# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,大模型再次攻下一城!
谷歌DeepMind宣布,他们数学AI“摘得”IMO(国际数学奥林匹克竞赛)银牌,并且距离金牌仅一分之差!
是的,没有听错!就是难到绝大多数人类的奥数题。要知道今年IMO全部609名参赛者,也仅有58位达到了金牌水平。
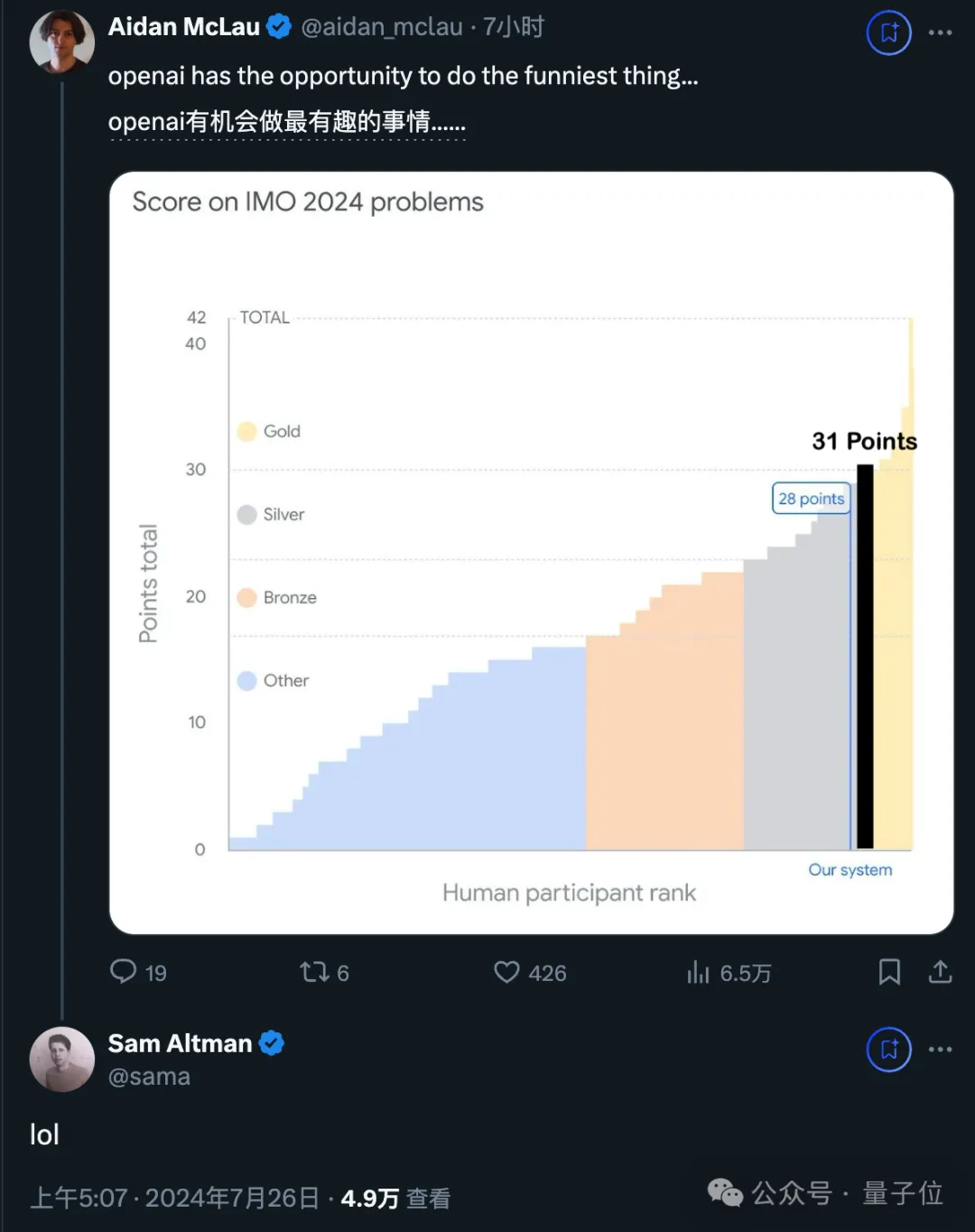
此次,谷歌AI解决了2024 IMO竞赛6道题目中的4道,而且一做一个满分,总共获得28分。(满分42分,金牌分数线29分)
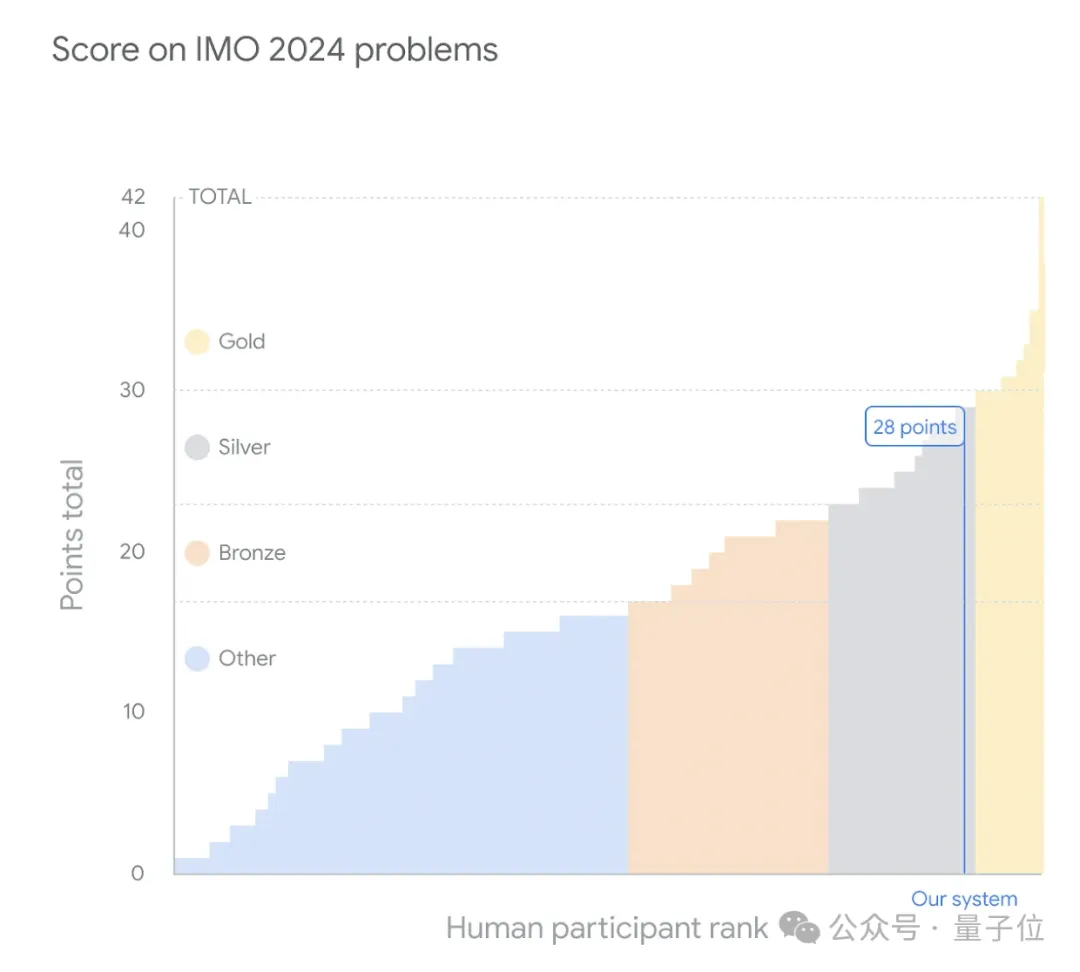
其中第四题几何题,AI仅仅用时19秒?!
而号称本届最难的第六题,今年仅有五名参赛者拿下,它也完全答对。
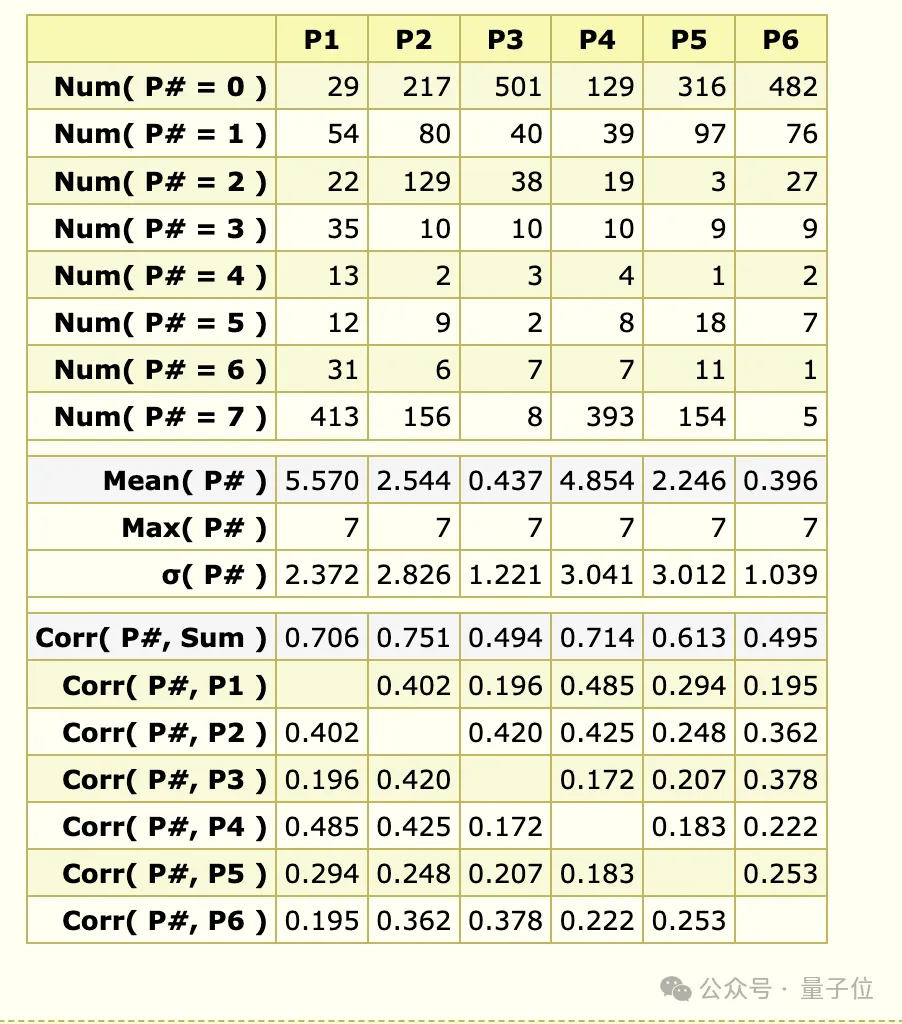
此次的成绩还得到了IMO组委的专业认证——由IMO金牌得主、菲尔兹奖获得者Timothy Gowers教授和两届IMO金牌得主、2024 IMO问题选择委员会主席Joseph Myers博士进行评分。
Timothy Gowers教授直接惊叹:远远超过我认知的最先进水平。
来康康是如何做到的?
此次拿下IMO银牌的是谷歌两位Alpha家族成员,他们各自数业有专攻。
先来认识一下新成员——AlphaProof。
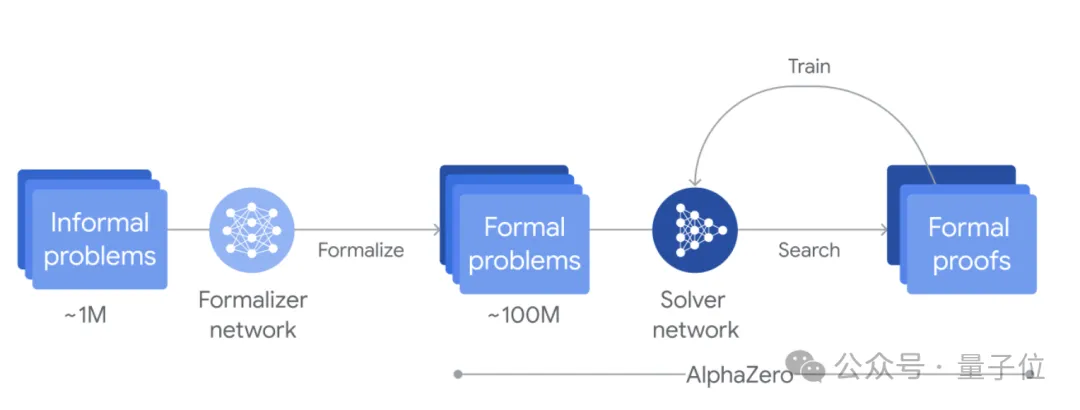
它是一个自训练系统,能用形式语言Lean来证明数学陈述。它能将预先训练好的语言模型与AlphaZero强化学习算法结合在一起。
团队通过微调Gemini,能自动将自然语言陈述转换为形式语言Lean陈述,由此创建了一个大型数学题库。
当遇到问题时,AlphaProof会生成解决方案候选,然后通过搜索Lean中可能的证明步骤来证明或反驳这些候选。
每个找到并验证的证明都会用于强化AlphaProof的语言模型,从而提高其解决后续更具挑战性的问题的能力。
在比赛的前几周内,它就这么循环往复地用数百万个IMO级别题目进行了训练。
比赛期间也应用了训练循环,不断强化自身证明,直到找到完整的解决方案。
再来了解一下进化之后的AlphaGeometry 2。它是一个神经-符号混合系统,其中语言模型基于Gemini。
它的前身1.0今年还登上了Nature:无需人类演示达到IMO金牌选手的几何水平。

跟上一个版本比,它使用了更大一数量级的合成数据进行从头训练。而它采用的符号引擎比其前代快两个数量级。当遇到新问题时,会使用一种新的知识共享机制来实现不同搜索树的高级组合,以解决更复杂的问题。
在正式比赛之前,它就已经可以解决过去25年所有IMO几何问题中的83%,而其前身的解决率仅为53%。
今年IMO赛事中,它仅用了19秒就完成了第四个问题。
接着就来看看,此次IMO这两位是如何配合发挥的。
首先,问题被手动翻译成正式的数学语言,以便系统理解。
我们知道人类比赛时,分两次提交答案,每次有4.5个小时。
而谷歌这两个系统先是在几分钟内解决了一个问题,其他问题则是花了三天时间。
最终,AlphaProof通过确定答案并证明其正确性,解决了两道代数题和一道数论题。
其中包括比赛中最难的一道题,也就是,今年的IMO比赛中仅有五名选手解出的第六题。

AlphaGeometry 2解决了几何问题,而两道组合问题仍未解决。
除此之外,谷歌团队还试验了一种基于Gemini的自然语言推理系统。换言之,无需将问题翻译成形式语言,并且可以跟其他AI系统结合使用。
团队表示,他们接下来还会探索更多用于推进数学推理的AI方法。
而关于AlphaProof的更多技术细节,也计划很快发布。
看到这两个系统的表现,网友们纷纷表示“不懂数学但大受震撼”。
AI程序员Devin团队Cognition AI联合创始人Scott Wu表示:
这样的结果真是令人惊叹。小时候,奥林匹克竞赛就是我的全部。从未想过它们会在10年后被人工智能解决。

OpenAI科学家Noam Brown也开麦祝贺:

不过,也有网友表示,如果按照标准比赛时间(竞赛分两天进行,每天四个半小时,每天解决三个题),这两个AI系统实际上只能解决6个问题中的一个。
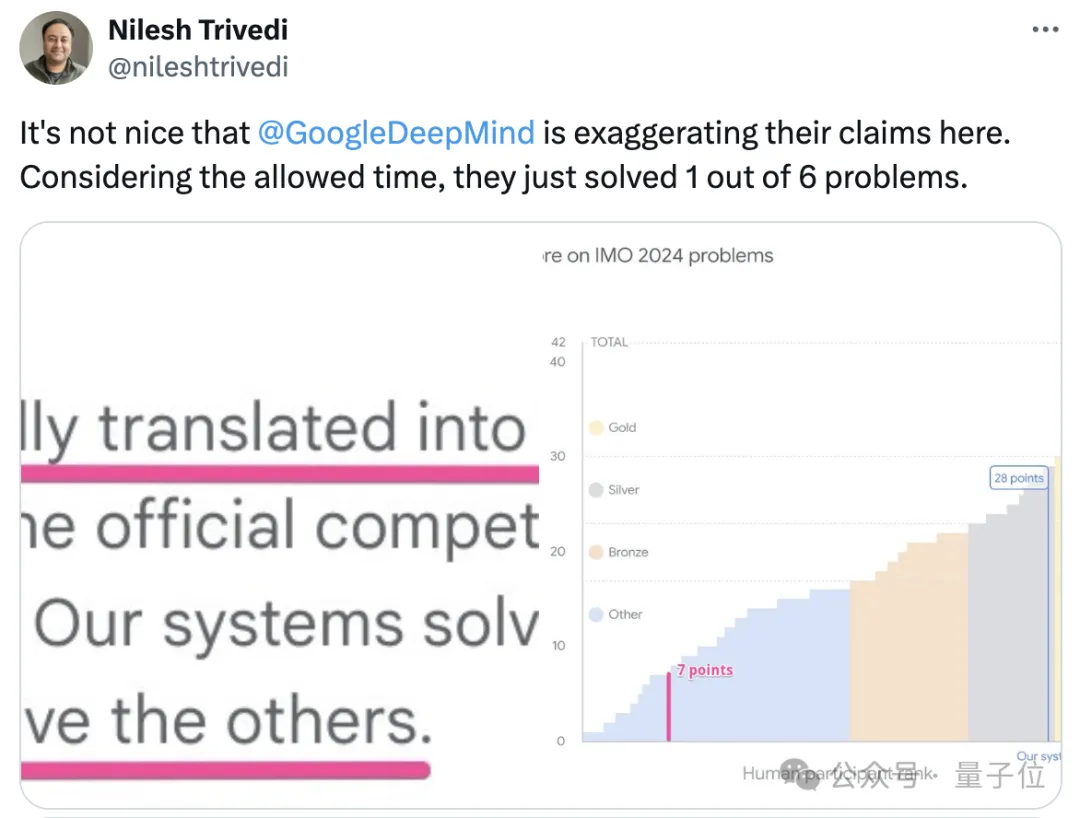
这一说法立刻得到了部分网友反驳:
在此情境中,速度不是主要关注点。如果浮点操作次数(flops)保持不变,增加计算资源会缩短解决问题所需的时间。
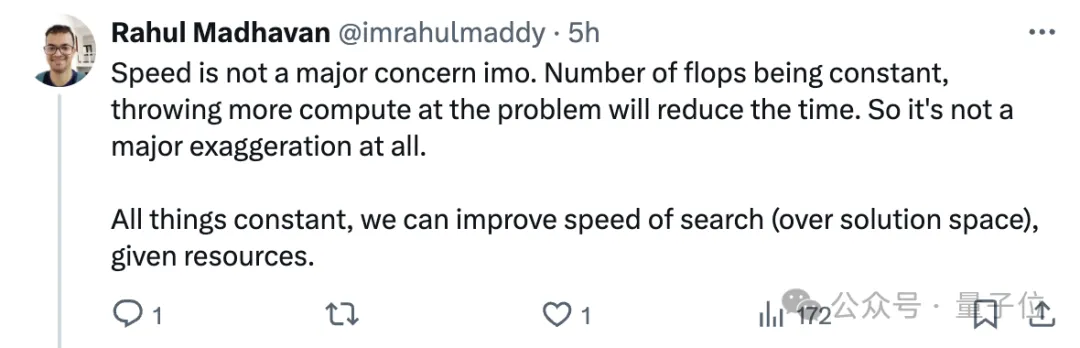
针对这一点,也有网友疑问道:
两个AI系统没能解答出组合题,是训练的问题还是计算资源不够,时间上不行?或者还存在其他限制吗?

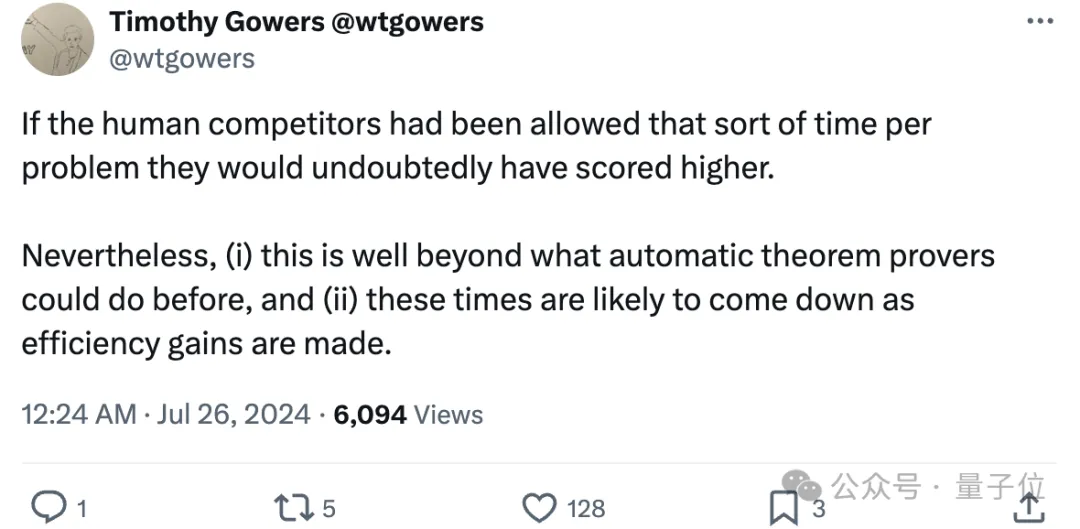
Timothy Gowers教授发推文给出了他的看法:
如果允许人类参赛者在每个问题上花费更多时间,他们的得分无疑会更高。然而,对于AI系统来说,这已经远超以往自动定理证明器的能力;其次,随着效率的提高,所需时间有望进一步缩短。
不过前两天大模型还困于“9.11和9.9哪个数字更大?”这么一个小学题,怎么这一边大模型又能解决奥数级别的难题了?!
失了智,然后现在怎么又灵光乍现,恢复了智?

英伟达科学家Jim Fan给出解释:是训练数据分布的问题。
谷歌的这个系统是在形式证明和领域特定符号引擎上进行训练的。某种程度上说,它们在解决奥林匹克竞赛方面高度专业化,即使它们建立在通用大模型基础上。
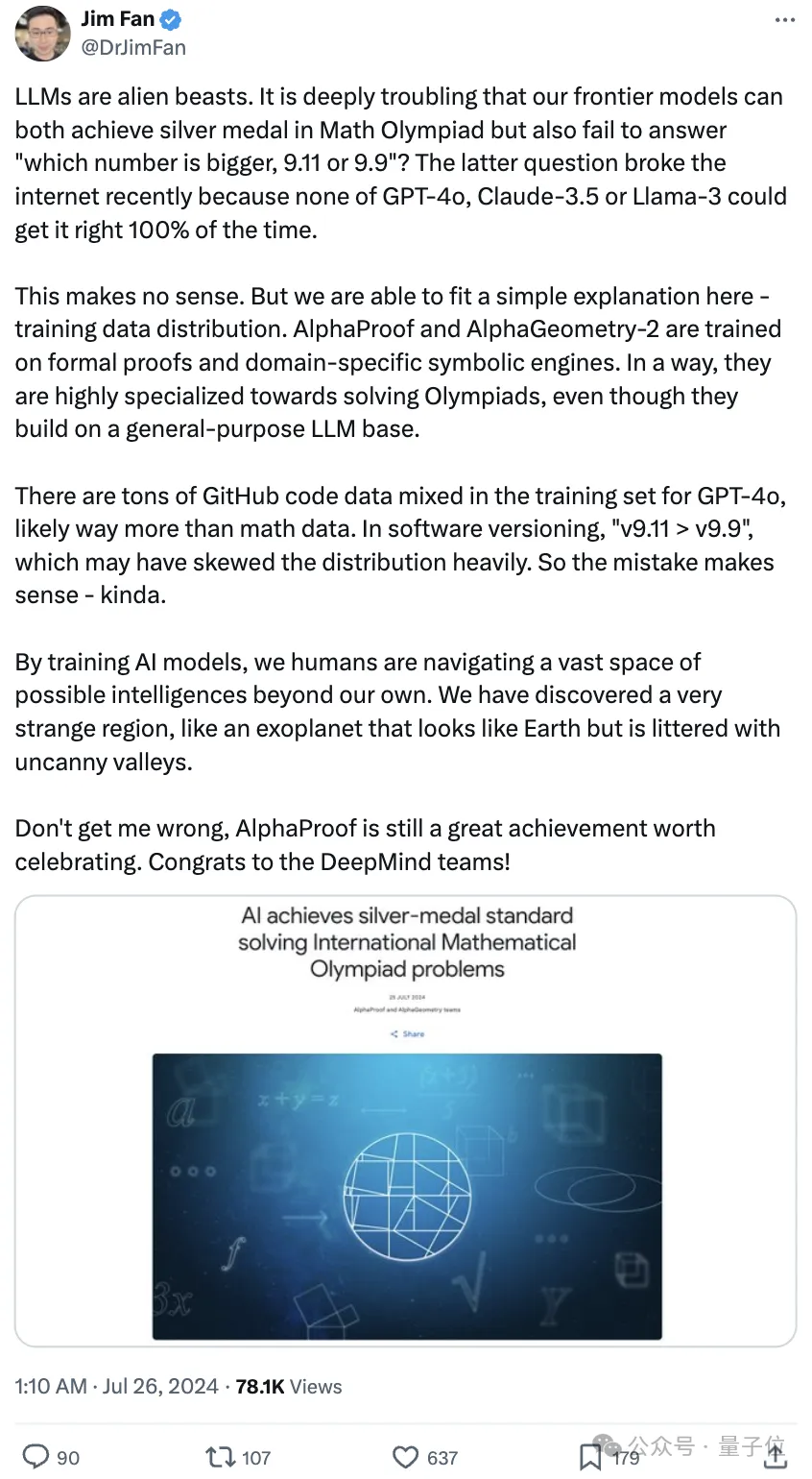
而像GPT-4o的训练集中混有大量GitHub代码数据,可能远远超过数学数据。在软件版本中,“v9.11>v9.9”,这可能会严重扭曲分布。所以说,这个错误还算说得过去。
对于这一奇怪现象,他将其形容为
我们发现了一个非常奇特的区域,就像一颗看起来像地球却遍布奇异山谷的系外行星。
还有热心的网友cue了下OpenAI,也许你们也可以尝试……
对此,奥特曼的回复是:
参考链接:
[1]https://x.com/googledeepmind/status/1816498082860667086?s=46
[2]https://x.com/jeffdean/status/1816498336171753948?s=46
[3]https://x.com/quocleix/status/1816501362328494500?s=46
[4]https://x.com/drjimfan/status/1816521330298356181?s=46
[5]https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
文章来自于微信公众号“量子位”,作者 “白交 西风”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
