# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如今,推荐系统已成为我们日常生活中不可或缺的一部分。无论是观看视频、浏览社交媒体,还是网上购物,推荐算法都在默默地影响着我们的选择。然而,传统的推荐系统往往只关注用户的短期行为,忽视了长期用户满意度这一更为重要的目标。
近日,来自Google、Google DeepMind和加州大学戴维斯分校的研究团队提出了一种创新的方法 - 学习排序函数(Learned Ranking Function, LRF),似乎解决了一长期存在的问题,这也是今年10月要上会的论文。这项研究不仅在理论上有重大突破,更已在YouTube等大型平台上成功部署,展现了其在实际应用中的巨大潜力。

这个推荐系统算法实现起来并不复杂,先是把推荐问题转化成为马尔科夫决策过程中找出累积奖励最大化,再用级联点击模型和提升公式约束优化,最终平衡后部署。你也可以把这个过程Prompt化(Promptization这是我发明的新词,或许用Prompt Standardization更精准,评论区可以留下您的意见!这个词用于解决高难度复杂算法的LLM交互问题,实际上用代码实现WorkFlow可能更具有鲁棒性Robustness,改日我写篇文章专门谈一下Promptization这个问题),我根据算法写了个MDP-LRF的SYSTEM PROMPT,在GPT 4o上运行了一下,文章末尾详细解读算法时还有Claude 3.5 Sonnet的运行结果。
传统的大型视频推荐系统通常包括以下几个阶段:
1. 候选生成:从海量视频库中生成一个较小的候选列表。
2. 多任务模型评分:对所有候选项进行用户行为预测(如点击率、观看时长等)。
3. 排序:将多任务预测结果合并为单一排序分数。
4. 重排序:考虑多样性等其他目标,对排序结果进行进一步调整。
然而,这种方法存在一个关键问题:它主要关注用户的短期行为,而忽视了长期用户满意度这一更为重要的目标。
LRF的核心思想是将短期用户行为预测作为输入,输出一个直接优化长期用户满意度的推荐列表。与之前基于启发式函数优化超参数的方法不同,LRF将问题直接建模为一个列表优化问题,目标是最大化长期用户满意度。
马尔可夫决策过程(MDP)建模
研究团队首先将推荐问题形式化为一个马尔可夫决策过程:
- 状态空间S:包括用户状态空间和候选视频集。
- 动作空间A:所有可能的视频排序方式。
- 状态转移概率P:描述用户行为如何影响状态变化。
- 奖励函数r:定义了immediate reward向量。
- 折扣因子γ:平衡即时奖励和长期奖励。
目标是找到一个最优策略π,使得累积奖励最大化,同时满足次要目标的约束条件。(关于MDP我写过好几篇文章介绍,您可以继续往下看,有过往文章推荐)
级联点击模型与提升值公式
为了更准确地建模用户与推荐列表的交互,研究者采用了级联点击模型的变体。这个模型考虑了用户可能放弃列表的情况,更符合现实场景。
基于此,研究者提出了"提升值公式"lift formulation with cascade click model:
Q_π(s,σ) = R_π_abd(u) + Σ(i=1 to n) P^i_cascade(p_clk, p_abd,s, σ) · R_π_lift(u, V_σ(i))
其中:
- Q_π(s,σ)是采取动作σ在状态s下的预期累积奖励
- R_π_abd(u)是用户放弃列表时的预期奖励
- P^i_cascade是用户点击第i个位置的概率
- R_π_lift是点击某项相对于放弃的提升值
这个公式巧妙地将短期行为预测(如点击概率)与长期价值(提升值)结合起来,为优化长期用户满意度提供了理论基础。
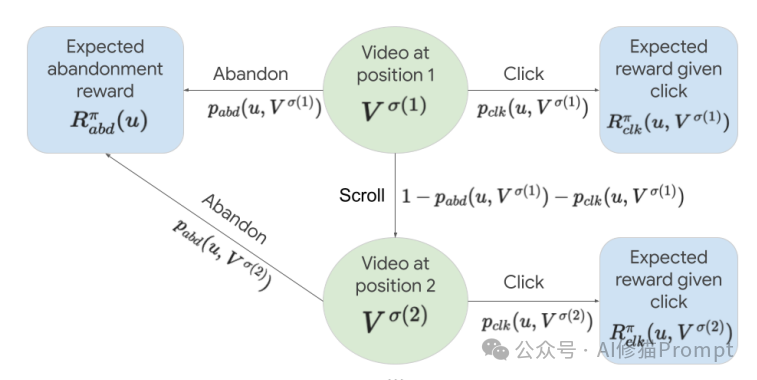
研究者用这张图展示了一个用户与推荐视频列表交互的级联点击模型。
1. 视频位置:
图中显示了视频在推荐列表中的不同位置(position 1, position 2等)。每个位置由一个绿色圆圈表示,里面是视频 V^σ(1), V^σ(2)等。
2. 用户行为:
对于每个视频,用户有三种可能的行为:
- 点击(Click):用户点击并观看视频
- 放弃(Abandon):用户在该位置放弃整个推荐列表
- 滚动(Scroll):用户跳过当前视频,继续浏览下一个
3. 转移概率:
- p_clk(u, V^σ(i)):用户u点击位置i的视频的概率
- p_abd(u, V^σ(i)):用户u在位置i放弃列表的概率
- 1 - p_abd(u, V^σ(i)) - p_clk(u,V^σ(i)):用户继续滚动到下一个视频的概率
4. 预期奖励:
- R^π_abd(u):用户放弃列表时的预期奖励
- R^π_clk(u, V^σ(i)):用户点击位置i的视频时的预期奖励
这个模型的关键在于它考虑了用户行为的顺序性和概率性。用户从第一个视频开始,依次决定是点击、放弃还是继续滚动。每个决策都影响后续的状态和可能获得的奖励。
在实际应用中,推荐系统通常需要平衡多个目标。为此,研究者开发了一种新颖的约束优化算法,基于动态线性标量化,以确保多目标优化的稳定性。
单目标优化
对于单一目标,LRF采用基于策略的蒙特卡洛方法,主要包括两个步骤:
1. 训练:构建函数近似Q(s,σ;θ)来估计Q_π(s,σ),通过分别建立R_π_abd、R_π_clk、p_clk和p_abd的函数近似实现。
2. 推理:根据arg max_σ Q(s,σ;θ)修改策略π(加入适当的探索)。
关于这些高级算法可以看之前的文章
往期推荐
N多高级推理的prompt算法,为什么REBASE树搜索能实现帕累托最优,精准控制LLM输出
斯坦福、剑桥大学重磅:LLM的无限猴子定理,用重复采样Prompt扩展推理能力,提高输出准确率
德黑兰、卡梅隆、哈佛等大学最新的C2P因果推理链Prompt,让LLM跨越因果推理鸿沟
一记惊雷:改一下Prompt的输出顺序,就能显著影响LLM的评估结果
谷歌重磅:LLM时代,我们用Prompt生成代码大纲,用文学编程
约束优化
为了处理多目标情况,研究者提出了一种基于相关性约束的优化方法:
1. 离线评估:使用探索候选项的数据集进行评估,计算各目标与加权组合提升值之间的相关性。
2. 相关性约束优化:通过求解一个优化问题来更新权重,最小化对主要目标的改变,同时满足次要目标的离线评估约束。
这种方法不仅能有效平衡多个目标,还能保持目标之间权衡的稳定性,这对系统的可靠性和开发效率至关重要。
在YouTube上的部署与评估
LRF系统首先在YouTube的观看页面上部署,随后扩展到主页和Shorts页面。以下是部署的关键点和评估结果:
轻量级模型与在线策略训练
为了支持多个LRF模型的在线策略评估,系统在总流量的一小部分(如1%)上进行模型训练。这使得研究者能够同时比较生产模型和多个实验模型的性能。
训练与服务
LRF系统使用过去几天的用户轨迹数据持续训练。主要奖励函数定义为用户对观看的满意度。特征包括多任务模型的用户行为预测、用户上下文特征(如人口统计)和视频特征(如视频主题)。
模型本身是一个小型深度神经网络,参数规模在10^4量级,保证了推理的高效性。在服务时,LRF模型接收上述特征作为输入,为所有候选项输出一个排序分数。
评估结果
研究团队在YouTube上进行了为期数周的A/B实验,评估LRF的有效性。主要评估指标是衡量长期累积用户满意度的指标。研究者用下面这张图展示了一系列实验的顶线指标(top-line metric)变化百分比。以下是一些关键实验结果:
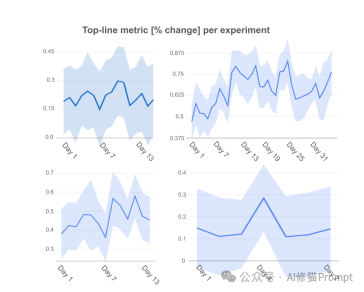
1. 初始部署:
简化版LRF(使用CTR预测和固定权重组合次要目标)相比之前的生产系统(使用贝叶斯优化调整的启发式排序函数)提升了0.21%(95%置信区间[0.04, 0.38])。
2. 级联点击模型:
引入级联点击模型后,主要指标进一步提升了0.66%(95%置信区间[0.60, 0.72])。
3. 约束优化:
引入约束优化显著提高了次要目标的稳定性。例如,对于相同的模型架构变更,次要目标的波动从13.15%降低到1.46%。
4. 提升值公式的必要性:
将R_abd设为0的实验导致主要指标下降0.46%(95%置信区间[0.43,0.49]),虽然观看页面推荐的贡献增加了0.2%(95%置信区间[0.14, 0.26])。这表明提升值公式对于优化整体用户满意度至关重要。
5. 双模型方法:
与分别预测R_abd和R_clk的双模型基线相比,LRF在主要指标上仍有0.12%的优势(95%置信区间[0.06, 0.18])上图蓝色区域。
这些数据强烈表明LRF(Learned Ranking Function)系统在各种实验中普遍带来了性能提升。虽然改进幅度看似较小(通常在0.1%到0.5%之间),但对于大规模推荐系统来说,这样的改进可能代表着显著的用户体验提升和商业价值。数据还显示,不同类型的实验或系统改进可能带来不同程度的效果,有些更稳定,有些则波动较大。这突显了持续实验和优化的重要性,以找到最有效的改进策略。
研究者没有给prompt模板也没有给代码,仅提供了下面的算法,这是一个约束优化算法,用于学习排序函数(LRF)的训练过程。我给大家解释一下:

1. 初始化:
- 创建一个FIFO(先进先出)数据缓冲区D
- 初始化神经网络 R_abd, R_lift, p_clk, p_abd,它们都由参数θ参数化
- 初始化一个m维的权重向量w = (1, 0, ...,0)
- 设置初始策略π
2. 主循环:
a. 应用当前策略π,收集K个用户轨迹数据并添加到缓冲区D
b. 使用Algorithm 1更新参数θ(这里指的是模型参数的更新)
c. 更新权重向量w(基于3.2.1和3.2.2节描述的方法,可能涉及多目标优化)
d. 更新策略π:
- 对于用户u和候选集V中的所有项目v,按以下公式排序:
[p_clk(u,v;θ) / (p_clk(u,v;θ) + p_abd(u,v;θ))] * ⟨R_lift(u,v;θ), w⟩
- 以概率ε将随机候选项提升到顶部(探索机制)
3. 重复上述过程
关键点解释:
1. 公式:
- p_clk/(p_clk + p_abd) 表示用户点击而非放弃的概率
- R_lift 表示点击相对于放弃的预期收益提升
- ⟨R_lift, w⟩ 是R_lift和权重向量w的内积,用于多目标优化
2. 在线学习:
算法通过不断收集新的用户轨迹数据来更新模型,实现在线学习
3. 使用:
通过概率ε随机提升候选项,算法在利用当前最佳策略和探索新可能性之间取得平衡
4. 多目标优化:
通过更新权重向量w,算法可以平衡多个可能相互冲突的目标
5. 约束满足:
虽然没有明确显示,但"Constraint Optimization"的标题暗示了算法在优化过程中考虑了某些约束条件。算法展示了LRF如何将短期行为预测(如点击概率)与长期价值估计(提升值)结合,同时考虑多目标优化和探索-利用平衡,以实现对长期用户满意度的优化。
根据这些算法,我写了一个基于MDP-LRF的SYSTEM PROMPT,并且模拟了一位高满意度美食小姐姐每天的视频观看日常,来进行分析预测:
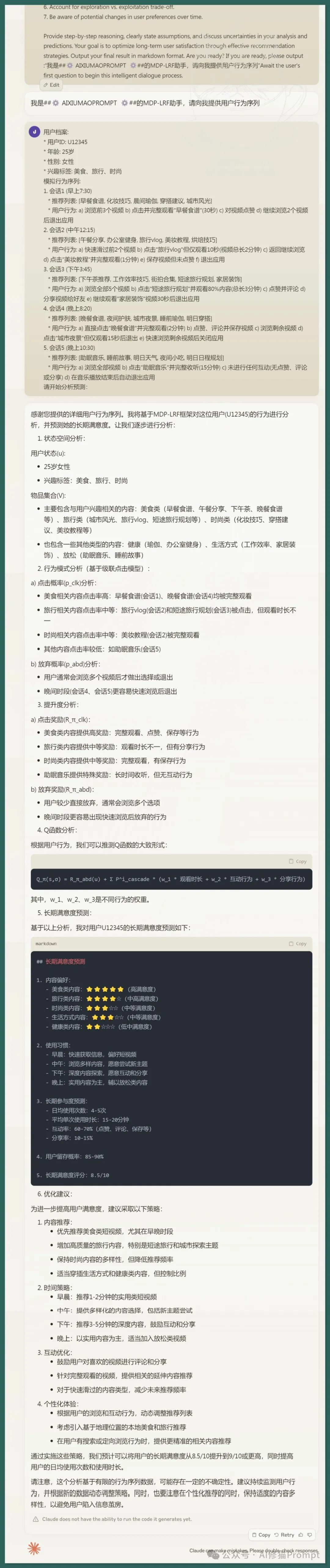
这是以视频平台立场跑出的预测结果,你也可以对这条SYETEM PROMPT改改,改成一个自己提升内容创作质量的选题决策工具,或者改成电子商务个性化推荐的算法,AI健康计划建议,学习路径推荐,游戏难度和付费意愿平衡,人力资源个性化培训,智能客服反馈,新闻等内容推荐等等。。。把它看作是LLM时代的AI推荐系统升级算法就对了,这篇论文仅6页,我已为您做了解读。希望深入了解,请进群来聊!
文章来源“AI修猫Prompt”,作者来源“AI修猫Prompt”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
