# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
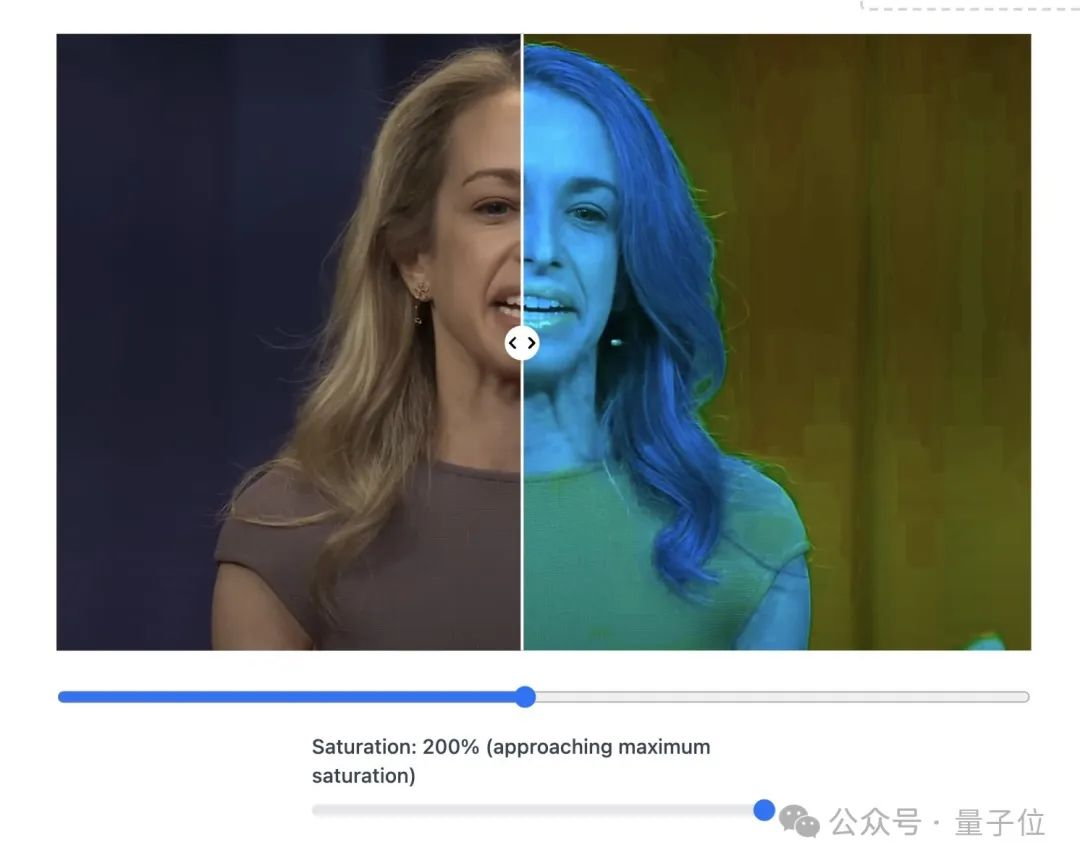
赛博照妖镜下,AI美女全变鬼。
来看它的牙。

把图像饱和度拉满,AI人像的牙齿就会变得非常诡异,边界模糊不清。
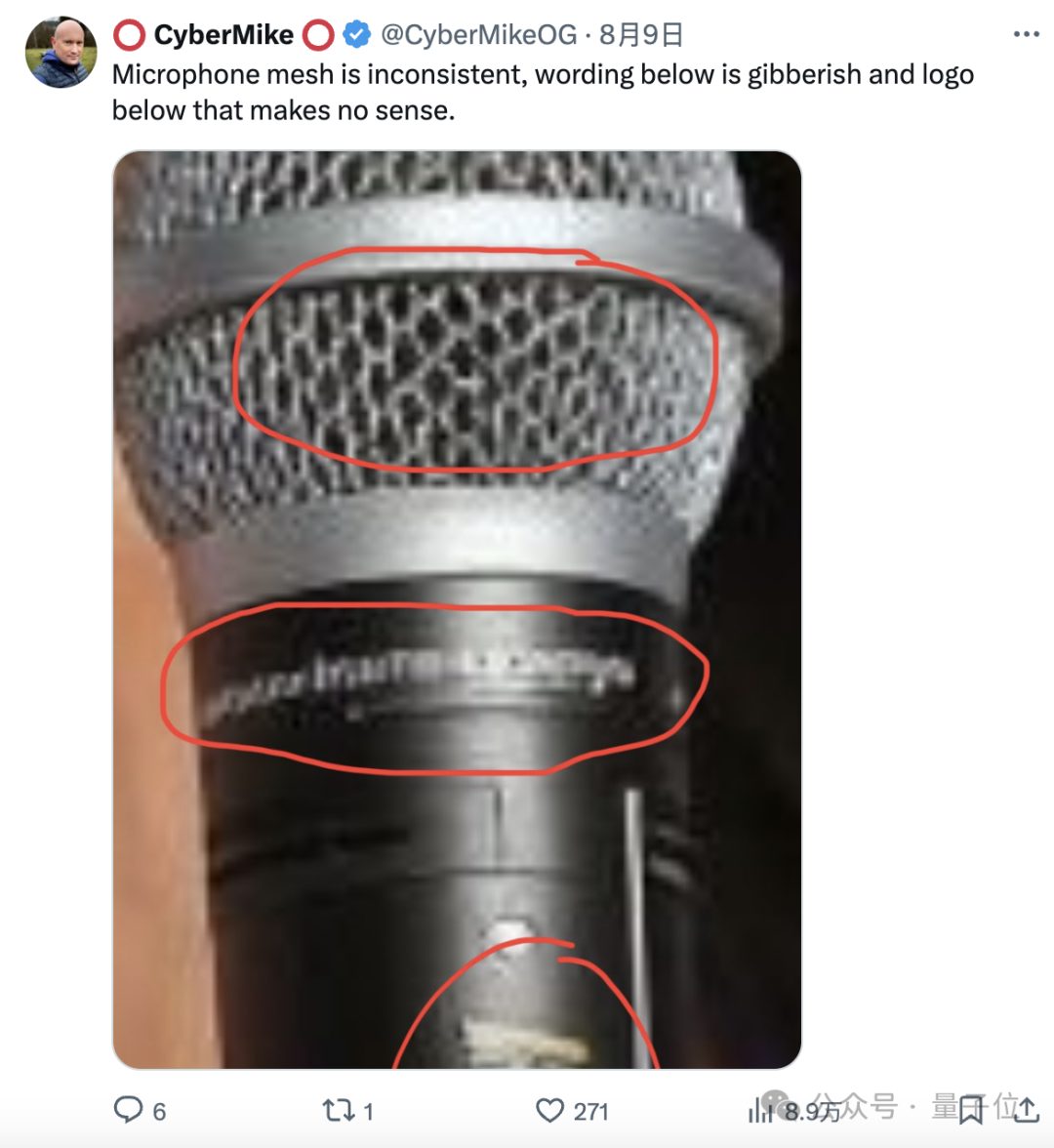
整体图片的颜色也正常,麦克风部分更是奇怪。
对比真实人类照片,则应该是这样的。
牙齿是清晰的,图片色块都是均匀一致的。
这个工具已经开放,人人都能拿着照片去试试。
AI生成视频中的某一帧,也难逃此大法。
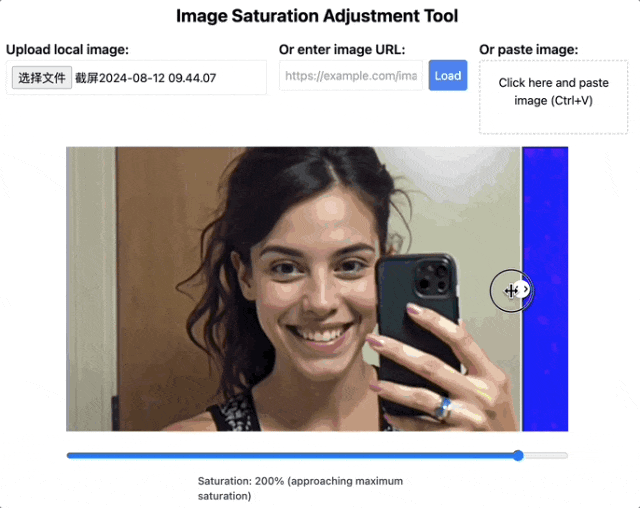
不漏牙的照片也会暴露问题。

不过BTW,这个工具出自Claude之手。用AI破解AI,奇妙的闭环。
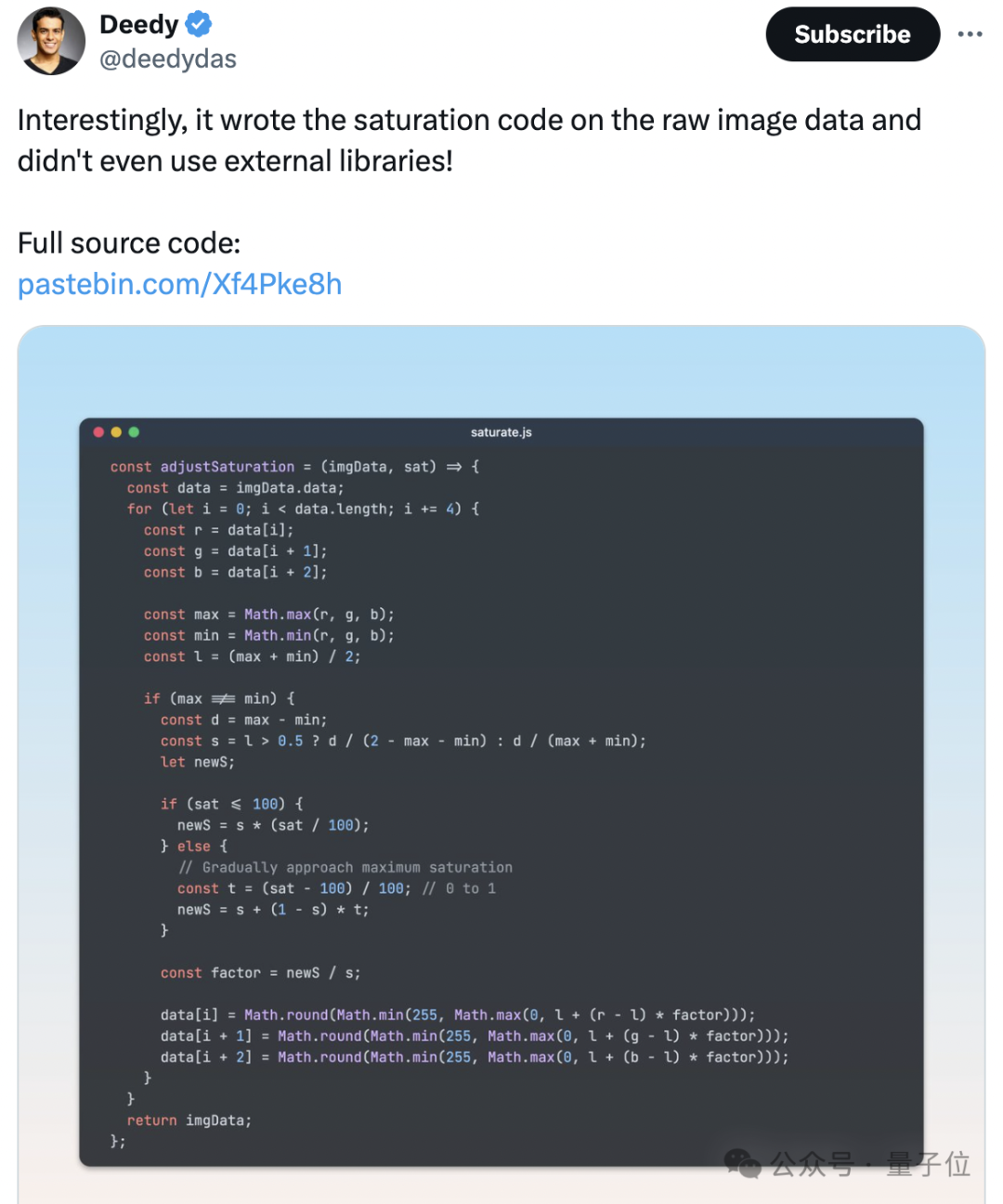
有一说一,最近AI人像太逼真又引发了不小讨论,比如一组大火的“TED演讲者视频”,其实没有一个是真人。

不只是人脸难以区分,就连之前AI的短板——写字,现在都能完全以假乱真。

更关键的是,生成这样的AI人像,成本也不高。低至5分钟、每20秒1.5美元(人民币10块左右)的价格即可搞定。
这下网友们都坐不住了,纷纷搞起AI打假大赛。
近5千人来讨论,这两张图到底哪张是真人。
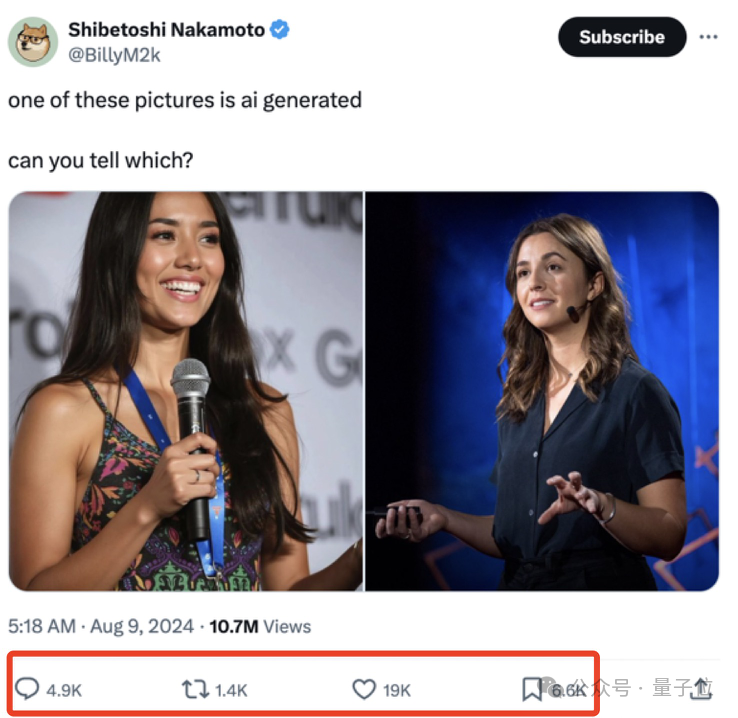
给出的理由五花八门。有人发现文字、花纹细节很抽象,有人则觉得人物眼神很空洞……
最先进的AI们生成人像有啥规律,逐渐被大家摸索出来了。
汇总来看,调整饱和度或许是目前最快速辨别的方法。
AI群像照在这种方法下暴露得更加彻底。

不过它存在一个问题。如果图像用JPEG算法压缩过后,该方法可能失效。
比如确定这张照片是真人照片。

但是由于画质压缩以及光线等问题,人物牙齿也有点模糊。

所以网友们还列出了更多分辨人像是否是AI合成的方法。
第一种方法,简单说就是依靠人类的知识判断。
由于AI学习图像的方式和人类并不一致,难免无法100%掌握人类视角下的视觉信息。
造成的结果就是,AI生成的图片常常包含与现实世界不符之处,这就为图像的鉴别提供了着手之处。
用开头的这张图片作为例子。
从整体上看,人物的皮肤过于光滑,看不到任何的毛孔,这种过于完美的特征反而增加了不真实感。
当然这种“不真实感”并不完全等同于“造假”,毕竟经过磨皮处理的图片同样看不到毛孔。
但这也并非唯一的判断因素,AI在图片中留下的与常识的出入也未必只有一处。

实际上,这张图只要稍微看以下细节,就能看到一个比较明显的特征——胸牌上方挂钩奇特的连接方式。

还有在高饱和度模式下露出破绽的麦克风,放大之后直接用肉眼也能看出端倪。
更为隐蔽的是,头发末端有几根毛发的位置很不合理,但这样的特征,恐怕要拥有列文虎克级别的视力才能看到了。
不过,随着生成技术的进步,能够找到的特征越来越隐蔽,也是一个无法避免的趋势。

还有一种方法是看文字,虽然AI在字型的刻画上正逐渐克服“鬼画符”的问题,但正确地渲染出有正确实际含义的文字还存在一些困难。
比如有网友发现,照片中的人佩戴的胸牌上,Google标志的下方最后一行字中的两个字母是“CA”,表示美国加州,前面的一大长串应该是城市名。
但实际上,加州根本没有名字如此之长的城市。

除了这些物体本身的细节,还有光线、阴影等信息也可以用来判断真伪。
这张图片是从一段视频当中提取的,在它所在的视频当中还有这样的一帧。
在话筒右侧的位置,有一片十分诡异的阴影,这片阴影对应的是人物的一只手,显然AI在这里处理得有所欠缺。

说到视频,由于涉及前后内容一致性,AI倒是比在静态图像中更容易露出鸡脚马脚。

还有一些特征不算“常识错误”,但也体现出了AI在生成图像时的一些偏好。
比如这四张图,都是AI合成的“普通人”(average people),有没有发现什么共同之处?

有网友表示,这四张图里的人,没有一个是笑脸,这点似乎就体现了AI生图的某种特征。
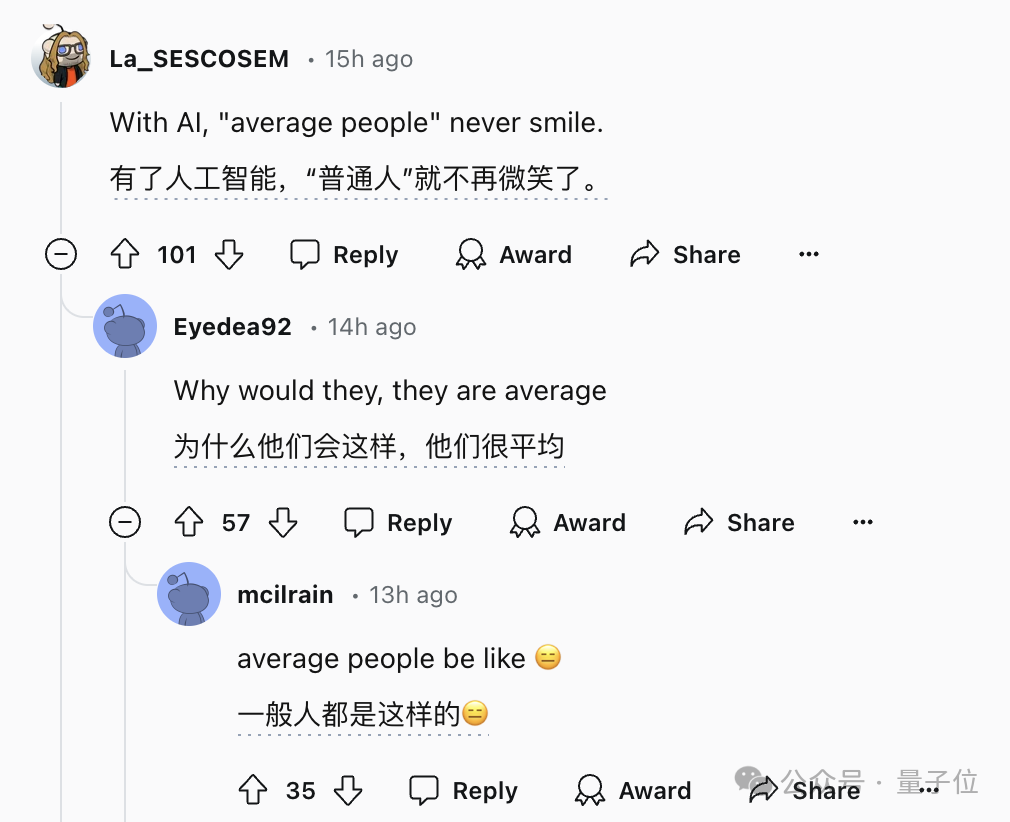
针对这几张图而言确实如此,但这样的判断方式很难形成系统,毕竟不同的AI绘图工具,特点也都不尽相同。
总之,为了应对逐渐进步的AI,一方面可以加大“列文虎克”的力度,一方面还可以引入像拉高饱和度这样的图像处理技术。
但如果这样的“量变”积累得越来越多,肉眼判断也会越来越困难,图像饱和度可能也有被AI攻破的一天。
所以人们也在转变思路,想到了“以模制模”的方法,用AI生成的图片训练检测模型,从图像中分析更多特征。
比如AI生成的图像在频谱、噪声分布等方面存在许多特点,这些特点依靠肉眼无法捕捉,但AI却能看得很清楚。
当然,也不排除检测方法落后、跟不上模型变化,甚至模型开发者专门进行对抗性开发的可能。
比如前文一直在讨论的这张图片,某AI检测工具认为它是AI合成的概率只有2%。
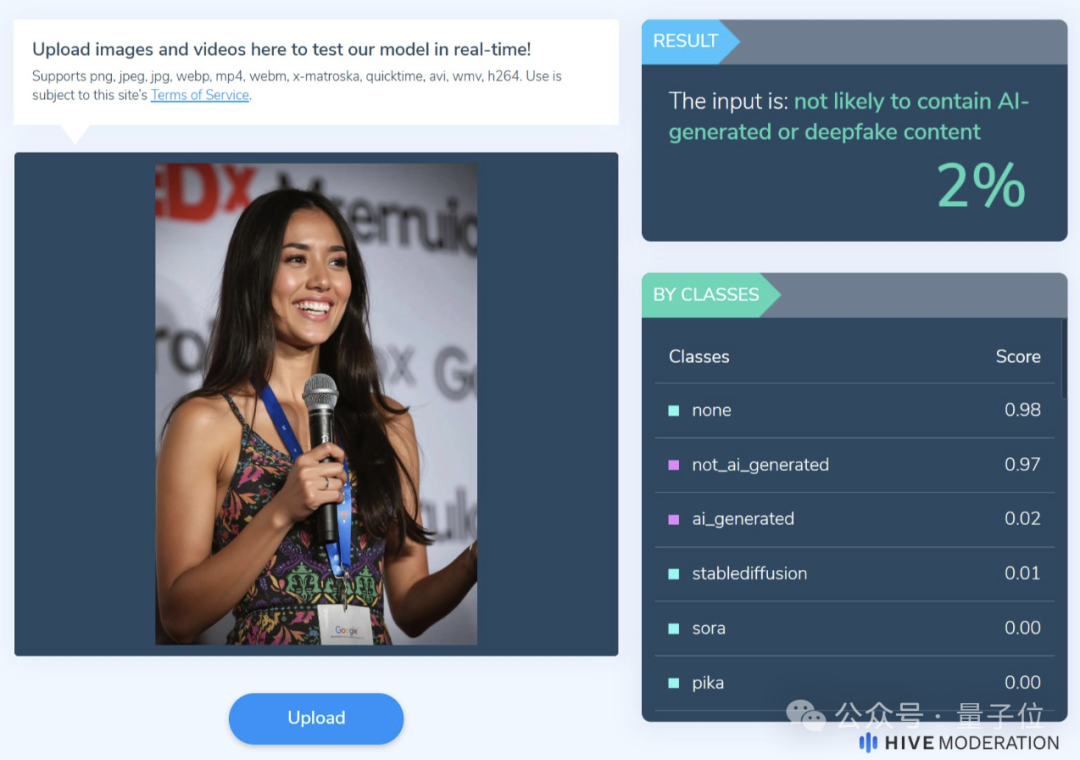
但AI造假和AI检测之间的博弈过程,本身就是一场“猫鼠游戏”。
所以在检测之外,可能还需要模型的开发者也负起一些责任,例如给AI生成的图片打上隐形水印,让AI造假无处遁形。
值得一提的是,如上引发恐慌的AI人像,不少都是由最近爆火的Flux生成/参与制作。
甚至大家已经开始默认,效果太好难以分辨的,就是Flux做的。
它由Stable Diffusion原班人马打造,发布才10天就在网络上掀起轩然大波。
这些精美的假TED演讲照片,都是出自它手。

还有人用Flux和Gen-3一起做出了精美的护肤品广告。

以及多角度的各种合成效果。

它很好解决了AI画手、AI生成图片中文字等问题。

这直接导致现在人类区分AI画图,不能再直接看手和文字了,只能盯着蛛丝马迹猜。

Flux应该是在手部、文字等指标上加强了训练。
这也意味着,如果当下的AI继续在纹理细节、色彩等方面下功夫训练,等到下一代AI画图模型出来时,人类的辨认方法可能又要失效了……
而且Flux还是开源、笔记本电脑上可运行的。不少人现在已经在Forget Midjourney了。
从Stable Diffusion到Flux,用了2年。
从“威尔史密斯吃面条”到“Tedx演讲者”,用了1年。
真不知道以后为了分辨AI生成,人类得想出哪些歪招了……
文章来源于“量子位”,作者“明敏 克雷西”




【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
