# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前,人工智能(AI)已广泛应用于众多领域,包括计算机视觉、自然语言处理、时间序列分析和语音合成等。
在深度学习时代,尤其是随着大型语言模型(LLMs)的出现,大多数研究人员的注意力都集中在追求新的最先进(SOTA)结果上,使得模型规模和计算复杂性不断增加。
对高计算能力的需求带来了更高的碳排放,也阻碍了资金有限的中小型公司和研究机构的参与,从而破坏了研究的公平性。
为了应对 AI 在计算资源和环境影响方面的挑战,绿色计算(Green Computing)已成为一个热门研究课题。
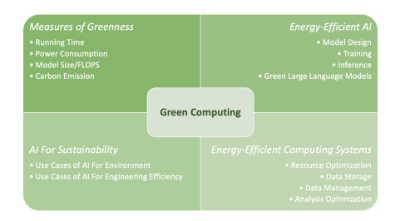
近日,蚂蚁集团携手国内众多高校和研究机构共同发布一项调查报告,系统地概述了绿色计算所使用的技术,并提出了一个绿色计算框架,其中包括以下四个关键组成部分:
该研究指出,“这一新的研究方向有可能解决资源限制和 AI 发展之间的冲突。”
相关研究论文以“On the Opportunities of Green Computing: A Survey”为题,已发表在预印本网站 arXiv 上。
论文链接:https://arxiv.org/abs/2311.00447
从众多 AI 算法的训练和推理案例中,模型大小、参数调优和训练数据成为影响计算资源的三大主要因素。在这基础上,该研究总结了六种常见的“环保性”测量方法,包括运行时间、模型大小、FPO/FLOPS(浮点运算操作数)、硬件功耗、能源消耗以及碳排放。
用于跟踪“环保性”测量的工具包括 tfprof、绿色算法、CodeCarbon、Carbontracker 以及自动 AI 模型环保性跟踪工具包。
在图像分类、目标检测和其他 AI 任务中,一些传统的深度学习神经网络模型,如 LeNet、VGG、GoogleNet 等,虽然取得了不错的性能,但却需要过多的计算资源。因此,该研究提出使用 Depth-wise Separable Convolution、Fire Convolution、Flattened Convolution 以及Shrinked Convolution 等方法来解决这一问题。
此外,在开发基于图数据的神经网络方面,该研究还提出了 ImprovedGCN,其中包含 GCN 的主要必要组成部分。另外,该研究还推荐了另外一种神经网络——SeHGNN,用于汇总预先计算的邻近表示,降低了复杂性,避免了在每个训练周期中重复聚合邻近顶点的冗余操作。
在时间序列分类方面,目前常用的集成学习方法需要大量计算资源。为此,研究建议使用LightTS 和 LightCTS 两种方法来解决这个问题。
另外,Transformer 是一个强大的序列模型,但随着序列长度的增加,其需要的时间和内存呈指数级增长。自注意力(Self-Attention)类型的网络在处理长序列时需要大量内存和计算资源。为此,研究建议使用 Effective Attention 以及 EdgeBERT 和 R2D2 两种模型来应对这一挑战。
除了特定神经网络组件的设计,还有一些通用策略可以用于高效的神经网络结构设计,例如低秩模块策略、静态参数共享、动态网络和超级网络等策略。这些策略可以无缝地集成到任何参数化结构中。
在模型训练方面,研究总结了有效训练范式、训练数据效率以及超参数优化三个方面的方法。为了实现绿色 AI,降低神经网络的能源消耗,可以采用模型剪枝、低秩分解、量化和蒸馏等有效方法。
在节能计算系统方面,研究简要介绍了包括优化云数据库资源利用、硬件和软件协同设计等多方面的解决方案,这些原则也同样适用于数据分析领域,包括利用混合查询优化和机器学习等技术,以提高处理过程的能源效率。
值得注意的是,绿色计算强调的是 AI 不仅在其自身的开发和运行中应具备能源效率,还应积极参与各种绿色应用领域,以解决环境和可持续性挑战。
研究指出,AI 能够有效地从监测数据、遥感数据和气象数据中提取有用信息,其中涵盖了空气污染监测、碳封存估算、碳价格预测等众多领域,从而为决策和行动提供指导。
目前,尽管绿色计算已经在能源效率和碳减排方面取得成功,但计算资源仍然成为产业增长的瓶颈。为此,该研究提出了一些未来研究方向,包括在模型评估中加入“绿色度”测量,制定广泛接受的绿色度评估框架,探索更小但更高效的语言模型,以及鼓励更多工业应用以降低对环境的影响。
另外,研究指出,绿色计算的未来将依赖于学术界、产业界和政府的共同努力,以实现环境可持续性和 AI 效率的平衡发展。政策支持、创新合作和最佳实践分享将是推动这一领域进一步发展的关键。
文章来自微信公众号 “学术头条”,作者 闫一米