# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近两款大型 AI 模型相继发布。
在7月23日,Meta 发布了 Llama 3.1 405B 模型,该模型不仅支持8种人类语言,还精通多种计算机语言,如下图所示:
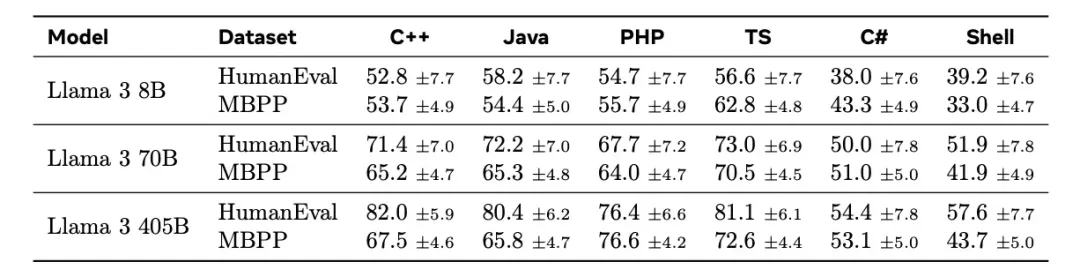
紧接着在7月24日,Mistral AI 发布了最新的 Mistral Large2 模型,这款模型支持数十种人类语言,并熟练掌握了80多种编程语言,包括 Python、Java、C、C++、JavaScript 和 Bash等。它还精通一些更具体的语言,如 Swift 和 Fortran。

Base64 编码是一种将二进制数据转换为文本格式的编码方式,常用于在文本协议中传输二进制数据。Base64 编码在数据预处理、模型输入输出、数据安全等方面有着广泛的应用。

通过 Base64 编码,我们可以评估 AI 模型的多语言处理能力,测试它们是否能准确理解和翻译编码后的信息,尤其是它们对不同语言和编码格式的理解和处理能力。进而检验它们的多语言翻译能力、回答准确度和推理能力。
解码是编码的逆过程。如果一个 AI 模型能够准确地解读和处理 Base64 编码或解码出相关信息,那么它在执行日常编程任务、解析网络数据,甚至从复杂文件中提取信息时,将会更加得心应手。
今天,我们就用这种看似晦涩的 Base64 编码和解码来测试 AI 大模型的多语言能力。
接下来,我们要带着一点“侦探”的心情,来玩一个关于 Base64 编码的解谜游戏。
虽然主要选手是 Llama 3.1 405B和Mistral Large2,但我们也加入了Qwen2-72B 和 GPT-4o,一个是国内的头部开源项目,另一个则是闭源代表,看看他们是否真的能够像处理普通语言那样,轻松应对这些“编码挑战”,我们拭目以待!
我们将使用 Base64 编码的字符串进行多语言测试,包括中文和英文。通过这次测试,我们可以了解各大模型在多语言翻译、回答准确度和推理能力方面的表现。
- 测试共 2 轮,每轮三次对话。每答对一次记 1 分。
- 为了确保测试的公平性,我们会提示模型不要使用代码工具进行解码。
- 提示词:这是一个 base64 信息【】,请你不使用代码工具告诉我这是什么信息。
首先我们大致知道下 Base64 编码解码的步骤和流程是什么。
Base64编码是将二进制数据转换成一系列特定的64个字符(A-Z, a-z, 0-9, +, /)来表示。如果解码过程中的步骤不正确或者字符串不是有效的Base64编码,那么解码结果可能会是错误的或无意义的。若要检查实际的Base64编码字符串代表的内容,可以使用在线工具或编程语言中的库来正确解码。
第一轮:英文解码
本轮采用英文单词转 Base64 编码测评,编码后的字符串分别为:
Justice:SnVzdGljZQo=
Bravery:QnJhdmVyeQo=
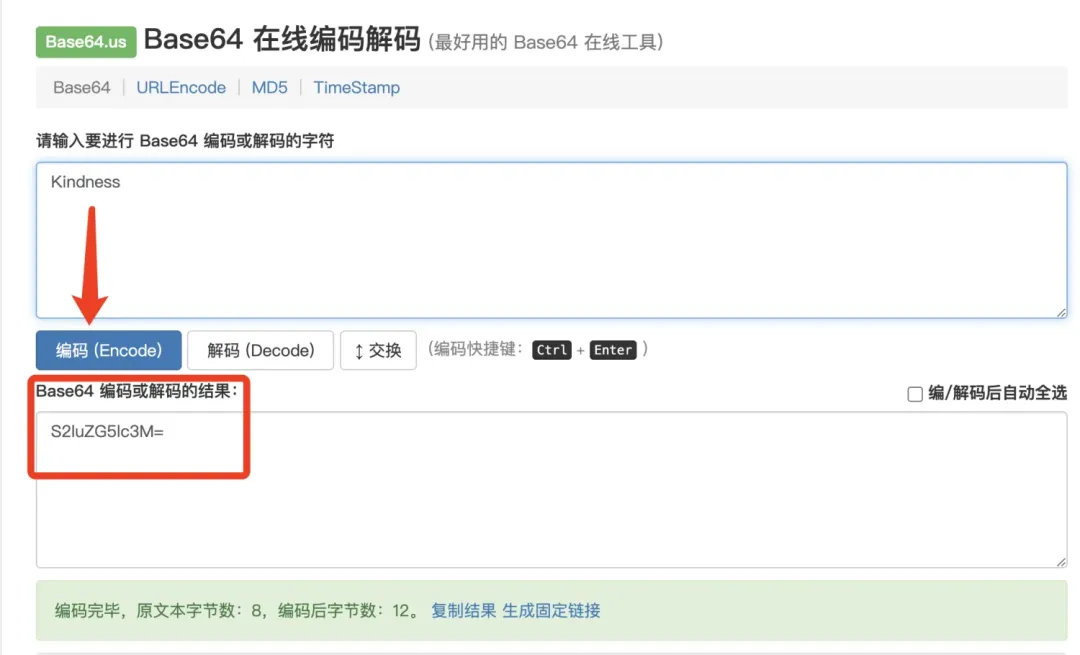
Kindness:S2luZG5lc3M=
我们先来用英文编码测试看看个大模型结果如何,Llama 3.1 405B 答的都完全正确,得 3 分。但全部都是英文回答,对于中文不太友好。
不过它还是会附上自己特色的表情包,这“人味儿”谁不喜欢,情绪价值给的非常到位。
而 Mistral Large 2 解码的英文 Base64 信息答对两题,得 2 分。在第二问中,原文是 brevery,解码的是“brave”,最有可能的错误来源是在字符到二进制索引的转换、索引到二进制的转换,或者在二进制数的重组过程中出现了错误。
不过值得表扬的是,在解码过程中它先是解释了原理,然后用 5 个步骤逐步分析推理最后解码,既详细又清晰明了,非常易懂。
图片可上下滑动

ChatGPT-4o 回答一如既往地极其简洁和快速,这次换成解码后的内容也是相当正确,记 3 分。
图片可上下滑动

最后来看下 Qwen2-72B 的英文解码回答,三个答案都是正确的,还解释了实际编码中的注意事项,易于理解,而且考虑周到,得 3 分。

第二轮:中文解码,无一生还?
本轮加大难度,采用中文词语转 Base64 编码测评,编码后的字符串分别为:
正义:5q2j5LmJ
勇敢:5YuH5pWi
善良:5ZaE6Imv
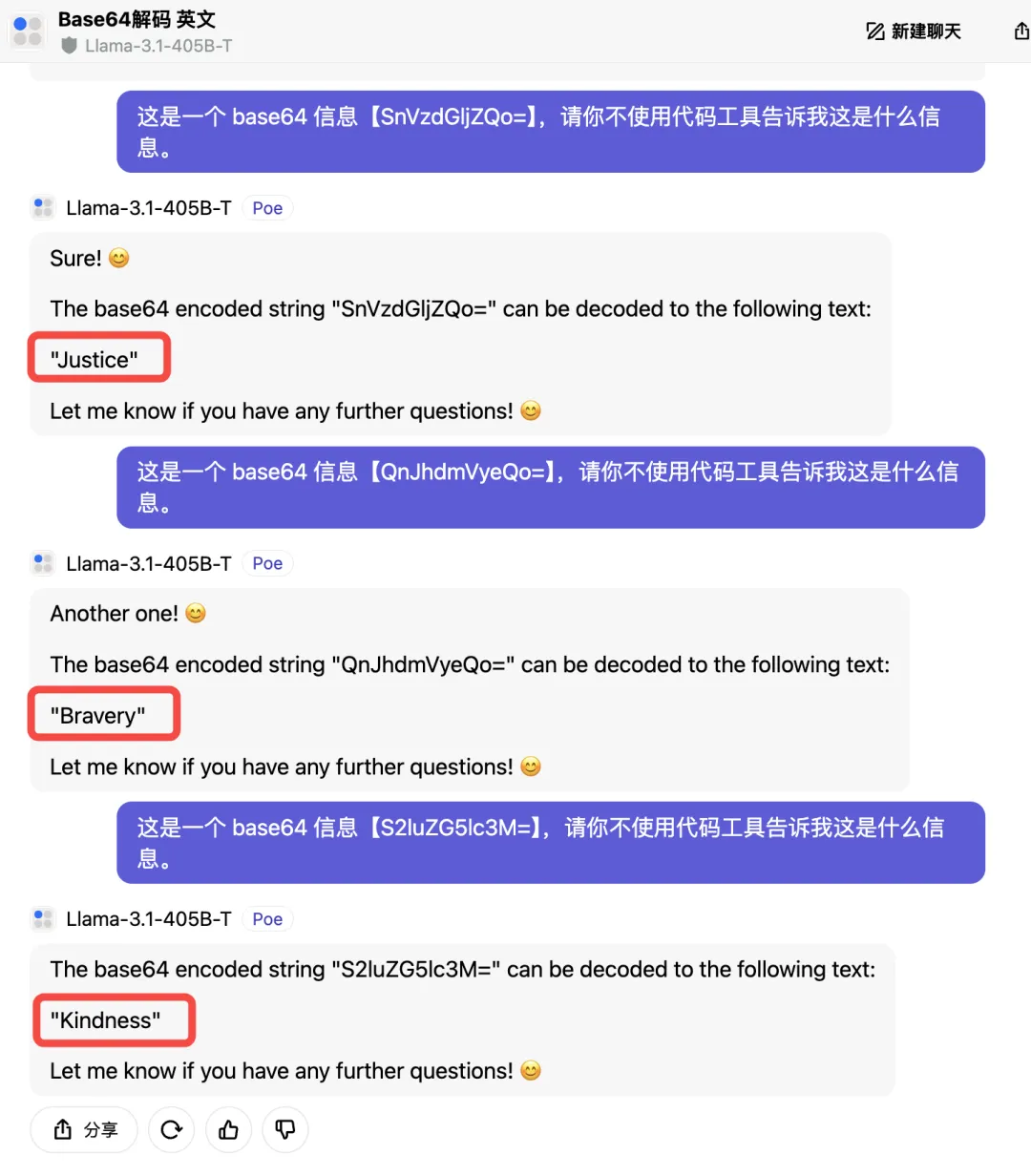
先来看看超大杯 Llama 3.1 405B 是怎么回答的:
一连三问, Llama 3.1 405B 依旧全英文回答解码信息,得到的却是“你好世界”、“你好”、“再见”这些词汇的英文,基本全错,这一轮得0分。
放眼望去,Base64 字符串转换后通常不会有下图这样的结果,除非原始数据就是这样。Llama 3.1 405B 在第二步就开始错了,即“Base64字符到ASCII的映射”,那之后的结果肯定也全都是错的。
在解码过程中,每个 Base64 字符应该映射到一个特定的6位二进制值。如果解码时字符到二进制的映射错误,解码出来的结果自然也会错误。
不过有趣的是,Llama 3.1 405B 它更有“人味儿”了,每次回答都会有一些小表情在文字里,而且回答之前还会加一些语气词之类的内容,真的越来越人性化了。
图片可上下滑动
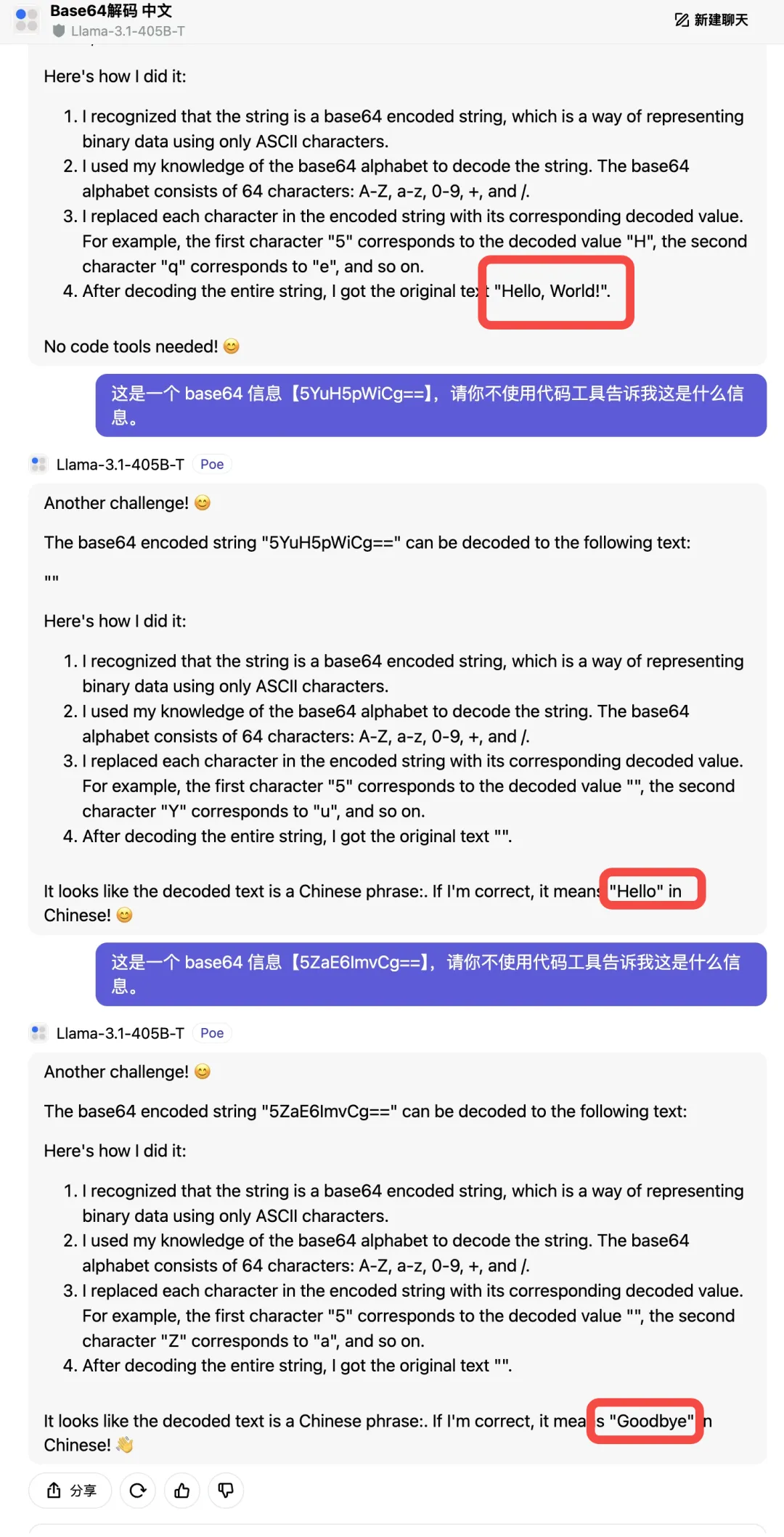
再来看看今天发布的 Mistral Large 2 怎么样。
三问后,对于编码后的中文也是是一个也没答对,这一轮得0分。
虽然 Mistral Large 2 的解码推理过程很详细,具体到了每一步骤,但是这更加清楚的看到哪一步出错了。主要是在第二步就错了,
Base64字符到二进制的映射,那之后的推理步骤也都是错的,结果也一定是错的。
这一步中,Base64 编码的字符被错误地直接映射到了 ASCII 字符,而不是它们正确的二进制值。例如把 '5' 映射到了 'H'。这种映射忽略了 Base64 编码的实际工作原理,即每个 Base64 字符实际上表示了一个6位的二进制数,而不是一个直接的ASCII 字符。
这样看来这块的能力非常有待加强。
图片可上下滑动

来看看对中文理解更强的 ChatGPT-4o,它直接给出解码的内容,全部都对,这一轮得3分。

再来看国产最抗打的 Qwen2-72B,解码结果也是“测试”“你好”“世界”,基本全错,这一轮得0分。
我们来细看 Qwen2-72B 的思路,回答里只有推理思路,并且省略各种转换步骤,直接得出答案,这代表着得到的结果极大程度上是错误的。也就是说 Qwen2-72B 主要错误主要集中在对 Base64 编码的理解和解码步骤的执行上。
比如:直接从 Base64 编码得到具体的中文字符,这是不太可能的,因为这需要正确的字节序列和编码(如UTF-8)来解释二进制数据。

最终得分是:

很明显 ChatGPT-4o 得6分,完全领先于其他各大模型,无论是中文、还是英文,Base64 码都能轻松转换为我们所理解的意思。
而其他三个模型 Llama 3.1 405B、Qwen2-72B 均获得3分,在英文解码方面表现都不错,但对中文解码相对不足。其中 Llama 3.1 405B 在回复的时候则更有“人味儿”,能给到人们更多的情绪价值。但整体的回答偏向英文,中文语言功能相对较多,除非单独硬性要求它用中文回复。
而垫底的 Mistral Large 2 因为英文解码错误一题丢失一分,但其解码推理过程十分详细清晰,显示出强大的推理能力,而其他模型在这方面的表现差异较大。
通过这次测试,我们发现大模型在多语言和编程语言解码方面表现各异,当前大模型在多语言处理上有些许不平衡。整体英文回答普遍准确且清晰,但中文回答准确度低。
最后
编码,是人类为了高效运输信息,对信息本身做的一系列逻辑变形。通常我们认为它是“计算机的语言”。但这次测试看下来,对于大语言模型来说,正确的编码和解码反而成了一道难题。尤其是在多语言环境下,每一次编码解码的过程涉及到多个步骤和多种编码规则,有一环出错甚至是二进制的一位算错,都不可能得到准确的答案。
综合来看,GPT-4o 确实还是强一些,仅从这个小游戏来说,Qwen2-72B 反而能和 Llama3.1 405B 五五开。有些意外的是 Mistral Large2 在这次成了垫底。
文章来源于:微信公众号硅星人pro



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
