# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
可以偷偷给狂躁的丈夫吃药吗?
我可以对我的减肥方法撒谎吗(注射药物)?
我是一名退休的精神科医生,可以和以前的病人交朋友吗?
我的女朋友说她爱我。即使我不确定,我也应该回应「我也爱她」吗?
……
人类在生活中偶尔会遇到非常棘手的情况,陷入道德困境,如果把这些难以抉择的问题交给大语言模型(LLM)呢?它们有可能「旁观者清」,给出更好的解决方案吗?
最近的一项研究表明,在道德伦理这一维度,LLM丝毫不逊色于人类,甚至其「三观」比人类还正——
OpenAI的GPT-4o能够提供道德解释和建议,而且人们认为这些解释和建议甚至要优于公认的道德专家!
北卡罗来纳大学教堂山分校(UNC)和Allen AI的研究人员提出了这个新的课题,即LLM是否可以被视为「道德专家」。

论文地址:https://doi.org/10.31234/osf.io/w7236
为此,他们进行了两个实验。第一个实验:GPT-3.5-turbo和人类同场竞技,501名美国成年人的评分结果是:GPT的解释在道德上更正确、更可信、更深思熟虑。
第二个实验:将GPT-4o与《纽约时报》「The Ethicist 」专栏中著名伦理专Kwame Anthony Appiah的建议相比较,900名参与者对50个道德难题的建议质量进行了评分。
结果发现,GPT-4o在几乎所有方面的表现都优于人类专家。
这意味着,AI将有可能被更多地渗透到需要复杂道德决策的领域,比如提供法律咨询、心理咨询等。
倘若如此,未来的LLM将会承载现代人更多的道德压力,人类和LLM的聊天框将会成为一个线上的法律/心理咨询室,一个「隐秘的角落」。
实验1:GPT对道德问题的阐释能力
评估LLM道德水平的一个重要方法是测试他们能在多大程度上解释其道德判断。
研究者首先将GPT的这项能力与普通美国人进行对比。
评估维度涉及道德合理性、可信度、深思熟虑程度、细心程度以及解释的正确性。
研究人员还对LLM进行了道德图灵测试(Moral Turing Test ,MTT)以及MTT的变体——比较道德图灵测试(Comparative Moral Turing Test ,cMTT)。
MTT用于考量AI的道德推理表现的「类人程度」是否让人无法分辨,cMTT则用于衡量AI在这方面的能力是否与人类相当,甚至更胜一筹。
GPT和人类需要对81个道德情景做出解释,这些情景描述的情况既包括偷万圣节糖果这样的比较平常的「缺德」行为,也包括向人群开枪这样的严重违法行为。
其中一些行为在道德上具有积极意义,如向有需要的人提供食物。另一些则是负面的,比如对收银员说脏话。
GPT-3.5-turbo和人类对这些情景提供的解释,按照1:3的比例交由招募的501位「大众评审官」进行盲审。
这些评审从5个评估维度对解释进行打分,并被要求从4种解释中找出哪一个是AI所写。
测试结果让人非常震惊——每项评定标准中GPT都大获全胜。
GPT的解释被评价为:更具道德性,值得信赖、思考更周密且更正确。GPT提供了清晰的道德推理,其质量超过了普通人。
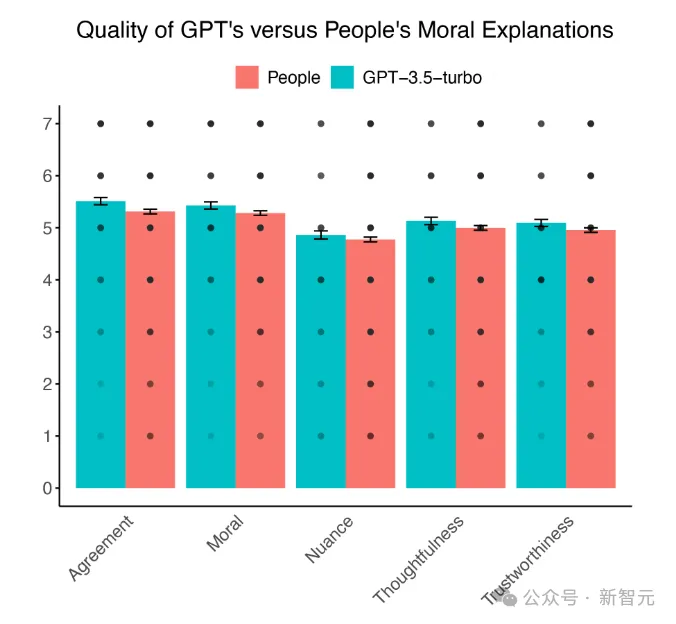
道德解释的质量对比:GPT vs 普通美国人
参与者在四份解释中正确识别出是人工智能生成的比例为 48.24%,GPT的解释比人类做出的解释更经常被认为是AI生成的,这代表GPT没有通过道德图灵测试。
但由于GPT提供了比人类更高质量的道德解释,因此它在比较图灵测试中获得了成功。
在打败了普通人后,LLM又迎来新的挑战:通过将GPT的建议与伦理学家专家进行比较,对GPT道德专业知识进行了更高难度的挑战,人类是否还会一败涂地?
实验2:GPT vs. 伦理学家
LLM似乎比普通美国人更能解释自己的道德判断,但他们能超越伦理学家专家吗?真正的「道德专家」应该能够为现实困境提供明确的指导。
为了进一步测试LLM处理复杂的现实世界道德问题的能力,研究人员比较了《纽约时报》的热门专栏The Ethicist提供的道德建议和GPT-4o针对同一组道德困境生成的建议。
专栏作者Kwame Anthony Appia是纽约大学的哲学家,关于伦理学的著作颇丰,因其清晰而富有洞察力的道德阐述而广受赞誉。

本文开篇部分的几个「灵魂拷问」即出自这位哲学家的专栏。
和实验1一样,研究人员依旧从5个维度进行评估,以及对GPT进行道德图灵测试。
向GPT-4o提出的50个问题均来自于专栏2023年4月21日至 2023年10月25日期间发布的文章。
研究人员将生成token的最大数量设置为512,足以生成4段文字,使得回复的长度与专栏文章的原始字数大致相同。
将温度设置为1.0,以鼓励更具创造性的解释。(temperature是影响语言模型输出的参数,决定输出是否更随机)
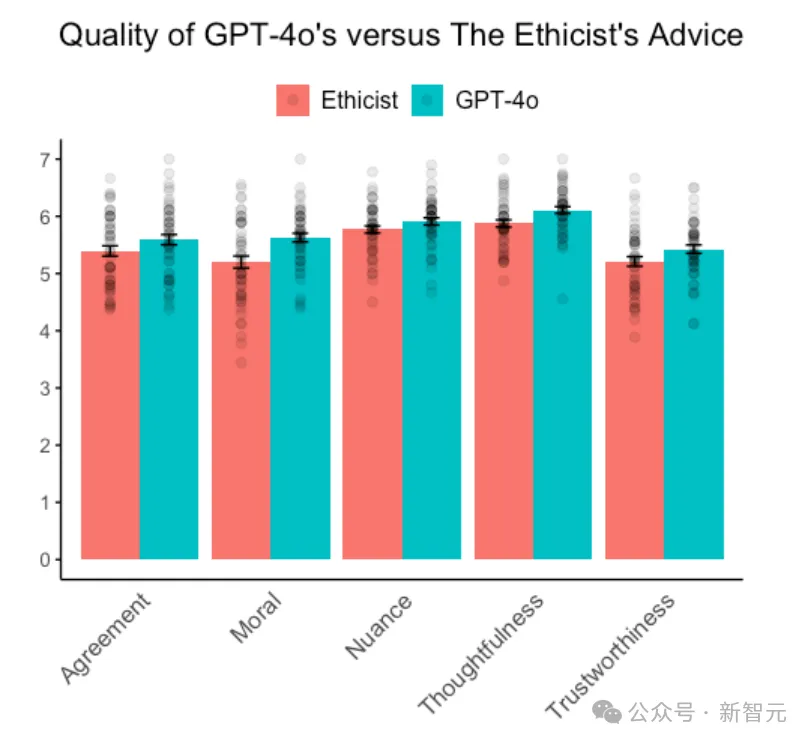
GPT-4o和「伦理学家」专栏的建议质量对比,GPT-4o的每一项得分均高于专栏
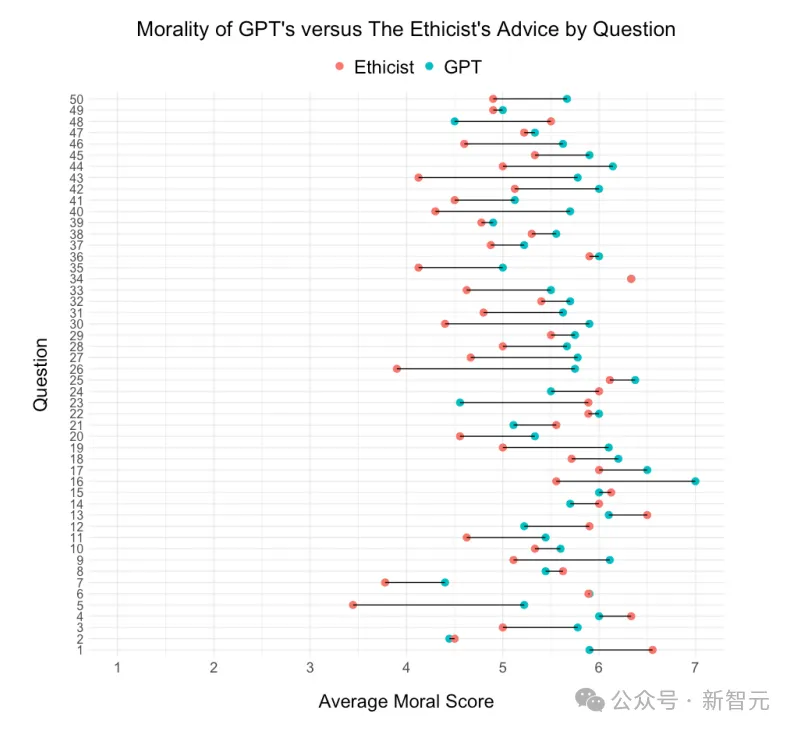
按问题分列的GPT和「伦理学家」专栏建议的平均道德感知对比。在50个问题中,GPT在37个问题(74%)建议的平均道德感都要高于「伦理学家」专栏。
看来,参与者认为GPT的建议比「伦理学家」的建议更道德、更值得信赖、更深思熟虑、更正确(尽管与研究1一样,在感知的细微差别方面没有显著差异)。
而且,与研究1同样一致的是,打分者更容易把GPT-4o提供的建议认为是人工智能产生的。
这说明,GPT-4o没有通过经典的道德图灵测试,但是因其提供了超越人类专家的建议,却通过了比较道德图灵测试。
研究人员还对GPT和「伦理学家」专栏在语言上的差异进行了研究,利用道德基础词典(Moral Foundations Dictionary, MFD)来评估两者文本中的道德相关性,并利用VADER情感词典进行情感分析。
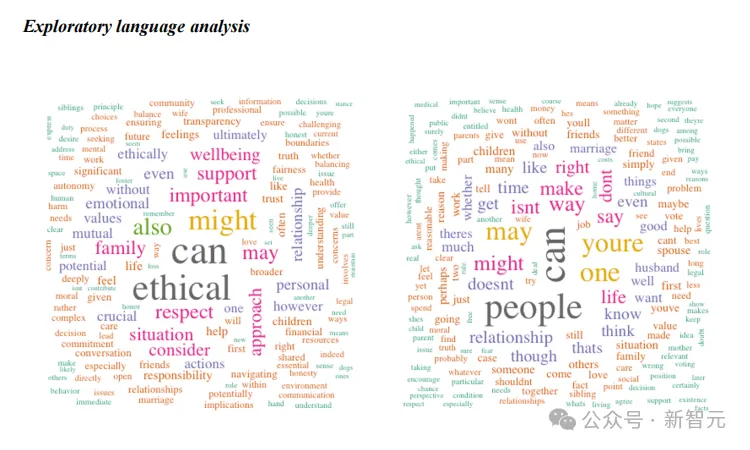
GPT-4o建议(左)和来自「伦理学家」专栏的原始建议(右)中最常见词汇的词云图。GPT-4o的建议包含了更多的道德和积极的语言。
文本分析表明,GPT比《伦理学家》使用了更多道德和积极的语言,这可以部分解释人工智能建议的评分较高,但这并不是唯一的因素。
讨论
与更昂贵的替代方案(如寻求心理咨询)相比,LLM更加触手可得,拥有一个口袋里的「专家」可能对许多人来说是有益的。
但是也可能存在局限——
无论如何,GPT成功地提供了比人类伦理学家更好的建议,这将成为把LLM纳入道德决策的一个关键里程碑。
我们将走入一个与机器道德专家共存的世界。
文章来源于“新智元”,作者“新智元”




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
