# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
日前,旷视科技发布了一项新的开源 AI 人像视频生成框架 ——MegActor。基于该框架,用户只需输入一张静态的肖像图片,以及一段视频(演讲、表情包、rap)文件,即可生成一段表情丰富、动作一致的 AI 人像视频。MegActor 所生成的视频长度,取决于给定的驱动视频的长度。与阿里 EMO、微软 VASA 等最新涌现的 AI 视频模型不同,旷视 MegActor 将采用开源的方式,提供给开发者社区使用。MegActor 能够呈现出丝毫毕现的效果,面部细节更加丰富自然,画质更出色。
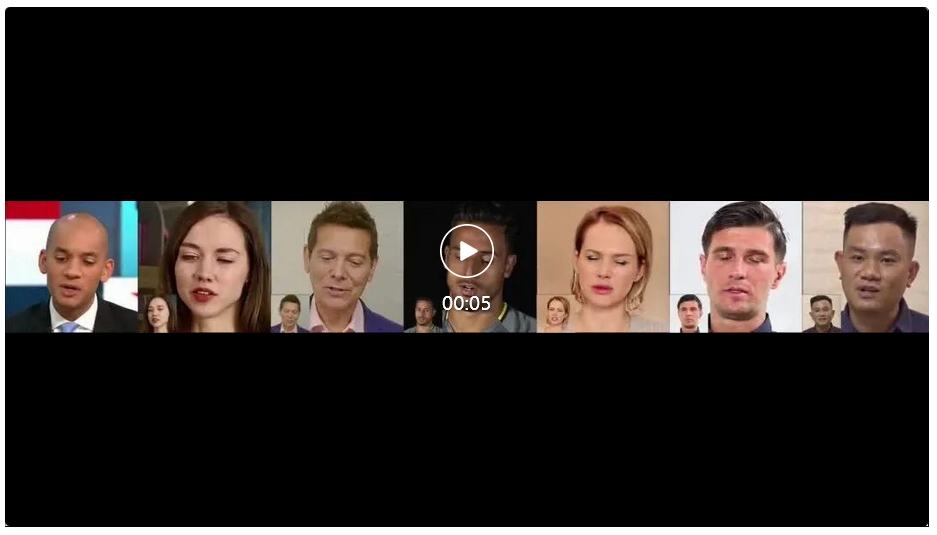

为了进一步展示其泛化性,MegActor 甚至可以让 VASA 里面的人物肖像和它们的视频彼此组合生成,得到表情生动的视频生成结果。


即使是对比阿里 EMO 的官方 Case,MegActor 也能生成近似的结果。




总的来说,不管是让肖像开口说话,让肖像进行唱歌 Rap,还是让肖像模仿各种搞怪的表情包,MegActor 都可以得到非常逼真的生成效果。

MegActor 是旷视研究院的最新研究成果。旷视研究院,是旷视打造的公司级研究机构。旷视研究院旨在通过基础创新突破 AI 技术边界,以工程创新实现技术到产品的快速转化。经过多年发展,旷视研究院已成为全球规模领先的人工智能研究院。
在目前的人像视频生成领域,许多工作通常使用高质量的闭源自采数据进行训练,以追求更好的效果。而旷视研究院始终坚持全面开源,确保实际效果的可复现性。MegActor 的训练数据全部来自公开可获取的开源数据集,配合开源代码,使得感兴趣的从业者可以从头开始完整复现这些令人惊艳的效果。
为了完全复刻原始视频的表情和动作,MegActor 采用了原始图像进行驱动,这与多数厂商使用 sketch、pose、landmark 的中间表示皆然不同,能够捕捉到细致的表情和运动信息。
旷视科技研究总经理范浩强表示,在 AI 视频生成领域,我们发现目前主流的骨骼关键点控制方式不仅要求用户提供难以获取的专业控制信号,同时生成视频相较于原肖像的保真程度也不尽如人意。通过一系列研究发现,使用原视频进行驱动,不仅将帮助用户降低控制信号的门槛,更能生成更加保真且动作一致的视频。
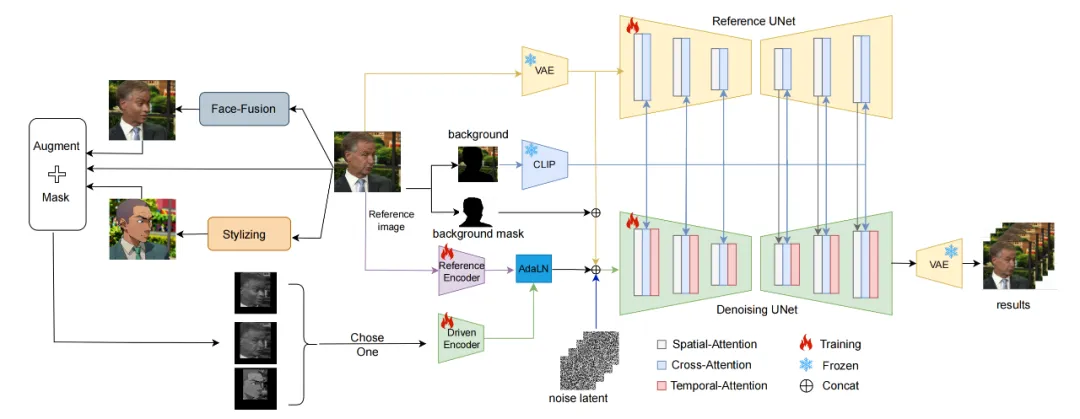
具体来说,MegActor 主要由两个阶段构成:
尽管相较于使用音频或 landmark 等表示方式,使用原始视频进行驱动能带来更加丰富的表情细节和运动信息。然而,使用原始视频进行驱动依然存在两大核心技术挑战:一是 ID 泄露问题;二是原始视频中的背景和人物皱纹等无关信息会干扰影响合成表现。
为此,MegActor 开创性地采用了条件扩散模型。首先,它引入了一个合成数据生成框架,用于创建具有一致动作和表情但不一致身份 ID 的视频,以减轻身份泄露的问题。其次,MegActor 分割了参考图像的前景和背景,并使用 CLIP 对背景细节进行编码。这些编码的信息随后通过文本嵌入模块集成到网络中,从而确保了背景的稳定性。
在数据训练方面,旷视研究院团队仅使用公开的数据集进行训练,处理了 VFHQ 和 CeleV 数据集进行训练,总时长超过 700 小时。同时,为了避免 ID 泄露问题,MegActor 还使用换脸和风格化方法 1:1 生成合成数据,实现表情和动作一致、但 ID 不一致的数据。此外,为了提高对大范围动作和夸张表情的模仿能力,团队使用注视检测模型对数据进行处理,获取大约 5% 的高质量数据进行 Finetune 训练。
通过采用一系列新的模型框架和训练方法,旷视研究院团队仅使用了不到 200 块 V100 显卡小时的训练时长,最终实现的具体特性包括:
与音频生成的方法相比,MegActor 生成的视频,不仅能确保表情和动作一致,更能达到同样的自然程度。
目前,MegActor 已经完全开源,供广大开发者和用户即开即用。
文章来自于微信公众号“机器之心”,作者 “机器之心”




【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
