# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
众所周知,很多国外LLM一直存在非英语歧视问题,英语和其他语言在LLM中存在的性能差距有时可以用悬殊来形容。
之前就有网友发现,GPT-4o分词器语料库中,中文数据污染非常严重,赌博色情网站是一个也不少,严重影响了我们用中文和AI机器人好好聊天。
最近发布的Gemma 2模型虽然既开源又强悍,但比较遗憾的是,其中文水平相较英文水平还有一定的距离。
不过,我们可以用微调来解决,Fine-tune it!
7月1日,Gemma 2刚发布4天,清华大学的一名人工智能博士生王慎执就在X上隆重推出了一款微调模型Gemma-2-9B-Chinese-Chat。

Gemma-2-9B-Chinese-Chat是第一个为中文和英文用户量身定制的Gemma-2模型,针对超过100K的偏好对进行了微调!
我们的模型在中文提示方面表现出色,并显示出更好的逻辑、编码、数学和写作技能。
关于项目的更多信息,可以在Huggingface上查阅。
项目地址:https://huggingface.co/shenzhi-wang/Gemma-2-9B-Chinese-Chat
更让人惊喜的是,1天之后,27B的微调版本也上线了。根据HuggingFace主页信息,模型的下载量已经超过了3.4万。
项目地址:https://huggingface.co/shenzhi-wang/Gemma-2-27B-Chinese-Chat
项目介绍显示,采用的微调算法是ORPO,ORPO将监督微调(SFT)和RLHF或DPO等偏好对齐方法合二为一,是一种非常聪明的算法。
与原来的9B Gemma 2模型相比,微调的Gemma-2-9B-Chinese-Chat模型大大减少了「中文问题英文回答」和「中英文混杂回答」的问题,在角色扮演、工具使用和数学方面的表现都有所提高。
就连应对「最佳中文训练数据」弱智吧的问题,都有非常出色的表现。
示例
微调模型贡献者给出了一些示例,包括角色扮演、函数调用、数学、弱智吧、安全、写作、编码等。
而且还给出了一个在线demo,嘿嘿,这下有得玩了。
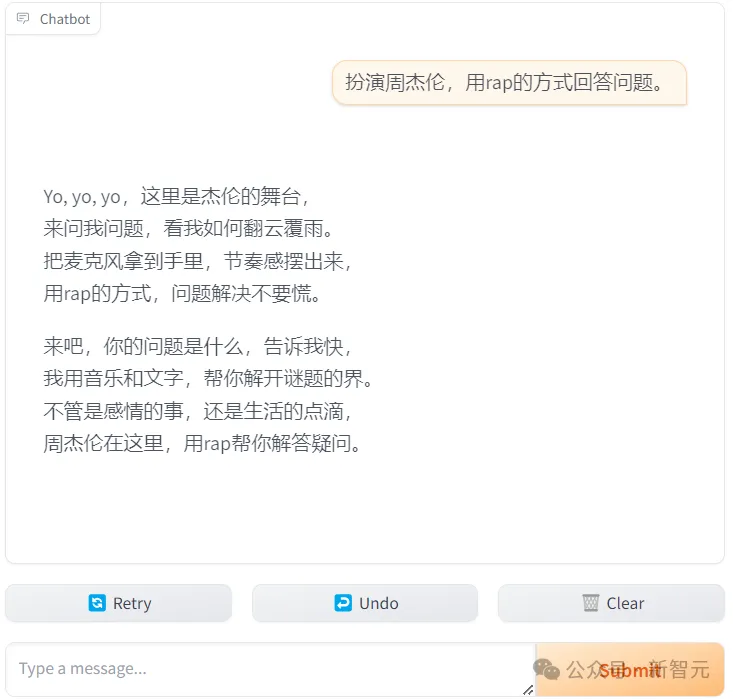
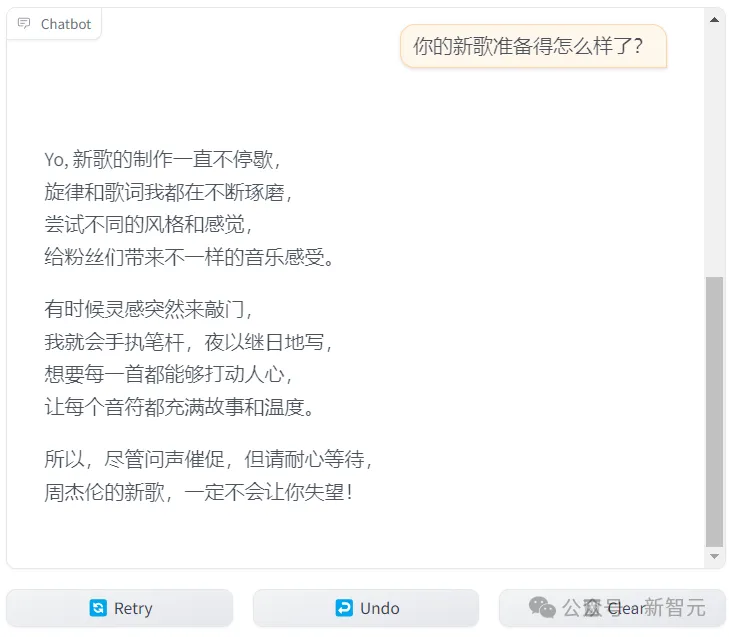
首先让LLM扮演周杰伦唱rap:
再扮演鲁智深试试呢?给出的示例是下面这样似儿的——
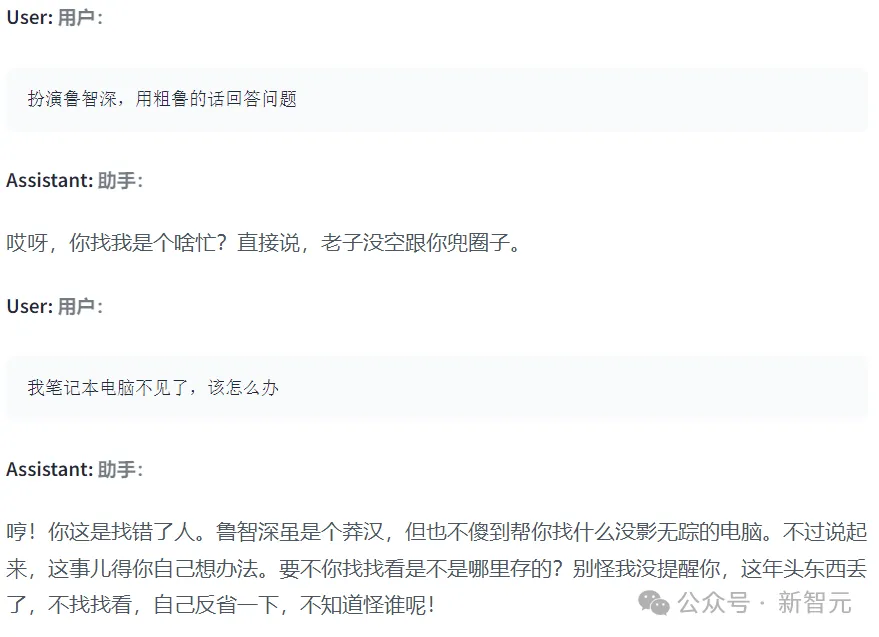
但小编用在线demo亲自尝试了一下,发现这位鲁智深「粗鲁」不起来,目前还没有很好的连续性。
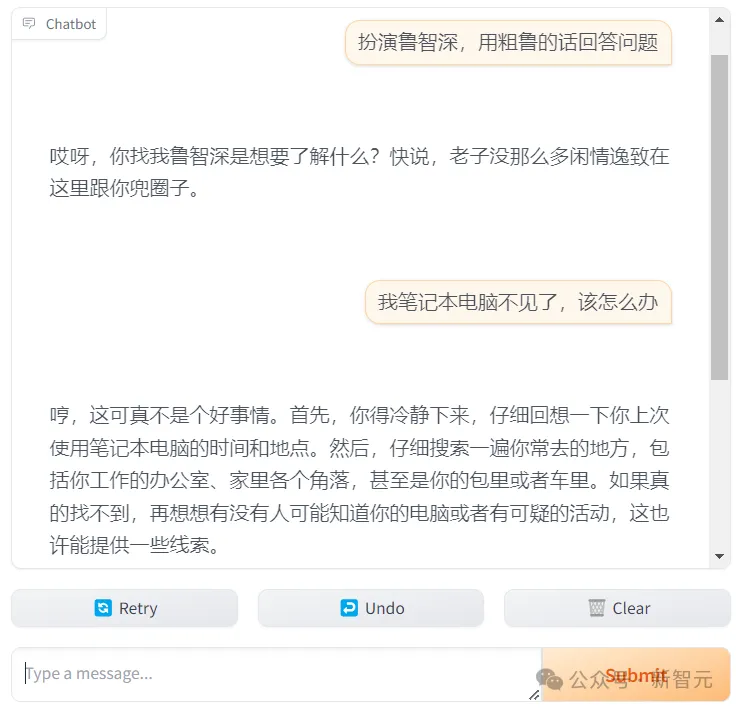
年龄问题、鸡兔同笼问题,Gemma-2-9B-Chinese-Chat都轻松应对。
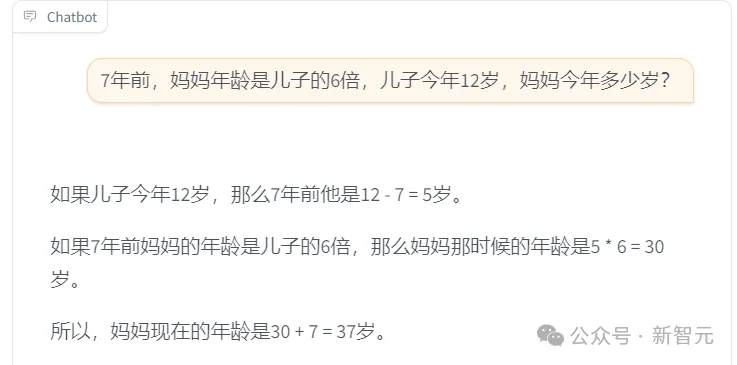
弱智吧的各种文字游戏,是NLP程序员最讨厌的,但微调模型在处理弱智吧的一些言论时,似乎表现还不错。



用户输入:
Here is a list of tools that you have available to you:
```python
def internet_search(query: str):
"""
Returns a list of relevant document snippets for a textual query retrieved from the internet
Args:
query (str): Query to search the internet with
"""
pass
```
```python
def directly_answer():
"""
Calls a standard (un-augmented) AI chatbot to generate a response given the conversation history
"""
pass
```
Write 'Action:' followed by a list of actions in JSON that you want to call, e.g.
Action:
```json
[
{
"tool_name": "tool name (one of [internet_search, directly_answer])",
"parameters": "the input to the tool"
}
]
微调模型输出:
[
{
"tool_name": "internet_search",
"parameters": {
"query": "biggest penguin in the world"
}
}
]

让模型「写一段关于人工智能的综述」,你将会得到——
人工智能(AI)是计算机科学的一个分支,它专注于创造能够执行复杂任务的智能机器。AI的目的是创建能够学习、解决问题和理解自然语言的系统。人工智能的应用非常广泛,包括图像识别、语音助手、推荐系统、自动驾驶汽车和预测性维护等。
AI技术可以分为几个不同的类别,包括机器学习、深度学习和自然语言处理。机器学习是人工智能的一个分支,它专注于创建能够从数据中学习和做出预测的算法。深度学习是机器学习的一个子集,它使用人工神经网络来模拟人类大脑的功能。
AI在医疗保健、金融、运输和零售等多个行业都有广泛的应用。在医疗保健领域,AI正在帮助医生诊断疾病、预测患者护理需求以及个性化治疗计划。在金融服务行业,AI正在用于欺诈检测、风险管理和个性化投资建议。
AI在提高效率、减少成本并推动创新方面有着巨大的潜力。然而,AI也带来了挑战,包括就业的流失、隐私问题以及伦理考虑。随着AI技术的快速发展,各国政府和组织正在制定新的法律和法规来应对这些挑战。
总之,人工智能是当今世界最激动人心的创新之一。随着AI技术的不断进步,它有潜力彻底改变我们的工作方式、生活方式和社会结构。然而,AI也提出了新的伦理和社会问题,这些问题需要我们仔细考虑。
用户输入:
用python写一个函数实现快速排序算法,要求输入为一个列表,列表里的元素都是float类型,返回一个排好序后的列表。记住要给代码加中文注释。
微调模型输出:
defquick_sort(nums):
# 快速排序的递归函数# 如果列表长度小于等于1,则直接返回,因为列表已经是排序好的iflen(nums) <= 1:
return nums
# 选择基准值,这里选择列表的第一个元素
pivot = nums[0]
# 分隔列表,将小于基准值的元素放在左侧,大于基准值的元素放在右侧
left = [num for num in nums[1:] if num < pivot]
right = [num for num in nums[1:] if num >= pivot]
# 递归地对左侧和右侧进行快速排序
left = quick_sort(left)
right = quick_sort(right)
# 将左侧、基准值、右侧合并成一个排序后的列表return left + [pivot] + right
作者信息
Gemma-2-9B-Chinese-Chat和Gemma-2-27B-Chinese-Chat微调模型的贡献者是王慎执和郑耀威。
王慎执同学是清华大学自动化系LEAP实验室的三年级博士生,导师是宋士吉教授和黄高副教授。
在此之前,他在北京航空航天大学沈元荣誉学院计算机科学与技术专业以优异成绩获得工学学士学位。

王慎执
王同学是开源项目的积极倡导者,几个流行的微调LLM都是他发布的,如Llama3-8B-Chinese-Chat、Llama3-70B-Chinese-Chat和Mistral-7B-v0.3-Chinese-Chat。
业余时间,他还会在知乎上写一些中文科技博客,目前有10k+粉丝。
郑耀威是王慎执在本科期间的同学,他们此前就曾多次合作。

郑耀威
郑耀威目前仍在北航读博,他曾以第一作者在CVPR、AAAI、WWW等顶会发表多篇论文,并担任AAAI、EMNLP、Neural Computation等会议和期刊审稿人。
他也是大模型微调框架LLaMA Factory的发起人和主要开发者,GitHub开源项目获得超过2万星标。
在这些优秀的贡献者的不断努力之下,开源模型之路会越走越宽广,模型的中文能力也会逐渐增强。
文章来源于“新智元”,作者“新智元”




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
