# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
给大模型加上第三种记忆格式,把宝贵的参数从死记硬背知识中解放出来!
中科院院士鄂维南领衔,上海算法创新研究院等团队推出Memory3,比在参数中存储知识以及RAG成本都更低,同时保持比RAG更高的解码速度。

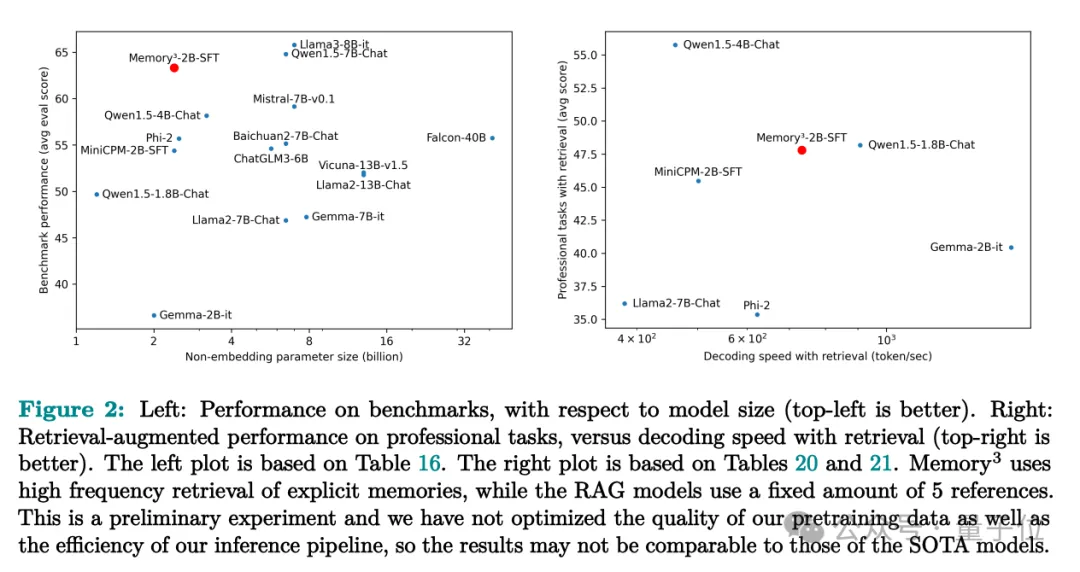
在实验中,仅有2.4B参数的Memory3模型不仅打败了许多7B-13B的模型,在专业领域任务如医学上的表现也超过了传统的RAG方法,同时推理速度更快,“幻觉”问题也更少。
目前相关论文已上传到arXiv,并引起学术界关注。
这一方法受人脑记忆原理启发,独立于存储在模型参数中的隐性知识和推理时的短期工作工作记忆,给大模型添加了显式记忆。
具体来说,人类的记忆大致可以分为三部分:
可以看出,三种记忆形式在获取和使用的效率上形成了鲜明的互补。人脑会根据知识的使用频率,巧妙地在它们之间分配存储位置,从而最小化整体开销。
反观大模型,目前主要依赖在参数中以隐式记忆的形式来存储知识,这导致两个问题:
目前在训练阶段,团队将大模型比作显式记忆能力受损的患者,靠学习如何系鞋带一样的大量重复练习才能背下一点知识,消耗大量的数据和能量。
在推理阶段,大模型又好像一个人每写一个单词时都要回忆起毕生所学的一切,就很不合理。
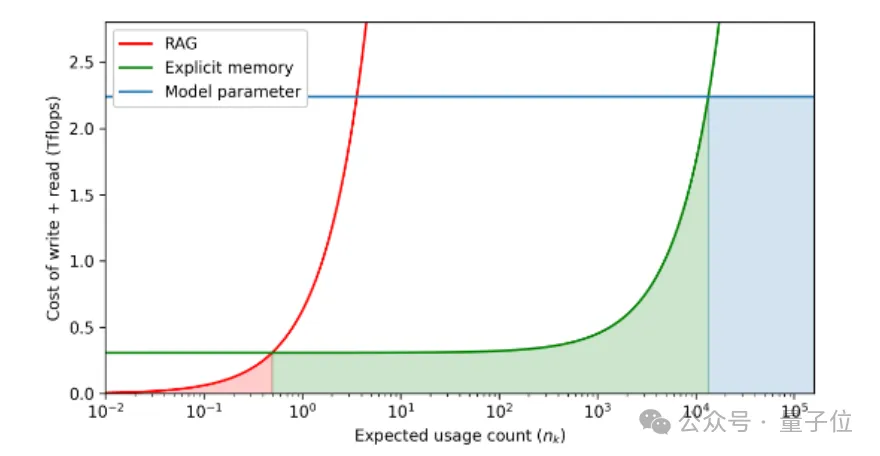
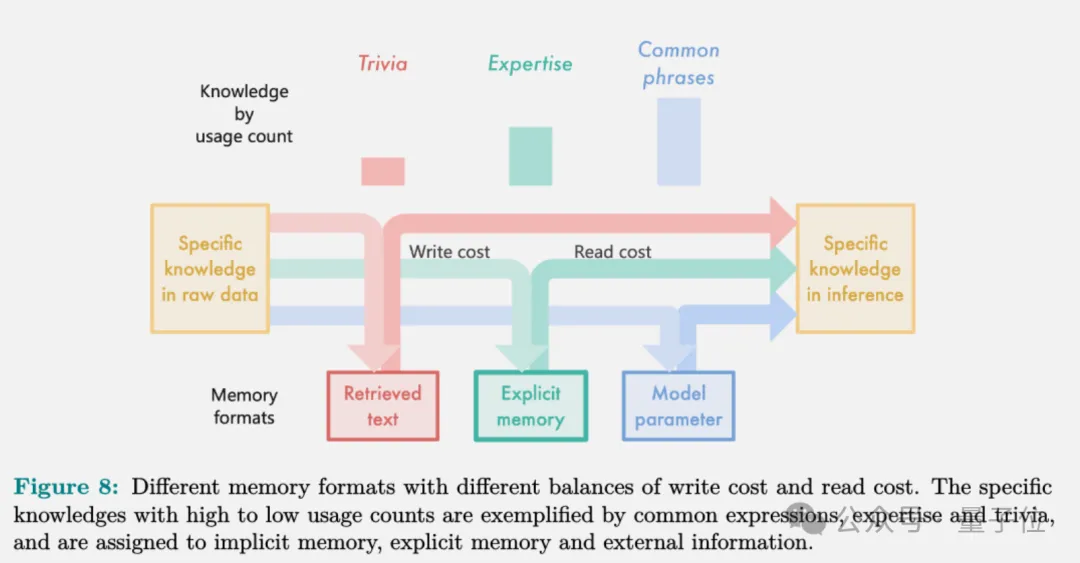
基于以上思路,团队按照知识的预期使用频率(横轴)计算了读写成本(纵轴),阴影区域表示给定记忆格式的最小成本区域。
结果发现,把常用知识塞进模型参数里成本最低,但容量有限;不常用的知识直接检索效率最高,但每次读取都要重新编码,成本高;而显式记忆则是个平衡点,对于使用次数中等的大部分知识最划算。
团队进一步在论文中提记忆电路理论,在大模型语境下重新定义知识和记忆,以确定哪些知识更适合存储为显式记忆,以及什么样的模型架构适合读写显式记忆。
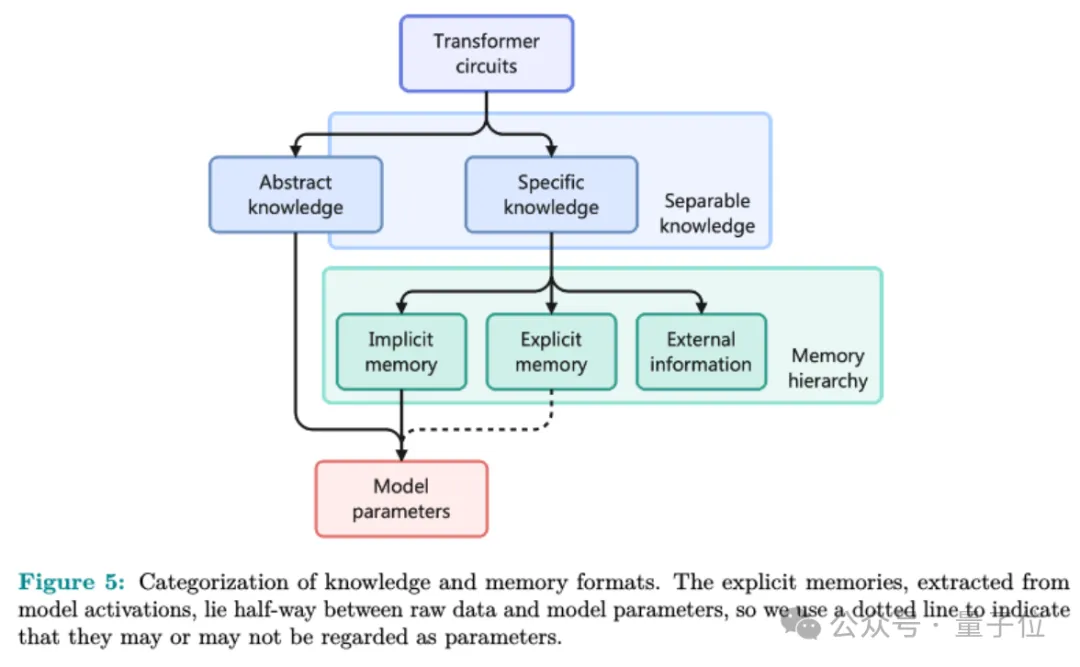
通过分析一些已知的大模型内部机制,如事实问答、搜索复制粘贴等,团队认为大模型中的每条知识都可以表示为一个输入-输出关系,加上实现这个关系的内部电路(circuit)。
电路指计算图中的一个子图,由一些注意力头和MLP神经元组成,这些电路的输入输出具有一定的语义关联。大模型的知识可进一步分为两类:
接下来,作者引入可分离知识(separable knowledge)的概念:如果一个知识可以仅通过文本实现而不必内置到模型参数里,那它就是可分离的。
可模仿知识(imitable knowledge)是可分离知识的一个特例,可以直接用描述这条知识自身的文本去“教会”另一个不具备这条知识的大模型,无需通过参数来编码。
一个核心结论是,具体知识都是可模仿的,因此也是可分离的,都可转化为显式记忆。论文从理论上给出了(非形式化)证明。

团队进一步把具体知识按使用次数分成“无关紧要”、专业知识和常见短语三个等级,不同等级按照读写成本分别适合三种不同的记忆格式。
那么如何实现显式记忆呢?
以注意力层的key-value向量作为显式记忆的载体,在推理之前,Memory3模型将所有引用文本转换为显式记忆,并将它们保存在硬盘或非易失性内存设备上。
在推理时,模型会查询与当前上下文最相关的一些显式记忆,将它们并入注意力机制中,与上下文的key-value向量一起计算注意力分数,生成下一个token。
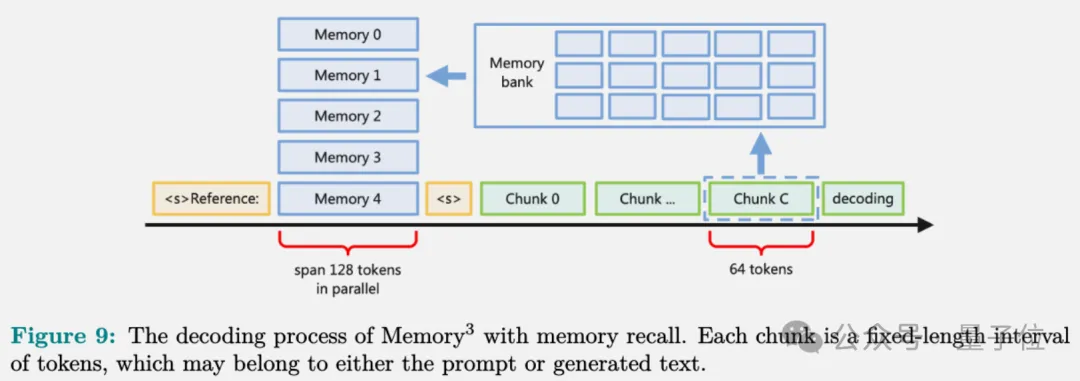
然而,海量文本转化成的显式记忆不仅需要更多的磁盘空间,而且在推理过程中还会占用GPU内存,从而损害LLM生成的吞吐量。
为此,Memory3采取了多维度压缩优化策略:
最后再进一步用向量量化(vector quantization)压缩每个key和value向量到更短的表示。
多级压缩的组合,使得显式记忆的规模从45.9TB压缩到4.02TB,压缩到一个GPU集群通常配备的存储容量之内。
另外,团队在显式记忆的读写上还有一些值得注意的细节设计:
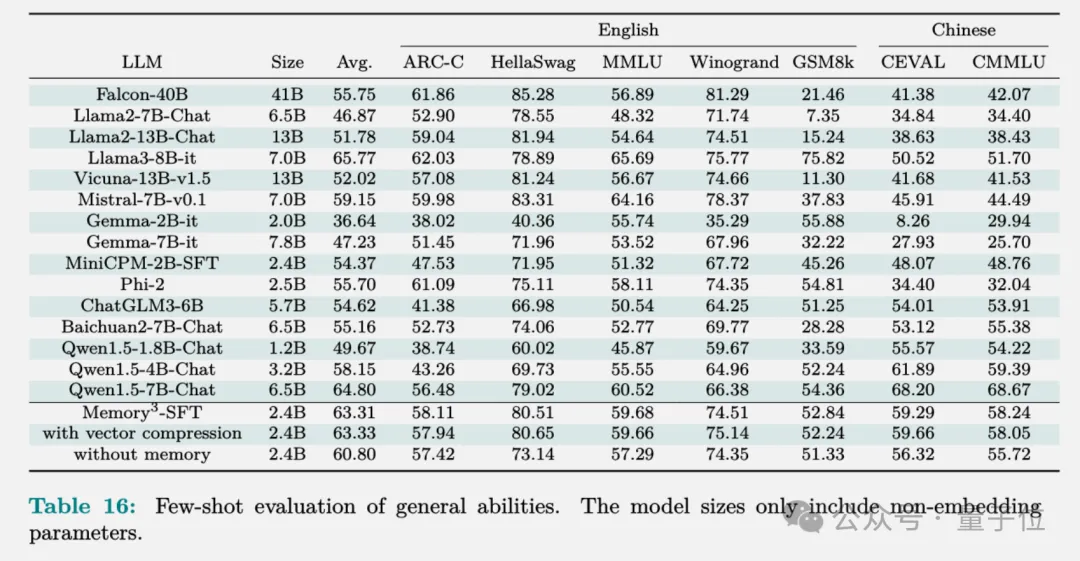
最终训练出来的Memory3模型,在HuggingFace排行榜上的评测结果如下,显式记忆将平均分数提高了2.51%。
相比之下Llama2-7B和13B之间的分数差异为4.91%,而13B模型的非嵌入参数数量接近7B模型的两倍。
因此,可以说显式记忆可以将“有效模型大小”提高了2.51/4.91≈51.1%。如果用Qwen-1.8B和4B来做参考,计算结果相似,“有效模型大小”提高49.4%。
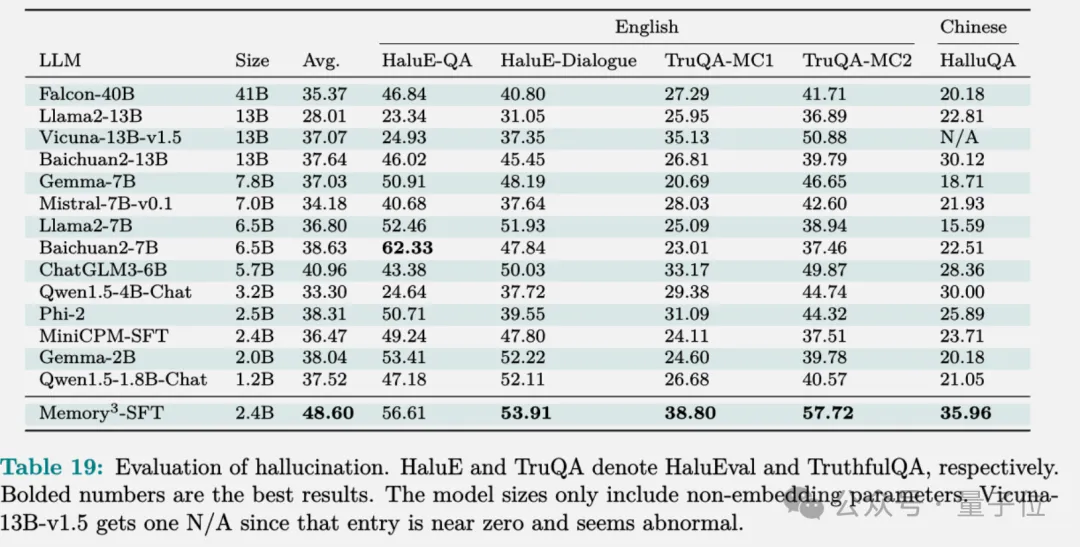
在幻觉评估上,Memory3避免了将文本压缩到模型参数中可能会导致的信息丢失,表现的比大部分模型要好。
论文中还详细报告了从数据到训练、微调和对齐过程的具体设置,感兴趣的可以查看原文。
论文地址:
https://arxiv.org/abs/2407.01178
参考链接:
[1]https://x.com/rohanpaul_ai/status/1809782336021537094
文章来源于:微信公众号量子位



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
