# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
更低门槛,更高质量,更有逻辑,更长时长。
这几个“更”,让上午刚刚亮相的国产AI视频新产品PixVerse V2,热度唰一下就上去了。
而且它出身很吸睛:
来自这条赛道上最受关注的国内明星创业公司爱诗科技,仅今年上半年,该公司就完成了两轮融资。

直接看Pixverse V2有哪些重点“新意”:
模型技术方面,采用了DiT(Diffusion+Transformer)架构,同时在多个方面运用独创技术显著提升生成效果。
如引入时空注意力机制等,实现运动幅度更大、更自然的视频生成。
且看下面这个小羊驼快乐冲浪,就和今天LIama 3.1发布即登顶很应景。

视频数量与质量方面,支持一键生成至多5段连续的视频内容。
且片段之间会自动保持主体形象、画面风格和场景元素的一致性。

除此之外,爱诗官方介绍还说明,新产品的提示词门槛又被砍了狠狠一刀。
不论是否学过提示词技巧, 只需言简意赅表达清楚画面需求,就能简单实现。而且中文语境同样适用。
再加上一次生成的几段视频之间,有风格、主体和场景的一致性——
现在制作一条短视频不仅不需要自己拍,连剪都不需要再自己剪了。
一键生成,直接上传各个平台分享,鹅妹子嘤!

既保质又保量,门槛还一低再低。
AI视频创作已经被爱诗PixVerse、Runway、Luma等卷得昏天黑地的公司们,卷入了全民能玩转的时代。
不过,等一下!
我们是绝对不会轻易被各个公司放出来的demo蒙蔽双眼的。
于是,今天上午发现PixVerse V2上线后,量子位第一时间进行了人肉实测。
进入PixVerse官网,在左侧菜单栏直奔PixVerse V2。
目前它支持文/图生视频两种生成模式,实际操作中可以二者取其一,也可以两个一起上。
文字输入提示词框,图片点击下图黄色框选部分即可上传。
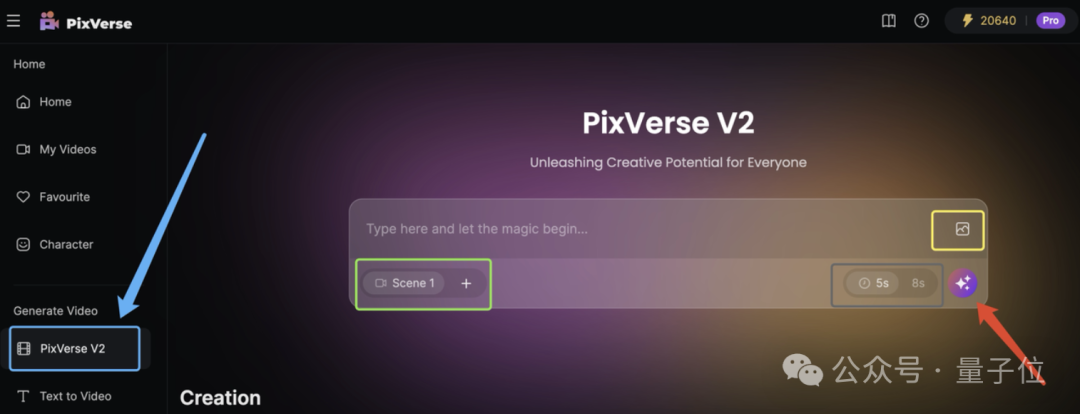
输入框右下角,灰色框选部分,还有个5s/8s的选项,可以根据自己的需求选择生成的单个视频片段的长度。
绿色框选的Scene,指代的是需要生成的具体视频片段。
确实如官方介绍所说,现在至多能添加至生成5个视频,分别是Scene1-5。

所有Scene片段的画面风格都会跟着Scene 1来,即便后面的其他Scene上传了参考图片,PixVerse会参考Scene 1的图片风格进行重绘。
总之,就是想尽一切办法让5段视频保持风格一致。
此外,每个Scene的提示词/提示图片都可以单独输入。
完事儿后就可以点击输入框右下角的星星按钮,进入生成状态。
体验后发现,无论需要生成几个Scene,每次生成都需要花费50 Credits(PixVerse V2的算力货币)。
体验过程中,秉承着输入尽可能简单的prompt的原则,咱输入的五段提示词分别是这样的:
虽然生成后,可以通过选项对每段视频分别进行微调(调整主体、场景、动作和运镜),但我们没有进行任何干预,主打一个想要原汁原味。
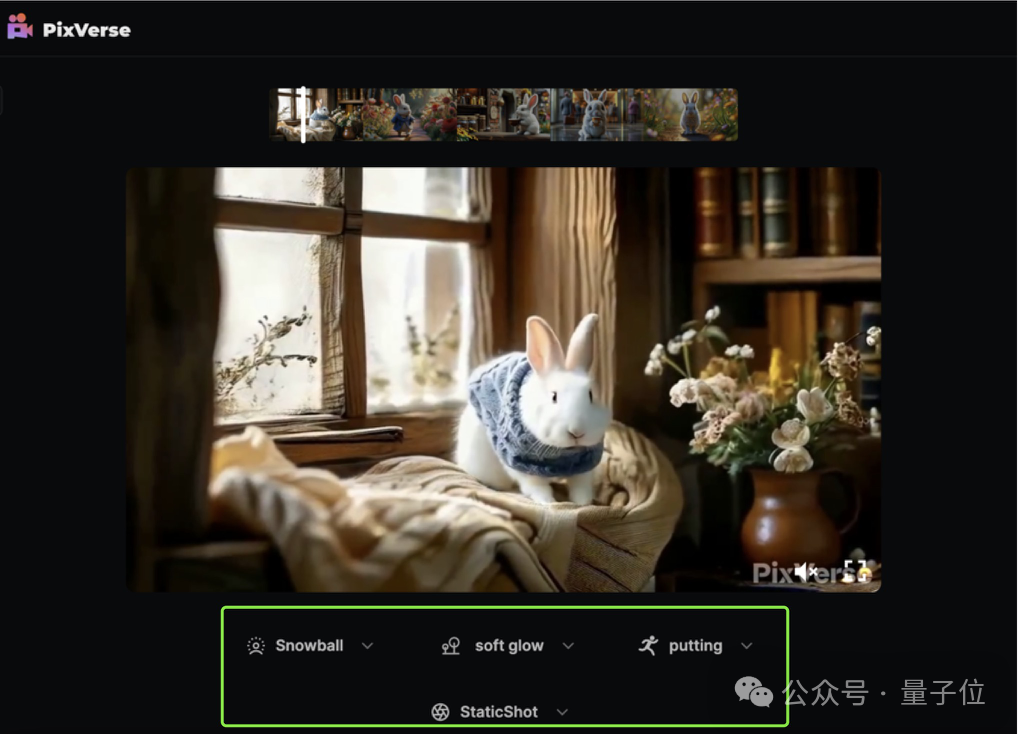
生成结果如下:

5个片段是已经拼接好了的,可以直接下载完整版,很方便。
有点搞笑,视频内容里,辞职了的小白兔pia就把工装脱掉了,不带走一点班味。
上手玩到这一步,精打细算如我等打工人,有个绝妙发现,一定要跟大家分享一下:
如果每次只想生成一个视频片段,直接在PixVerse V2的选项调整里,删减到只有Scene 1,就ok——我们称之为办法1。
但还有另一种办法(办法2),通过另一个入口进入PixVerse V2的另外模式。
办公室里问了一圈,如果要生成单个视频片段,大家都更愿意选择后面这种办法。
为啥?
一来,办法2能根据视频比例、视频风格等参数做更多的调整,你给的“想要”的信息越多,那模型就更有可能懂你,生成的视频画面就更可能符合心意。
另一方面,小算盘噼里啪啦一算,办法1一次生成消耗50 Credits,无论是生成1个片段还是5个片段,都得扣这么多;但办法2生成一次,只需要消耗30 Credits。
更省钱啊,朋友们!

快在脑子里拿小本本记好,办法2的操作流程——
点击左侧菜单栏中的Text to Video,然后在“Model”选择 “PixVerse V2”。
就能进行文生视频了。
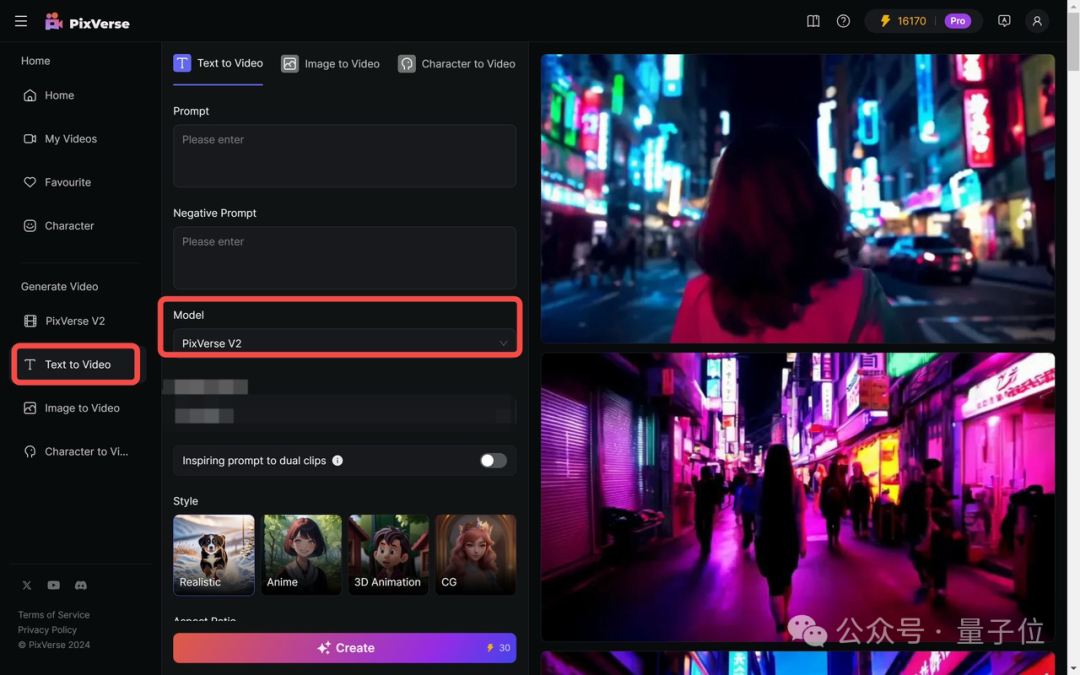
且通过在提示词中加入“Anime”“Realistic”等词语,可以让生成内容进行风格变换。
整点有难度的,生成一些现实世界没有的场景。输入提示词:
棉花糖巨人在彩色的棉花糖森林里漫步。
生成结果:

好好好,unbelievable,想不到真的可以get到“棉花糖巨人”这么抽象的描述!
盲猜是因为PixVerse V2背后对语义理解进行了显著优化。
类似方法也可以体验图生视频功能。
点击左侧菜单栏的Image to Video,在“Model”选择“PixVerse V2”。
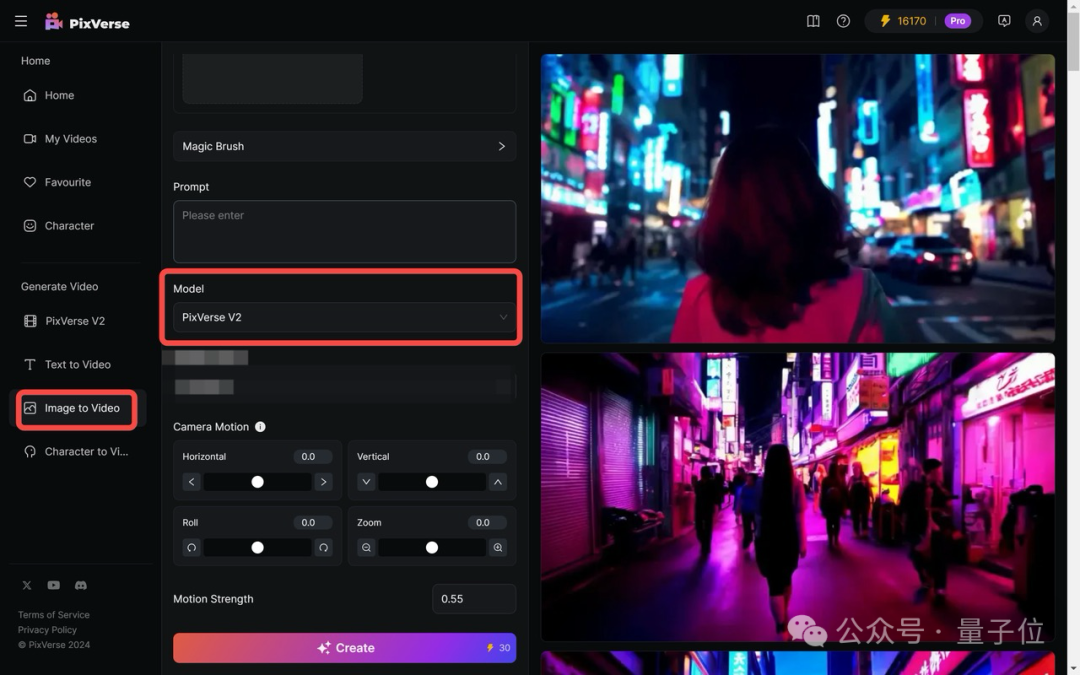
小小遗憾,目前PixVerse的图生视频还不能使用前面提到过的运动笔刷。
需要注意的是,目前图生视频还不能使用“涂哪哪动”的运动笔刷(这是爱诗上个月上新的AI视频功能)。
量子位向PixVerse V2团队打听到,运动笔刷很快也会上线在V2版本里。
之前Runway和PixVerse的运动笔刷都广受好评,因为它弥补了提示词描述的不足,增强了画面的运动可控性等。
如果PixVerse V2上线该功能,想来大家玩起来会更爽,视频中人物/物体的运动也更符合物理规律。
鉴于人物或者动物“走秀”一直都是AI视频秀肌肉的必选项(虽然咱也不知道为啥),这次在体验PixVerse V2图生视频功能时,咱直接上强度,搞了个宇航员在街头跑酷。
输入提示图片:

生成结果:

这个任务属于有点叠buff,是基于图片生成非现实内容的动态。
更需要的是背后模型有很强的视觉理解能力。
从效果来看,不管是连续视频创作、文生视频还是图生视频,PixVerse V2都能轻松拿下。
最后多提一嘴,不管是文生还是图生,每生成一个5s/8s视频,都需消耗30 Credits。
不过生成速度算比较快,质量也稳定有保障,实际感觉花这30 Credits还算挺值得。
在号称今年卷王之王的AI视频赛道,爱诗突然放出了不太一样的一招。
当全世界范围内所有的Sora平替在做时长拓展、画质提升和难度降低时,爱诗做的还有狂削门槛。
不仅仅是提示词不需要太专业,更重要的是一次能创作(至多)5条视频,每段8秒。
这1到5个视频片段之间,风格、主体、场景的一致性是能够保证的,并且根据每段视频提示词之间的逻辑,最终合成一段40秒左右的长视频。
剧情连贯、内容一致性的那种。
号称“动作流畅、细节丰富”,且画质达到1080p。

也就是说,用户想好自己想要什么,输入提示词,就能坐等生成拥有10s-40s时长不等的视频。
既能在画面中实现“把脑子里的想法搬到视频里”,片段之间连贯自然;还能在视频制作过程中少费时费力,创作效率猛猛提升。
PixVerse V2发布后,很快就有网友用起来了。
比如下面这个,就是网友Steven Eddie专门为了测试体验新产品一致性而创作的小故事片:

PixVerse V2的出现,让很多没用过AI视频工具,甚至从未制作过视频的人,都能靠它完成生成数量上0到5,作品数量上0到1的突破。
AIGC工具的使用权,再一次下放。
它带来的AIGC工具用户破圈层(不再局限在专业用户之间)外扩,是靠技术迭代更新来实现的。
PixVerse V2背后,是爱诗科技对DiT架构底层自研模型的迭代更新。
这也是PixVerse背后的核心技术。
前情回顾一下,量子位梳理此前爱诗公开资料/王长虎对外演讲发现,最开始,该公司采用过Diffusion+Unet架构的技术路线,这也是Sora问世前的主流AIGC做法,但越往后走,参数扩张、指令复杂,Unet就有点不够用了。
因此,爱诗很早(Sora出现前)开始尝试DiT架构,并沿着Scaling Law来提升模型性能。
车头调转得很早,因此Sora的出现倒没有让爱诗措手不及,反而因验证了路线的正确,爱诗今年的速度明显加快。

那么,这次PixVerse V2的DiT底模有哪些更新?
第一点,在Diffusion时空建模方面。
爱诗独创了一种时空注意力建模机制,且是“更合理的”,它优于时空分离以及fullseq架构。
这种机制对时间、空间的感知力都更好,对复杂场景的处理也更好。
第二点在文本理解方面。
PixVerse V2对于prompt的理解能力显著增强。背后是运用上了多模态模型,能够更好地对齐文本信息和视频信息,让生成结果即创作者所想。
第三,为了获得更高的运算效率,PixVerse V2在传统的Flow模型基础之上,对损失进行了加权,使得模型可以更快更好的收敛。
还有一点,则是PixVerse V2背后,研发团队设计了一个更好的3D VAE模型。
其中引入了时空注意力机制,来提升视频压缩质量;同时采用持续学习技术进一步提升视频压缩及重构结果。

AIGC简直是今年最妇孺皆知的话题。
但对AIGC进行应用的能力,其实还掌握在少部分人手中,如程序员、设计师等专业人士。
AIGC还没有像UGC那样,进入全民“GC”的阶段。
面对这样的情况,爱诗科技成立一年多以来做的事,可以总结归纳为:
这一点不仅体现在PixVerse V2上,往前看也是一脉相承——
复盘发现,PixVerse V2的发布,其实已经是今年以来这家公司第三次在AI视频功能和产品上有所动作。
今年1月,爱诗正式发布文生视频产品PixVerse网页版,月访问量迅速突破百万。
4月,发布基于自研视频大模型开发的C2V(Character to Video,角色一致性)功能,网页端可使用。
通过精确提取人物特征,并深度嵌入到视频生成模型中,PixVerse能够锁定角色,初步解决AI视频创作中的一致性难题。
6月,发布Magic Brush运动笔刷,拿它对视频画面涂涂抹抹,能精确控制视频元素的运动及运动方向。
这也是继Runway后,首家发布类似功能的AI视频生成公司。
半年三次,不可谓不频繁,但前两次的动作,似乎都有些低调了。
这或许与创业公司希望潜心打磨作品有关,又或许与王长虎等带队者的低调性格有关,我们不得而知。
但现象就是,很多人知道国产AI视频赛道上,爱诗科技是奔驰在前的头部,却不一定知道它到底为什么是头部,到底好不好用。
现在PixVerses V2一出现,老的少的、专业的非专业的,都可以亲自上手,感受它确实效果整挺好——这也是PixVerse V2上线即爆火的原因之一。
以及回溯种种动作,不难发现,这数次产品能力的上新,都在围绕一个主体:让AI视频创作更实用更简单。
同时可以看到,前几次产品能力,重点关注的是专业人士的使用体验。
这也和王长虎此前发言的相互印证,他曾表示:
希望AI原生视频能够融入内容行业的生产和消费链路。
而PixVerse V2就不一样了,这一代产品着重打磨的是,如何让更广大的普通人群都能上手进行AI视频创作。
毕竟,Magic Brush虽然好用、有用,但大前提还是需要用户已经生成了一段AI视频。
而视频prompt比文本生成、文生图的prompt都要难,很多时候都是普通人来玩AI视频生成的拦路虎。
PixVerse V2抓的点就很妙——
从压低提示词难度、选项式微调、拓展生成内容边界、后期免剪辑等各个方面,尽量把AI视频创作成本一压再压。
会得到什么结果呢?
所有人,人人有机会,人人能参与,能把天马行空的脑洞变成看得见的视频作品。
因为能有很强的参与感,因此会有更多人,甚至所有人都能释放创意,参与到AI视频创作当中来。
长期来看,逐渐就能形成AI时代的UGC生态,而且比UGC更简单、更有趣。
之前看过有意思的一个meme图,相信不少朋友也见过:

“PixVerse很荣幸‘跪’在了第一排,跟Runway、Pika、SVD等当时最好的视频生成产品放到一起,也是这张图里面唯一一家中国公司。”王长虎本人曾拿着这张图开玩笑,“但另一方面,我们前面有一个巨人,还需要进一步超越它。”
不可否认,AI视频是AI 2.0时代多模态赛道的焦点,尤其是Sora掀起巨浪之后。
所有巨头、大厂、创业公司的十足干劲,都在说明一个问题。
AI视频正在扩宽和激发市场的潜力,AI多模态大模型驱动的创新正在增长。
爱诗能出现在这张meme图上,而且是作为唯一一张登图的中国公司,原因非常明显。
一方面,爱诗科技的模型技术,与自研底模上长出的产品效果,确实受到认可。
另一方面,无论在哪一波科技浪潮中,创业公司都会被全球目光重点关注。
搜索大战时期,谷歌利用创新的网页排名算法PageRank,抢夺雅虎的用户,甚至后来者居上,成为搜索市场至今独占鳌头的那一位。
大语言模型初期,Transformer虽然出自Google,但GPT则是(当时)小型研究机构OpenAI的创举,一步步走到今天的GPT-4o,成为被追逐的对象。
而今天OpenAI的追逐和竞争者中,就有Google的身影。
在任何时候,哪怕面临大厂巨头围攻,创业公司迸发出点燃行业的火花、闪耀星光的故事从不缺席。
爱诗科技正在用技术和产品书写的,就是AI视频赛道,属于创业公司自己的故事。
文章来源于“量子位”,作者“关注前沿科技”




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
