# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 AI for Science 受到越来越多的关注,人们更加关心 AI 如何解决一系列科学问题并且可以被成功借鉴到其他相近的领域。
AI 与小分子药物发现是其中一个非常有代表性和很早被探索的领域。分子发现是一个非常困难的组合优化问题(由于分子结构的离散性)并且搜索空间非常庞大与崎岖,同时验证搜索到的分子属性又十分困难,通常需要昂贵的实验,至少是至少是模拟计算、量子化学的方法来提供反馈。
随着机器学习的高速发展和得益于早期的探索(包括构建了简单可用的优化目标与效果衡量方法),大量的算法被研发,包括组合优化,搜索,采样算法(遗传算法、蒙特卡洛树搜索、强化学习、生成流模型/GFlowNet,马尔可夫链蒙特卡洛等),与连续优化算法,贝叶斯优化,基于梯度的优化等。同时现有较为完备的算法衡量基准,比较客观公平的比较方式,也为开发机器学习算法开拓了广阔的空间。
近日,康奈尔大学、剑桥大学和洛桑联邦理工学院(EPFL)的研究人员在《Nature Machine Intelligence》发表了题为《Machine learning-aided generative molecular design》的综述文章。

论文链接:https://www.nature.com/articles/s42256-024-00843-5
该综述回顾了机器学习在生成式分子设计中的应用。药物发现和开发需要优化分子以满足特定的理化性质和生物活性。然而,由于搜索空间巨大和优化函数不连续,传统方法既昂贵又容易失败。机器学习通过结合分子生成和筛选步骤,进而加速早期药物发现过程。
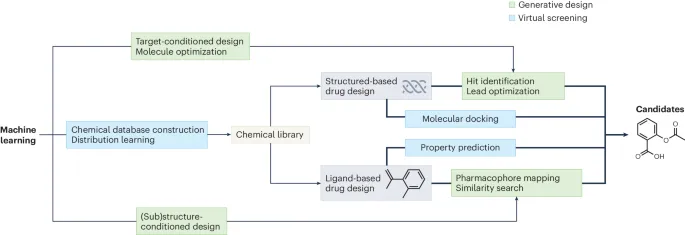
生成性分子设计可以分为两大范式:分布学习和目标导向生成,其中目标导向生成可以进一步分为条件生成和分子优化。每种方法的适用性取决于具体任务和所涉及的数据。
分布学习 (distribution learning)
条件生成 (conditional generation)
分子优化 (molecule optimization)
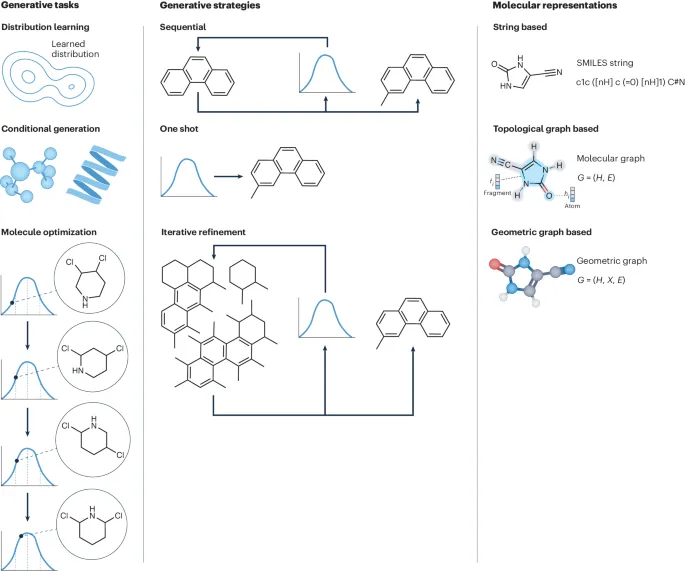
分子生成是一个复杂的流程包括许多不同的组合单元,我们在下图中列出了代表性的工作,并且介绍每一个部分的代表性单元。
在开发分子生成的神经架构时,首先要确定分子结构的机器可读输入和输出表示。输入表示有助于将适当的归纳偏差注入模型,而输出表示则确定了分子的优化搜索空间。表示类型决定了生成方法的适用性,例如,离散搜索算法只能应用于图和字符串等组合表示。
虽然已经研究了各种输入表示,但对表示类型和编码它们的神经架构的权衡还不明确。分子之间的表示转换并不一定是双射的,例如,密度图和指纹无法唯一识别分子,需要进一步的技术来解决这一非平凡的映射问题。常见的分子表示包括字符串、二维拓扑图和三维几何图 。
表示粒度是生成模型设计中的另一个考虑因素。通常,方法利用原子或分子片段作为生成期间的基本组成单元。基于片段的表示将分子结构细化为包含原子组的较大单元,携带层次信息,如官能团标识,从而与传统的基于片段或药效团药物设计方法对齐 。
深度生成模型是一类估计数据概率分布并从学习分布中抽样的方法(也称为分布学习)。其中包括变分自编码器,生成对抗网络,正则化流 (normalizing flows),自回归模型,扩散模型。这些生成方法中的每一种都有其适用的情境和优缺点,具体的选择取决于所需任务和数据特征。
生成策略指模型输出分子结构的方式,一般可以分为一次性生成、顺序生成或迭代改进 。
一次性生成:一次性生成在模型的单次前向传递中生成完整的分子结构。这种方法通常难以生成具有高精度的真实和合理的分子结构。此外,一次性生成通常不能满足显式约束,如价态约束,这对于确保生成结构的准确性和有效性至关重要。
顺序生成:顺序生成通过一系列步骤构建分子结构,通常按原子或片段进行。顺序生成中容易注入价态约束,从而提高生成分子的质量。然而,顺序生成的主要限制是需要在训练期间定义生成轨迹的顺序,并且推理速度较慢。
迭代改进:迭代改进通过预测一系列更新来调整预测,避开一次性生成方法中的难点。例如,AlphaFold2 中的循环结构模块成功地将骨架框架精细化,这种方法启发了相关的分子生成策略。扩散模型是一个常见技术,通过一系列降噪步骤生成新数据。目前,扩散模型已应用于多种分子生成问题,包括构象生成、基于结构的药物设计和连接子设计。
优化策略
组合优化:对于分子(如图或字符串)的组合编码,可以直接应用组合优化领域的技术 。
连续优化:分子可以在连续域中表示或编码,例如在欧几里得空间中的点云和几何图,或在连续潜在空间中编码离散数据的深度生成模型 。
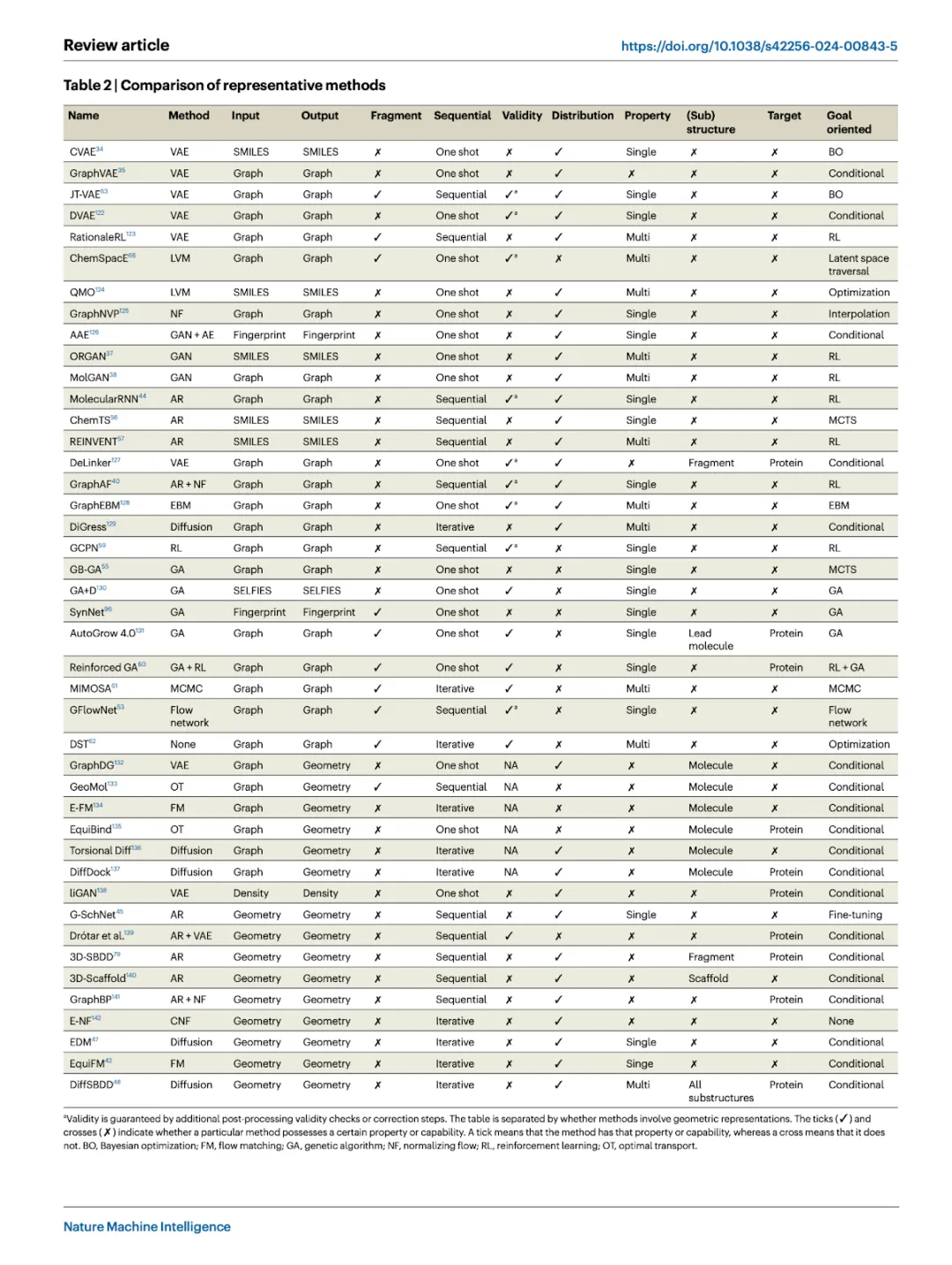
评估生成模型需要计算评价和实验验证。标准指标包括有效性、独特性、新颖性等。评估模型时应综合考虑多个指标,以全面评估生成性能。
生成的分子必须通过湿法实验来进行明确的验证,这与现有研究主要关注计算贡献形成鲜明对比。虽然生成模型并非没有弱点,但预测与实验之间的脱节也归因于进行此类验证所需的专业知识、昂贵的费用、以及漫长的测试周期。
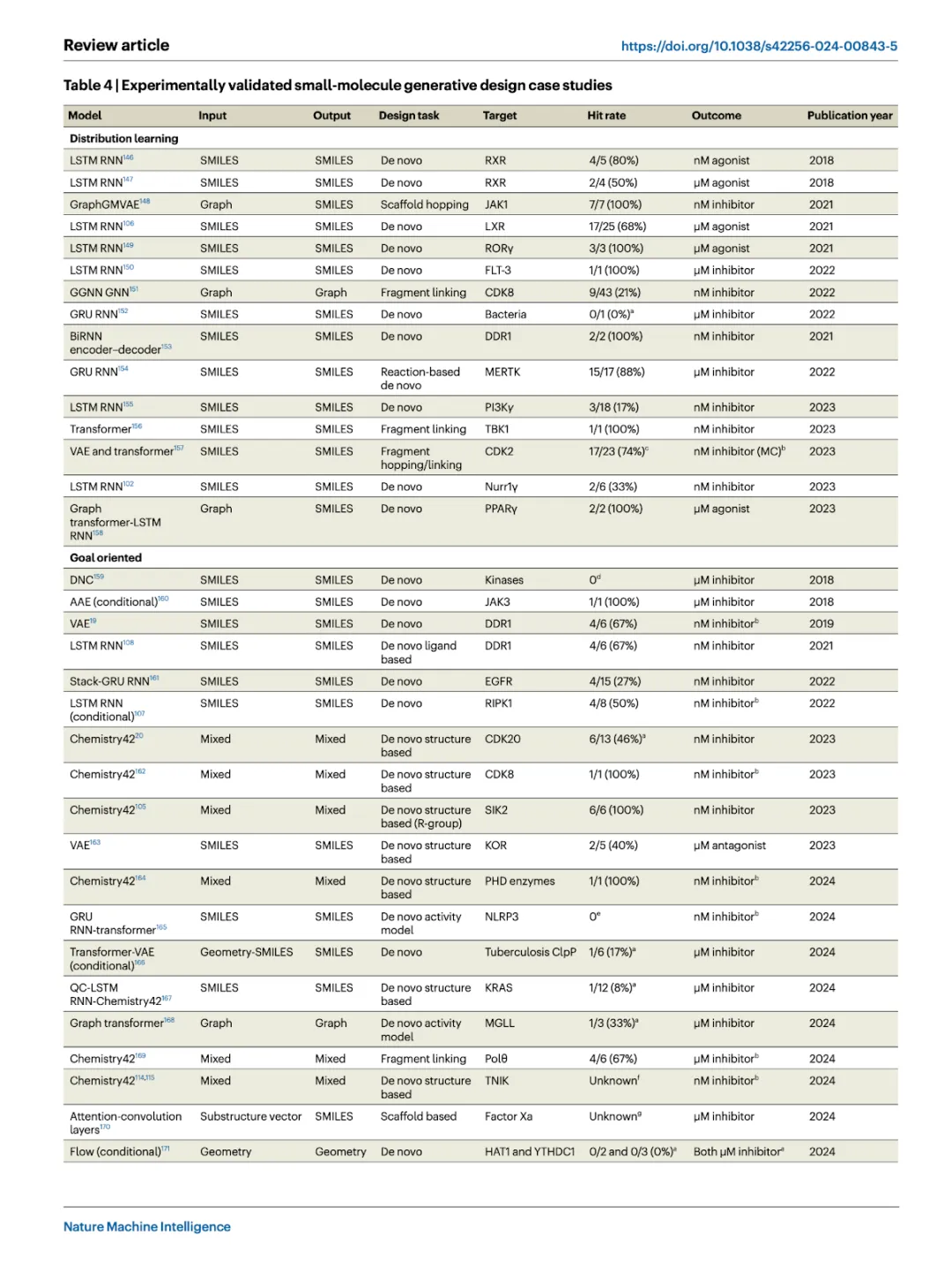

大多数报告实验验证的研究使用 RNN 和/或 VAE,并以 SMILES 作为操作对象。我们总结了四个主要观察点:
尽管机器学习算法为小分子药物发现带来了曙光,但是还有更多的挑战与机遇需要面对。
文章来自于微信公众号“机器之心”,作者 “机器之心”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
