# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近一段时间开源大模型市场非常热闹,先是苹果开源了70亿参数小模型DCLM,然后是重量级的Meta的Llama 3.1 和Mistral Large 2相继开源,在多项基准测试中Llama 3.1超过了闭源SOTA模型。
不过开源派和闭源派之间的争论并没有停下来的迹象。
一边是Meta在Llama 3.1发布后表示:“现在,我们正在迎来一个开源引领的新时代。”另一边是Sam Altman在《华盛顿邮报》撰文,直接把开源闭源的矛盾上升到国家和意识形态层面。
在前段时间的世界人工智能大会上,李彦宏直言“开源其实是一种智商税”,因为闭源模型明明性能强,推理成本更低,再次引发讨论。
随后,傅盛也发表了他的看法,他认为开源和闭源这两个阵营是彼此共同竞争,共同发展。并对“开源其实是一种智商税”这一观点进行了反驳:“开源大语言模型是免费的,他怎么来的智商税呢,谁在收税?”,
“如果今天企业用付费闭源大语言模型,那才叫'智商税',尤其是收很高的模型授权费、API费用,一年花了数百上千万,最后买回去当个摆设,甚至员工根本用不起来(模型)。”
这场争论的核心涉及到技术发展的方向和模式,反映了不同利益相关者的观点和立场,在我们谈论大语言模型的开源和闭源之前,需要厘清先“开源”和“闭源”这两个基本概念。
“开源”一词源自软件领域,指在软件开发过程中公开其源代码,允许任何人查看、修改和分发。开源软件的开发通常遵循互惠合作和同侪生产的原则,促进了生产模块、通信管道和交互社区的改进,典型代表包括Linux,Mozilla Firefox。
闭源软件(专有软件)由于商业或其他原因,不公开源代码,只提供计算机可读的程序(如二进制格式)。源代码仅由开发者掌握和控制。典型代表包括Windows,安卓。
开源是一种软件开发模式,基于开放、共享和协作,鼓励大家共同参与软件的开发和改进,推动技术的不断进步和广泛应用。
选择闭源开发的软件更有可能成为一个稳定、专注的产品,但是闭源软件通常需要花钱,且如果它有任何错误或缺少功能,只能等待开放商来解决问题。
至于什么是开源大模型,业界并没有像开源软件一样达成一个明确的共识。
大语言模型的开源和软件开源在理念上是相似的,都是基于开放、共享和协作,鼓励社区共同参与开发和改进,推动技术进步并提高透明性。
然而,在实现和需求上有显著区别。
软件开源主要针对应用程序和工具,开源的资源需求较低,而大语言模型的开源则涉及大量计算资源和高质量的数据,并且可能有更多使用限制。因此,虽然两者的开源都旨在促进创新和技术传播,但大语言模型开源面临更多的复杂性,社区贡献形式也有所不同。
李彦宏也强调了两者的区别,模型开源不等于代码开源:“模型开源只能拿到一堆参数,还要再做SFT(监督微调)、安全对齐,即使是拿到对应源代码,也不知道是用了多少比例、什么比例的数据去训练这些参数,无法做到众人拾柴火焰高,拿到这些东西,并不能让你站在巨人的肩膀上迭代开发。”
大语言模型的全流程开源包括将模型开发的整个过程,从数据收集、模型设计、训练到部署,所有环节都公开透明。这种做法不仅包括数据集的公开和模型架构的开放,还涵盖了训练过程的代码共享和预训练模型权重的发布。
过去一年,大语言模型的数量大幅增加,许多都声称是开源的,但它们真的有多开放呢?
荷兰拉德堡德大学的人工智能研究学者Andreas Liesenfeld和计算语言学家Mark Dingemanse也发现,虽然“开源”一词被广泛使用,但许多模型最多只是“开放权重”,关于系统构建的其他大多数方面都隐藏了起来。
比如Meta和微软等科技虽将其大语言模型标榜为“开源”,却并未公开底层技术相关的重要信息。而让他们意外的是,资源更少的AI企业和机构的表现更令人称赞。
该研究团队分析了一系列热门“开源”大语言模型项目,从代码、数据、权重、API到文档等多个方面评估其实际开放程度。研究还将OpenAI的ChatGPT作为闭源的参考点,凸显了“开源”项目的真实状况。
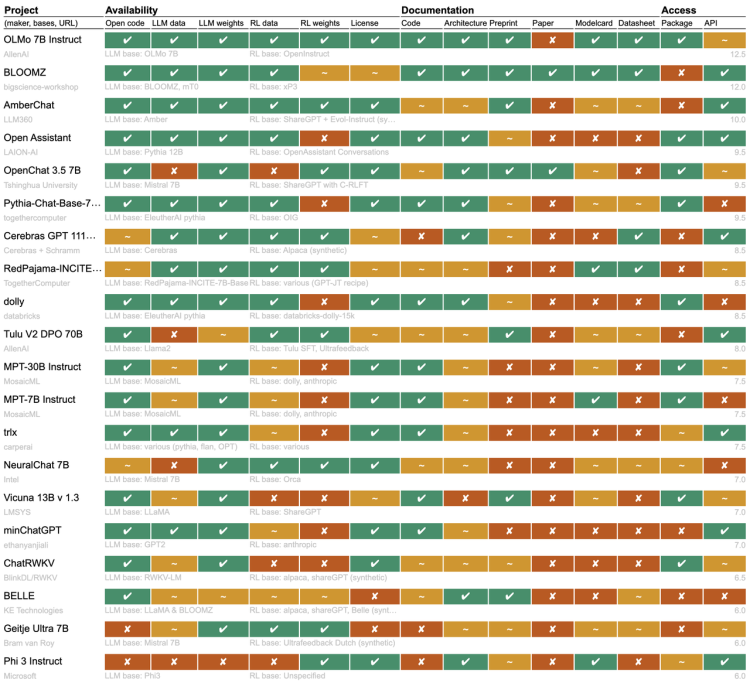
✔为开放,~为部分开放,X为封闭
结果显示,项目间差异显著,根据这个排行榜,Allen Institute for AI的OLMo是最开放的开源模型,其次是BigScience的BloomZ,两者都是由非营利组织开发。
论文称,Meta的Llama以及 Google DeepMind的Gemma 虽然自称开源或开放,但实际上只是开放权重,外部研究人员可以访问和使用预训练模型,但无法检查或定制模型,也不知道模型如何针对特定任务进
行微调。
最近LLaMA 3和Mistral Large 2的发布引起了广泛关注。在模型在开放性方面,LLaMA 3公开了模型权重,用户可以访问和使用这些预训练和指令微调后的模型权重,此外Meta还提供了一些基础代码,用于模型的预训练和指令微调,但并未提供完整的训练代码,LLaMA 3 的训练数据也并未公开。不过这次LMeta带来了关于LLaMA 3.1 405B 的一份93页的技术报告。
Mistral Large 2的情况类似,在模型权重和 API 方面保持了较高的开放度,但在完整代码和训练数据方面的开放程度较低,采用了一种平衡商业利益和开放性的策略,允许研究使用但对商业使用有所限制。
谷歌表示,该公司在描述模型时“在语言上非常精确”,他们将Gemma称为开放而非开源。“现有的开源概念并不总能直接应用于 AI 系统,”
这项研究的一个重要背景是欧盟的人工智能法案,该法案生效时,对归类为开放的模型实施较宽松的监管,因此关于开源的定义可能会变得更加重要。
研究人员表示,创新的唯一途径是通过调整模型,为此需要足够的信息来构建自己的版本。不仅如此,模型还必须接受审查,例如,一个模型在大量测试样本上进行了训练,那么它通过特定测试可能并不算一项成就。
他们也对如此多的开源替代方案的出现感到令人欣喜,ChatGPT非常受欢迎,以至于很容易让人们忘记对其训练数据或其他幕后手段一无所知。对于那些希望更好地了解模型或基于构建应用的人来说,这是一个隐患,而开源替代方案使得关键的基础研究成为可能。
硅星人也对国内部分开源大语言模型的开源情况进行了统计:
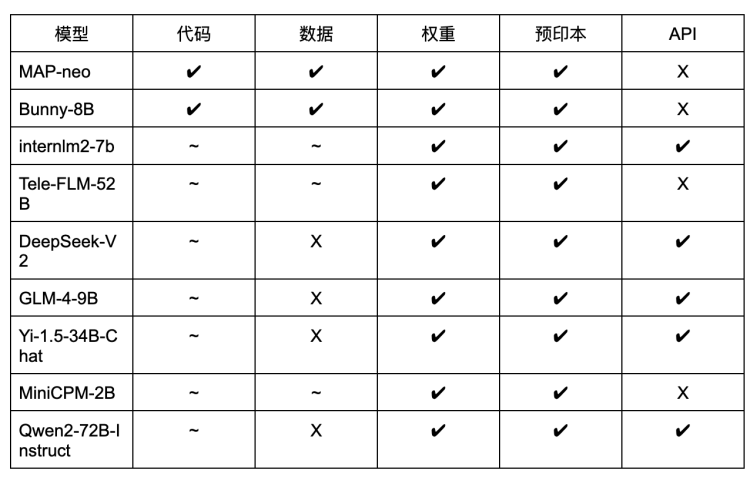
从表中我们可以看到,和海外的情况类似,开源较为彻底的模型基本是由研究机构主导,这主要是因为研究机构的目标是推动科研进步和行业发展,更倾向于开放其研究成果。
而商业公司则利用其资源优势,开发出更为强大的模型,并通过适当的开源策略在竞争中获得优势。

从GPT-3到BERT以来,开源为大模型生态系统带来了重要的推动力。
通过公开其架构和训练方法,研究人员和开发者可以在这些基础上进行进一步的探索和改进,催生出更多前沿的技术和应用。
开源大模型的出现显著降低了开发的门槛,开发者和中小企业能够利用这些先进的AI技术,而不必从零开始构建模型,从而节省了大量的时间和资源。这使得更多创新项目和产品得以快速落地,推动了整个行业的发展。开发者们在开源平台上积极分享优化方法和应用案例,也促进了技术成熟和应用。
对教育和科研而言,开源大语言模型提供了宝贵资源。学生和新手开发者通过研究和使用这些模型,能快速掌握先进AI技术,缩短学习曲线,为行业输送新鲜血液。
然而,大语言模型的开放性并非简单的二元特性。基于Transformer的系统架构及其训练过程极为复杂,难以简单归类为开放或封闭。开源大模型并非一个简单的标签,更像一个光谱,从完全开源到部分开源,程度各异。
大语言模型的开源是一项复杂而细致的工作,并非所有模型都必须开源。
更不应以“道德绑架”的方式要求全面开源,因为这涉及大量技术、资源和安全考量,需要平衡开放与安全、创新与责任。正如科技领域的其他方面一样,多元化的贡献方式才能构建一个更丰富的技术生态系统。
开源和闭源模型的关系或许可以类比于软件行业中开源和闭源软件的共存。
开源模型促进了技术的广泛传播和创新,为研究者和企业提供了更多可能性,而闭源模型则推动着整个行业的标准的提升。两者的良性竞争激发了持续改进的动力,也为用户提供了多样化的选择。
正如开源和专有软件共同塑造了今天的软件生态,开源和闭源大模型之间也并非二元对立,两者的并存发展是推动AI技术不断进步、满足不同应用场景需求的重要动力。最终,用户和市场会作出适合自己的选择。
文章来源微信公众号“硅星人Pro”,作者“周一笑”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
