# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
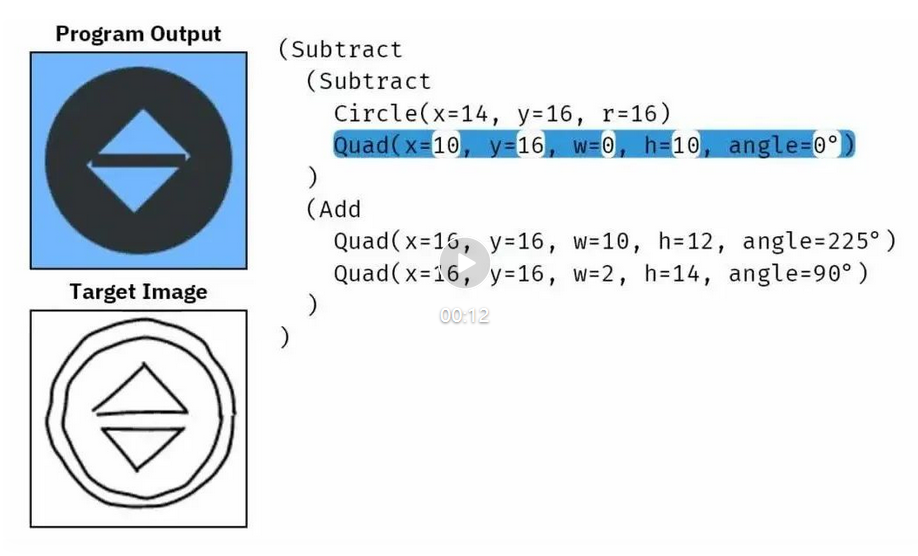
假设我们给模型一张手绘的「5」状图形,它就能通过不断突变来修改程序,最终得到能输出目标图形的程序。
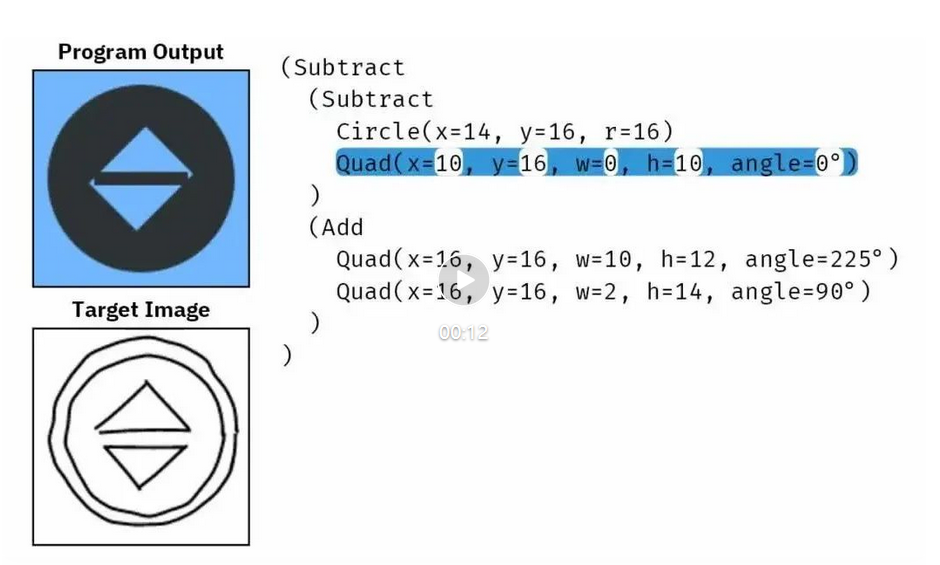
该模型来自加州大学伯克利分校的一个研究团队,他们提出的这种程序合成新方法使用了神经扩散模型来直接操作句法树。
论文一作为该校博士生 Shreyas Kapur,其导师为该校计算机科学教授 Stuart Russell。

扩散模型之前已经在图像生成领域取得了巨大成功。而该团队发现,通过利用扩散机制,可让模型学会迭代地优化程序,同时确保句法有效性(syntactic validity)。这种新方法的关键在于可让模型观察程序在每一步的输出,从而实现有效的调试流程。
迭代的能力已经在 AlphaZero 等系统中得到了体现,而扩散机制的迭代性质也就很自然地会被用于基于搜索的程序合成。
该团队发现,通过在训练扩散模型的同时训练一个价值模型,就可以引导其中的去噪过程得到能输出所需结果的程序。这样一来,便能高效地探索程序空间,在生成过程中的每一步都做出更明智的决策。
为了实现该方法,该团队选择了逆向图形任务(inverse graphics task),即假定使用特定领域的语言来绘制图像。
该团队表示:「逆向图形任务天然就适合我们的方法,因为代码中的一点微小改变就能导致所得图像出现有意义的语义变化。」
举个例子,如果图像中出现了一个放置错误的图形,那就能被轻松看见并定位到程序空间中。图 1 给出了一些示例。
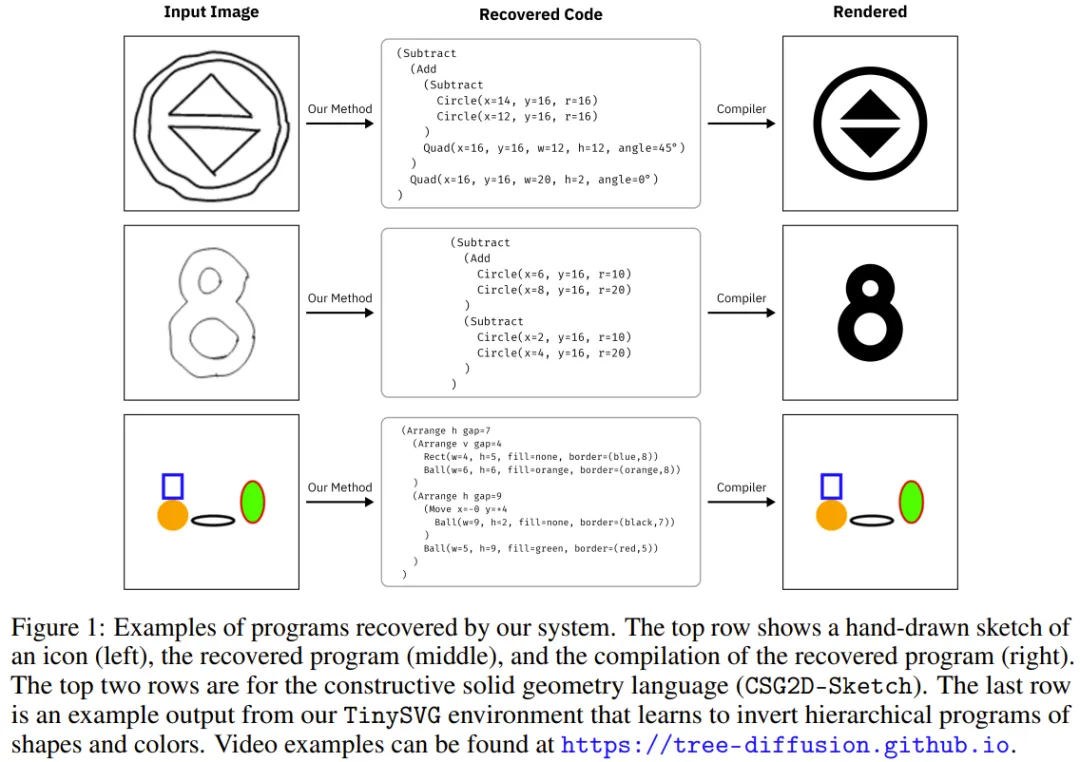
这项研究的主要贡献包括:
1. 提出一种在句法树上使用扩散的全新方法
2. 针对逆向图形任务实现了该方法,并发现新方法优于之前的方法。
简而言之,该方法的核心思想是:为句法树开发一个去噪扩散模型,类似于为视觉任务开发的图像扩散模型。
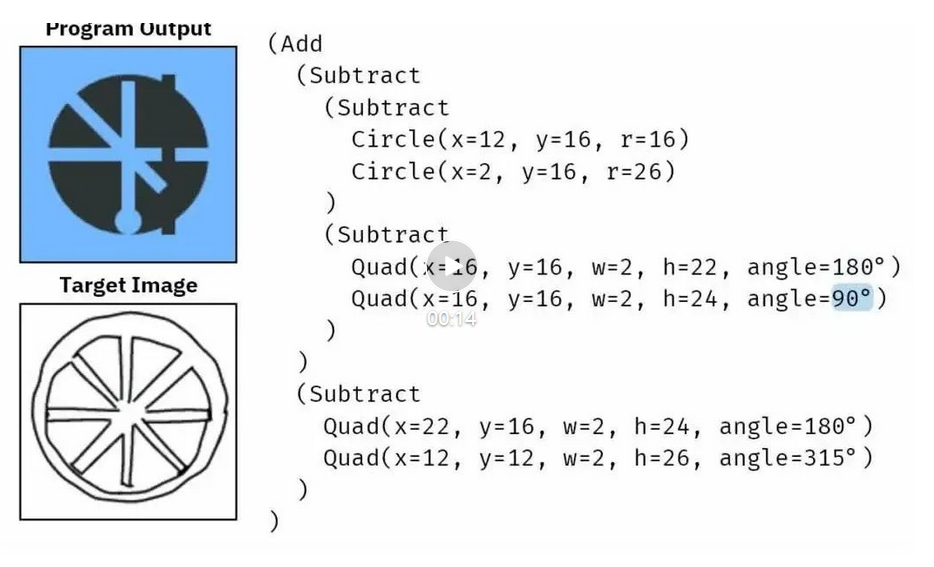
首先来看一个来自 Ellis et al. 论文《Write, execute, assess: Program synthesis with a repl》中的任务示例:根据图像生成一个构造实体几何(CSG2D)程序。使用 CSG2D,我们可以使用加法和减法等布尔运算将圆和四边形等简单的原语组合起来,从而能使用下面的上下文无关语法(CFG)创建出更复杂的形状:
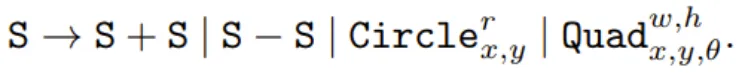
在图 2 中,z₀ 是目标程序,x₀ 是 z₀ 渲染过的版本。
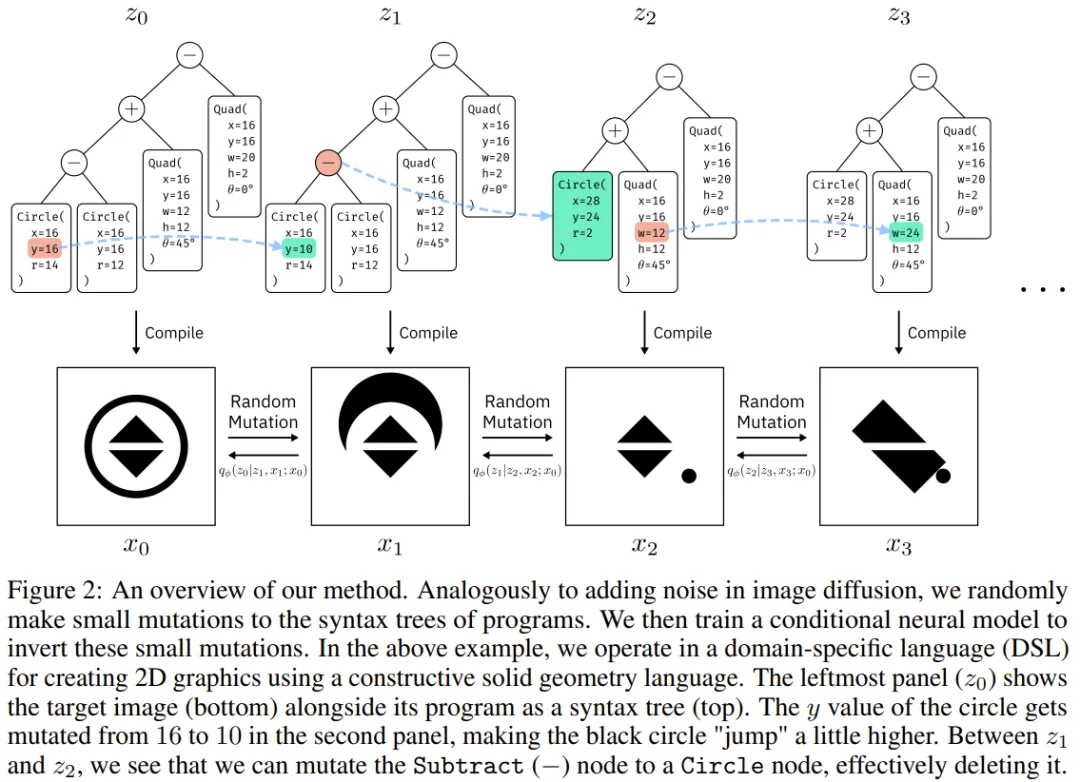
任务就是逆转 x₀,从而恢复得到 z₀。首先,去噪过程将 y=16 随机突变为 y=10。然后再将左侧有两个形状的子树转变成只有一个形状的新子树。这里的目标是基于图像 x₀,从 z₃ 和 x₃ 开始,训练一个能逆向该去噪过程的神经网络,从而得到 z₀。
下面首先将介绍如何将「噪声」添加到句法树中,然后将详细描述如何训练逆向该噪声的神经网络,最后将描述如何使用该神经网络来执行搜索。
令 z_t 为时间 t 时的程序。令 p_N (z_{t+1}|z_t) 为将程序 z_t 随机突变成 z_{t+1} 所基于的分布。这里希望 p_N 突变满足两点:(1) 很小,(2) 能得到句法有效的 z_{t+1}。
为此,该团队探究了大量有关基于语法的模糊测试的计算机安全文献。为了确保突变很小,他们首先定义了一个函数 σ(z),其能给出程序 z 的「大小」。在实验中,则是将 CFG 中的一组端点(terminal)定义为原语。
举个例子,如果用他们的 CSG2D 语言来写,上述原语就为 {Quad, Circle}。使用该语言时,该团队的做法是让 σ(z) = σ_primitive (z),这能统计原语的数量。σ(z) 还可能包含深度、节点数量等选项。
然后,基于精确的约束条件 σ_min < σ(z) ≤ σ_max 从 CFG 随机采样程序。该函数被命名为 ConstrainedSample (σ_min, σ_max)。为 σ_max 设定一个较小的值就能随机采样小程序。在生成小突变时,设定 σ_max = σ_small。
为了让给定程序 z 发生突变,首先可在其句法树中生成一个在某个 σ_small 范围内的候选节点集合:

然后,从该集合中均匀采样一个突变节点:

由于能读取整个句法树和 CFG,因此知道了哪条生成规则能得到 m,并由此可以确保得到句法有效的突变。举个例子,如果 m 是一个数值,那么替代它的也应该是一个数值。如果 m 是一个一般子表达式,那就可以把它替换成任何一般子表达式。因此,可采样出 m',这是 m 的替代:
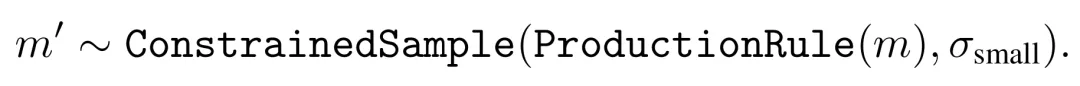
前向过程
该团队将程序合成问题视为一个推理问题。令 p (x|z) 为观察模型,其中 x 可以是任意类型的观察。任务是逆转这个观察模型的方向,即给定某个观察 x 得到一个程序 z。
首先,从一个数据集 D 取出某个程序 z₀,或者这里的做法是从 CFG 随机采样一个程序。即采样一个满足 σ(z₀) ≤ σ_max 的 z₀。然后通过下式描述的过程向 z₀ 添加噪声,执行 s 步,其中 s ∼ Uniform [1, s_max],而 s_max 是一个超参数:
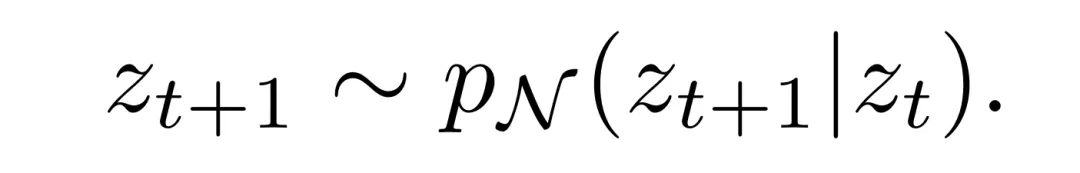
然后,训练一个建模以下分布的条件神经网络。
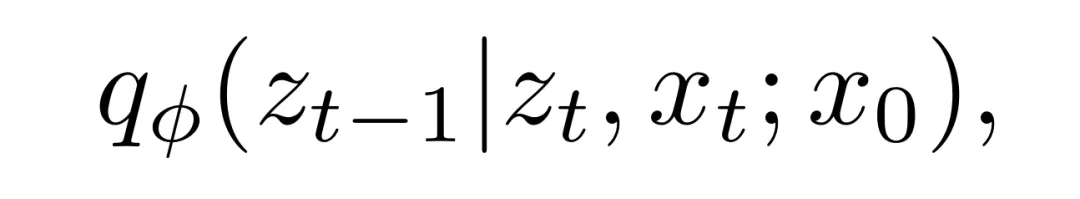
其中 ϕ 是该神经网络的参数,z_t 是当前的程序,x_t 是该程序当前的输出,x₀ 是需要求解的目标输出。
逆向突变路径
由于能够获取基本真值突变,因此可以简单地通过前向过程马尔可夫链 z₀ → z₁ →... 来逆向采样的轨迹,从而生成用以训练神经网络的目标。乍一看,这或许是个合理选择。但是,直接训练模型逆向最后一次突变有可能为神经网络创造出远远更有噪声的信号。
举个例子,在一个大得多的句法树中,一种颜色的突变路径为:

目标图像 x₀ 的颜色是 Red,而突变后图像 x₂ 的颜色是 Green。如果只是简单教模型逆向上述马尔可夫链,则可能会训练网络将 Green 变成 Blue,即便可以直接训练网络将 Green 变成 Red。
因此,为了创建更好的训练信号,可以计算目标树与突变树之间的编辑路径。该团队使用了一种大体上基于树编辑距离(tree edit distance)的树编辑路径算法。广义的树编辑距离问题允许插入、删除和替换任意节点。但这里的设定不同,对树的编辑仅能在一个只允许小突变的动作空间中实现。
对于两个树 z_A 和 z_B,可以线性方式比较它们的句法结构。对于已经满足 ≤ σ_small 的改变,就将其加入到突变列表中。对于 > σ_small 的改变,则寻找能降低两个树之间距离的首个突变。因此,对于任意两个程序 z_A 和 z_B 而言,可以在 O (|z_A| + |z_B|) 时间内计算出突变路径的第一步。
该团队另外还训练了一个价值网络 v_ϕ (x_A, x_B),其输入为两张经过渲染的图像 x_A 和 x_B,预测的是生成这两张图像的底层程序之间的编辑距离。由于在训练期间已经计算出了树之间的编辑距离,因此对于任意一对经过渲染的图像,都能直接获得它们的基本真值程序编辑距离,这就可以用于以监督式方法训练该价值网络。
使用该团队提出的上述新策略和新价值网络,就可以为任意目标图像 x₀ 和随机初始化的程序 z_t 执行波束搜索。在每一次迭代中,都要维护搜索树中一组有最有希望值的节点,并且仅扩展这些节点。
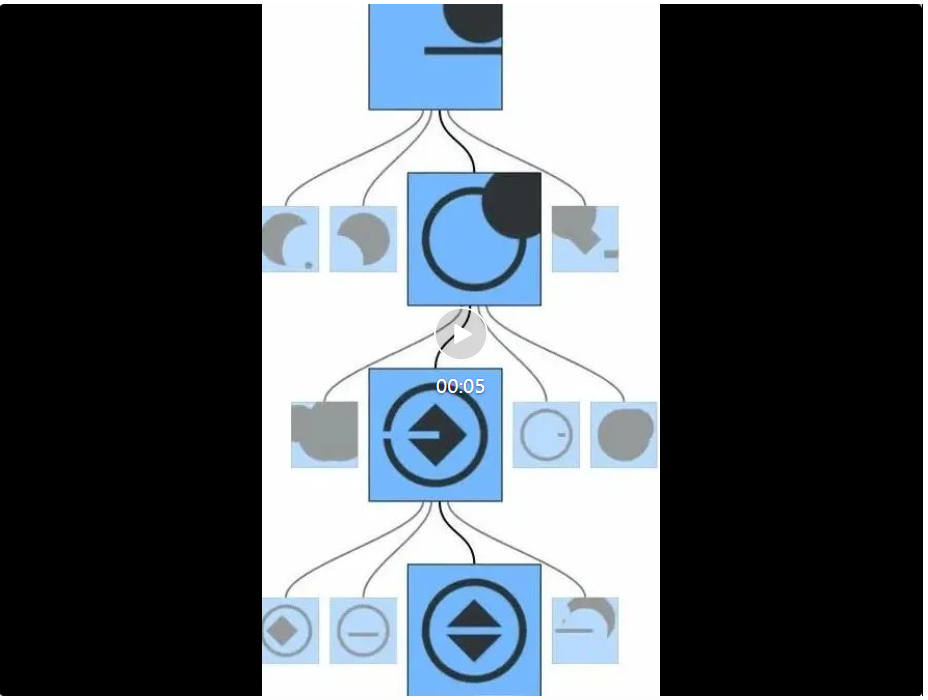
图 3 展示了新提出的神经架构的概况。
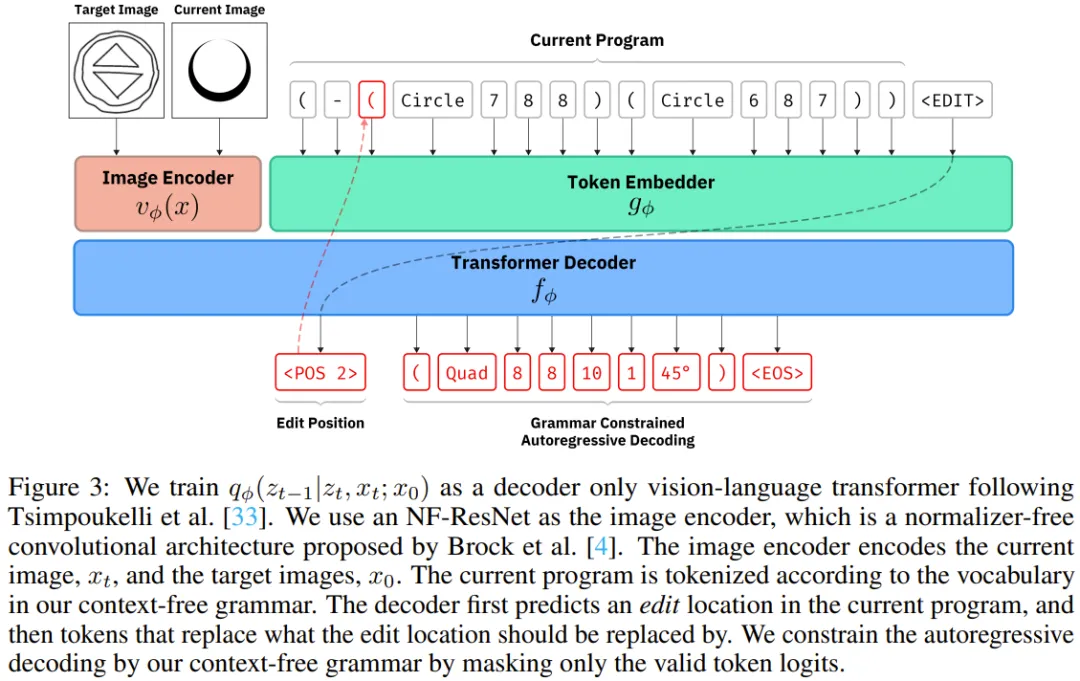
他们的去噪模型 q_ϕ (z_{t−1}|z_t, x_t; x₀) 使用的是 Tsimpoukelli et al. 在论文《Multimodal few-shot learning with frozen language models》中描述的视觉 - 语言模型。至于图像编码器,他们使用的是现成可用的 NF-ResNet-26 的实现;这是一种无归一化器的卷积架构,可避免使用 Batch-Norm 时的时间不稳定问题。
该团队实现了一种定制化的 token 化器,其中使用了他们的 CFG 的端点为 token。该编辑模型的其余部分是一个小型的仅解码器 Transformer。
他们还添加了另外两种类型的 token:用作该模型的句子起点 token 的 <EDIT> 以及允许模型在其上下文中引用位置的 token <POS x>。
给定一张当前图像,一张目标图像,和当前一个已 token 化的程序,训练该 Transformer 模型使之能以自回归方式预测编辑位置和替换文本。在进行预测时,解码过程受到语法的约束。该团队对预测 logit 进行了掩蔽,使之仅包含能表示句法树节点的编辑位置,以及仅得到对于所选编辑位置句法上有效的替换。
这里设置 σ_small = 2,这意味着只允许网络产生少于两个原语的编辑。对于训练数据,他们的做法是从 CFG 采样一个无限的随机表达式流。对于噪声步数 s,他们是从 [1, 5] 中随机选取一个。样本中有一定的比例 ρ 是完成随机采样新表达式作为突变表达式。他们使用单台英伟达 A6000 GPU 训练了三天时间。
他们在 4 种特定领域的图形语言上进行了实验:CSG2D、CSG2D-Sketch、TinySVG、Rainbow。
所选用的基准方法为 Ellis et al. 提出的《Write, execute, assess: Program synthesis with a repl》以及 Sharma et al. 提出的《CSGNet: Neural shape parser for constructive solid geometry》。
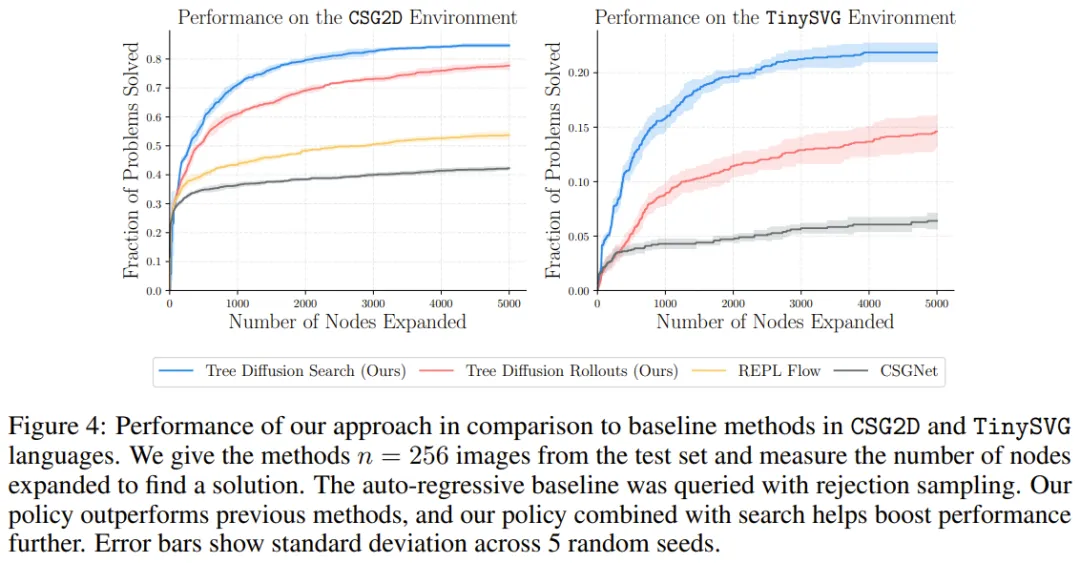
图 4 比较了新方法与基准方法的性能。
可以看到,在 CSG2D 和 TinySVG 环境中,新提出的树扩散策略明显优于之前方法的策略。如果组合使用波束搜索,该策略的性能还能进一步提升,在解决问题时相比其它方法可以更少地调用渲染器。
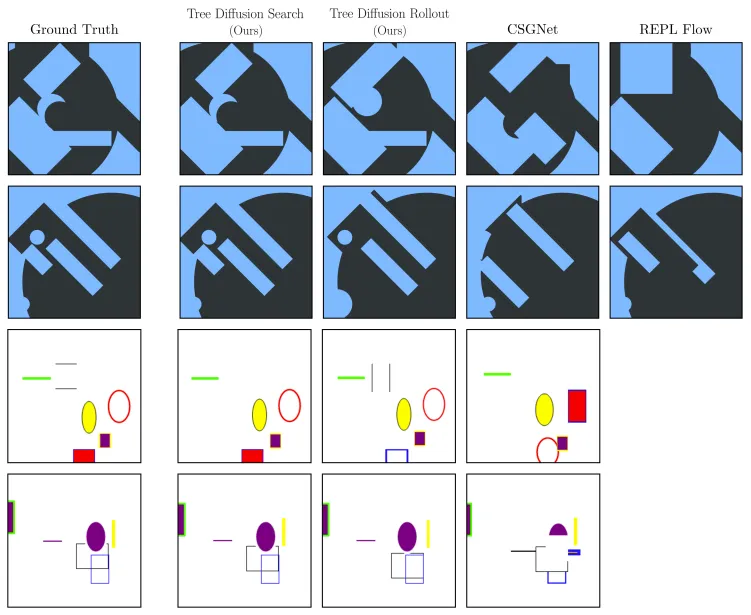
下图给出了新系统的一些成功示例以及基准方法的输出。可以看到,新系统能修复其它方法遗漏的较小问题。
如下视频展示了两个使用 CSG2D-Sketch 语言基于草图恢复程序的示例,其表明观察模型并不一定需要确定性的渲染;它也可由随机的手绘图像构成。
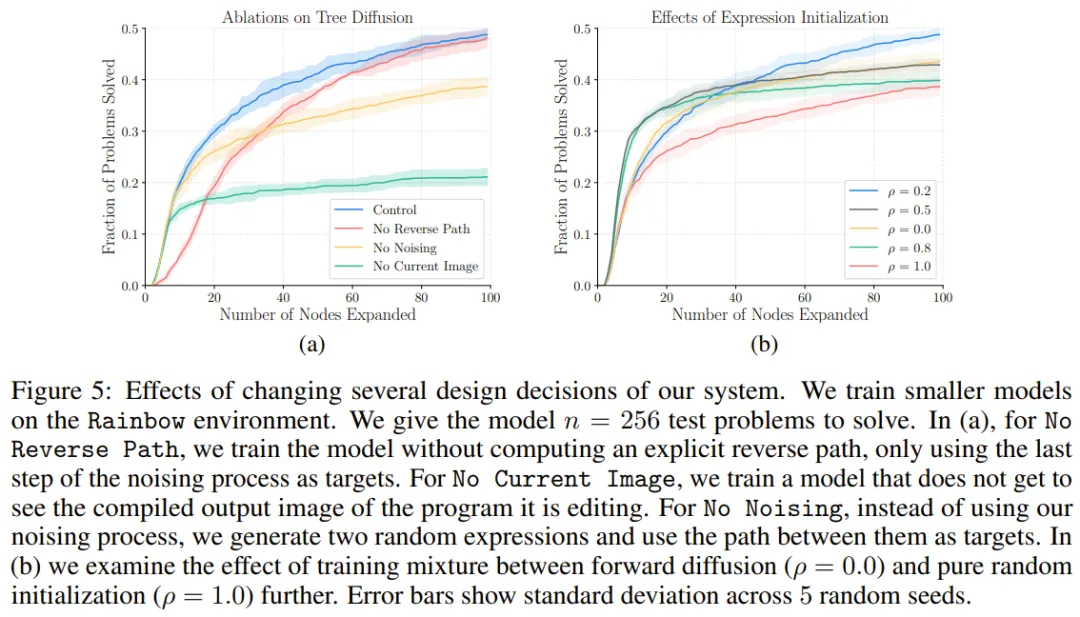
为了理解这些新设计的影响,该团队也在简化的 Rainbow 环境中使用一个更小的 Transformer 模型进行了消融实验,结果见图 5。总体而言,这些设计选择的效果得到了证明。
更多细节内容请参考原论文。
文章来自于微信公众号“机器之心”,作者 “机器之心”




