# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
寻隐(英文名 Queryable)是一款 iOS 上的 AI 照片搜索软件,支持用户使用自然语言搜索本地照片。软件诞生的契机是 OpenAI 发布的 CLIP 模型。
花费两周时间开发的这款产品,冲到过 Hacker News 首页第二名,登上过少数派首页头条。两天时间内,英文版本 Queryable 几乎横扫了欧洲所有国家的工具榜第一,美国榜第二。可谓是爆火了一把。
从一开始的开源+免费,又转为后来的付费。然后是苹果官方发布了类似产品——iOS 18 支持相册语义搜索。
诞生、爆火、开源、沉寂,今天这篇文章,独立开发者「碎瓜」分享了他开发一款 AI 相册搜索应用的两年。
故事起源于 2022 年 5 月的一个周末,我坐在北京昌平区的书店里,正在调试 Disco Diffusion 模型。此时 AI 绘画时代初露端倪、SD 尚未发布。画一张图,在一张性能良好的 V100 显卡上要 5 分钟。
我将开源代码封装成可以只加载一遍模型、暴露少数参数的接口,花 2000/月租了张显卡,并在朋友圈和社交媒体上发帖,想玩 AI 绘画的人可以给我句子描述,我在机器上跑完并把图发给他们。
网友们玩得很开心!朋友说,要不搭建一个网站让大家自己玩?于是就有了 6pen.art。我们在很短时间内有了 100 万用户,然后逐渐销声匿迹。这次「创业」不太成功,我自觉是我没有训练出差异化的模型占很大因素,但这里不展开了。如上所说,SD 发布之前的 AI 绘画速度极慢,我的大部分时间是在做模型加速,其中一个优化项就是 关于 CLIP 模型。
CLIP 是 OpenAI 2021 年发布的模型,它能比较任意一张图片和一句文本之间的相似度。在 Disco Diffusion 中,模型用 CLIP 来计算生成图像与用户 prompt 之间的损失,不断优化损失从而实现绘画。使用越小的 CLIP 模型,绘图速度越快,但画面细节也会越差,我当时正在调试以平衡绘图速度和画面细节。
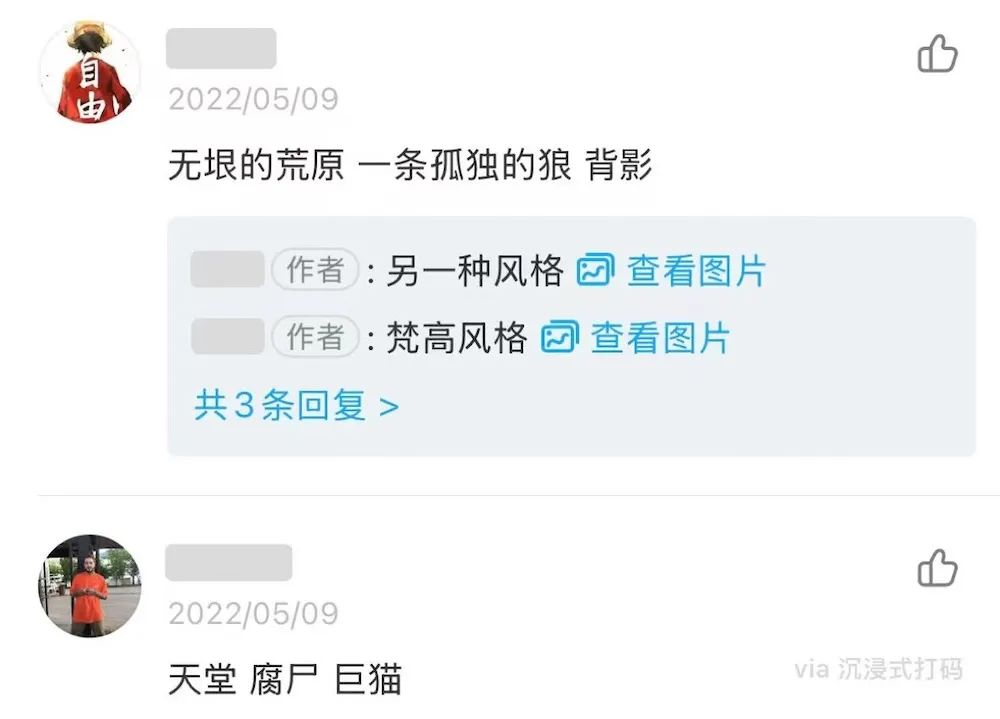
坐在书店里,突然一个想法闯进了脑子:既然可以比较图文相似度,那么可以用它来搜照片吗?搜索后发现已经有人 (https://github.com/kingyiusuen/clip-image-search) 这么干了,原理是将照片上传到服务器,统一提取特征,输入英文并计算文本与每一张图的相似度,排序就能实现搜图。
我开始尝试将我的 iPhone 相册上传到服务器,试了一番下来,我发现效果好得惊人!特别是搜一些虚无缥缈的东西,比如我输入"lonely"(孤独),它返回到前三张照片如下:

把照片放在服务器,这不是个好想法。我照片最多的地方就是 iPhone 本地相册。能否做一个完全运行在本地的 CLIP 搜图 App 呢?我非常喜欢这个 idea,几次和朋友讨论起,但每次都无疾而终。
我心里太没底了:
- 我完全不懂 iOS 开发。
- Apple 底层可能不支持 CLIP 模型算子。
- 即使能跑起来,如果索引速度慢到 1 秒/张,或者搜一次 10 分钟,这个产品也没有意义。
直到 2024 年,端侧语言模型才逐渐被大家所关注,但在 2022 年,我在 App 市场上没找到一个运行在端侧的语言模型,应该.. 不太可行吧?我终于忘了这件事,继续投入到 6pen 的研发中。
转折点是 2022 年 12 月初,因为一些变故,我突然到了一个语言完全不通的陌生国家,与 6pen 的缘分也走到尽头。于是,在空旷的咖啡店,一台笔记本、一杯冰拿铁坐一整天。背景音乐放着 Kpop,窗外是厚厚的积雪,中午饿了吃店里的三明治,我每天就这样度过。
这里网速飞快、没有核酸、周围人的谈话因语言不通自动变成了白噪音,我好像突然活在真空之中。这种陌生的真空感让我兴奋:像流放的逃犯一样,我是谁、我的过去不再重要,在这里我好像从头学习并完成任何事。是时候开始做点真正让我兴奋的产品了——这个 idea 再次抓住了我。
但这次,我不再恐惧验证可行性,我学习用 Swift 编写 tokenizer,研究应该如何计算并将特征保存,学习用多核加速索引。期间在 StackOverflow 提了许多愚蠢的问题,有很多次挫败时刻。但我脑海里一直浮现这个画面:在手机输入"coffee and laptop"(咖啡和笔记本电脑),点击搜索,旋转动画后,下面这张照片从 3 万张相册中跳出来,出现在我眼前。

这个幻想支撑我废寝忘食地干了 2 个星期——字面意思,好几次忘记吃午饭,一杯拿铁喝到傍晚饿到胃疼、全身乏力。有个重要的时间节点,就是 ChatGPT 在那时刚刚发布。但我在开发中陷入太深,根本忽视了它的存在,那可能是我这辈子最后几次在 StackOverflow 提问。
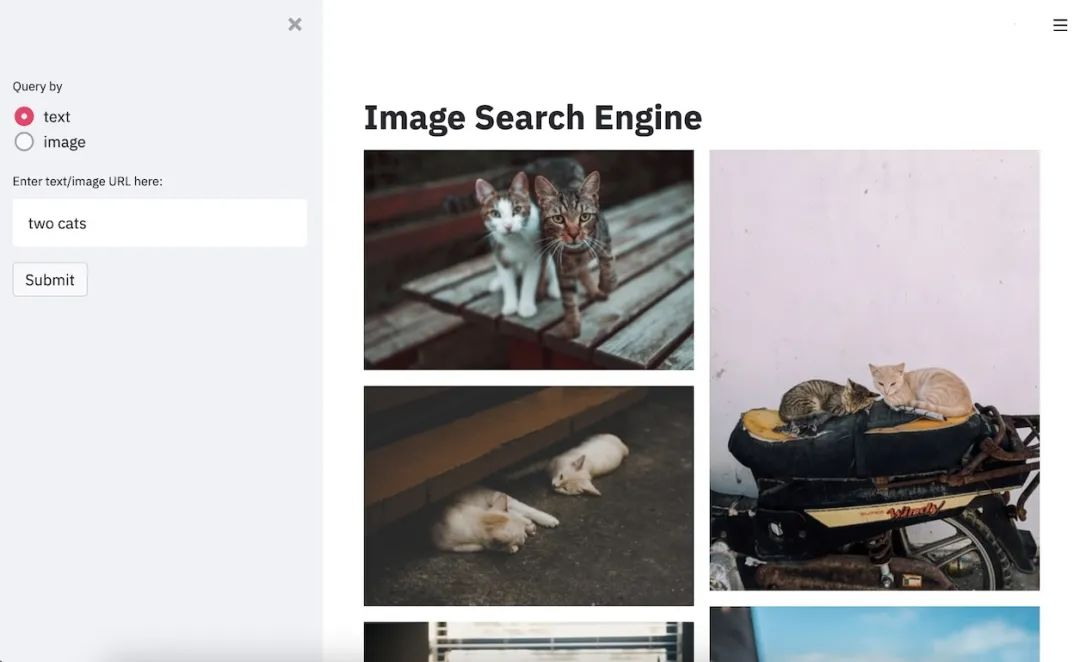
总之,在 12 月 27 日,我终于完整做出了产品。我把模型中的文本模型和图像模型分拆成两个独立模型,分开加载:
为相册构建索引时只加载图像模型,计算索引并保存,搜索时只加载文本编码器,并逐一计算与保存的索引之间的余弦距离,然后返回相似度最高的 topK 照片。
错开加载模型可以有效降低软件的内存占用,并且能加速构建索引。同时,使用多核并行的方式计算索引,可以做到在我的 iPhone 12 mini 上 以 2000 张/分钟速度为照片构建索引,而 10,000 张照片搜一次只要不到 1s。
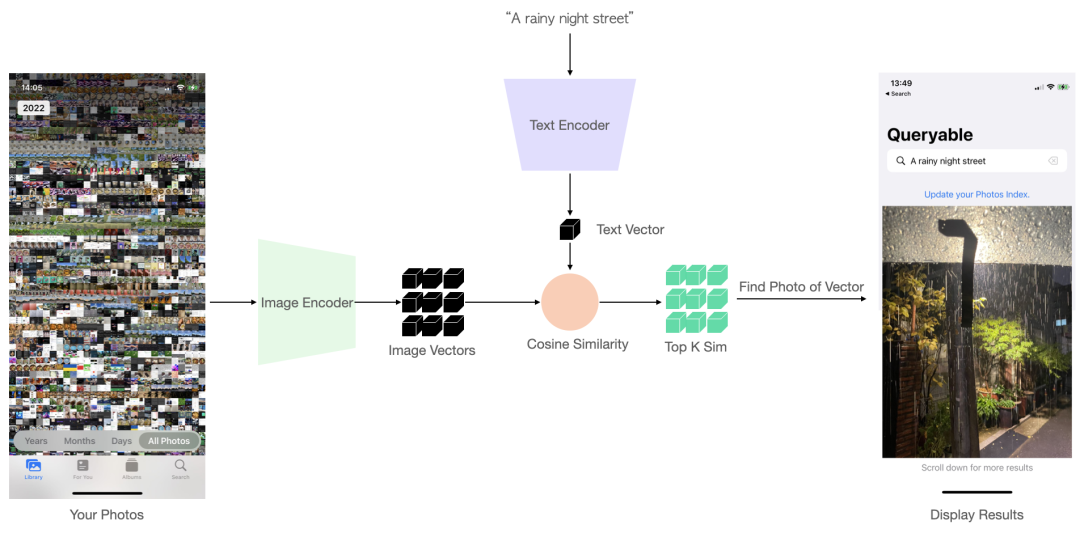
这表明:算子是支持的、速度是可用的,我悬着的心终于落下了。
作为一个定价小天才,我的设想是:
用户可以免费下载,并构建索引、任意搜索。当他未来有新照片、想更新索引,就要付费。
这个策略妙处在于:只有真正用上了、喜欢这个产品的人,才需要付费。那些来尝鲜的、或者试了下发现和预期不一样的人,不需要也不会掏钱,因而避免了用户花冤枉钱怒打差评。
但很快,在调试代码时我发现一个合理但又搞笑的事实:App 内购买需要联网。这简直是晴天霹雳,因为我从一开始就下决心:决不允许 App 在任何情形下弹出联网请求。为什么?因为这是一个相册搜索应用,它会扫描你的整个相册,没有人知道联网后你会不会将用户的照片上传到地球某处的服务器。我知道可以在产品里解释为什么会弹窗请求联网权限,但我不想陷入尴尬的自证境地。
于是我只好将它变成付费产品:用户必须购买,之后从打开 App、构建索引到完成搜索的过程中,只弹出一次相册权限请求。我知道这么做很蠢——后续的教训也验证了,付费下载会带来大量差评:因为模型太吃算力,许多内存小的机型上构建索会崩溃、卡顿,在 iPhone X 系列算子支持异常导致搜索结果全黑,这些都会被骂 Ripoff(诈骗);并且,用户根本不会在意不弹出联网请求这件事,一旦出现以上异常,他们就会删 App、打差评,质问我把他的相册偷偷上传到哪去了。
总之,最终我将其定价为 3.99 美元,一次购买、终身使用。
我给产品取了名字:Queryable,意为可查询的,并发了条很中二的动态:我觉得这个 app 可能会改变世界,我对此信心满满,甚至给 Tim Cook 写了一封邮件,希望苹果能收购这个产品 (笑)。那时候我已经开始用 ChatGPT 了,可能因为太激动,我忘了替换掉自己的名字,点击发送之后,才看到邮件开头是:"Dear Mr. Cook, My name is [Your Name]"。
当然最终也没有收到回信。
我又开始雄心勃勃地准备写篇产品介绍文章,反复斟词酌句、试图将它变成我心中 Hacker News 好文章的风格。在 12 月 29 日,App Store 审核通过的当天,我立刻在 Hacker News 提交了我的文章链接,但系统提示账号太新无法提交,我给他们发邮件反馈了这个问题,并让朋友用他的账号帮我发帖。
帖子很快沉了,邮件也没收到回信。
我很难过,但由于收到许多用户请求支持中文输入,我来不及悲伤,便立即投入中文模型训练中。得益于分离了 CLIP 中文本模型和图像模型,我只需要找到中英文双语平行语料,训练一个中文文本模型,将其输出结果与英文模型对齐即可,这个过程本质上是蒸馏。
很快,2023 年 1 月 18 日,我做好了中文版,取名寻隐,来源就是贾岛古诗《寻隐者不遇》,也暗含从相册中发现隐藏含义的意思。毕竟,我的初次震撼就是搜`lonely`时意识到那几张照片原来代表孤独
上线后,我用中文在少数派写了一篇文章介绍此产品,和英文版不同,除了讲述技术方案外,我还完整记录了心路历程,竟然进了当天的首页,这带来了大量下载,以及 1500 美元的收入。
2 月初,我收到了 Hacker News 编辑的回信,他说我的账户被系统误判为 SPAM,鼓励我重新发帖,说我的文章很符合社区精神 ("the article is definitely fine HN material"),他会将我新帖子的链接放在候选池 (pool):池里的文章会随机进入首页底部,如果用户点赞,排名就会上升,否则再次沉下去。
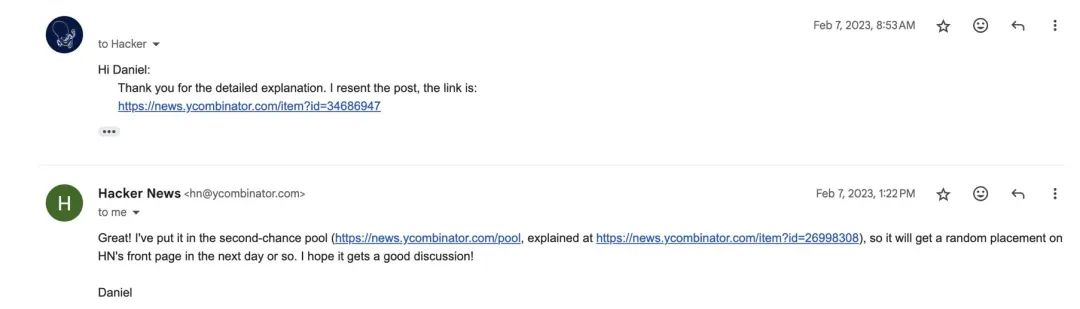
我发现 pool 机制很有意思,社区似乎希望在去中心化的机制下,仍然维持黑客精神的调性:
这是我们长期进行的故事重演实验。版主和少数审阅者用户会深入寻找被忽视、但社区用户可能会感兴趣的故事。这些故事会进入第二次机会池,该池中的故事会被随机选择并放置到首页的底部。这保证了它们获得了几分钟的注意力。如果社区用户不感兴趣,它们很快就会下沉消失,但如果社区感兴趣,它们就会得到支持 (upvote) 并留在首页。
https://news.ycombinator.com/item?id=11662380
当晚 7 点,我的帖子冲到了 Hacker News 首页第二名。
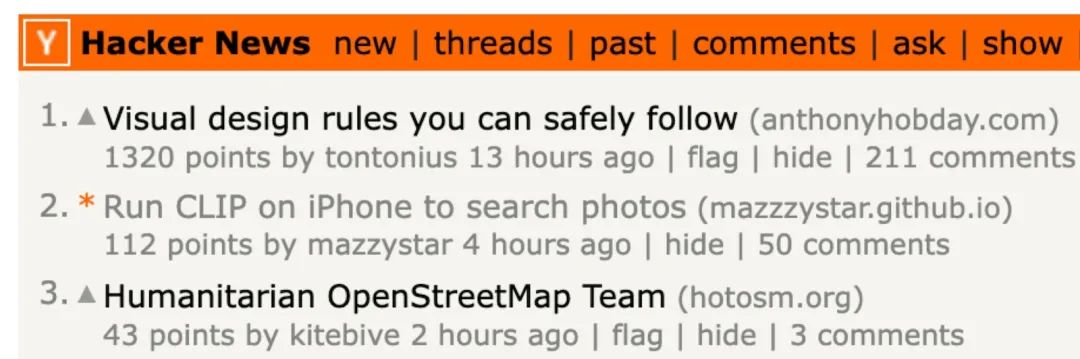
那晚,我抱着手机每 10 秒刷新一次,兴奋感从十二点躺下持续到凌晨三点,我一直在回复帖子下的讨论、反馈 bug 的邮件。有人教我用 LSH 来提高搜索速度,有人给出如何在不联网的前提下,将照片经纬度映射到城市,有人讨论 iPhone X 上运行失败的原因。
这种感觉好像和产品有多少下载、赚多少钱无关:你创造了一个东西,得到了一大群同行的赞美、兴奋地讨论、给它出主意,这是人生少有的经历,一次就很知足了。
其中有一条评论引起了我的注意:

我阅读了作者的开发日志,发现地球上还有一个人、正在和我做一模一样的事。我们像地球上随机的两个脑子产生相同想法的人,我甚至在 Testflight 试用了他还未上线的产品,有种莫名的惺惺相惜感。
当晚,我很兴奋地睡着了,为自己产品被同行喜欢而激动,事实证明我远远低估了 Hacker News 的影响力:两天时间,Queryable 几乎横扫了欧洲所有国家的工具榜 #1,美国 #2,总收入是 2800 美元。之后的几天,我醒来第一件事就是看邮件,德国、法国、西班牙、美国,各个国家都有:有反馈 bug 的,有德国杂志社想报道的,有法国 iOS 社区的,有油管博主测评的。我的推特也会因为有人转发 Hacker News 热榜而不断收到通知。
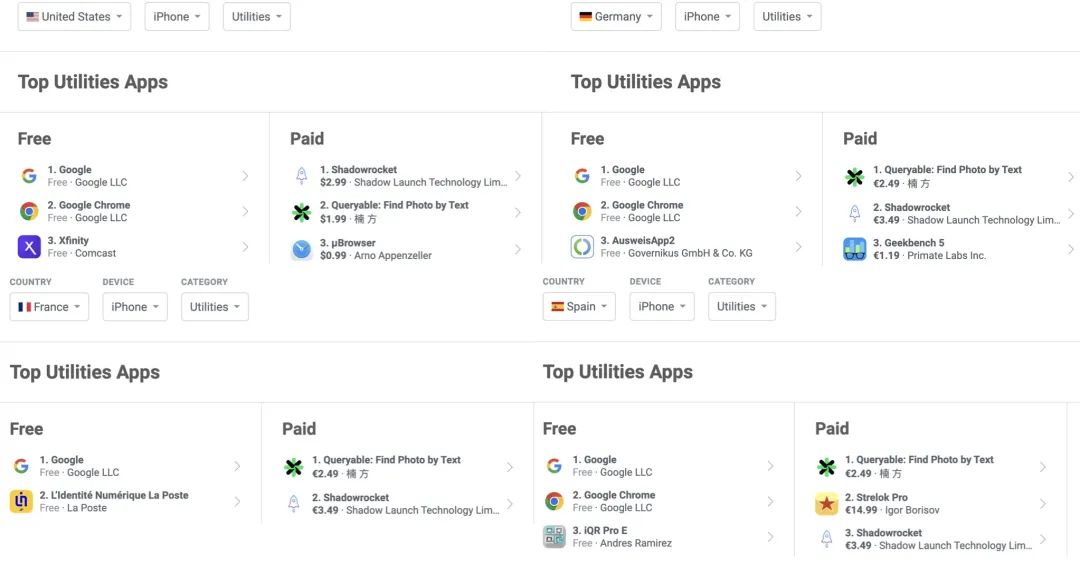
甚至一位在 Apple Photos 组工作的朋友告诉我,他们组里也知道 Queryable。
以上这些都迫使我意识到某种世界性:Hacker News 并非只属于美国,它像世界中心区域一块虚拟的公告牌,每个作品在上面短暂停留,但总有来自各个国家、无数双眼睛盯着。这个产品只支持英语,但不妨碍它在欧洲几乎所有国家付费工具榜 #1。他们好像会天然接受一个只能用英语的产品,在美国行得通的产品往往欧洲人也能接受,反之,我没有看到明显的案例。
热度很快降了下来,随即而来的是很多恶评。
简单来说,Hacker News 的用户质量极高,我没看到任何令我感到不适的评论。但经过各种网站、YouTube 和社区的二次传播后,不那么友好的用户就浮出水面了。主要攻击的有两点:
1. 害怕我会窃取他的相册隐私。
2. 我是中国开发者。
在他们看来,第 2 点让第 1 点的情况变得更糟了。在 Hacker News 接二连三的余热结束以后,这个产品在欧美销量迅速变得惨淡,每天个位数的下载,几十块的收入。
在我的想象中,改变世界的东西是一骑绝尘的,怎么会突然停下了呢?我陷入了巨大的怀疑和悲观。
所幸国内的差评公众号、果壳等媒体对寻隐的自来水曝光,让我从 1 月份开始,每个月可以获得 1 万元左右的收入,并且因为模型运行在手机端,也就没有服务器成本。从 4 月份起,没有任何流量曝光、不做任何更新的情形下,平均每月大概可以获得 3000 元的收入。
但是!我仍然觉得这是一个很有用的产品,只是我没办法让更多人知道。我做过一次限时免费,当天下载量超过过往日均的 100 倍,我想,与其维持这样每月 3000 块的收入,可能阻止了 99% 的人发现这个产品,不如让所有人都可以使用它,于是我决定让它一直免费。
既然免费了,源代码好像就并不是什么机密了,我在思考要不要把源代码放出来。最终,在 2023 年 7 月 10 日,我在 V2EX 发布的一条帖子决定免费&开源。很多人一听到开源就觉得莫名高大上,但对我而言,开源动机很简单:
开源后,这个项目上了 Github Trending,我也因此白嫖了一年 Github Copilot,开心。
谈抄袭之前,我想定义一下什么叫抄袭:
抄袭是指未经授权或未给予适当信用的情况下,直接或间接地使用他人的作品、创意、或内容,将其作为自己的作品或创意发表。
其实在开源前,抄袭就出现了。有人做了 Android 版,发布在 Google Play,名字和产品介绍完全照搬 Queryable,我感到很生气,但这其实挺难的,需要同时掌握机器学习和 iOS 开发,开源前这样的人我只遇到一个。
但开源之后,抄袭、套壳的人就多了。因为项目是 MIT 开源,所以即使套壳换图标,然后重新上架 App Store,我虽然有点无语,但也不会说什么,这是我见过最多的形式,开发者全是中文名。
印象比较深刻的一次,是根据某个套壳者的邮箱,找到了他的 V2EX 账号,发现对方 27 天前发帖说自己 35 岁被裁,该怎么办,我沉默良久,关掉了网页。
有些是在原项目的基础上,加上了用户希望的删除照片、按日期/地点筛选照片的需求,并且 UI 比我做得好看——我其实甚至蛮支持的,这也是我开源的初衷。但也有让我感觉不爽的套壳产品,不仅没有 Acknowledgement,被用户提问与寻隐有什么不同时,还要踩一脚:我比寻隐多了 xx 功能。
比较恶劣的是,用 Queryable 名字套壳上架,比如下面这个,收费模式是免费+广告。我很担心用户误以为这是 Queryable 的 Android 版,后续出事了找我麻烦。
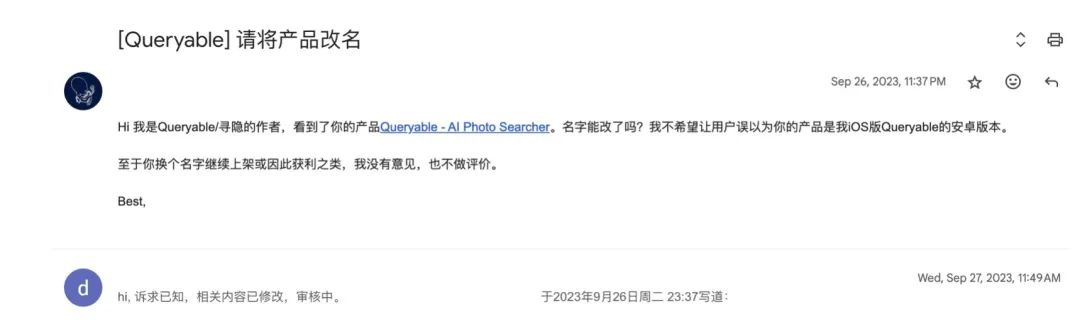
我最开始会伤心,正如一位 v2er 在评论区预言得那样:开源是好事情,但是我不希望看到你看到李鬼后伤心。但虱子多了不痒,后来也就慢慢看淡了。
重新变成付费是在 2023 年 11 月份,除了生存压力增加之外,我发现:
开源并不能帮助我的产品变得更好。我原先希望借助开源+免费,让专业的移动开发者贡献代码,帮助寻隐/Queryable 打磨得更好,但事实就是,大多数人会下载源码去开发自己的套壳版本,而不会提交 PR 给你。所以我的产品原地踏步,甚至因为免费的缘故,用户抱怨的邮件比过去更多。
每当用户发邮件向我提反馈/bug/建议时,我的第一反应是不耐烦 (_内心:免费给你用就不错了,还挑三拣四_),我发现这种想法导致产品越来越落后,直到有天被淘汰。
可一旦收费,我就会很心平气和地应对用户的意见、改进产品,收到反馈第一反应是感激而不是厌烦。这会倒逼我不得不花费心血优化产品,最终让所有曾经付费的用户用上打磨更好的产品,而不是疏于维护过几年死掉。
转为付费后,我开始隔 1-2 个月提交一次版本更新。
Apple 在今年的 WWDC 终于宣布:iOS 18 即将支持相册语义搜索了,这比国内的厂商慢许多。不过,虽然我在 beta 版本还无法体验,但有理由相信苹果会做得比寻隐/Queryable 好,毕竟,谁让它禁了第三方 App 跳转到系统相册呢?在 Hacker News 当天一则关于 WWDC 的讨论中,有人再次提到了 Queryable。
从想法诞生、产品上线到现在快两年,它陪伴我经历了人生的跌宕起伏、见证了好几家咖啡店倒闭。我也陪它经历了诞生、高峰和低潮,并没有像最早幻想的那样赚到钱 (100 万人下载每人给我 10 块钱我就...)。
生活依旧继续,故事也还没有结束:上周,调研最新 paper 并重新设计、训练了中文文本模型,App 体积从原来的 232M 降低到 159M,索引速度翻倍,准确率更高,训练过程花了 3 天,70 美元。

并且,最近订阅的 Claude 3.5 Sonnet 写代码能力过于逆天,之前靠 GPT-4 搞不定的多选删除,拖了一年半后,终于在上周开发完成并上线,我还是挺喜欢这个平淡的结尾。
俱往矣,迫不及待开始下一个让我废寝忘食的 idea、下一次流放到真空中。
文章来源于“Founder Park”,作者“Founder Park”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
