# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想要看懂短视频,除了视觉内容外,语音和音频等听觉信息,如视频音乐、音效、语音内容等,也对短视频的理解起到关键作用。
音视频大语言模型(av-LLMs)在近几年取得了显著进展,但语音作为视频中人类语言的主要载体,仍未在这些模型中得到充分探索。语音不仅提供了丰富的语言和语义信息,还有助于理解视频中的情感和潜在意义。
与此同时,语音信号还包含丰富的副语言信息,如音调和音高,以及多样的说话者属性(如年龄、性别、口音和身份),这些都是视频理解中不可或缺的要素。
然而,增强通用视听大语言模型的语音能力极具挑战性,这需要时间上精细的建模,并在粗略(如视频主题)和精细(如唇部动作)时间尺度上与其他模态进行复杂的交互。
近期,发表在ICML 2024的论文《video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models》成为了首个集齐视频中所有音视频元素(自然图像、文字、语音、音频事件、音乐)的大模型。

video-SALMONN论文链接:https://openreview.net/pdf?id=nYsh5GFIqX
SALMONN论文链接:https://arxiv.org/abs/2310.13289
Github Page:https://github.com/bytedance/SALMONN
通过下面几个例子,一起来看看video-SALMONN是如何通过语音-音频-视频的信息来解读视频内容的吧!
首先来一段经典的《泰坦尼克号》片段

让video-SALMONN来谈谈为什么这段视频很浪漫吧:

问题:
请结合视频,音频和人物对白解释为什么视频很浪漫
回答:
这段视频展示了一对男女在船上的浪漫场景。男人把女人拥在怀里,两人一起看着日落。背景音乐是一首歌,增添了浪漫的气氛。女人说「我在飞」和「杰克」,这表明他们很幸福,享受这一刻。船和日落的背景创造了一个美丽宁静的环境,增强了视频的浪漫感觉。男女的肢体语言和面部表情也传达了他们对彼此的爱和深情。总的来说,这段视频完美地展现了两人之间浪漫而亲密的时刻。
不止描述看到的场景,video-SALMONN还把听到的音乐,和人物的对白,都融合进了他的描述里。
更惊喜的是,video-SALMONN还能知道是女人说的「我在飞」,进一步询问的话,
此外,video-SALMONN还能推理出男人的名字是「杰克」。
我们都知道,正是这两句对白成就了这个经典场景,而video-SALMONN恰恰抓住了这个场景的精髓所在!
再来一段《疯狂动物城》的动画片段:
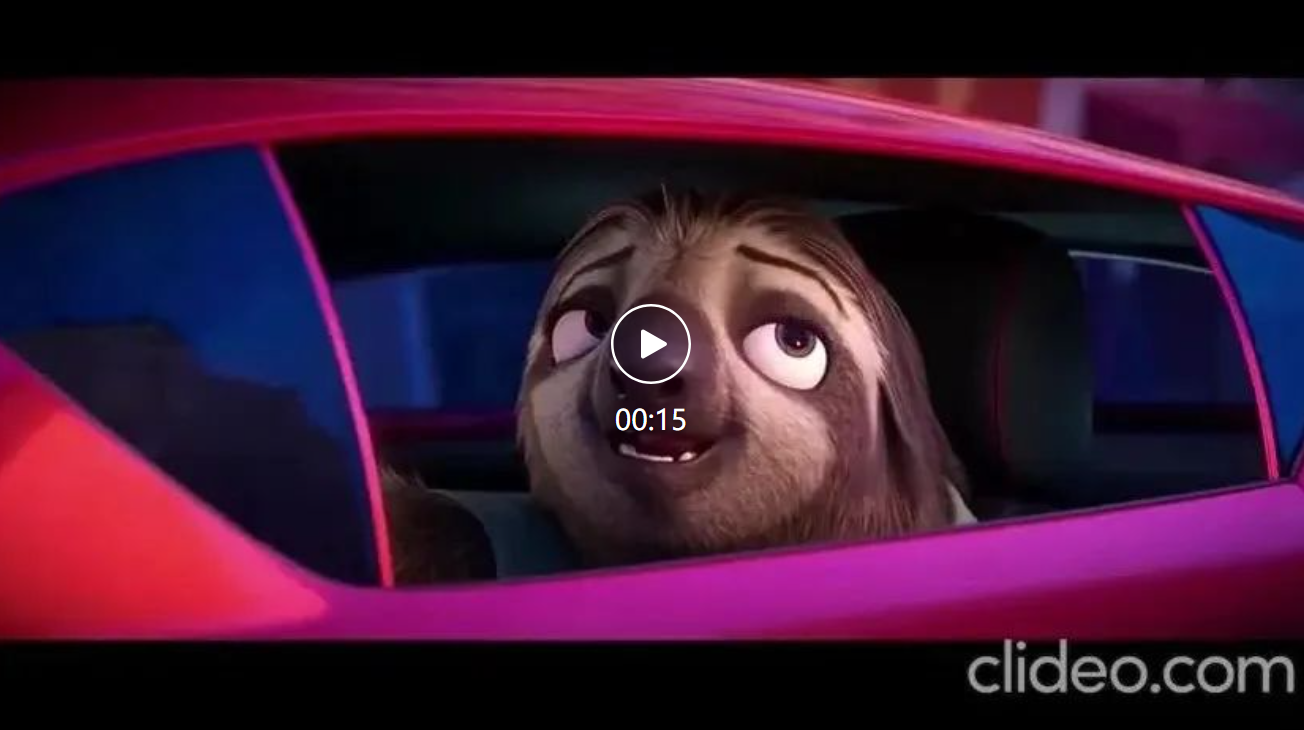
看看video-SALMONN是怎么理解树獭的搞笑之处吧:

问题:
场景中有兔子,狐狸和树獭,树獭说了什么?为什么树獭很有趣?
回答:
树懒在视频结尾时说了「Nick」。树懒之所以搞笑,是因为它是一种动作缓慢的动物,在视频中表现得非常懒散,做事情花了很长时间。这与其他动物(如兔子和狐狸)的活跃和充满活力形成了鲜明对比,使树懒显得尤为突出,增加了幽默感。此外,视频中树懒的慢动作和表情也增加了它的喜剧效果。
这个例子展示了视听结合对说话人的识别,只有听觉我们不知道是树獭在说话,只有视觉我们不知道树獭说了什么,只有视听结合才能真正理解视频!
还有这个非常受欢迎的meme:

问问video-SALMONN这个视频为什么搞笑吧:

问题:
你可以解释为什么这个视频很有趣吗?
回答:
这段视频之所以有趣,是因为它展示了一个男人做了一个滑稽的表情,然后说「nice」。他严肃的表情与「nice」这个词之间的反差创造了幽默感和惊喜感。此外,男人打嗝的声音效果和响亮的爆破音也增加了视频的娱乐价值。
再来看一段国家地理的纪录片片段,让我们来看看理解语音还有什么帮助:

问问video-SALMONN视频里是哪种鲨鱼吧:

问题:
视频中的鲨鱼是哪种鲨鱼?
带audio输入的回答:
视频中的鲨鱼是一头鲸鲨
不带audio输入的回答:
视频中的鲨鱼是一头大白鲨
光看视频,没点专业知识真的不知道是哪种鲨鱼,模型就只能猜,容易出现幻觉。
但是听了语音讲解,video-SALMONN就能准确知道视频讲的是鲸鲨,再也不用瞎猜了。
还有这个大佬之间对话的视频片段:
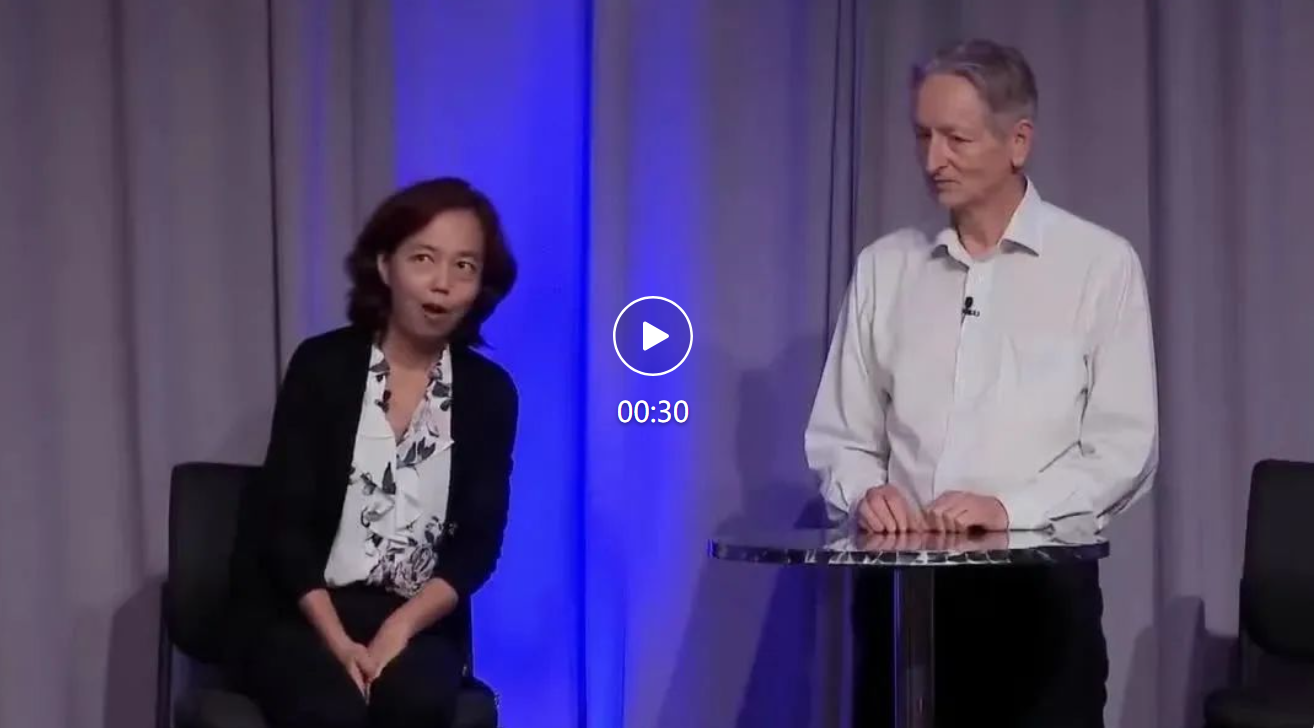
不止理解对话内容,video-SALMONN还将说话人和对话内容联系到了一起:

提问:
基于视频和语音,是视频中飞去了Florence的是男人还是女人?
回答:
是女人飞去了Florence
这个例子进一步展示了video-SALMONN对视频里语音的全方位理解。
如果直接输入语音转录的文字,模型是不可能知道到底是谁飞去了Florence,而video-SALMONN可以将语音内容和说话人信息紧密结合在一起
接下来是干货部分:让我们一起来看看video-SALMONN具体是怎么实现语音-音频-视频的综合理解的吧!
核心技术
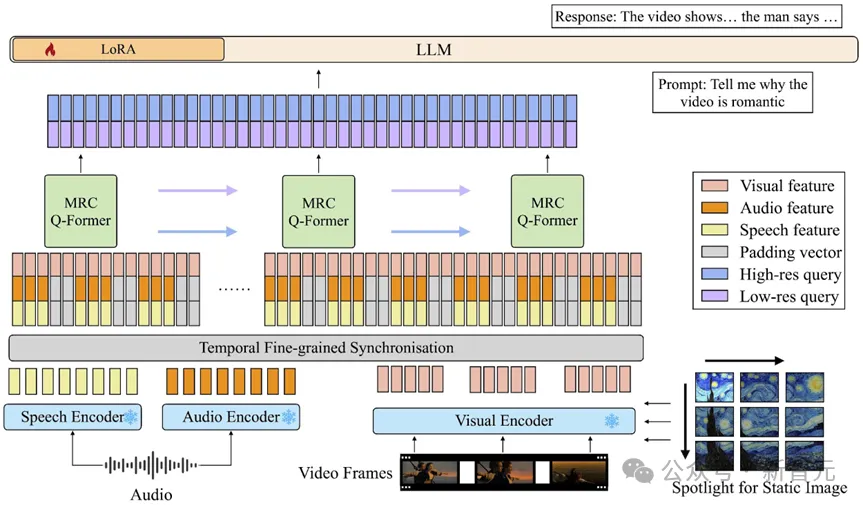
video-SALMONN模型
面对音视频大模型中语音理解挑战,video-SALMONN通过以下三部分创新,使其能够处理自然图像、视觉帧序列、语音、音频事件和音乐元素等各种视频基本元素:
第一部分:音视频编码和时间对齐
video- SALMONN使用Whisper语音编码器和BEATs音频编码器,分别得到语音和音频的编码向量序列(每1秒音频对应50个向量),同时使用InstructBLIP视觉编码器,以2 FPS的视频采样率得到视觉编码向量序列(每1秒视频2帧,对应64个向量)。
三个序列在时间维度上,以视频帧为基准每0.5秒对齐并拼接一次(temporal fine-grained synchronisation),因为语音音频序列略短于视觉序列,短的部分加上zero padding。
第二部分:多分辨率因果Q-Former
多分辨率因果(MRC)Q-Former结构是video-SALMONN的创新核心,它不仅在多个不同的时间尺度上将时间同步的视听输入特征与文本表示空间对齐,满足依赖于不同视频元素的任务需求,同时为了加强连续视频帧之间事件的时间因果关系,引入了带有特殊因果掩码的因果自注意结构。
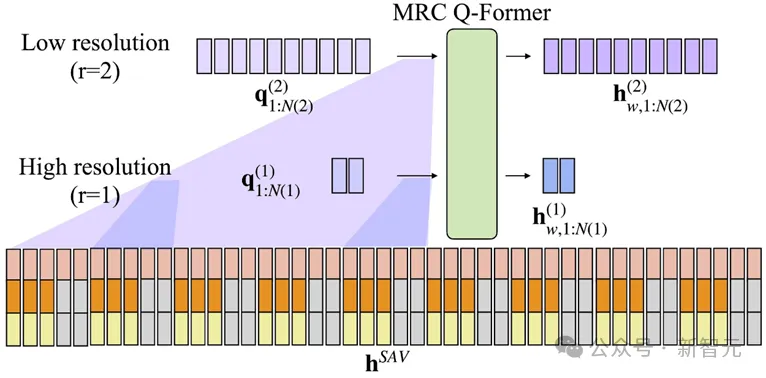
MRC Q-Former结构
首先,MRC Q-Former将输入序列分成不同长度的窗。然后,在每一个窗内,用Q-Former把拼接后的多模态表征映射到语义表征空间。最后,将每个分辨率层级内的各个窗Q-Former输出的向量串起来形成语义空间的向量序列。
MRC Q-Former通过保证输出向量个数和窗长比为定值,来保证不同分辨率层级的输出序列可以直接在特征维度拼接,拼接后的向量通过线性层映射后用作大语言模型的输入。
通过训练,高分辨率的Q-Former可以捕捉细粒度的信息,比如语音内容以及语音和唇部动作的联系,低分辨率的Q-Former可以有效提取视频层级的信息,对视频的整体内容以及多个帧之间的关系有更好的理解。
(注:MRC Q-Former结构也适用于空间上的多分辨率,论文首次提出image spotlight方法,可以将图片拆分成不同精度的子图序列作为输入,从而大大提高图像理解的性能)
第三部分:多样性损失函数和混合未配对音视频数据的训练
此外,为了避免视频中某一特定帧主导地位,video-SALMONN在交叉熵的基础上,提出并使用了一种新的多样性损失函数,鼓励模型探索整个序列的不同部分。
同时,为了防止配对音视频数据中的单一模态的主导问题(比如视频中非语音音频往往只提供极少量的辅助信息,容易被忽视),video-SALMONN使用混合未配对的音频和视频的策略进行训练,使video-SALMONN不得不同时注意两个模态的信息。
主要结果
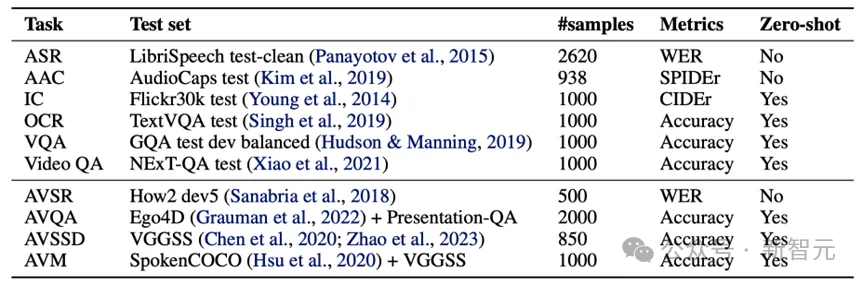
Video-SALMONN论文提出speech-audio-visual evaluation (SAVE) benchmark来测试,并在语音,非语音音频,图像和视频等任务上均展示了不俗的表现。
SAVE的测试任务包括语音识别 (ASR),音频描述 (AAC),图片描述 (IC),视觉文字识别 (OCR),图片问答 (VQA),视频问答 (Video QA) 等视觉和听觉单一输入模态的任务,还包括视听语音识别 (AVSR),音视频问答 (AVQA),音视频声源检测 (AVSSD)和音视频匹配 (AVM)四个音视频共同输入的感知任务。
其中,AVQA为新提出的测试集,AVM为新提出的任务,要求模型判断音频和视频是否匹配。
首先,video-SALMONN在单一模态输入的任务上,达到了和仅能处理视觉或听觉一种模态输入的模型相同甚至更好的效果。
相比同样可以处理音视频的大模型Video-LLaMA,video-SALMONN不仅增加了对语音输入的理解能力,而且在各个单模态任务上远超其表现。

在音视频共同输入的理解任务上,video-SALMONN更是展现了远超其他模型的表现。
得益于其理解语音的能力,video-SALMONN在AVQA上大幅超过同类大模型Video-LLaMA。
更重要的是,在AVM和AVSSD这两个完全没有训练过的任务上,video-SALMONN展现了出色的语音-音频-视觉联合推理的零样本的涌现能力。
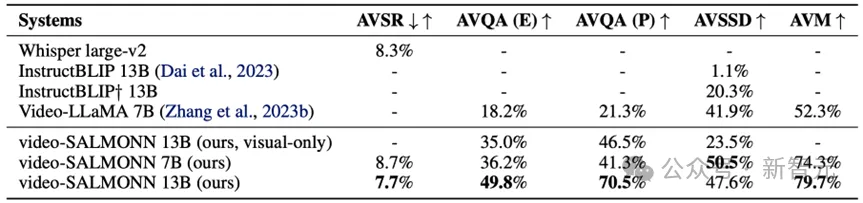
这些共同推理的涌现能力需要模型同时给予输入的视觉和听觉信息等量的关注,且可以理解视听之间复杂的联系。
然而现存的开源模型,要么无法完全理解音频,要么仅能分别描述每个单一的输入模态。
结语
video-SALMONN的推出,将有助于提升视频理解技术的全面性和准确性,为视频内容分析、情感识别、多模态交互等领域带来新的机遇。
该模型不仅在学术研究上具有重要意义,也为实际应用提供了强大的技术支撑。
参考资料:
https://openreview.net/pdf?id=nYsh5GFIqX
文章来源于:微信公众号新智元



【开源免费】Whisper是由openai出品的语音转录大模型,它可以应用在会议记录,视频字幕生成,采访内容整理,语音笔记转文字等各种需要将声音转出文字等场景中。
项目地址:https://github.com/openai/whisper
在线使用:https://huggingface.co/spaces/sanchit-gandhi/whisper-jax
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
