# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 MIPL实验室,第一作者为博士生徐铸,通讯作者为博士生导师刘洋。MIPL 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项代表性成果发表,多次荣获国内外 CV 领域重量级竞赛的冠军奖项,和国内外知名高校、科研机构广泛开展合作。
人物交互图像生成指生成满足文本描述需求,内容为人与物体交互的图像,并要求图像尽可能真实且符合语义。近年来,文本生成图像模型在生成真实图像方面取得出了显著的进展,但这些模型在生成以人物交互为主体内容的高保真图像生成方面仍然面临挑战。其困难主要源于两个方面:一是人体姿势的复杂性和多样性给合理的人物生成带来挑战;二是交互边界区域(交互语义丰富区域)不可靠的生成可能导致人物交互语义表达的不足。
针对上述问题,来自北京大学的研究团队提出了一种姿势和交互感知的人物交互图像生成框架(SA-HOI), 利用人体姿势的生成质量和交互边界区域信息作为去噪过程的指导,生成了更合理,更真实的人物交互图像。为了全面测评生成图像的质量,他们还提出了一个全面的人物交互图像生成基准。

SA-HOI 是一种语义感知的人物交互图像生成方法,从人体姿态和交互语义两方面提升人物交互图像生成的整体质量并减少存在的生成问题。通过结合图像反演的方法,生成了迭代式反演和图像修正流程,可以使生成图像逐步自我修正,提升质量。
研究团队在论文中还提出了第一个涵盖人 - 物体、人 - 动物和人 - 人交互的人物交互图像生成基准,并为人物交互图像生成设计了针对性的评估指标。大量实验表明,该方法在针对人物交互图像生成的评估指标和常规图像生成的评估指标下均优于现有的基于扩散的图像生成方法。
方法介绍
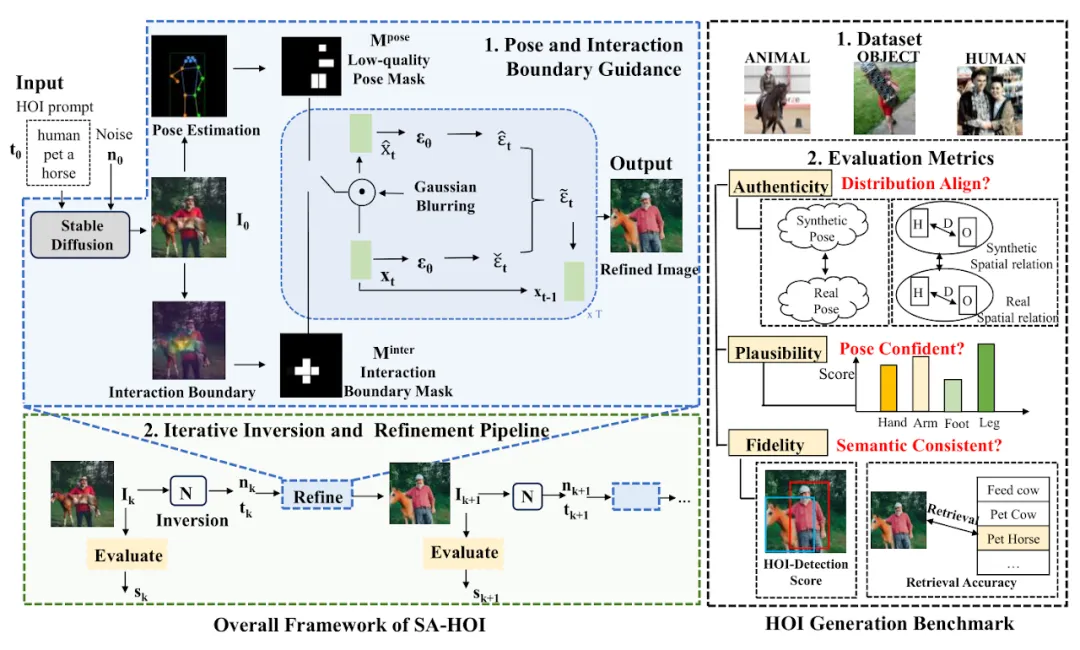
图 1:语义感知的人物交互图像生成方法框架图
论文中提出的方法如图 1 所示,主要由两个设计组成:姿态和交互指导(Pose and Interaction Guidance, PIG)和迭代反演和修正流程(Iterative Inversion and Refinement Pipeline, IIR)。
在 PIG 中,对于给定的人物交互文本描述和噪声,首先使用稳定扩散模型(Stable Diffusion [2])生成作为初始图像,并使用姿态检测器 [3] 获取人类体关节位置 和相应的置信分数 , 构建姿态掩码 高亮低质量姿态区域。
对于交互指导,利用分割模型定位交互边界区域,得到关键点和相应的置信分数, 并在交互掩码中高亮交互区域,以增强交互边界的语义表达。对于每个去噪步骤, 和 作为约束来对这些高亮的区域进行修正,从而减少这些区域中存在的生成问题。此外, IIR 结合图像反演模型 N,从需要进一步修正的图像中提取噪声 n 和文本描述的嵌入 t,然后使用 PIG 对该图像进行下一次修正,利用质量评估器 Q 对修正后的图像质量进行评估,以 < 反馈、评估、修正 > 的操作来逐步提高图像质量。
姿态和交互指导

图 2:姿势和交互指导采样伪代码
姿势和交互引导采样的伪代码如图 2 所示,在每个去噪步骤中,我们首先按照稳定扩散模型(Stable Diffusion)中的设计获取预测的噪声 ϵt 和中间重构 。然后我们在 上应用高斯模糊 G 来获得退化的潜在特征 和 ,随后将对应潜在特征中的信息引入去噪过程中。
和 被用于生成 和,并在 和 中突出低姿势质量区域,指导模型减少这些区域的畸变生成。为了指导模型改进低质量区域,将通过如下公式来高亮低姿势得分区域:
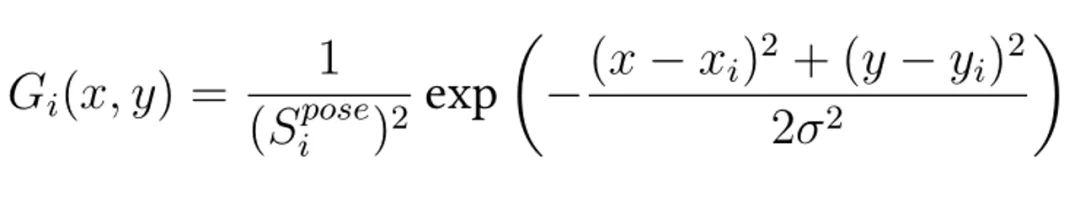
其中 ,x、y 是图像的逐像素坐标,H,W 是图像大小,σ 是高斯分布的方差。 表示以第 i 个关节为中心的注意力,通过结合所有关节的注意力,我们可以形成最终的注意力图,并使用阈值将 转换为一个掩码 。
其中 ϕt 是在时间步 t 生成掩码的阈值。类似地,对于交互指导,论文作者利用分割模型得到物体的外轮廓点 O 以及人体关节点 C,计算人与物体之间的距离矩阵 D,从中采样得到交互边界的关键点 ,利用和姿势指导相同的方法生成交互注意力 与掩码 ,并应用于计算最终的预测噪声。
迭代式反演和图像修正流程
为了实时获取生成图像的质量评估,论文作者引入质量评估器 Q,用于作为迭代式 < 评估 + 修正 > 操作的指导。对于第 k 轮的图像 ,采用评估器 Q 获取其质量分数 ,然后基于 生成。为了在优化后保留 的主要内容,需要相应的噪声作为去噪的初始值。
然而,这样的噪声不是现成可得的,为此引入图像反演方法来获取其噪声潜在特征 和文本嵌入,作为 PIG 的输入,生成优化后的结果。
通过比较前后迭代轮次中的质量分数,可以判断是否要继续进行优化:当和 之间没有显著差异,即低于阈值 θ,可以认为该流程可能已经对图像做出了充足的修正,因此结束优化并输出质量分数最高的图像。
人物交互图像生成基准
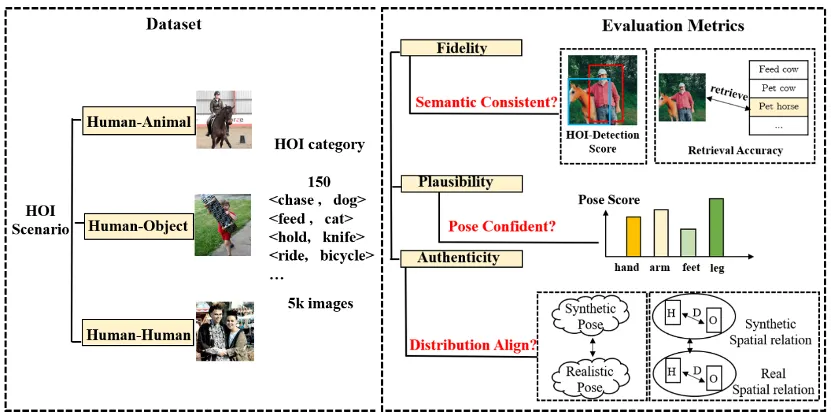
图 3:人物交互图像生成基准(数据集 + 测评指标)
考虑到没有针对人物交互图像生成任务设计的现有模型和基准,论文作者收集并整合了一个人物交互图像生成基准,包括一个含有 150 个人物交互类别的真实人物交互图像数据集,以及若干为人物交互图像生成定制的测评指标。
该数据集从开源人物交互检测数据集 HICO-DET [5] 中筛选得到 150 个人物交互类别,涵盖了人 - 物体、人 - 动物和人 - 人三种不同交互场景。共计收集了 5k 人物交互真实图像作为该论文的参考数据集,用于评估生成人物交互图像的质量。
为了更好地评估生成的人物交互图像质量,论文作者为人物交互生成量身定制了几个测评标准,从可靠性 (Authenticity)、可行性 (Plausibility) 和保真度 (Fidelity) 的角度全面评估生成图像。可靠性上,论文作者引入姿势分布距离和人 - 物体距离分布,评估生成结果和真实图像是否接近:生成结果在分布意义上越接近真实图像,就说明质量越好。可行性上,采用计算姿势置信度分数来衡量生成人体关节的可信度和合理性。保真度上,采用人物交互检测任务,以及图文检索任务评估生成图像与输入文本之间的语义一致性。
实验结果
与现有方法的对比实验结果如表 1 和表 2 所示,分别对比了人物交互图像生成指标和常规图像生成指标上的性能。
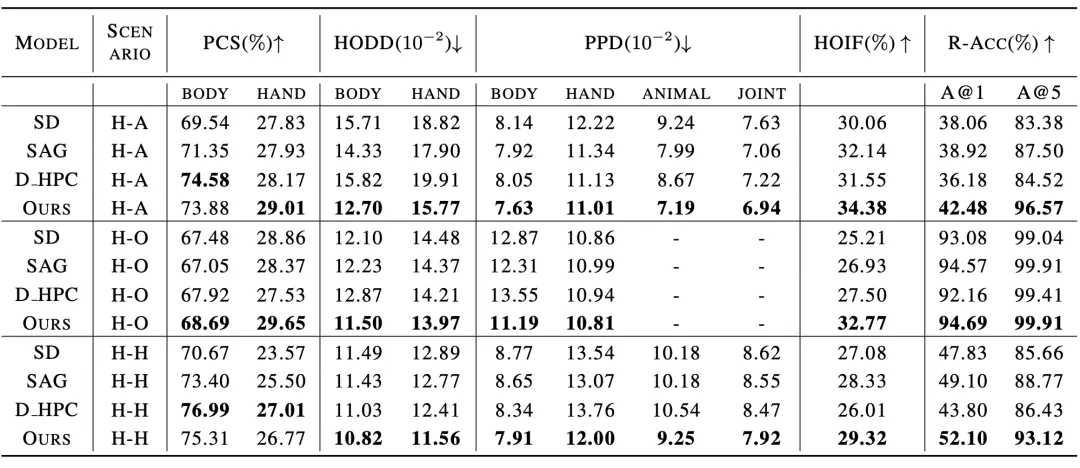
表 1:与现有方法在人物交互图像生成指标的对比实验结果
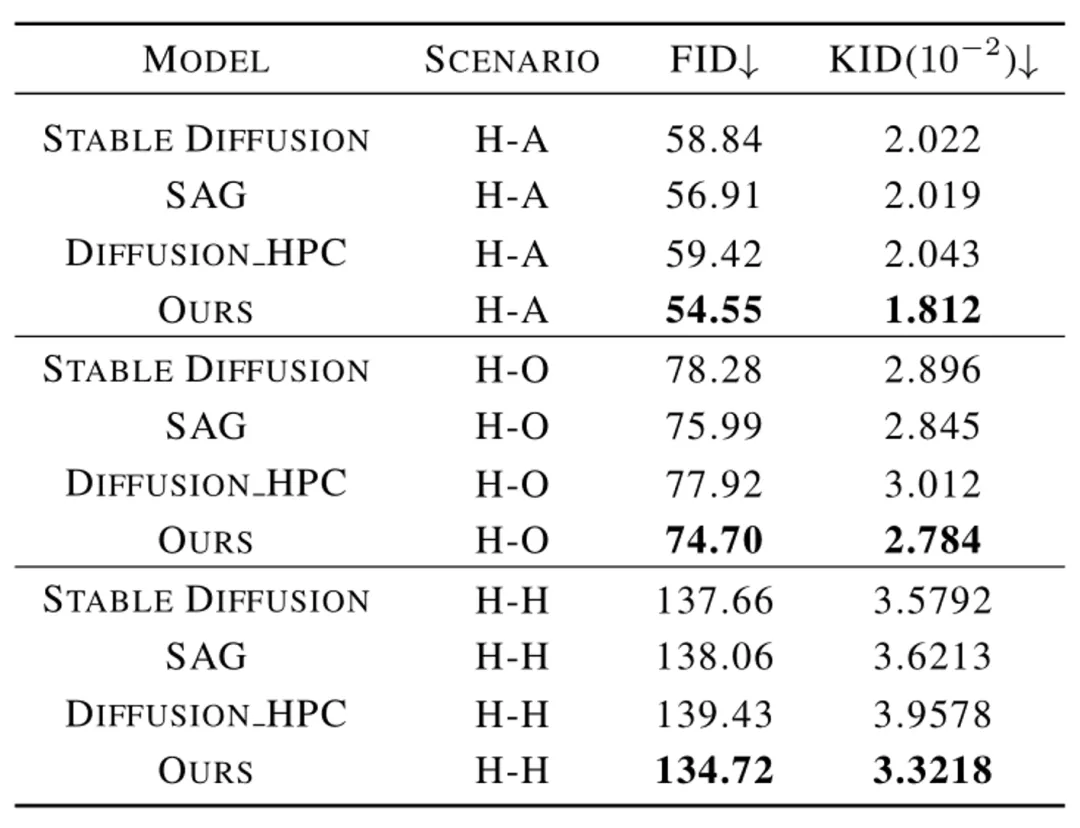
表 2:与现有方法在常规图像生成指标的对比实验结果
实验结果表明,该论文中的方法在人体生成质量,交互语义表达,人物交互距离,人体姿态分布,整体图像质量等多个维度的测评上都优于现有模型。
此外,论文作者还进行了主观评测,邀请众多用户从人体质量,物体外观,交互语义和整体质量等多个角度进行评分,实验结果证明 SA-HOI 的方法在各个角度都更符合人类审美。
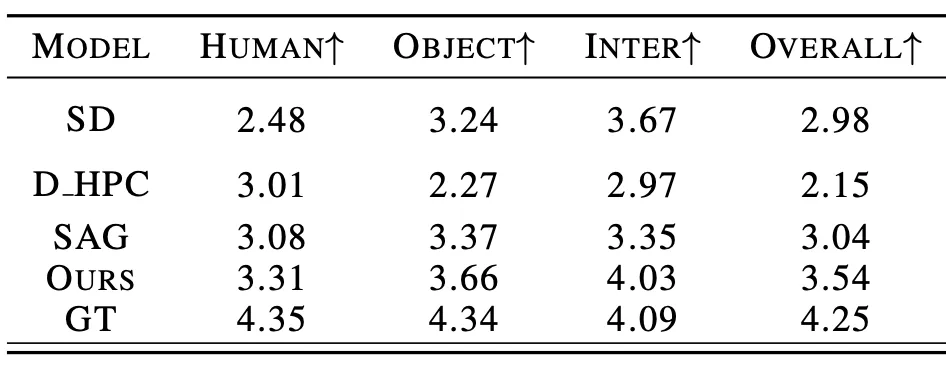
表 3:与现有方法的主观评测结果
定性实验上,下图展示了不同方法对同一个人物交互类别描述生成结果的对比。在上方的组图中,采用了新方法的模型准确表达了 “亲吻” 的语义,并且生成的人体姿势也更合理。在下方的组图中,论文中的方法也成功缓解了其他方法中存在的人体扭曲和畸变,并且通过在手与手提箱交互的区域生成手提箱的拉杆来增强 “拿手提箱” 这个交互的语义表达,从而得到在人体姿态和交互语义两方面都优于其他方法的结果。

图 4:人物交互图像生成结果可视化
更多研究细节,可参考原论文。
参考文献:
[1] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, June 2022
[2] HuggingFace, 2022. URL https://huggingface.co/CompVis/stable-diffusion-v1-4.
[3] Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., Zhang, Z., Cheng, D., Zhu, C., Cheng, T., Zhao, Q., Li, B., Lu, X., Zhu, R., Wu, Y., Dai, J., Wang, J., Shi, J., Ouyang, W., Loy, C. C., and Lin, D. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155, 2019.
[4] Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-
text inversion for editing real images using guided diffusion models. arXiv preprint
arXiv:2211.09794, 2022.
[5] Yu-Wei Chao, Zhan Wang, Yugeng He, Jiaxuan Wang, and Jia Deng. HICO: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, 2015.
文章来自于微信公众号机器之心 作者机器之心




