元的投资,获得 30 亿美金的估值。大量跟应用模型相关的,比如音乐生成的 Suno 也快速拿到了融资。

可以明显地看到,整个投资开始从底座模型和 AI 侧向应用侧进行迁移。与此同时,到去年为止大部分的应用还是 ToB 的,ToC 也是以生产力为主,但是今年开始,大量的 C 端应用开始爆发,不仅是生产力和效率类的应用,偏娱乐社交的应用也开始批量涌现,从 ToB 延伸到 ToC,从生产力和效率延伸到综合的社交娱乐和其他的多模态等各个领域。
我觉得大家还是太焦虑了。
大模型从开始到现在才一年多时间,整个的应用发展,本质上还是要随着模型的成熟和整个应用生态的构建逐渐发展。未来应用要扩展,在我看来有四个前提:模型性能、推理成本、模型的模态、应用生态整体的演进与完善。

大家要做应用,需要按照这四个象限,来规划当前做什么,未来做什么。超前来做的话,可能会比较难和麻烦。
首当其冲的是推理成本。AI 最重要的一点并不仅仅是 AGI 的实现,而是普惠化。AGI 就算实现了,如果无法实现普惠化,跟在座的各位也没有任何关系。
以当年的 PC 计算机为例,IBM 曾经说全世界只要 7 台电脑就行,这里的电脑指 Mainframe computer 大型主机,只用在银行、金融部门这些大型的关键企业里面。微软实现了把每台 PC 放在每个办公桌上,给社会价值和产业生态带来了巨大的拓展。而直到手机把每部「个人电脑」装到了每个人的口袋里,才真正的影响了整个社会,从吃喝玩乐到衣食住行。
普惠,实际上要看模型的推理成本。为什么大部分的应用到现在为止还是以 ToC 或者生产力为主?因为哪怕用 GPT-4 做复杂的生产力应用模型,性能还是有挑战性的。现在 GPT-4 做社交娱乐、衣食住行消磨时间,性能是足够用的,但为什么大家宁愿去做生产力或者 ToB 呢?

因为推理成本实在太贵。
GPT-4 的推理成本在十几美金,这种情况下,必须要做所谓的高价值用户场景,而且要从用户侧收费。
做生产力,对模型性能有挑战的应用才能收到钱,但是模型性能不足;如果做社交娱乐,使用模型的成本又太高。所以现在的 AI 应用被卡在中间,两边都有点不沾。
只要模型性能成本降下来,事情就会不一样。
在我的判断里,到今年年底左右,模型的推理成本可以比年初降 10 倍。到了明年,大概明年年底的时候,模型的性能推理成本会降到现在的 100 倍。大家可以想象一下,如果推理成本降到现在的 1%,GPT-4 级别的模型推理成本降到几美分的话,大体量的应用、免费的应用甚至不光是生产力赛道,娱乐类、社交类、消磨时间类的应用都可以得到大规模的 普及。
但是模型成本下降的前提是「模型性能够用」。现在大家会意识到很多应用为什么做不出来,是因为模型对于复杂指令的遵循能力不行。你设想了一个很好的场景,但是模型的失败率特别高,做不出来。
哪怕是做社交娱乐的应用,用 GPT-4 level 的模型跟用便宜的开源模型,用户的留存、使用时长也可以差出两三倍。所以到现在为止,做很多的应用。GPT-4 级别的模型的性能和体验是底线。甚至 GPT-3.5 这个级别的模型,在很多应用里面是不够用或者没法用的,哪怕是做 C 端应用。
随着模型性能的提升越多,能够解锁的应用类型也越多。
第三个就是模态了,现在的模型模态以文本为主。如果要做 C 端应用的话,大家可以看到,当年移动互联网应用的今日头条的日活和使用时长远远比不上 TikTok。如果交流模态仅限于文字的话,做 C 端应用会非常受限。当你能够解锁更多模态,能够解锁的类型就能解锁的更多。
这三个前提是跟模型完全相关的,要做应用的话,必须要根据当下的模型和接下来一年内的模型是否能达到这三个前提,再决定自己做什么。这跟当年的移动互联网还是不一样,必须要跟着整个模型的技术栈往前走。
最后一个,一个新平台的出现是需要几年时间的。
一是完成用户群的扩散,二是完成对于产品交互和新产品体系的探索。任何一个新的应用出来,第一波用户都不是下沉用户,而是先导用户,比如学生、科技爱好者、科技从业者。之后两三年时间逐渐下沉到年轻用户,最后下沉到普通用户。
二是产品交互也需要时间探索,比如 2010 年的时候跟大家说将来所有的应用,吃喝玩乐、看视频、购物等都可以在手机上完成,但当时大家做的事情都是把 YouTube、优酷、土豆原封不动地搬到手机上。TikTok 出现的时候,已经到了 15、16 年了。

移动应用最终的产品形态并不是把优酷、土豆或者 YouTube 直接搬到手机上。从内容源、产品交互来看,最终的版本答案——短视频的形态是花了 4-5 年才慢慢摸索出来。
相比起 PC 和移动互联网的区别,AI 的应用本身,正确的交互形态到底是什么,其实跟之前可能差别会更大,需要开发者和应用者花一点时间。我觉得(这个时间)会比当年移动互联网更快,但也要 take time,可能也得花两到三年的时间,让大家真正去探索 AI-Native 的产品交互和形态应该是什么样子的。
所以应用的爆发并不会一蹴而就,是这四个维度决定了 AI 应用发展的节奏和顺序。这里面最大的前提是高性能模型的成本下降。
但最近也有一些好消息。
GPT-4o,包括刚出的 Claude 3.5,其实已经在很多大规模的 ToC 应用里够用了。大家不用担心将来 AGI 能不能做到,或者 GPT-5 的性能到底够不够好,现在的 GPT-4o、 Claude 3.5 哪怕性能没有太大提升,维持现在的性能,已经足够支持大量的应用了。
模型成本的下降其实只是一件工程的事情,是一件确定的事情。比如零一万物本身也是在做很多模型推理成本下降的探索。到今年年底、明年年初,会推出接近 GPT-4o 级别性能的大模型,售价会降到现在的 1/10,百万 token 降到几块钱人民币。到明年年底的话,数字还可以再降一个数量级。
这是非常确定的一件事,主要有几个原因。

首先是模型结构、算法和硬件 Infra 本身,在接下来的半年到一年每个都可以实现 4-5 倍的提升;用于推理优化的硬件成本可以降 4-5 倍,模型结构的优化和特化可以提升 4-5 倍;算法侧的优化可以提升 3 到 4 倍。所以这些乘起来的话,差不多能在明年年底实现 100 倍的模型成本下降。
其实现在已经看到一些很好的信号了。比如前段时间一些大厂非常卷模型价格,号称把百万 token 的推理成本降到了一块钱、两块钱甚至更低。当然这个还是不太够,因为目前大家卷的价格还是比较低性能的模型,真正高性能模型的成本还没有降。但这个事情会在半年之后很快发生。半年后,高性能模型的价格也会从现在的二三十块钱降到几块钱人民币。
现在,国内的模型还都是文字模态的,多模态并不强。到今年年底,真正的全模态模型都会出来。起码零一万物今年年底、明年年初的模型,就会是一个接近于 GPT-4o 的完整多模态,并且推理成本会降得非常低。其他几家国内企业明年上半年应该也都能做到。对于开发大体量应用而言,实际上是切实可行的。
我把这些定义为一个普惠点,对于开发者来说,最重要的点是「普惠点什么时候能到达?」「随着普惠点的达到,大家能解锁什么东西?」
我觉得最大的普惠点就是推理成本降到 1%,这意味着几千万日活、上亿万日活,甚至免费的产品可以大规模的实现。实际上,推理成本哪怕降到 1/10,也已经有很多的应用可以提前出现了。
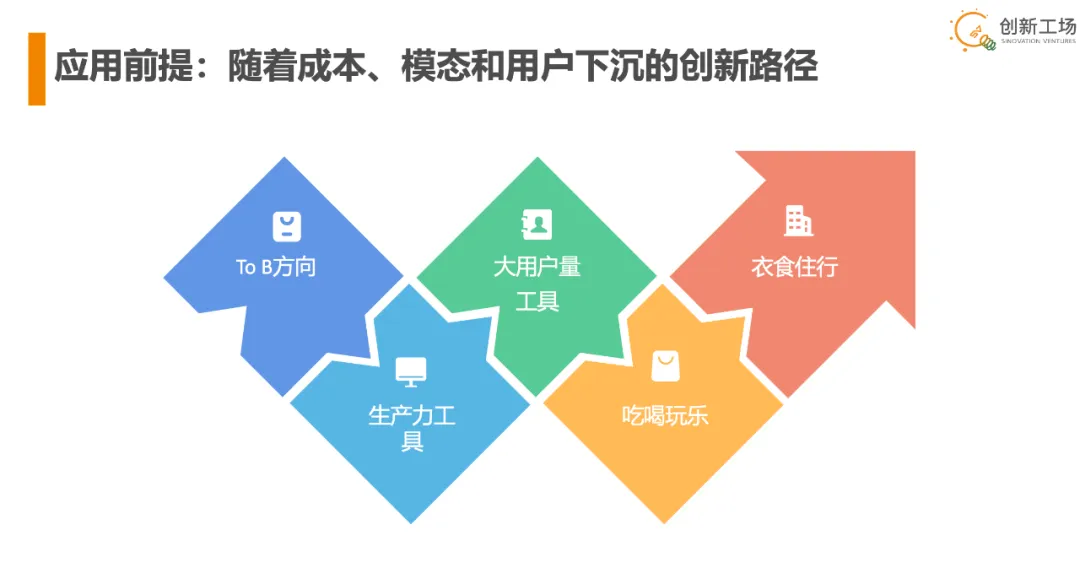
随着多模态和推理成本的相继突破,ToB 会先实现,因为它对价格的承受能力最高,对模态的需求最低。其次是生产力工具,大体量的工具型应用,只要推理成本降 10 倍,就能实现大体量免费。
举个简单例子,互联网时代,搜索是典型的工具型应用。当年移动互联网搜索类的工具用户使用时间短,消耗的 token 少,我在 Google 的时候,用户的平均使用时长是两三分钟,不超过五分钟。
ChatGPT 作为通用工具,用户平均时长是七八分钟,但我看过很多做社交娱乐的创业公司,他们的平均使用时长超过 150 分钟。推理成本只要降 10 倍,工具类的应用就可以做大体量免费。推理成本降得更低,高时长娱乐性的应用才能做到大体量免费,所以大用户量的工具,我觉得今年年底到明年年初就会实现。
再往后是衣食住行,这个会比娱乐性的应用更晚一些,因为它涉及到人类的交易生活。这类应用一是需要更高的模型性能,二是需要商业模式整合,比如做今日头条只需要处理信息,但是做电商就需要整合供应链、整合资源、建立商业模式。从吃喝玩乐到衣食住行,这个时间周期个人认为在 3-4 年之内走完。
移动互联网大概从 2008 年苹果出 App Store 开始,大概花了六七年的时间。我觉得大模型时代的话,整个 AI 的节奏会比移动互联网更快,大概 3-4 年把这个顺序走一遍。
那我们现在可以做什么?
一个好消息是,现在中美的模型对比来看,中国的模型已经有足够多的能力。去年大家做应用的时候,要么只能做出海,因为出海有 OpenAI 的 API 或者别的特别好的模型可以调用。但在国内如果合法做应用的话,国内去年模型的性能的确是不够的。

但从最近开始,中国模型的性能已经足够强了。比如零一万物的 Yi-Large 已经达到了 GPT-4 的级别。千问、智谱的模型也已经跟 Llama-3 非常接近。
对于做应用的来说,用中国本土的模型跟用美国的已经没有什么太大差距了。当然多模态中国比美国还是落后一点,但也就是半年的时间,而且我相信在中国比较卷的情况下,中国同等性能模型还可以做到更加便宜。有了这个基础,接下来中国就可以复刻应用爆发的状态了。
中国的整个应用层因为模型能力的拖累,当然也包括很多对于应用和大模型本身的监管,大致的节奏比美国慢差不多一年的时间。美国现在的情况是,他们的应用已经到了第二波发展阶段,在去年上半年已经完成了第一波在知识工作人群里面的应用普及,达到大几千万的日活。ChatGPT 不光完成了对于用户认知的普及,美国现在百分之七八十的白领工作者和知识工作者已经将各种 AI 工具囊括进日常使用工具的范畴。现在已经到了百花齐放,扩展应用类型的第二阶段。

中国实际上处于美国上半年第一阶段的应用爆发前期。虽然最近大家看到很多产品在大量推广,用户量也在迅速增长,但是把所有应用加在一起,日活也不过就是 1000 万,中国有 12 亿网民;而美国 3 亿人口就有大几千万的日活,相比之下还有很大的差距。
但好处是,最近无论什么样的应用,虽然用户基数很小,差不多都是小几百万日活的状态,但增速都很高。目前大多数中国人都知道 AI,听说过 AI,只不过用上 AI 的很少,就算用上的也只是偶尔尝鲜式地使用,并没有像美国的那些知识工作者一样把它当做工作伴侣来使用,就意味着中国现在的增长潜力非常大。
我预判今年年底到明年年初,在效率工具类的 ToC 应用里面就会出现千万级日活的单应用。明年上半年,中国也会完成类似于美国 ChatGPT 的第一波普及。客观地讲第一波用户还是会集中在学生、科技从业者、科技爱好者、白领知识工作者这样的先导人群中。应用类型的话,大多数会从工具效率起步,慢慢往社交娱乐、杀时间多模态的方向去扩展。
再说说对创业者的建议,因为我平时也投资应用,见过非常多的创业者。
第一我觉得,大家还是太焦虑了,我经常看到同一波创业者两极分化,一个大新闻出来了之后,大家非常兴奋,觉得 AGI 要实现了。过了几天又突然很焦虑,说应用怎么到现在还没有爆发,投资是不是趋冷了或者怎么样。其实移动互联网从 2008 年 APP Store 到整个应用形态出产,都已经是 12、13 年的事情了,甚至到 13 年李彦宏还说移动互联网是新瓶装旧酒。所以大家不要太焦虑,要真正把时间、心思沉浸到用户场景开发里面去,不要焦虑于一周、两周、一月这种短时间的外部变化。

我看到过两种创业者,一种是商业产品出身,一种是技术科研出身。从长期来讲,做 AI 应用,要既懂产品又懂技术。因为 AI 大模型创业跟当年移动互联网创业有一个很大的不同,移动互联网当年创业的时候虽然是一个新平台,但整个后台技术是成熟的,无论是成本、技术栈,还是端侧的开发,都有当年 PC 互联网 10 年的积淀。只要能想得到对的用户场景,从技术上、成本上说没有做不出来的。

但是大模型的创业本身更接近于 1999 年 Google 做搜索的年代,想做一个很容易让人全搜整个互联网的产品,场景很简单就想出来了,关键是能不能做得出来?Google 为了做这个东西,当年开发了 PageRank、集群,MapReduce 等一套技术才实现最初场景。
我看到商业产品出身的开发者有时候会过于宏大叙事,过于不考虑产品模型的限制去做产品。对于技术科研出身的开发者的话,往往是太追求于技术圣杯,不考虑算力成本的花效,对整个场景考虑得比较少。对于这两种创业者,我的建议是两边都要考虑对方的优点,在现阶段不成熟的时候更脚踏实际,落足场景。而且哪怕是技术出身的创业者,也不要过于追求技术圣杯。更加现实点,结合起来讲就是仰望星空脚踏实地。

Google 的创业者就是典型的技术出身的创业者,他们当时要做搜索,高价的服务器买不起,所以只能手搓服务器,就是为了把成本降下来。最早的服务器都是他们从电脑店里面买回来自己攒出来的。杨致远做 Yahoo 时候也是非常脚踏实地,大家都知道 Yahoo 第一个产品是一个网址站,并没有过于追求技术。产品出身的创业者哪怕你做不了 Google,你也可以想办法做 Yahoo,做不了 Larry Page,也可以做杨致远。
张一鸣是一个我觉得在两者之间结合得非常好的创业者。他既懂技术,当时还是机器学习——第一代的 AI,要用推荐算法来重塑内容行业。但另外一方面又特别脚踏实地,在移动互联网早期的时候,除了今日头条,它还做了内涵段子或者其他大量产品矩阵来去获取早期流量,这些成功专业者早年都是非常脚踏实际的,无论是从技术出身的,还是从产品商业出身的。
最重要的是在现有模型和技术成本的限制下,真正落实深挖用户场景。因为什么都变了,但是人性和用户场景并没有变化。有时候跟创业者交流,发现大家对这件事做的还是不够的。
接下来确定的是,智能上限、多模态、 AI Agents 这三个都会在今年年底到明年会有很大的升级。

年底的话,GPT-4.5 或者 GPT-5 会有一个渐进式的改良,模型的智能上限真正要出现跨代级别的体验可能还是要等到明年年底,但今年年底在模型的指令遵循和复杂能力上会有不错的提升。多模态的话今天还是 GPT-4o,到了明年我们会实现理解和生成真正统一的多模态。
AI Agents 现在是一个痛点,主要是在复杂指令遵循,现在 AI Agents 还是一个玩具,ToB 的应用大家都只能做 Copilot。但大家真正想要的是 Autopilot,我个人感觉这个还是有机会工程实现的。
然后再到具身智能,等到 AI Agents 和多模态、智能上限都实现了之后,模型不只是在数字空间,而是通过 Robotic 传感器在物理世界里实现智能和交互。将来大家做 APP 就不是做数字世界的 APP,而是在做物理世界的 APP 了。
接下来就有两个奇点。

第一个基点是非常确定的普惠奇点,二十四个月内成本降到 1%,亿级别日活的应用因此可以实现。以 4- 5 年为周期的话,推理成本会降到现在的 1‰,那时候就不存在 AI 应用了,因为所有的应用都会用 AI 重塑交互和后端的实现。

第二阶段是智能奇点,这个并不是特别确定。有可能模型的性能达到 GPT-5 级别之后就会到一个软天花板,但即使这样,并不影响第一个阶段的普惠奇点。如果模型性能能继续通过 Scaling Law 突破 GPT-5,达到复杂指令遵循,达到 PHD 级别的思维能力,那就不是我说的普惠奇点概念了,可能会对整个人类世界实现重塑。
智能奇点在 4-5 年之内就可以看到端倪,如果能实现,3-4 年之内就能实现,如果 3-4 年之内实现不了,那这一代基于 Transformer 和 Scaling Law 的整一代技术就实现不了。
最后说一下,创新工场从 2012 年就开始大力投资 AI,在应用和 AI(技术)都有非常丰富的经验。所以如果各位想在 AI 领域创业的话,欢迎来创新工场和我交流。
文章来自于微信公众号“Founder Park”,作者 “Founder Park”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
