# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
模型性能的高低,到底是模型结构决定的,还是训练模型的算力和数据决定的?
DeepMind的研究人员给出了自己的回答——Compute is all you need!
他们认为,模型性能主要由可用的算力和数据来决定。
论文地址:https://arxiv.org/abs/2310.16764
LeCun第一时间转发了这篇论文,同时也振臂高呼:Compute is all you need!
有网友评论:「我们又行了!(We are so back)」。
LeCun回复:「其实我们从未离开」。
研究人员最主要是通过比较卷积神经网络(CNN)和视觉Transformers(ViT)在大规模图像识别任务上的表现,来得到这个结论的。
卷积神经网络是许多早期深度学习成功的原因。
Deep ConvNets在20多年前,就被LeCun等人首次商业化部署。
而AlexNet在2012年ImageNet大赛中的成功,则重燃了人们对该领域的兴趣。
近10年来,ConvNets主导了计算机视觉的基准测试。然而,近年来,它们越来越多地被(ViTs)所取代。
与此同时,计算机视觉社区已经从主要评估随机初始化网络在特定数据集(如ImageNet)上的性能,转变为评估从网络收集的大型通用数据集上预训练的网络的性能。
这就提出了一个重要的问题: 视觉Transformers在类似的计算预算下是否优于预训练的ConvNet架构?
虽然社区中的大多数研究人员认为,ViTs具有比ConvNets更好的缩放特性,但令人惊讶的是,几乎没有证据支持这一说法。许多研究ViTs的论文将其与弱ConvNet基线进行比较。
此外,最强的ViT模型已经使用超过500k TPU-v3 Core Hour的大型计算量进行了预训练,这远远超过基线了用于预训练的计算量。
而在这项研究中,研究者评估了NFNet模型家族的缩放特性,这是一种与第一篇ViT论文同时发表的纯卷积架构,也是最后一篇在ImageNet上达到SOTA的ConvNet。
研究者没有对模型架构或训练程序进行任何更改(除了调整简单的超参数,如学习率或epoch预算)。
他们在含40亿图像的JFT-4B数据集上预训练了不同规模的NFNet模型,预训练计算量从0.4k到110k TPU-v4 Core Hour。
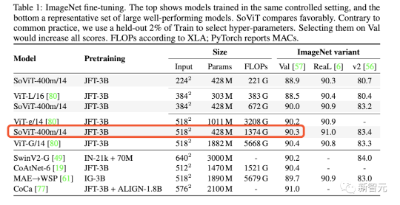
在ImageNet上微调后,最大的NFNet-F7+模型达到90.4%的top-1准确率,而ViT-g/14在相同计算量下预训练后的成绩是90.2%,SoViT-400m/14的成绩是90.3%。
二者表现出来的性能基本上是相当的。
而且,研究人员在实验时还发现,模型验证损失(Validation Loss)与预训练计算量呈对数关系。这和在训练Transformer模型中观察到的Scaling Law是一致的。
而且,适当调整模型大小、训练Epoch和学习率对结果有重要影响。
在固定计算预算下,模型大小和训练Epoch同时扩大效果最好。
学习率应先取一个较大值(1.6左右),然后随着模型复杂度和训练Epoch的增长逐渐减小。
有人表示:从音频或图像处理中取出卷积,跟与从意大利面中取出番茄差不多。
LeCun锐评道:要我说,从位置上取出本地连接和共享参数,就像从披萨中取出面包一样。除了卷积之外,许多运算符都是局部的,并且与翻译等变。
有人觉得,其实这个研究并不意味着ViT优于CNN。卷积内核分层聚合模式的方式非常有效,并以生物视觉系统为模型。在大量使用两者之后,每个人都喜欢Transformers,它们表现得很好,但不一定比我发现的经典Resnet更好。
人类大脑中的计算能力水平确实相对相似,但人类智力和表现的差异很大。这是否意味着,计算不是我们所需的全部?
「Tbh并不让我感到惊讶,所有的AI基本上都是以一种或另一种形式地将数据扔到黑盒里,看它是否能解决,所以flops可能比架构更重要。不过,在语义/大型局部任务中看到并置会很有趣。」
研究人员在JFT-4B上训练了一系列不同深度和宽度的NFNet模型。
每个模型都使用余弦衰减学习率针对0.25到8之间的Epoch预算进行训练。
在小对数网格上针对每个Epoch预算单独调整基础学习率。
在下图 2 中研究人员提供了对一组130k图像进行训练结束时的验证损失,并根据训练每个模型所需的计算预算进行绘制。
研究人员注意到F7的宽度与 F3 相同,但深度是 F3 的两倍。类似地,F3 是 F1 深度的两倍,F1 是F0深度的两倍。
F3+和F7+的深度与F3和F7相同,但宽度更大。
研究人员使用带有Momentum和自适应梯度裁剪 (AGC) 的SGD进行训练,batch大小为4096 ,图像分辨率为224×224。
图2展示了验证损失和预训练计算量之间的双对数(log-log)Scaling Law,他们之间呈现出线性关系。
这符合在训练Transformer模型中观察到的Scaling Laws。
最佳模型大小和最佳Epoch预算(实现最低验证损失)都会随着计算量的增加而增加。
研究人员还发现,以相同的速率缩放模型大小和训练Epoch的数量,训练效果最好。
对于大于5k TPU-v4 Core Hour左右的总体计算量,最佳Epoch应该是大于 1。
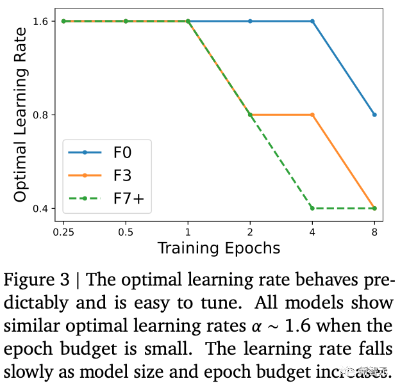
下图3中,研究人员绘制了3个模型在不同Epoch量中观察到的最佳学习率线条(最大限度地减少了验证损失)。
研究人员在间隔为2的对数网格上调整了学习率。他们发现 NFNet 系列中的所有模型对于Epoch量比较小的时候最佳学习率???? 约为1.6。
然而,随着Epoch的增加,最优学习率就开始下降,并且对于大型模型,最优学习率下降得更快。
在实践中,研究人员可以通过假设最优学习率随着模型大小和Epoch的增加而缓慢地下降,从而在2次试验内有效地调整学习率。
最后,研究人员还发现在上图2中的一些预训练模型的表现不如预期。
例如,不同预训练预算下的NFNet-F7+模型的曲线并不平滑。
研究人员认为出现这种情况是因为他们的数据加载管道(data loading pipeline)不能保证如果训练运行被抢占/重新启动,每个训练样本能在每个Epoch采样一次。
如果训练运行多次重新启动,则可能导致某些训练样本采样不足。
在图1中,研究者对ImageNet上预训练的NFNets模型进行微调,并根据预训练期间使用的计算,绘制top-1错误率。
其中,研究者使用了锐度感知最小化(SAM)对每个模型进行了50个epoch的微调,并使用随机深度和dropout。
训练分辨率为384×384,评估分辨率为480×480。
随着计算预算的增加,ImageNet Top-1的准确率也在不断提高。
研究中,经过8个epoch预训练的模型NFNet-F7+,ImageNet Top-1准确率达到了90.3%,而预训练大约需要11万 TPU-v4核心小时,微调需要1.6 万TPU-v4核心小时。
此外,如果研究人员在微调过程中额外引入重复增强(repeated augmentation),增强倍数为 4,这时Top-1准确率将达到90.4%。
相比之下,NFNets在ImageNet上的Top-1准确率为86.8%,是由NFNet-F5实现的。这表明NFNet从大规模预训练中受益颇多。
尽管两种模型架构之间有很大差异,但大规模预训练的NFNets的性能与预训练的Vision Transformer的性能非常相似。
比如,谷歌在2021年研究「Scaling Vision Transformers」中,在ImageNet上使用ViT-g/14达到90.2%的Top-1,在JFT-3B上进行210k TPU-v3核心小时的预先训练后;
使用ViT-g/14达到90.45% ,在JFT-3B上进行超过500k TPU-v3核心小时的预先训练后。
另外,在谷歌最近的另一项工作「Getting vit in shape: Scaling laws for compute-optimal model design」中,优化了ViT结构,在JFT-3B上进行230k TPU-v3小时的预训练后,使用SoViT-400m/14达到90.3%的Top-1。
这次,研究人员评估了这些模型在TPU-v4上的预训练速度(使用原作者的代码库),估计ViT-g/14预训练需要120k TPU-v4核心小时,而ViT-G/14需要280k TPU-v4 核心小时,SoViT-400m/14需要130k TPU-v4核心小时。
作者在图1中使用这些估计值来比较ViT和NFNets的预训练效率。注意到,NFNets是针对TPU-v4优化的,在其他设备上评估时表现较差。
最后研究发现,JFT-4B上达到最低验证损失的预训练检查点,在微调后并不总是在ImageNet上达到最高的Top-1准确率。
特别是,研究者发现,在固定的预训练计算预算下,微调机制一致倾向于稍大的模型和稍小epoch预算。
直观地说,较大的模型容量更大,因此能更好地适应新任务。在某些情况下,(预训练期间)稍大的学习率在微调后也能获得更好的性能。
论文结尾,研究者称,决定一个合理设计模型最终性能,最重要的因素是:算力和数据量。
虽然基于Transformer的模型,比如ViT,在视觉任务中展现出非常强大的能力。
总而言之,Compute is all you need!
作者介绍
Samuel L. Smith

Samuel L. Smith的兴趣是创建聊天机器人、编写教程,并从事深度学习和自然语言处理方面的研究。他从2018年加入谷歌,今年7月,前往了加利福尼亚参加谷歌大脑驻留项目。
Soham De
Soham De是伦敦DeepMind的一名研究科学家,致力于更好地理解和改进大规模深度学习。他目前专注于优化和初始化方面的主题,最近一直致力于隐私保护机器学习。
Leonard Berrada
Leonard Berrada在DeepMind强大且经过验证的AI团队中担任研究科学家。在此之前,他在牛津大学的Andrew Zisserman和Pawan Kumar的监督下完成了DPhil/博士学位。
他的研究方向是,优化、深度学习、验证和隐私保护机器学习。
Andrew Brock

Andrew Brock在2019年入职DeepMind。他曾毕业于美国加州圣路易斯-奥比斯保分校。
参考资料:
https://twitter.com/ylecun/status/1717676624865382901
文章来自微信公众号 “新智元”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner