# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。
在实际应用中,处理 PDF(或其他复杂格式)的 RAG 流水线通常包括以下步骤:
完成这些处理步骤后,文本可以作为输入提供给如 Vespa 等检索系统。使用 Vespa,开发人员可以通过文本嵌入模型(如 Cohere、ColBERT 等)对文本进行分块和嵌入,或结合传统 BM25 方法的 hybrid 组合进行处理。
每一个“提取和嵌入”步骤都可能复杂且耗时,并且对检索质量有很大影响。正所谓“垃圾进,垃圾出”。例如,有大量 YouTube 视频专门讨论如何为嵌入进行文本数据分块。
但是,如果我们能够跳过这些复杂的“提取、分块和嵌入”步骤,直接将整个渲染的文档(包括图像、图表、表格)嵌入到对检索有用的向量表示中,会怎样呢?

ColPali
复杂(且信息丰富)的 PDF 页面截图。来源
视觉语言模型 (VLMs) 1 是一种新型模型,结合了视觉 (图像) 和文本功能。与传统的仅文本模型不同,VLMs 可以处理和读取视觉数据及文本数据。这种融合使得 VLMs 能够执行需要理解视觉内容与文本的任务,例如解释图像、为视觉输入生成描述,甚至基于视觉内容回答问题。可以看到,视觉语言模型不仅限于处理可爱猫咪的照片,它们还能处理像 PDF 这样复杂的文档,其中视觉内容和文本同样重要。
ColPali 2 为应对复杂文档格式提供了一种新颖的方法;ColPali 直接将 PDF 页面的截图(包括图像、图表、表格)转化为用于检索(和排序)的向量表示,无需 OCR、布局分析或任何其他复杂的预处理步骤,也无需文本分块。
所需的仅仅是页面的截图图像。
ColPali 中的 Col 灵感来自于 ColBERT ,其中文本被表示为多个向量,而不是单个向量表示。而 Pali 则源于 PaliGemma ,这是一种强大的视觉语言模型。
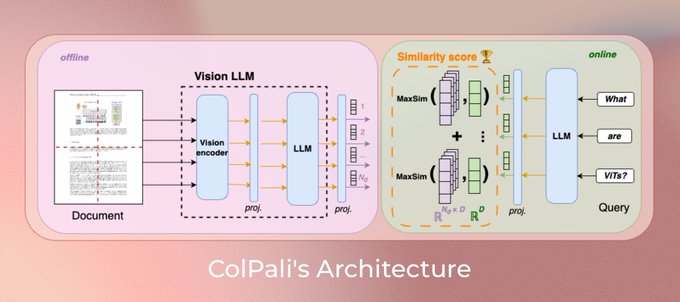
ColPali
ColPali 模型架构概述 来源
ColPali 基于以下两个观察:
理解具有丰富布局和多模态组件的文档一直是一个重要且实用的任务。最近的大型视觉语言模型(LVLM)在各种任务中取得了显著进展,特别是在单页文档理解(DU)方面。
引自 3。
ColPali 模型通过端到端训练来优化页面检索任务。它将网格单元(patch)投影到 128 维的嵌入空间中。文本查询表示也被投影到相同的 128 维空间,每个文本 token 都有一个对应的向量。与 ColBERT 类似的是,模型使用后期交互评分机制(MaxSim)来计算查询 token 向量和页面图像 patch 向量之间的相似度得分。
大多数信息检索(IR)基准测试(如BEIR)不包含复杂的文档格式,开发人员得到的是干净和预处理过的文本。这与现实世界中的情况相差较远,现实中的文档往往包含复杂的元素,如图像、表格和图表。
为了克服这一点并将 ColPali 与其他检索方法进行基准测试,ColPali 的作者引入了视觉文档检索 (Visual Document Retrieval, ViDoRe) 基准。
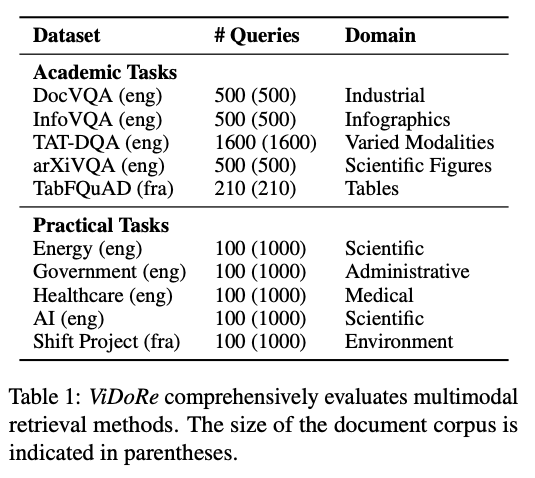
ColPali
视觉文档检索 (ViDoRe) 基准的组成。截图来自论文2

ColPali
ViDoRe 中的查询示例和文档页面。截图来自论文2ColPali 模型在引入的 ViDoRe 基准测试中取得了显著的检索性能,超过了涉及 OCR、布局分析、大型 VLMs 标注和文本嵌入模型的复杂流程。
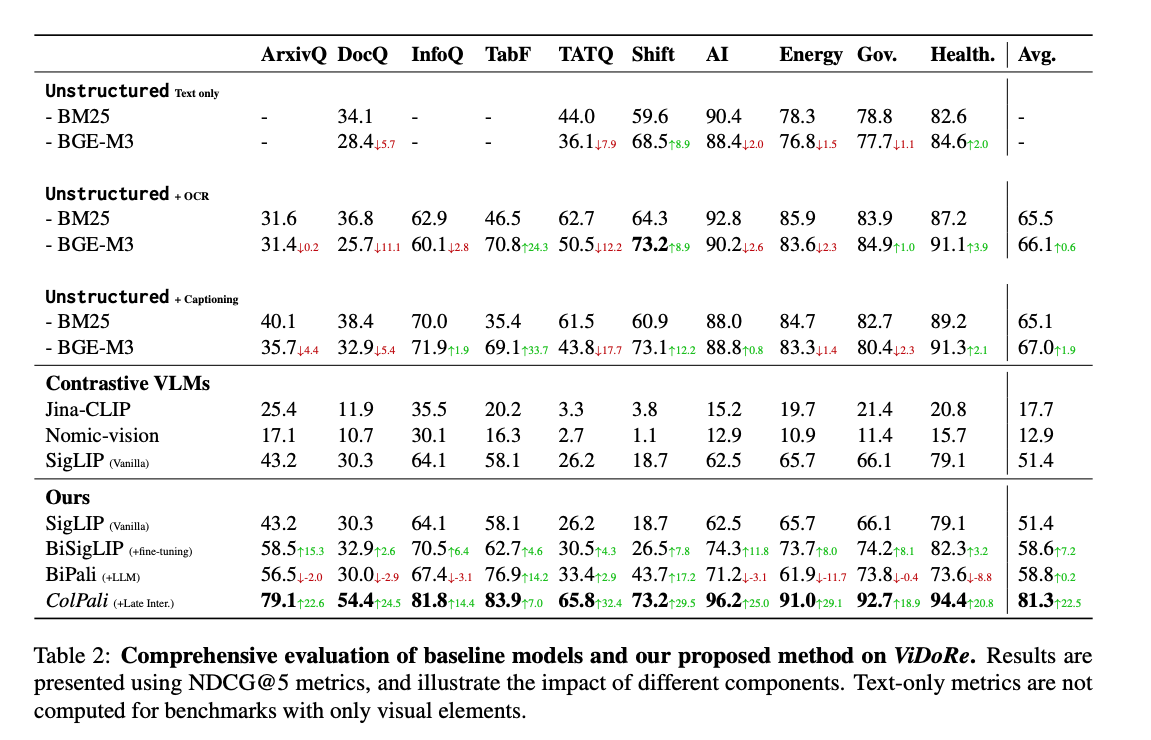
ColPali
在视觉文档检索基准 (ViDoRe) 上评估的检索方法。截图来自论文2
作者将 ColPali 与其他检索模型进行了比较:
BM25 和 BGE-M3 都是基于文本的检索模型,而 ColPali 的表现更为出色,nDCG@5 的得分为 81.3,相比之下,BM25 和 BGE-M3 的得分在 65 到 75 之间。作者还将其与对比单一向量视觉模型(如 Jina-CLIP 和 Nomic-vision)进行比较,但由于这些模型未在此任务上进行训练,表现较差。
除了效果上的显著提升,更重要的是 ColPali 模型的简单性;只需嵌入页面图像即可。
我们编写了一份完整的笔记本,如果你想立即动手试试如何在 Vespa 中使用 ColPali 嵌入,可以点击这里。
利用 Vespa 的张量框架和计算引擎,我们能够表示 ColPali 嵌入,并在 Vespa 排名表达式中实现后期交互评分,这和使用ColBERT的方法类似。
在 Vespa 中,我们可以通过两种主要方式表示 PDF 文档的 ColPali 嵌入:
tensor<float>(patch{}, v[128]),其中第一个维度是补丁 ID,第二个是稠密向量嵌入。tensor<float>(page{}, patch{}, v[128])。通过二值化处理,我们还可以使用 tensor<int8>(page{}, patch{}, v[16]),有关类似 ColBERT 嵌入的二值化详细信息,请参见colbert。与 float 格式相比,二值化可以将存储空间减少 32 倍,与半精度的 bfloat16 格式相比可以减少 16 倍。
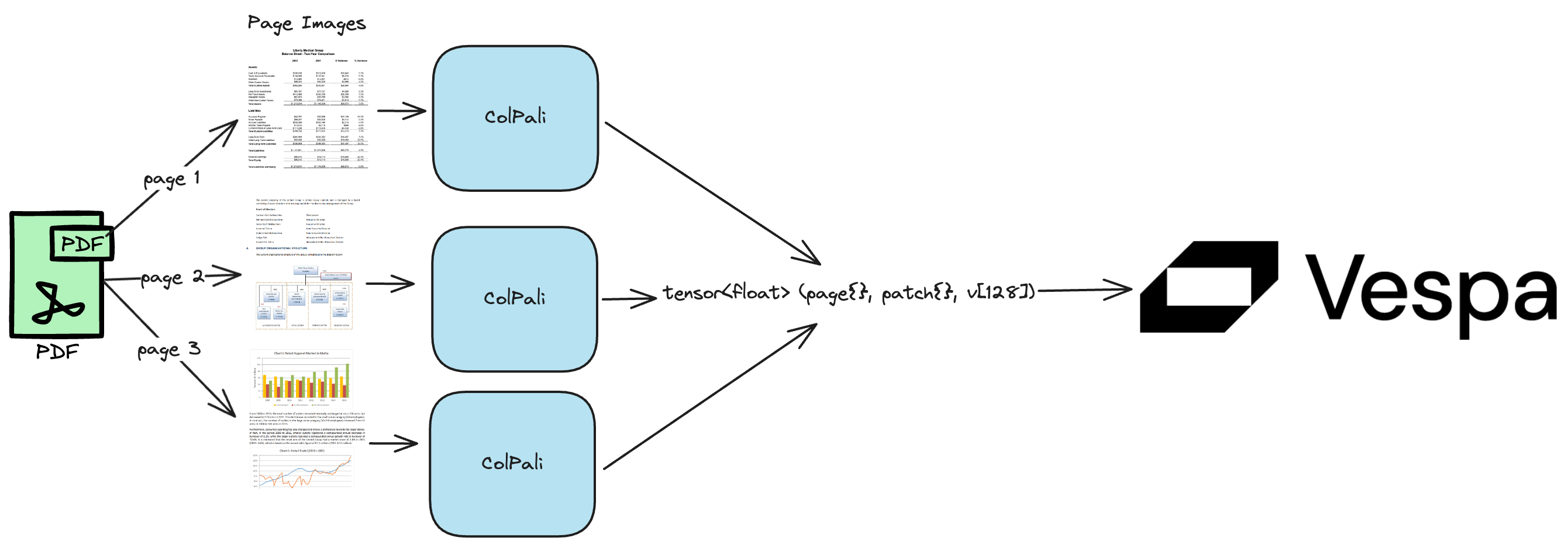
ColPali
像其他检索模型一样,你可以构建自己的评估数据集。这是唯一能判断某个方法是否比其他方法在你的_数据_上表现更好的方法。在基准测试中,他们将仅文本模型与 ColPali 进行比较,你也可以用你的数据进行类似的比较。
我们使用 base64 编码将图像数据存储为字符串字段在 Vespa 中。这使我们能够将图像数据直接存储在 Vespa 的文档中。此字段仅用于摘要目的,实际的嵌入存储在张量字段中。
因为 BM25 是一种强大的基线模型,计算成本低,可以作为分阶段排名管道的第一阶段。此外,我们不需要为高效检索 ColPali 嵌入构建索引结构,但仍然可以在排名阶段使用它们(无需移动向量数据)。
你可以使用 ColPali 嵌入进行端到端检索和排名,请参阅这个笔记本获取灵感,了解如何在 Vespa 中使用 ColBERT 嵌入进行端到端检索和排名。
它可以在这里找到,还可以查看其他资源:
在演示文档中,我们使用了以下排名配置文件,通过使用分阶段排名,第一阶段使用 BM25 算法(适用于整个 PDF 内容),第二阶段使用 ColPali 嵌入(适用于页面级嵌入)。查询的 ColPali 嵌入称为query(qt),文档的嵌入称为attribute(colbert)。ColPali 查询嵌入是通过将查询文本输入 ColPali 模型获得的,我们称该维度为querytoken{}。注意,输入使用的是全浮点精度,二进制补丁嵌入位的解包是在排名表达式中完成的。
from vespa.package import RankProfile, Function, FirstPhaseRanking, SecondPhaseRanking
colbert_profile = RankProfile(
name="default",
inputs=[("query(qt)", "tensor<float>(querytoken{}, v[128])")],
functions=[
Function(
name="max_sim_per_page",
expression="""
sum(
reduce(
sum(
query(qt) * unpack_bits(attribute(colbert)) , v
),
max, patch
),
querytoken
)
""",
),
Function(
name="max_sim", expression="reduce(max_sim_per_page, max, page)"
),
Function(
name="bm25_score", expression="bm25(title) + bm25(texts)"
)
],
first_phase=FirstPhaseRanking(expression="bm25_score"),
second_phase=SecondPhaseRanking(expression="max_sim", rerank_count=10),
match_features=["max_sim_per_page", "bm25_score"],
)
colbert_schema.add_rank_profile(colbert_profile)
PDF 文档按最高页面得分进行排名。不过,我们可以通过匹配特征访问所有页面级别的得分。
匹配特征使我们能够显示每个 PDF 文档的前 k 页(或将其输入到读者 VLM 中,或两者兼有)。
这种表示方式类似于我们在Vespa 长上下文 ColBERT中所做的,并且还允许跨多个页面进行评分。我们将这些方法称为上下文级 MaxSim 和跨上下文 MaxSim。在这种情况下,当我们有页面级别的视觉表示时,可以称其为页面级 MaxSim 和跨页面 MaxSim,使用 ColPali 向量嵌入。
演示文档还展示了如何将检索到的前 k 个截图输入到一个强大的视觉 LLM 中。在我们的例子中,我们使用Gemini Flash。
import google.generativeai as genai
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
response = model.generate_content([queries[0], image])
借助 ColPali 和 Vespa,我们可以为 PDF 等复杂文档格式构建一个完整的 RAG 管道,仅需使用文档页面的视觉表示。
使用视觉大语言模型 (Visual LLMs) 来表示文档文本是一种简化复杂文档格式检索流程的有效方法。ColPali 是一个利用视觉大语言模型进行文档检索的优秀示例。通过直接嵌入文档截图,ColPali 消除了复杂的预处理步骤,使文档检索更加高效。在 ViDoRe 基准测试中的结果表明,ColPali 相对于传统的基于文本的检索模型具有更高的有效性。
将 ColPali 与 Vespa 结合,开发者可以为复杂的文档格式(如 PDF)构建强大的 RAG 管道,仅使用文档页面的视觉表示。如果我们像在演示笔记本中那样从 PDF 中提取文本,开发者还可以根据文本内容进行过滤和排序,例如按日期、作者或其他元数据进行过滤。这些功能是 Vespa 自带的特性。
Vespa 的一个优点是其张量框架及其优化的张量计算引擎,允许在不需要自定义插件、扩展或开发时间的情况下,在 Vespa 中表示像 ColPali 这样更复杂的模型。
ColPali 模型最初是在 PDF 上训练的,但可以在其他复杂文档格式如 HTML、Word 等上进行微调。通过在多种文档上训练模型,可以确保其在多种格式的文档上表现良好。我们认为这是在复杂文档格式上进行检索的一个有前景的方向。
与其他视觉大语言模型一样,ColPali 可以在任何语言的文档上进行微调。通过在多种文档上训练模型,可以确保其在多种语言的文档上表现良好。
模型能适应新任务吗?与更复杂的多步骤检索流程不同,ColPali 可以端到端训练,直接优化下游检索任务,这大大促进了在专门领域、多语言检索或模型难以处理的特定视觉元素上的微调性能。为了演示这一点,我们在训练集中加入了 1552 个法语表格及其相关查询样本。这是训练集中唯一的法语数据,其他所有示例保持不变。
引自 2。
ColPali 并不处理多页文档,它的训练是基于页面级的图像。我们展示了一种方法,可以通过增加一个张量维度来表示页面,例如 tensor<float>(page{}, patch{}, v[128])。
可以,ColPali 可以与其他检索模型结合使用以提升性能。将 ColPali 嵌入作为检索流程中的附加特征,可以提高文档检索系统的准确性。这也适用于在 GBDT 或其他模型中将 ColPali 嵌入作为一个特征使用。
patch 是图像中的一个网格单元。
该模型每张图像会生成 1030 个 patch 嵌入,每个 patch 的嵌入维度为 128。使用 bfloat16 格式时,这些数据大小为 256KB。通过二值化处理,可以将其压缩到 8KB。
该模型大约有 30 亿个参数,比许多流行的文本嵌入模型参数少。编码一个短查询比编码整页图像要快得多。
基础模型是 PaliGemma 3,这是谷歌发布的一个强大的视觉语言模型。该模型是受限的,并且具有资源使用限制。
MaxSim 的一个优点是可以将查询 token(查询 token)向量表示与 patch 嵌入进行比较,找出页面截图中哪些区域(网格单元或 patch)对分数贡献最大(针对每个查询词向量)。
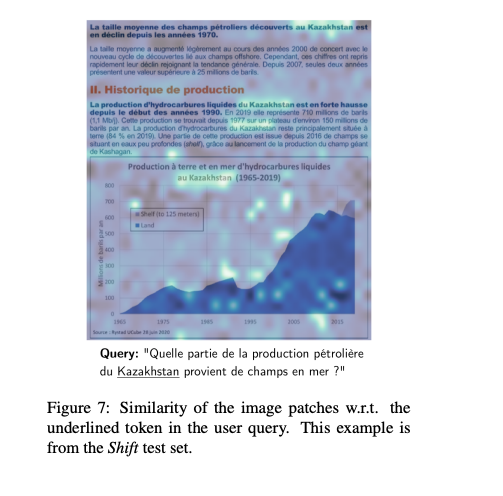
ColPali
可解释性分析。截图来自论文 2
你可以像其他检索模型一样,构建自己的评估数据集。这是唯一能够确定某种方法是否在你的_自身_数据上表现更好的方式。在基准测试中,他们比较了仅文本模型与 ColPali,你也可以用你的数据做类似的比较。
我们使用 base64 编码将图像数据作为字符串字段存储在 Vespa 中。这使我们能够将图像数据直接存储在 Vespa 文档中。这个字段仅用于摘要,实际的嵌入存储在张量字段中。
因为 BM25 是一个强大的基线模型,计算成本低,可以用作分阶段排名管道的第一阶段。此外,我们不需要为高效检索 ColPali 嵌入构建索引结构,但仍然可以在排名阶段使用它们(而且不需要移动向量数据)。
你可以使用 ColPali 嵌入进行端到端检索和排名,参见这个笔记本,了解如何在 Vespa 中使用 ColBERT 嵌入进行端到端检索和排名。
它可以在这里找到,还可以查看其他资源:
如果你对 Vespa 或 ColBERT 感兴趣,可以加入 Slack 上的 Vespa 社区 或 Discord 与大家交流,寻求帮助,或获取最新动态。
文章来源于“宝玉”
![使用视觉语言模型进行 PDF 检索 [译]](https://www.aitntnews.com/pictures/2024/7/21/24b726b7-4728-11ef-8a7c-fa163e4b35c9.jpg)



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
