# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
数据对LLM训练而言是至关重要的存在,但我们的关注点往往放在训练和评估数据,而会忽略微调数据。
比如Llama系列模型,虽然开放了权重(如Llama-3-Instruct),但微调数据集依旧是私有的。
LLM的成功有很大一部分取决于指令微调(instruction fine-tuning),这个过程能让模型更好地泛化到训练过程中没有接触过的任务。
正如训练的有效性依赖于训练语料的质量,指令微调的有效性也取决于能否获得高质量的指令数据集。
然而,相比于无标注的自监督训练语料,高质量微调和对齐数据集更加难以构建、扩展,因为需要更多人工标注,而且存在预先定义的提示范围。
就连专门为AI科技巨头提供数据的公司Scale AI,在目前阶段都无法实现自动化标注,甚至得高薪聘请专业人士参与微调和对齐数据集的构建。
Scale AI的CEO Alexandr Wang曾表示,LLM合成数据是一个很有前景的解决方案。
最近,华盛顿大学和研究机构Allen AI联合发表的一篇论文就专注于如何让对齐过的LLM合成高质量的微调数据。

论文地址:https://arxiv.org/abs/2406.08464
论文提出的方法实现了全流程的自动化,不需要任何种子问题。更为惊艳的是,代码不仅能在本地运行,而且用LLM自动生成了非常可靠的高质量数据。
他们用Llama-3-8B的Base模型在自己生成的SFT数据集上微调后,得到了比官方微调版本Llama-3-Instruct性能更强的模型。
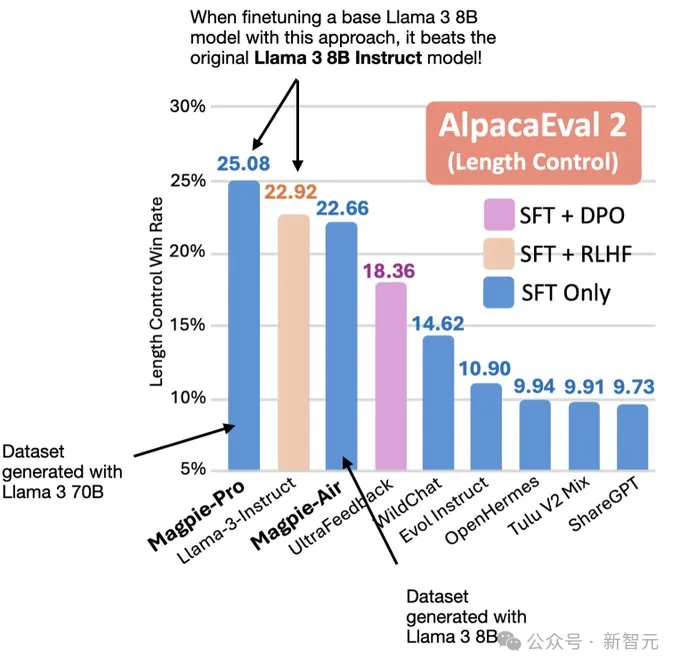
论文得到了AI圈大佬Sebastian Raschka的转发背书。
起初,他也不相信这种方法真的能够在MacBook Air上本地运行,但亲自尝试后惊喜地发现,真的可以。

Raschka是多本技术畅销书的作者,包括《从头开始构建大语言模型》、《Python机器学习》等,他目前担任Lightning AI的研究工程师。


论文的第一作者Zhangchen Xu是华盛顿大学网络安全实验室的二年级博士生,师从Radha Poovendran教授,研究兴趣是机器学习的安全性、隐私性和公平性,目前关注如何构建可信LLM。

那就让我们仔细探究一下,这种高效的数据合成方法究竟如何实现。
典型的LLM输入一般由3个部分组成:
- 查询前模版(pre-query template)
- 查询内容(query)
- 查询后模版(post-query template)
其中的两个模版一般由模型开发者预先定义,以保证正确地提示模型。
比如Llama-2-chat的输入形式就是:
[INST] Hi! [/INST]
在之前的研究中,通常有两种方法构建微调数据集。一是直接让人类手动制作,显然既耗时间又耗资源。二是从少量人工注释的种子指令开始,通过提示调用LLM以合成更多指令。
第二种方法虽然节省人力,但非常考验提示工程的水平,以及对初始种子问题的选择。换言之,很难实现可控的大规模扩展。
更为致命的问题是,合成的指令往往与种子指令十分接近,这会严重影响大规模数据集的多样性。用可扩展的方式,创建高质量且多样化的指令数据集,依旧是LLM领域具有挑战性的问题。
但作者在早期实验中的有一个有趣的发现:由于LLM的自回归特性,只输入查询前模版时,模型会自动合成查询,而且从内容来看,似乎有不错的质量和多样性。这表明它能够有效利用对齐过程中学习到的能力。
以此为启发,作者提出如下思路构建指令数据集:使用查询前模版作为提示,输入给对齐过的LLM,自动生成指令数据。
如下图所示,每个指令数据实例包含一个或多个指令-响应对(instructon-response pair),且会规定指令提供者(provider)与遵循者(follower)的角色。
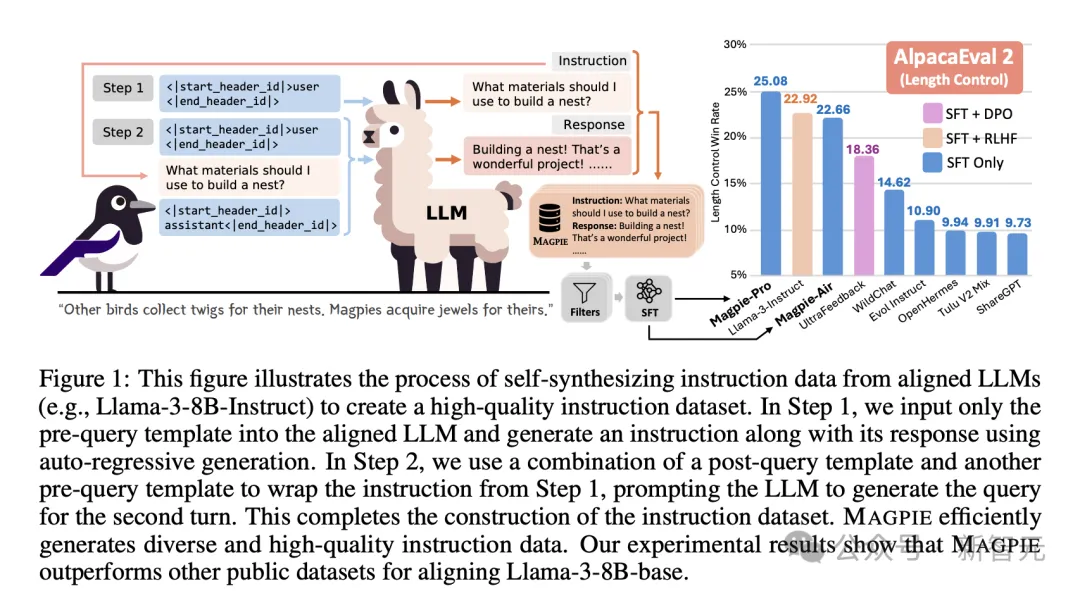
图1描述了整个数据自动生成的pipeline,大体分为两个步骤。
首先是指令生成。MAGPIE方法将查询内容构建为LLM预定义指令模版的格式,但只包含指令提供者(如user),不包含具体的指令内容。
以此作为LLM输入,模型就会以自回归的方式生成指令。由于不需要特定的提示工程技巧,也没有使用任何种子问题,这个流程确保了生成指令的多样性。
第二步骤中,MAGPIE将之前生成的指令再输入给LLM,得到响应内容。
将以上两个步骤进行重复迭代,就能够得到多轮的指令数据。如果想针对某个特定领域生成数据,加上相应的提示即可实现。

得到原始的生成结果后,作者还根据文本长度、任务类别、输入质量、输入难度等指标进行了过滤。
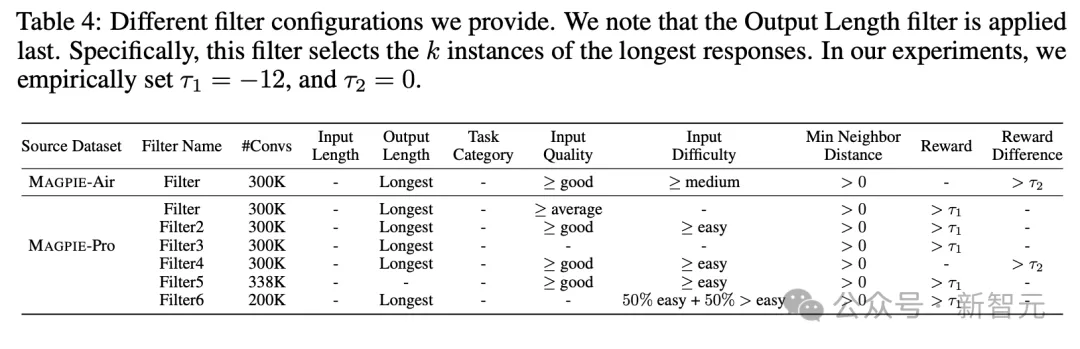
论文分别使用Llama-3-8B-Instruct和Llama-3-70B-Instruct两个模型,构建了两个数据集MAGPIE-Air和MAGPIE-Pro,并在附录中给出了生成指令的示例:

可以看到,文本质量的确不错,完全可以与人类撰写的指令水平相当。
然而,想评估如此庞大规模数据的质量不能只依靠主观感受,于是作者对生成的指令数据集MAGPIE-Pro进行了定量分析。
要考量指令文本的多样化程度,一个有效指标是文本嵌入的在语义空间中的覆盖范围。
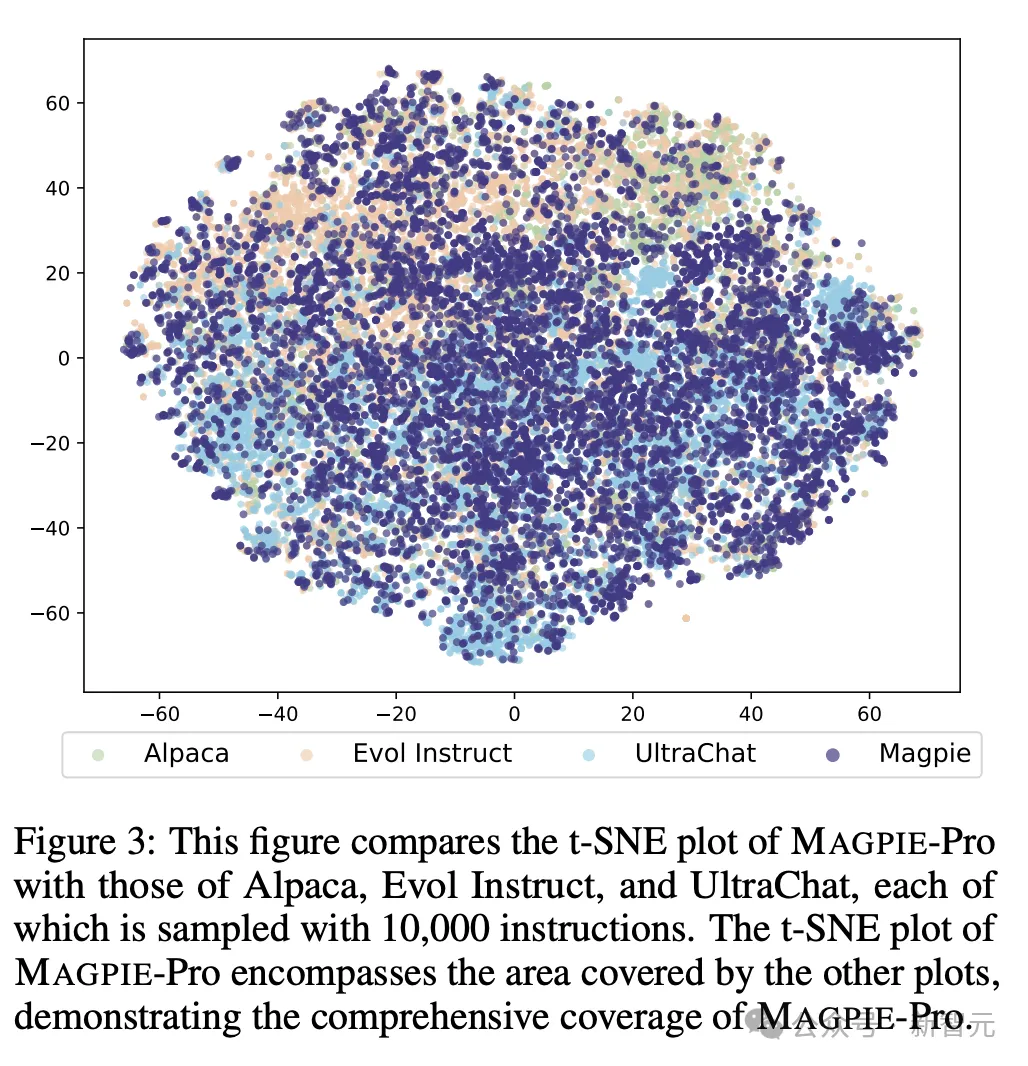
作者从MAGPIE-Pro中随机采样指令文本,编码为嵌入向量并用t-SNE方法投影到二维空间,同时采用三个基线数据集作为对比,包括Alpaca、Evol Instruct和UltraChat。
下图中的每个t-SNE投影点都代表随机抽取的1万条指令。可以看到,MAGPIE-Pro的投影基本将其他三个数据集的范围囊括在内,这表明它提供了更广泛、多样化的主题。
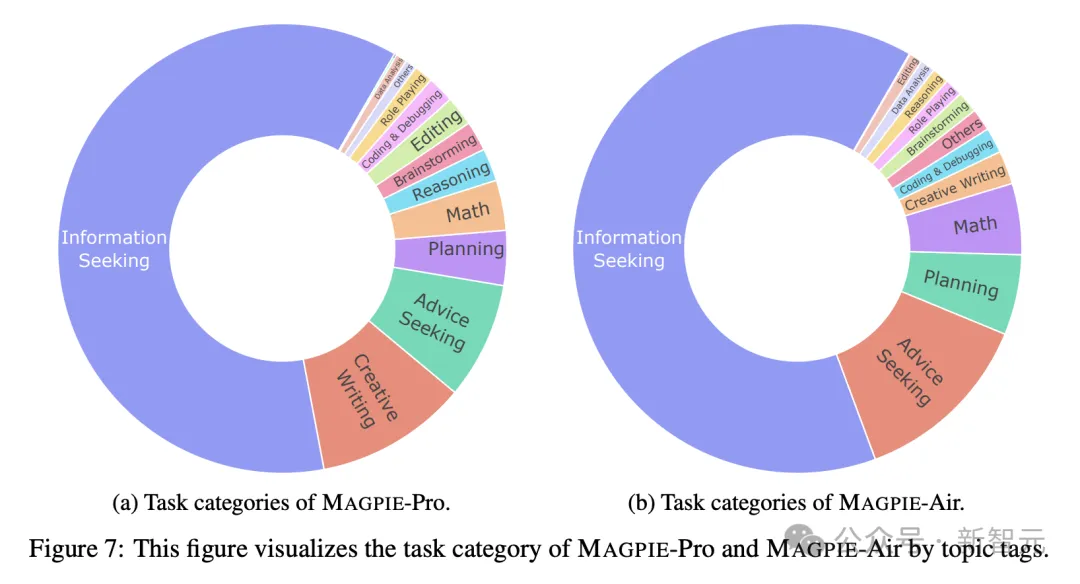
论文使用Llama-3-8B-Instruct模型评估MAGPIE指令数据的各种属性,比如指令的任务类别、质量、难度、相似性和响应质量。
生成指令的任务类别主要是信息检索,占比超过一半,也包括创意性写作、寻求建议、规划、数学、推理、头脑风暴编辑等等,与人类用户的主流需求基本一致。
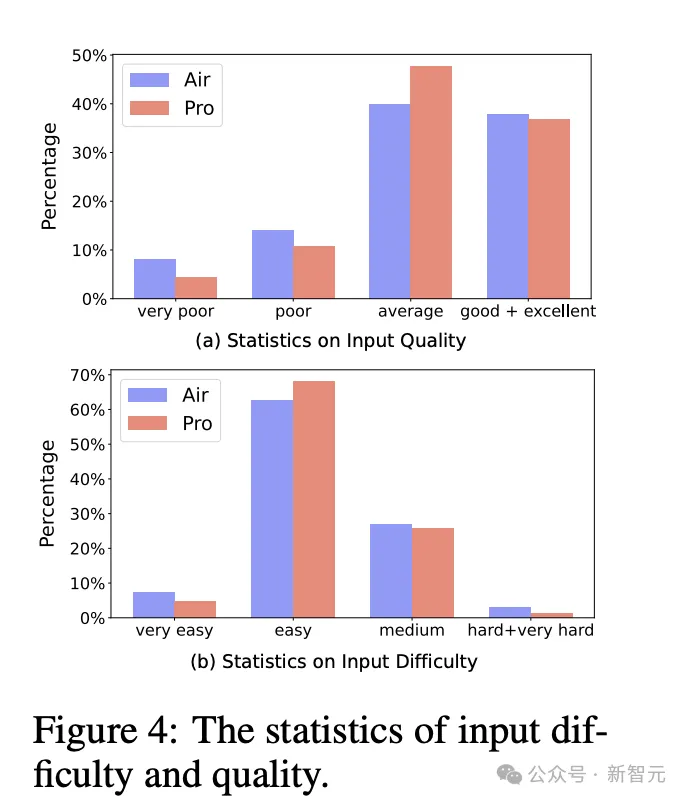
指令的质量和难度同样使用Llama-3-8B-Instruct模型进行自动评估。
可以看到两个数据集中,大部分实例都被判定为平均水平及以上,MAGPIE-Pro的总体质量优于MAGPIE-Air。
数据集指令难度的分布基本类似,超过60%集中在「简单」级别,且Pro数据集比Air略具挑战性。
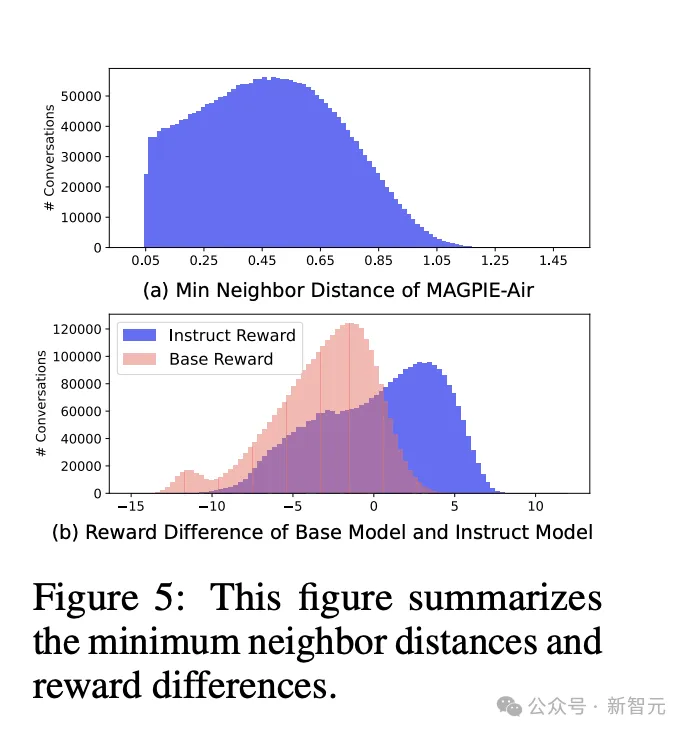
通过计算指令相似度,可以从另一个侧面评估多样化程度。论文使用FAISS搜索每个文本嵌入的最近邻居并计算二者间距离,来衡量相似程度。
响应质量方面,采用FsfairX-LLaMA3-RM-v0.1作为奖励评估模型,同时以URIAL作为对比的基线模型。奖励差异为正值表示质量较高,有利于指令微调过程。
图5b可以看到,MAGPIE的数据分布相比基线模型整体右移且峰值更低,表明整体上响应质量更好。
此外,在指令安全性方面,作者采用Llama-guard-2进行自动评估,发现MAGPIE的数据集绝大部分是安全的,但仍然包含了不到1%的有害指令或响应结果。

这项研究最大的亮点之一在于高效的运行成本,以及完全自动化、无需任何人工干预的pipeline。
在创建3M MAGPIE-Air数据集时,用4块A100 GPU运行1.55小时/50小时即可完成指令/响应的生成。生成1M MAGPIE-Pro数据集则分别需要3.5小时/150小时。
如果在云服务器上运行,成本也非常可观。每生成1k个实例花费为0.12美元或1.10美元,具体取决于是Air或Pro数据集。
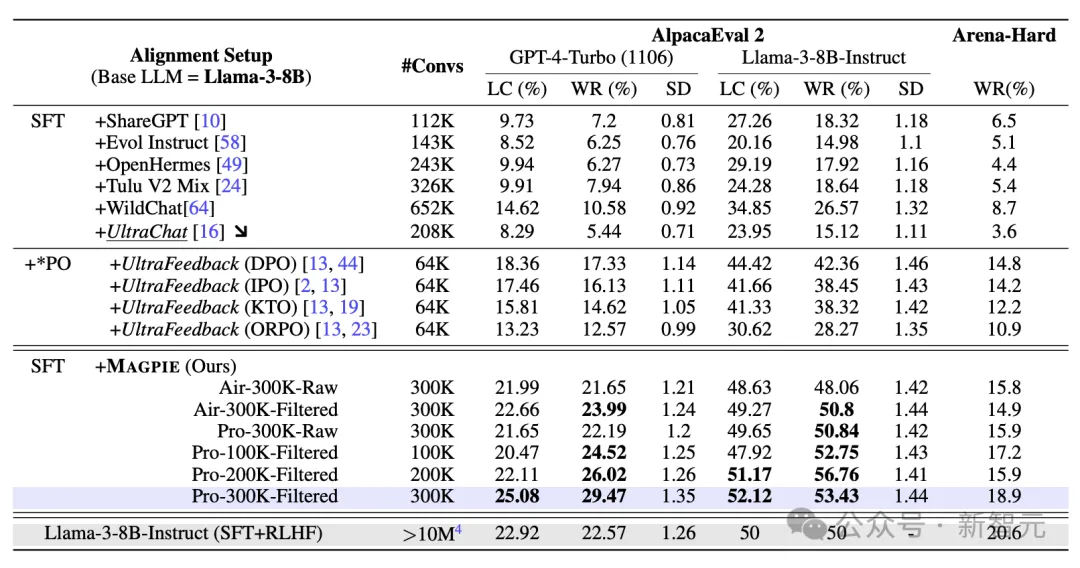
为了真正体现MAGPIE方法的优势,论文将数据集真正运用到基座模型的微调中,与官方发布的微调版本进行对比。
作者选择了ShareGPT、Evol Instruct等6个最先进的开源指令微调数据集作为基线。其中ShareGPT和WildChat由人类撰写,Evol Instruct和UltraChat为合成数据集。
微调的基座模型包括Llama-3和Qwen-1.5,并选取AlpacaEval和Arena-Hard两个广泛采用的指标评估性能。
从两个表格的详细数据对比中可以发现,无论在哪个基座模型上,MAGPIE方法生成的数据集都有更高质量,优于所有的基线数据集,并且在绝大部分指标上优于官方发布的微调模型。

在LLM的scaling law逐渐触摸到数据墙时,这篇论文的方法为合成数据又打开了一扇希望之门。或许使用精心设计的算法与技巧,LLM合成数据能逐渐成为公开数据集的「中流砥柱」。
参考资料:
https://arxiv.org/abs/2406.08464
文章来自于微信公众号“新智元”,作者 “乔杨”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
