# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本工作由来自清华大学、墨尔本大学、香港中文大学、中国科学院大学的 Rui Zhang, Yixin Su, Bayu Distiawan Trisedya, Xiaoyan Zhao, Min Yang, Hong Cheng, Jianzhong Qi 等学者团队联合完成。该团队专注于大模型、知识图谱、推荐搜索、自然语言处理、大数据等方向的研究。
知识图谱作为结构化知识的重要载体,广泛应用于信息检索、电商、决策推理等众多领域。然而,由于不同机构或方法构建的知识图谱存在表示方式、覆盖范围等方面的差异,如何有效地将不同的知识图谱进行融合,以获得更加全面、丰富的知识体系,成为提高知识图谱覆盖度和准确率的重要问题,这就是知识图谱对齐(Knowledge Graph Alignment)任务所要解决的核心挑战。
传统的知识图谱对齐方法必须依赖人工标注来对齐一些实体(entity)和谓词(predicate)等作为种子实体对。这样的方法昂贵、低效、而且对齐的效果不佳。来自清华大学、墨尔本大学、香港中文大学、中国科学院大学的学者联合提出了一种基于大模型的全自动进行知识图谱对齐的方法——AutoAlign。AutoAlign彻底不需要人工来标注对齐的种子实体或者谓词对,而是完全通过算法对于实体语义和结构的理解来进行对齐,显著提高了效率和准确性。

模型介绍
AutoAlign 主要由两部分组成:
总体流程如下图所示:
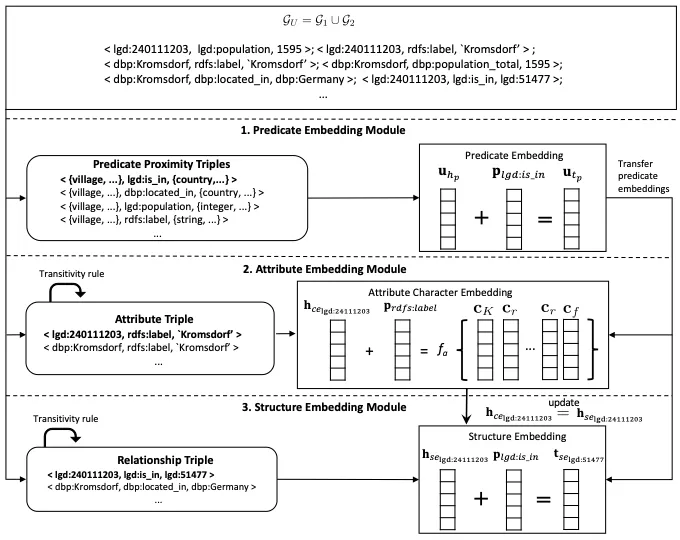
谓词嵌入模块:谓词嵌入模块旨在对齐两个知识图谱中代表相同含义的谓词。例如,将“is_in”和“located_in”进行对齐。为了实现这一目标,研究团队创建了一个谓词邻近图(Predicate Proximity Graph),将两个知识图谱合并成一个图,并将其中的实体替换为其对应的类型(Entity Type)。这种方式基于以下假设:相同(或相似)的谓词,其对应的实体类型也应相似(例如,“is_in”和“located_in”的目标实体类型大概率属于location或city)。通过大语言模型对类型的语义理解,进一步对齐这些类型,提高了三元组学习的准确性。最终,通过图编码方法(如TransE)对谓词邻近图的学习,使得相同(或相似)的谓词具有相似的嵌入,从而实现谓词的对齐。
具体实现上,研究团队首先构建谓词邻近图。谓词邻近图是一种描述实体类型之间关系的图。实体类型表示实体的广泛类别,可以自动链接不同的实体。即使某些谓词的表面形式不同(例如“lgd:is_in”和“dbp:located_in”),通过学习谓词邻近图,可以有效识别它们的相似性。构建谓词邻近图的步骤如下:
为了捕捉谓词相似性,需要聚合多个实体类型。研究团队提出了两种聚合方法:加权和基于注意力的函数。在实验中,他们发现基于注意力的函数效果更好。具体而言,他们计算每个实体类型的注意力权重,并通过加权求和的方式获得最终的伪类型嵌入。接下来,研究团队通过最小化目标函数来训练谓词嵌入,使得相似的谓词具有相似的向量表示。
属性嵌入模块和结构嵌入模块:属性嵌入模块和结构嵌入模块都用于实体(entity)对齐。它们的思想和谓词嵌入相似,即对于相同(或相似)的实体,其对应的三元组中的谓词和另一个实体也应该具有相似性。因此,在谓词对齐(通过谓词嵌入模块)和属性对齐(通过 Attribute Character Embeding 方法)的情况下,我们可以通过TransE使相似的实体学习到相似的嵌入。具体来说:
实验结果
研究团队在最新的基准数据集DWY-NB (Rui Zhang, 2022) 上进行了实验,主要结果如下表所示。
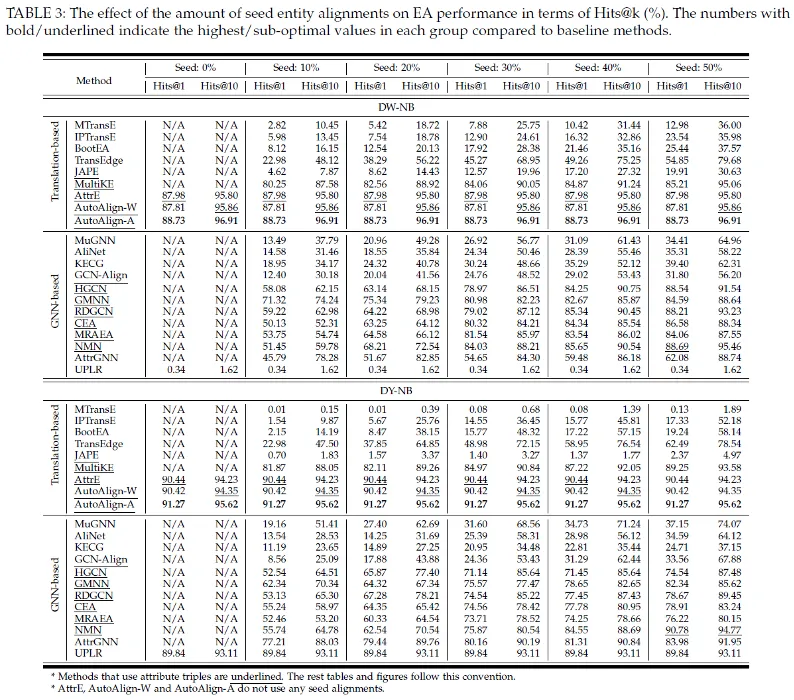
AutoAlign在知识图谱对齐性能方面有显著提升,特别是在缺少人工标注种子的情况下,表现尤为出色。在没有人工标注的情况下,现有的模型几乎无法进行有效对齐。然而,AutoAlign在这种条件下依然能够取得优异的表现。在两个数据集上,AutoAlign在没有人工标注种子的情况下,相比于现有最佳基准模型(即使有人工标注)有显著的提升。这些结果表明,AutoAlign不仅在对齐准确性上优于现有方法,而且在完全自动化的对齐任务中展现了强大的优势。
参考文献:
Rui Zhang, Bayu D. Trisedya, Miao Li, Yong Jiang, and Jianzhong Qi (2022). A Benchmark and Comprehensive Survey on Knowledge Graph Entity Alignment via Representation Learning. VLDB Journal, 31 (5), 1143–1168, 2022.
文章来自于微信公众号“机器之心”,作者 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
