# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。
近期,哈工大和鹏城实验室的研究人员提出了「Training-free 的异构大模型集成学习框架」DeePEn。
不同于以往方法训练外部模块来筛选、融合多个模型生成的回复,DeePEn 在解码过程中融合多个模型输出的概率分布,联合决定每一步的输出 token。相较而言,该方法不仅能快速应用于任何模型组合,还允许被集成模型访问彼此的内部表示(概率分布),实现更深层次的模型协作。
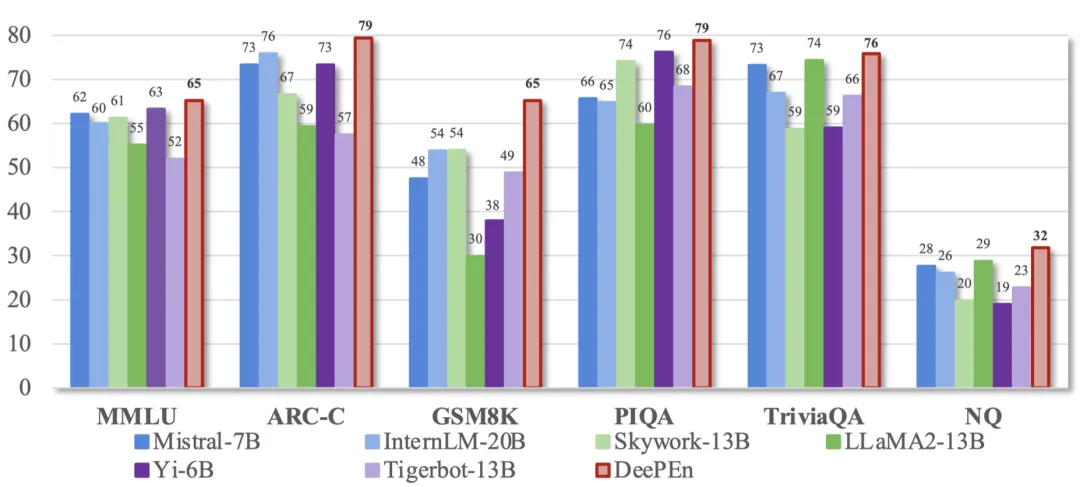
结果表明, DeePEn 在多个公开数据集上均能取得显著提升,有效扩展大模型性能边界:
目前论文及代码均已公开:

方法介绍
异构大模型集成的核心难点在于如何解决模型间的词表差异问题。为此,DeePEn 基于相对表示理论,构建由多个模型词表之间的共享 token 构成的统一相对表示空间。在解码阶段,DeePEn 将不同大模型输出的概率分布映射到该空间进行融合。全程无需参数训练。
下图中展示了 DeePEn 的方法。给定 N 个模型进行集成,DeePEn 首先构建它们的转换矩阵(即相对表示矩阵),将来自多个异构绝对空间的概率分布映射到统一的相对空间中。在每个解码步骤中,所有模型进行前向计算并输出 N 个概率分布。这些分布被映射到相对空间并进行聚合。最后,聚合结果被转换回某个模型(主模型)的绝对空间,以确定下一个 token。
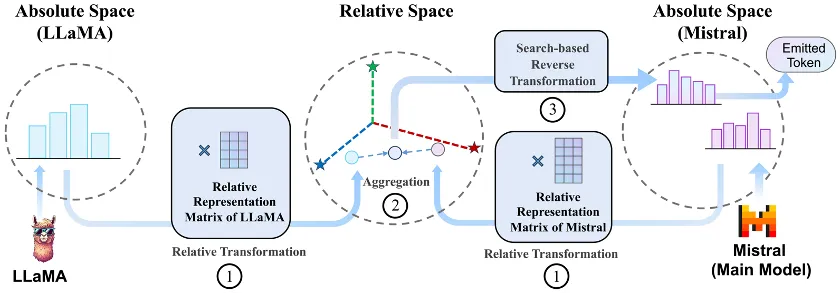
图 1:方法示意图。其中,相对表示转换矩阵是通过计算词表中每个 token 与模型间共享的锚点 token 之间的词嵌入相似度得到的。
构建相对表示转换
给定 N 个要集成的模型,DeePEn 首先找出所有模型词表的交集,即共享词集,并从中抽取一个子集 A⊆C 或使用全部共享词作为锚点词集合 A=C。
对于每个模型,DeePEn 计算词表中每个 token 与锚点 token 的嵌入相似度,得到相对表示矩阵。最后,为了克服离群词的相对表示退化问题,论文作者对相对表示矩阵进行行归一化,通过对矩阵的每一行进行 softmax 操作,得到归一化相对表示矩阵。
相对表示融合
在每个解码步骤中,一旦模型输出概率分布,DeePEn 使用归一化相对表示矩阵将转换为相对表示:
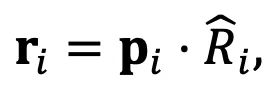
并将所有相对表示进行加权平均以获得聚合的相对表示:
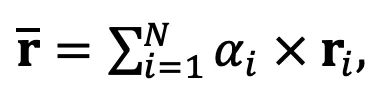
其中是模型的协作权重。作者尝试了两种确定协作权重值的方法:(1) DeePEn-Avg,对所有模型使用相同的权重;(2) DeePEn-Adapt,根据各个模型的验证集性能成比例地为每个模型设置权重。
相对表示逆映射
为了根据聚合的相对表示决定下一个 token,DeePEn 将其从相对空间转换回主模型(开发集上性能最好的模型)的绝对空间。为了实现这种逆转换,DeePEn 采用了基于搜索的策略,找出相对表示与聚合后的相对表示相同的绝对表示:
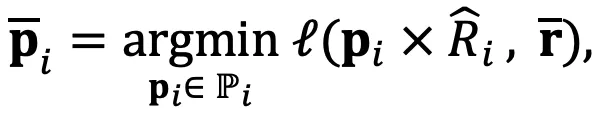
其中表示模型的绝对空间,是衡量相对表示之间距离的损失函数(KL 散度)。
DeePEn 利用损失函数相对于绝对表示的梯度来指导搜索过程,并迭代地进行搜索。具体来说,DeePEn 将搜索的起始点初始化为主模型的原始绝对表示,并进行更新:
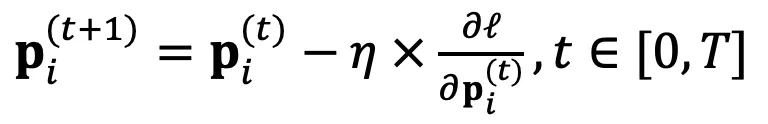
其中 η 是称为相对集成学习率的超参数,T 是搜索迭代步数。
最后,使用更新后的绝对表示来确定下一步输出的 token。
实验
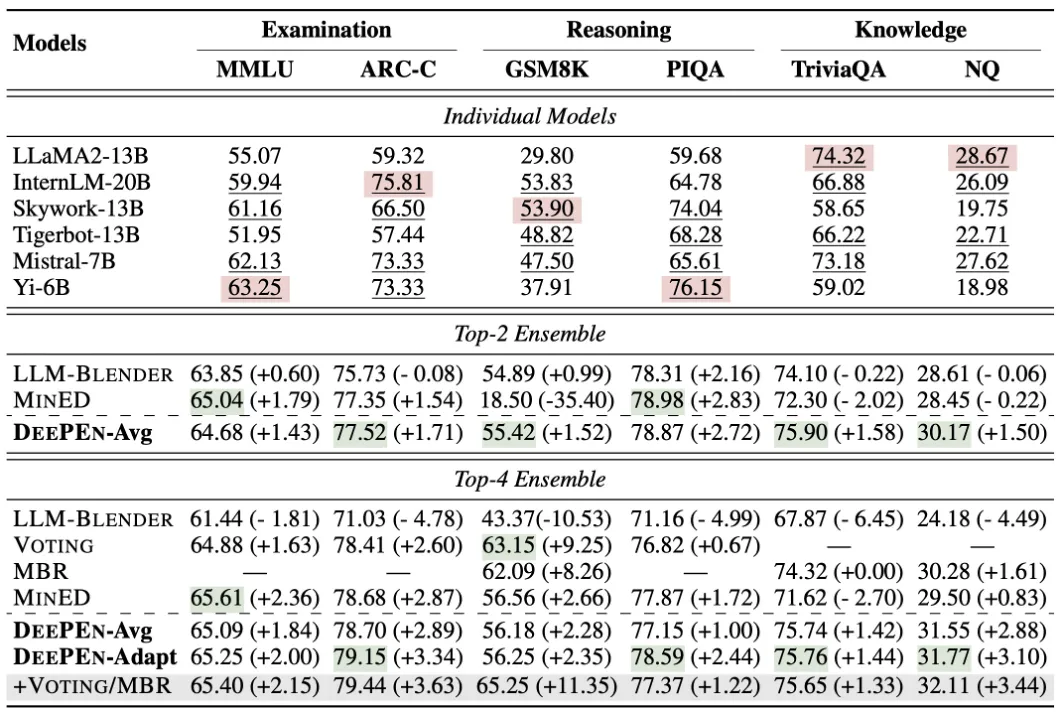
表 1:主实验结果。第一部分为单模型的性能,第二部分为分别对每个数据集上的 top-2 模型进行集成学习,第三部分为 top-4 模型集成。
通过实验,论文作者得出了以下结论:
(1) 大模型在不同任务上各有所长。如表 1 所示,不同大模型在不同数据集上的表现存在显著差异。例如 LLaMA2-13B 在知识问答 TriviaQA 和 NQ 数据集上取得了最高的结果,但是其他四个任务上的排名并未进入前四。
(2) 分布融合在各个数据集上取得了一致性的提升。如表 1 所示,DeePEn-Avg 和 DeePEn-Adapt 在所有数据集上均取得了性能提升。在 GSM8K 上,通过与投票法组合使用,最终取得了 + 11.35 的性能提升。
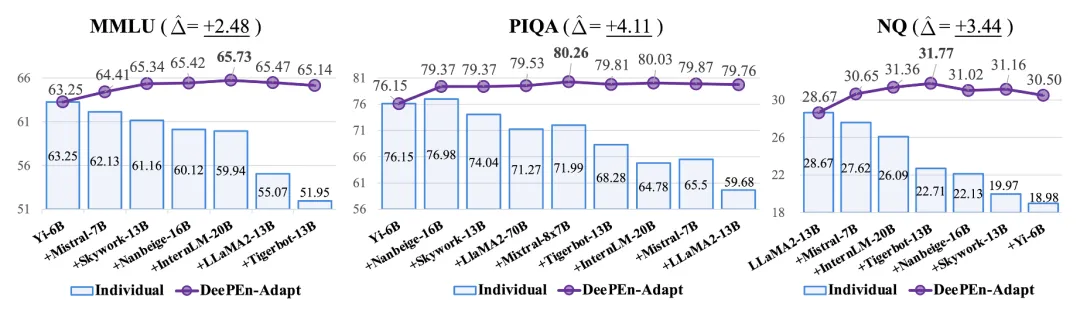
表 2:不同模型数量下的集成学习性能。
(3) 随着集成模型数量的增加,集成性能先增后减。作者在根据模型性能由高到低,依次将模型加入集成,然后观察性能变化。如表 2 所示,不断引入性能较差的模型,集成性能先增后减。
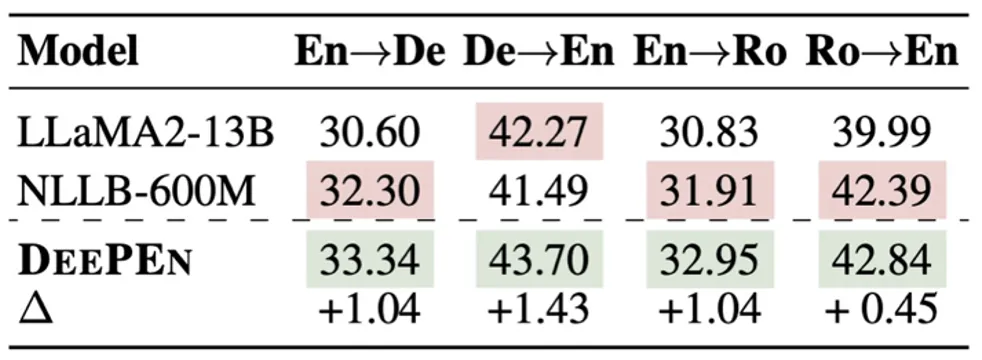
表 3:在多语言机器翻译数据集 Flores 上,大模型与翻译专家模型之间的集成学习。
(4) 集成大模型与专家模型有效提升特定任务性能。作者还在机器翻译任务上对大模型 LLaMA2-13B 和多语言翻译模型 NLLB 进行集成。如表 3 所示,通用大模型与任务特定的专家模型之间的集成,可以显著提升性能。
结论
当前的大模型层出不穷,但很难有一个模型能在所有任务上全面碾压其他模型。因此,如何利用不同模型之间的互补优势,成为一个重要的研究方向。本文介绍的 DeePEn 框架,解决了不同大模型在分布融合时的词表差异问题,且无需任何参数训练。大量实验表明,DeePEn 在不同任务、不同模型数量及不同模型架构的集成学习设置中,均取得了稳定的性能提升。
文章来自于微信公众号“机器之心”,作者 “机器之心”




