# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Claude团队这次惹了众怒!
原因:24小时内访问某公司服务器100万次,以不付费形式,爬虫抓取网站内容。
不仅明目张胆无视了“禁止爬取”的公告,还强行占用了服务器资源。
这家“受害者”公司其实尽力防御了,但阻止失败,内容数据还是被Claude抓走了。
公司负责人气得吹胡子瞪眼,在x上激情开麦:
嘿,Anthropic,我知道您渴望数据。Claude真的很聪明!
但你造吗,这一点也不!酷!哦!

许多网友为此愤愤不平,有个搞文案工作的网友留言称:
“我建议用‘偷’,而不是‘不付费’来描述Anthropic的这种行为。”

一时之间,群情激愤!
支持声讨的,要求Claude付费的,评论区简直乱成一锅粥了。

强烈谴责Anthropic的这家公司叫做iFixit,是一家美国电子商务和操作指南网站。
iFixit的业务的一部分,是为消费电子产品和小工具提供类维基百科的免费在线维修指南。
网站内有数百万个页面,包括修理指南、指南的修订历史、博客、新闻帖子和研究、论坛、社区贡献的修理指南和问答部分等。
但,iFixit突然发现,Claude的爬虫程序ClaudeBot在几个小时内,每分钟都有数千次请求访问。
这约等于一天内访问其网站近百万次。
据统计,它一天内访问了10 TB的文件,整个5月份总计访问了73 TB。

为此,iFixit的CEO老K(Kyle Wiens)丢下一句话:
未经许可,ClaudeBot偷走我们所有的数据,还把我们的服务器占满了……Fine,这也没什么大不了。
不知道它有没有爬到我们的许可说明??
对你没看错,「未经许可」。
iFixit其实有写声明——
未经iFixit明确事先书面许可,严禁因为任何其他目的(包括训练机器学习或人工智能模型)复制、复制或分发本网站上的任何内容、材料或设计元素。

然并卵。
Claude不仅视若无睹地继续疯狂访问-抓取,还躲避了iFixit的防御。
iFixit其实成功阻止了两个Anthropic的AI抓取机器人,分别名为“ANTHROPIC-AI”和“CLAUDE-WEB”。
但这俩AI抓取机器人似乎已经是过去式了,目前的主力爬虫正是没被阻止成功的“ClaudeBot”。
逼不得已,老K表示,iFixit本周修改了robots.txt文件,专门用来阻止Anthropic的爬虫机器人。

那,Anthropic那边有啥反应不?
它们倒是没有闭麦,对媒体回应道:
ANTHROPIC-AI 和 CLAUDE-WEB 这俩确实是公司使用过的旧爬虫,但现在已经停止使用了。
当然了,Anthropic回避了现在活跃的ClaudeBot是否尊重防爬虫robots.txt阻止被爬取的问题。
翻看Anthropic的官方网站可以发现,早就挂着一篇名为《Anthropic是否从网络上抓取数据?网站所有者如何阻止抓取工具?》的文章。
里面提到:
根据行业标准,Anthropic使用各种数据源进行模型开发,例如通过网络爬虫收集的来自互联网的公开数据。
我们的爬取不应具有侵入性或破坏性。
我们的目标是通过考虑爬取相同域的速度,并在适当的情况下尊重爬行延迟来将干扰降到最低。

但一片舆论声中不难发现,Anthropic显然不是这么做的。
它,未经允许爬取别人数据,老惯犯了。
就说今年4月的时候,Linux Mint论坛就惨遭被爬。
在几个小时中,ClaudeBot多次访问论坛爬取数据,导致论坛在几个小时内处于超低速or崩溃状态,最终完全崩掉。
有人表示,在同一时间内,ClaudeBot占用的流量独占鳌头,是第二名的20倍、第三名的40倍。
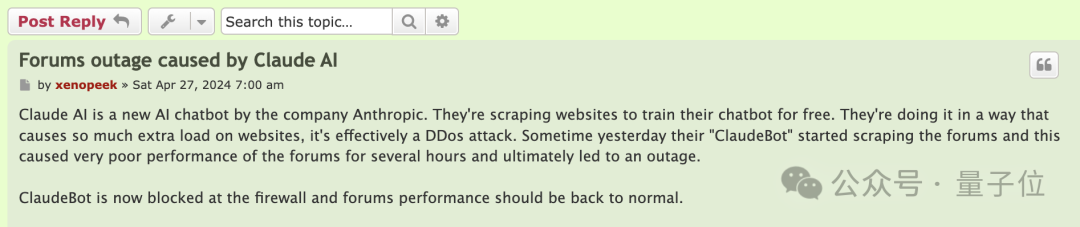
在4月事件和本次事件的讨论贴中,都有人建议:
既然放禁爬取公告没有用,那不放在网站中搞一些带有可追踪or独特信息的虚假信息,以便检测是谁偷走了数据。
iFixit确实也这么做了。
而且真的有用——发现自家网站的信息不仅被Claude爬个底朝天,还被OpenAI也爬走了……

讲道理,有什么办法呢?真的一点办法也没有。
因为除了Claude和GPT以外,这样强行偷家的AI挺不少的。
前几天就有一家名为Tollbit的机器人检测初创公司声称Perplexity、Claude、OpenAI会忽略爬取网站上的robots.txt设置——当时有人跑去问了OpenAI的态度,OpenAI不予置评。
再往前看,上个月也闹过一次。
《福布斯》谴责AI搜索产品Perplexity涉嫌抄袭其新闻文章;一石激起千层浪,更多媒体站出来,指责Perplexity的爬虫机器人PerplexityBot非法抓取自家网站信息。
而Perplexity一直的态度都是:
尊重出版商不抓取内容的要求,并且在合理使用版权法的范围内运营。
理论上讲,不管是ClaudeBot还是PerplexityBot,在遇到标明“禁止抓取”“禁止robot.txt”的文件时,都应该遵从协议,规避爬取声明方网站的内容。
既然声明无效,就有人呼吁创作者把内容尽可能转移到付费区域,来防止无限制的抓取。
你觉得这样的办法会有效吗?
文章来源于“量子位”,作者“关注前沿科技”




【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
