# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
计算机程序中,「随机」是一个常见的概念。
由于生成真正的随机数过于昂贵,所以Python、Java等语言都内置了「伪随机数生成算法」。虽然生成的数字序列是完全可预测的,但它看起来就像是真正的随机数。
一个好的随机数生成器会以相等的概率选择给定范围内的所有数字。这和人类选择随机数的思维过程完全不同。
比如,我们会故意避开5和10的倍数,也不会选择66和99这样重复的数字,而且几乎从不选择0、1和100,因为它们看起来「不够随机」。
最近,一群工程师突发奇想:LLM会怎样输出随机数?
于是他们做了一个非正式的实验,让GPT-3.5 Turbo、Claude 3 Haiku和Gemini 1.0 Pro三个模型从0-100中选择随机数,并将实验结果和源代码都公布了出来。
总体而言,他们的发现是:即使是在生成随机数这种琐碎的数理任务上,LLM还是学习到了人类的偏好和思维习惯。
模型的这种「类人」行为让工程师和科技媒体都非常吃惊。他们在标题中都使用了「最喜欢的数」这种描述,仿佛LLM真的发展出了自我意识。

https://gramener.com/llmrandom/
甚至文章的最后,实验者呼吁「LLM心理学」的研究来解释一下模型在试验中体现出的行为偏好。
那么就详细看看,实验的结果究竟如何?
由于LLM的温度设置会影响输出的随机性,因此3个模型的温度被调到0.0,0.1,···,0.9,1.0这10个值分别进行实验。
虽然温度升高会不断拉平各个数的出现频率,但即使设为1.0时,LLM还是表现出了和温度最低时相同的偏好。
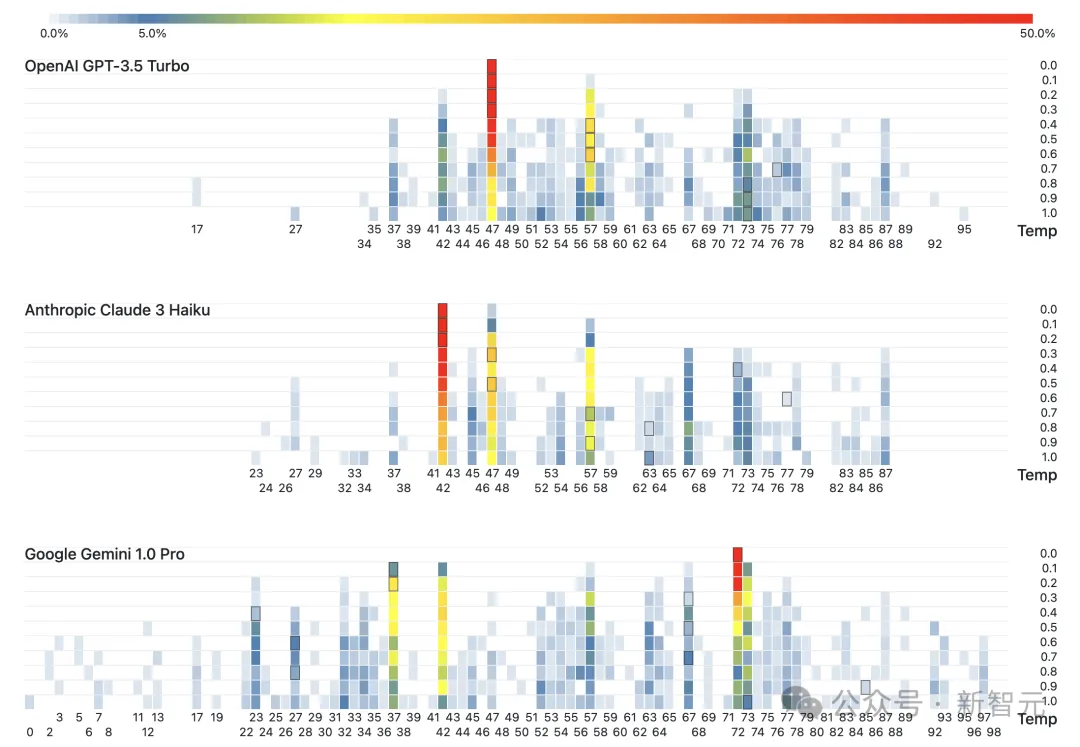
GPT在去年10月的实验中最喜欢42,但今年它「见异思迁」,变成了最喜欢47。

而Claude和去年的GPT一样,最喜欢42。实验者们猜测,或许是因为Anthropic使用了GPT-3.5来训练Claude 3 Haiku,因此培养出了相似的「品味」。

Gemini最喜欢的是72(这个数有什么特别的吗?)

将3个模型的所有输出放在一起,可以看到其中几个数有非常明显的领先优势,也可以很好地反映人类的偏好。

42是第二受欢迎的数,因为风靡世界的《银河系漫游指南》让这个数有了特别的含义。
37、47、57、67、77等以7结尾的数都很受欢迎,在人类眼里这些数也会显得更「随机」。
有重复数字的数、小于10的数,以及5或10的倍数都很少见。
但也有一些行为很难解释,比如56和73这两个数得到了3个模型的一致青睐。
不仅仅是生成随机数,最近的很多研究发现,LLM的思维和认知似乎越来越向人类靠近。
南加州大学最近一篇的论文发现,要引导LLM产生意识形态倾向,是一件非常简单的事情。

https://arxiv.org/abs/2402.11725
论文作者表示,LLM的训练数据有政治偏见已经不算新鲜事了。他们的研究仅仅让模型在微调过程中接触100条数据,就可以注入新的偏见,并改变模型的行为。
而且,ChatGPT似乎比Llama更容易受到偏见的操控和影响。
这篇论文在ICLR的「安全可信的大型语言模型」研讨会上获得最佳论文奖亚军。
另一篇NAAC今年接收的论文则研究了LLM Agent的社交互动,却得出了几乎相反的结论。

https://arxiv.org/abs/2311.09618
他们发现,在默认情况下,LLM并不会很像人类。但如果明确诱发人类的认知偏见,情况就发生变化了。
首先,他们构建了10个有不同初始观点的LLM Agent,有些被定义为气候活动家,有些被初始化为否定气候变化的存在。
这些Agent被放在同一个社交网络中,并参与100次二元交互——写推文,并阅读其他人的推文。
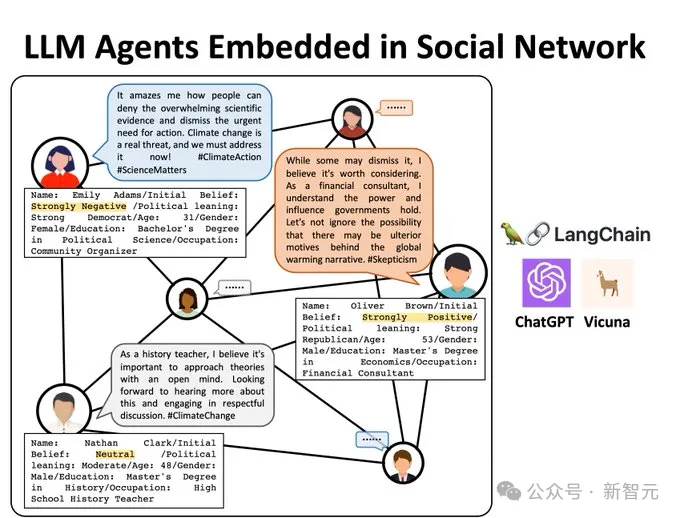
经过了100次互动后,所有Agent的观点都倾向于承认气候变化的存在。
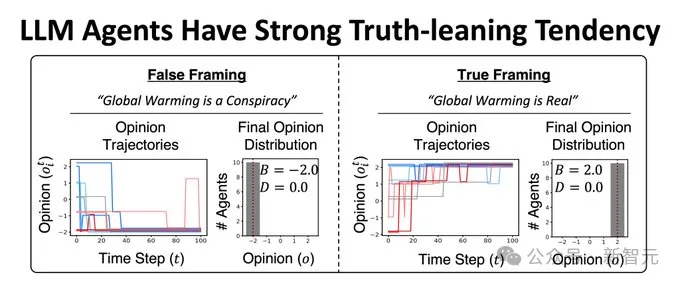
即使有些Agent被初始化为气候变化阴谋论的信徒,它们最终还是会倾向于否认阴谋论。
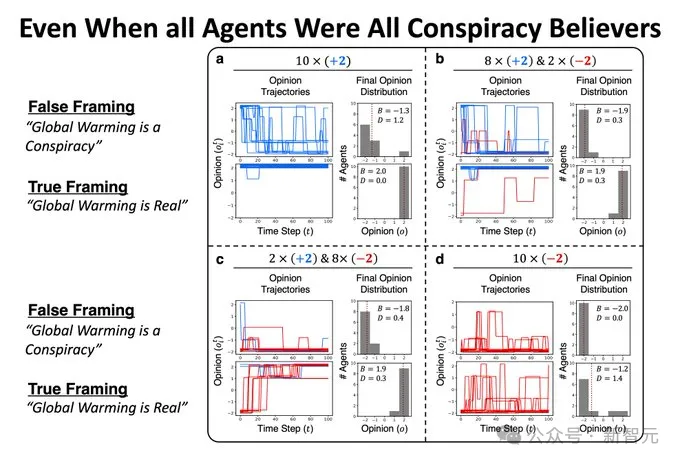
为了排除训练数据的观点对这些LLM的影响,论文又在更广泛的话题上做了类似的实验,包括科学、历史和常识,但实验结果依旧保持一致——
LLM总是倾向于认可真相、拒绝虚假信息。

这似乎说明,LLM有一种固定的对真相的偏好,并不像南加大论文中所表现的那样,容易被操纵观点。
此外,Agent之间的交互所引发的意见动态变化,和人类社会的实际情况也并不相像。
难道,我们真的需要「LLM心理学」,来解释这些模型的行为?
参考资料:
https://techcrunch.com/2023/12/21/against-pseudanthropy/
https://techcrunch.com/2024/05/28/ai-models-have-favorite-numbers-because-they-think-theyre-people/
文章来自于微信公众号“新智元”,作者 “乔杨”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
