# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
芯片巨头英伟达,在AI时代一直被类比为在淘金热中“卖铲子”的背后赢家。

现在他不装了,也要亲自下场“挖金矿”:
配合最强开源大模型Llama3.1,推出NVIDIA AI Foundry和NVIDIA NIM推理微服务两大新业务。
Foundry在芯片行业指“铸造厂”,比如台积电制造其他公司设计的芯片。
NVIDIA AI Foundry,代表英伟达可以定制化制造大模型了:
NVIDIA AI Foundry 提供从数据策管、合成数据生成、微调、检索、防护到评估的全方位生成式AI模型服务。

NVIDIA NIM在年初的GTC大会上首次亮相,使用几行代码就可以在云、数据中心、工作站和PC上部署AI模型。
现在则又新加一个标签:将Llama 3.1模型部署到生产中的最快途径,吞吐量最多可比不使用NIM运行推理时高出2.5倍。
为什么在这个时间点出手?
黄仁勋表示:“Meta的Llama 3.1开源模型标志着全球企业采用生成式 AI 的关键时刻已经到来”。
企业可以将Llama 3.1 NIM 微服务与与全新NVIDIA NeMo Retriever NIM微服务组合使用,为AI copilot、助手和数字人虚拟形象搭建先进的检索工作流。
NVIDIA和Meta还一起为Llama 3.1提供了一种提炼方法,供开发者为生成式AI应用创建更小的自定义Llama 3.1模型。这使企业能够在更多加速基础设施(如 AI 工作站和笔记本电脑)上运行由Llama驱动的AI应用。
之前老黄与小扎见面,交换皮衣穿,原来是商量这些合作去了(手动狗头)。

Llama 3.1系列模型发布还没几天,手快的企业已经用在生产中了。
Aramco、AT&T和优步,成为首批使用面向Llama 3.1全新NVIDIA NIM微服务的公司。
咨询巨头埃森哲更进一步,借助NVIDIA AI Foundry为自己以及咨询客户创建自定义Llama 3.1 模型,
从自定义模型到加速部署,被英伟达打造进了同一套流程。
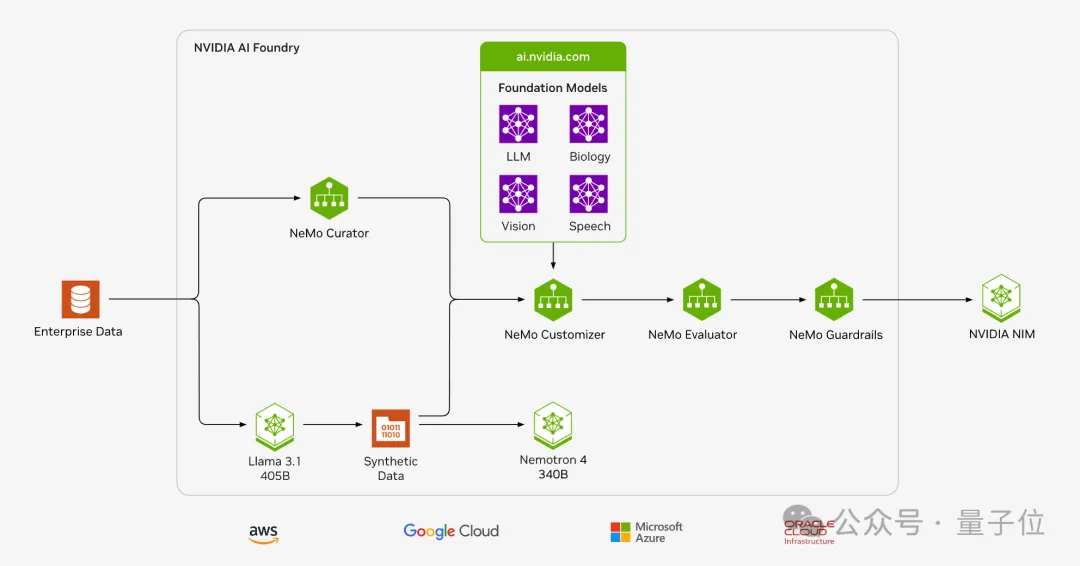
企业自有数据,可使用NeMo Curator开源Python库完成快速且可扩展的数据集准备和大模型用例的管理,包括基础模型预训练、领域自适应预训练 (DAPT)、监督微调 (SFT) 和参数高效微调 (PEFT)。
接下来使用NeMo Customizer简化大模型的微调和对齐。最初支持两种流行的参数高效微调技术:LoRA和P-Tuning。未来还将添加对完全对齐技术的支持,包括监督式微调(SFT)、从人类反馈中进行强化学习(RLHF)、直接偏好优化(DPO)以及NVIDIA SteerLM等。
Nemo Evaluator支持多种学术基准的自动评估,能够对自定义数据集进行评估,同时也支持支持使用大模型作为评委(LLM-as-a-Judge)对模型响应进行自动评估。
NeMo Guardrails使开发者能够构建三种边界:
在创建了自定义模型后,企业就可以构建NVIDIA NIM推理微服务,在其首选的云平台,使用自己选择的最佳机器学习运维(MLOps)和人工智能运维(AIOps)平台在生产中运行这些模型。
像Llama 3.1 405B和和英伟达Nemotron-4 340B这样超过千亿参数的大模型,用在绝大多数场景在成本和速度上都不会令人满意。
英伟达和Meta都意识到,用于生产合成数据,将是他们发挥作用的最大场景。
英伟达Nemotron-4 340B系列包括基础、指导和奖励模型,这些模型形成一个管道,用于生成用于训练和优化LLMs的合成数据,并且使用了独特宽松的开放模型许可证,为开发人员提供了一种免费、可扩展的方式来生成合成数据
Llama 3.1更新的开源协议这次也特别声明:允许使用Llama生产的数据去改进其他模型,只不过用了之后模型名称开头必须加上Llama字样。

参考链接:
[1]https://nvidianews.nvidia.com/news/nvidia-ai-foundry-custom-llama-generative-models
[2]https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
文章来源于:微信公众号量子位



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
