# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
史上最快对话视频AI来了,延迟不到一秒!
端到端,能听、能看、会说、有形象。
这个产品并不是出自OpenAI或HeyGen这样此前已经大展身手的公司,也没有一个具体的名字。
因为来自创业团队Tavus,因此也被称为Conversational Replicas by Tavus。
主要功能,就是搭建一个身临其境般的AI生成视频体验。
今日上线后,已经冲上Producthunt今日新品热榜第一,点赞数还在不断上升中。
Tavus官方为大家把产品特点总结了一把:
看得网友热血沸腾的:
好了,这下有“人”替我开ZOOM视频会议了哈哈哈哈!
也有不少网友把这视为比阅读文档or聊天更好的人机交互界面。
这个会话视频界面改变了游戏规则!
我已经可以想象沉浸式体验的无限可能性。
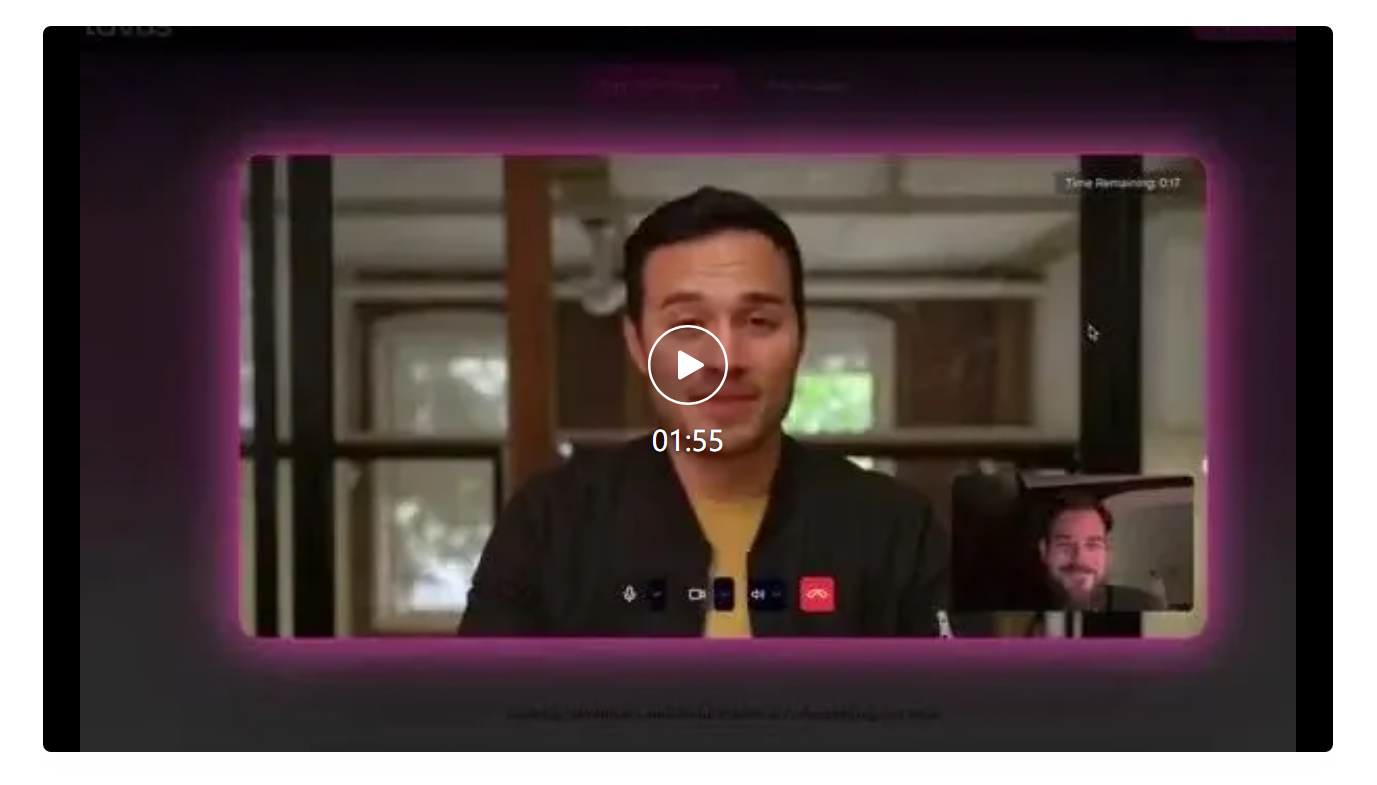
看到这则讯息,量子位一秒冲到了Tavus的官方网站。
在官网上,可以在线体验2分钟这个“史上最快对话视频”。
根据既有设定,体验时的对话对象是Tavus塑造的卡特。
卡特的形象定位是AI视频研究公司Tavus的一名员工,以幽默的方式回应,同时很乐于助人。
就是下面这个男人:
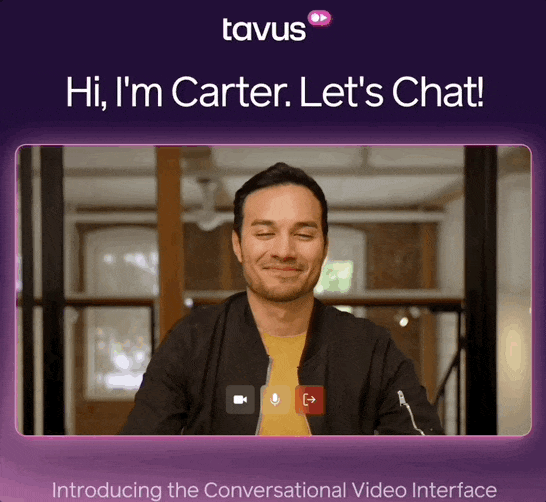
虽然卡特是个虚拟人形象,但和他视频,就像和自己朋友视频一样。
官方建议,授权摄像头和麦克风后,和卡特聊天的时候尽量呆在一个安静的房间里。
以下是网友的在线试玩录屏:
卡特在交谈中提到,人们最喜欢跟他讨论的几个话题,除了跟他打听Tavus运用的AI技术,就是分享自己的每日心路历程,以及讲笑话。
他当场就讲了个笑话:
问,为什么自行车不能靠自己就站在那儿?
答案是,因为它too tired(Two tires)。
讲完过后,卡特自己还自己给自己捧场,哈哈了两声。

量子位也实际体验了2分钟,总体感受如下:
首先,Tavus的响应速度确实非常快,符合官方号称的“一秒以内”。
哪怕是他在说话的过程中你突然出声,卡特也能立马停下来倾听你的最新发言。
其次,虽然官方号称它支持30多种语言,但不管是用中文还是英文发问,问来问去,他都无法开口说中文。
我们问他“Can u speak Chinese”时,卡特会回答:“我更愿意用英文对话呢!”
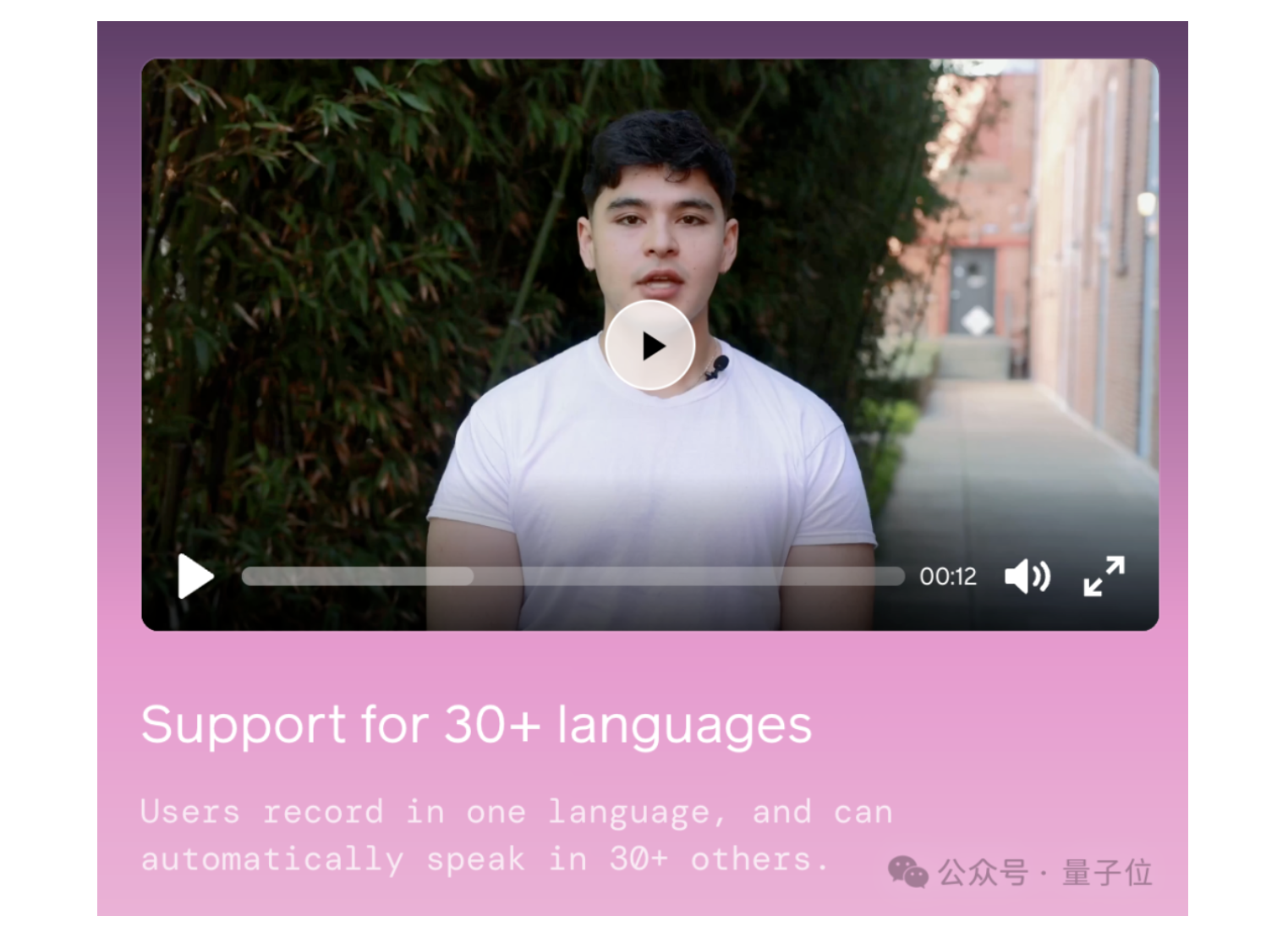
第三,Tavus的AI确实能“用眼睛看”。
量子位试玩儿过程中,一度尬住,不知问什么是好,只能傻笑。
卡特立马开口:
Oh!你对我露出了一个微笑呢~

第四,在试玩版本中,卡特的口型和所说的话几乎能做到完全同步。
这也就不难怪为什么有网友试玩后表示:
确实令人印象深刻,它拥有快速响应、出色的视频和音频生成能力。
现在,只要注册就可以使用Tavus的对话视频AI。
正式版本中,可供对话的AI形象就不只有卡特了,有男有女,身份设定从销售到生活指导等,应有尽有。
聊天所在的背景也能根据用户选择进行更换,不拘泥在办公室场景中。
同时,还能手动输入对话内容的上下文。
可以说个性化定制程度算很高了。
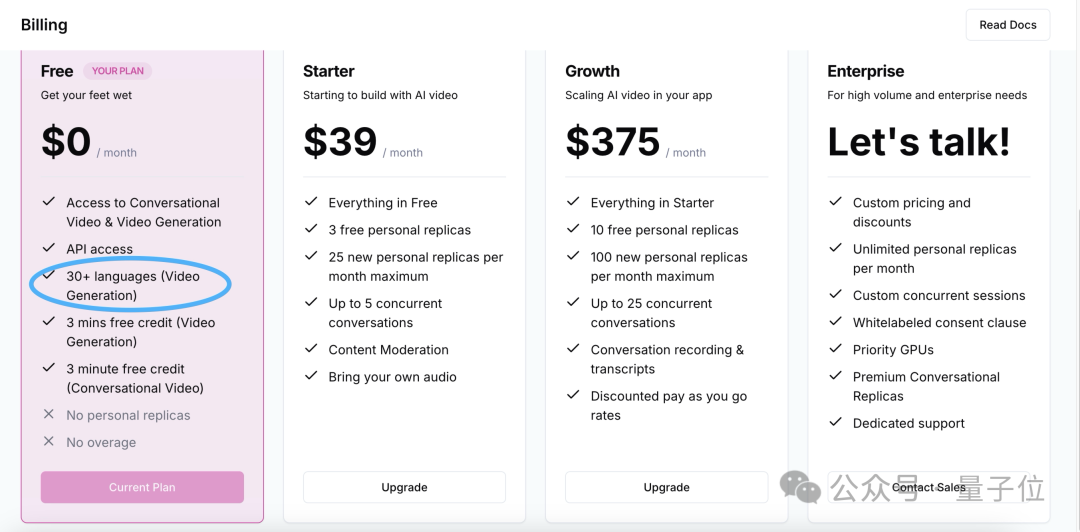
目前有免费版本,也有收费形式,对应不同的生成权益。
Tavus对话视频AI背后,是Tavus团队自研的Phoenix-2模型。
这是一个用音频和文本驱动的3D模型和2D GANs的组合,能生成1-2分钟的逼真短视频。
生成过程大致分为以下四个步骤:
TTS(文本转语音)——头部和肩部的3D重建——提示词脚本驱动的面部动画——高保真渲染。

为了让和用户对话的AI形象更逼真,Tavus团队在构建Phoenix-2的视频渲染pipeline的时候,结合了GAN和3D高斯泼溅。
这样做的原因,是传统的GAN通常受到图像分辨率的限制,而体积模型总在时间一致性的问题上有所欠缺。
因此,Tavus想到把两者结合起来。
训练GAN时,需要大量的数据集和昂贵的计算资源,且因为其二维性质和时间一致性问题,通常推理时间和视频质量都会受限。
Tavus把3D模型作为“中间体”,实现了超过100 FPS的渲染,并且由于动态物体周围的物理感知约束,实现更高程度的可控性和通用性。
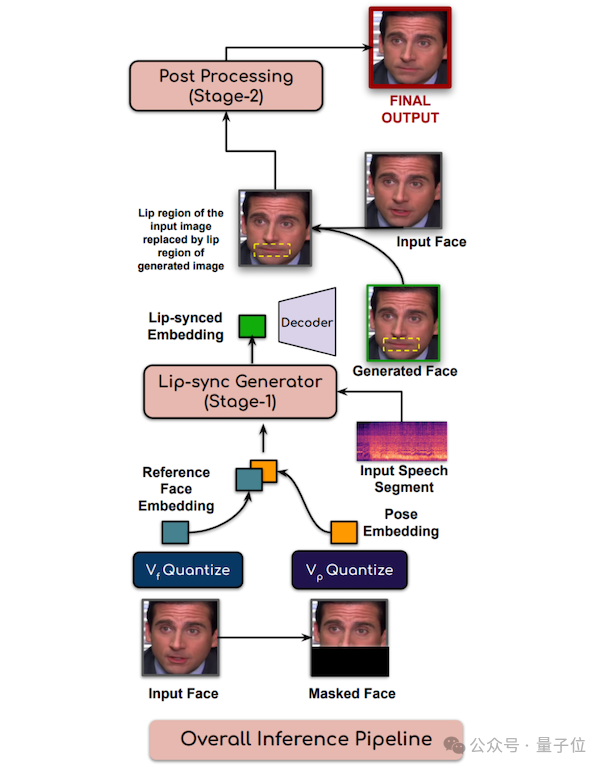
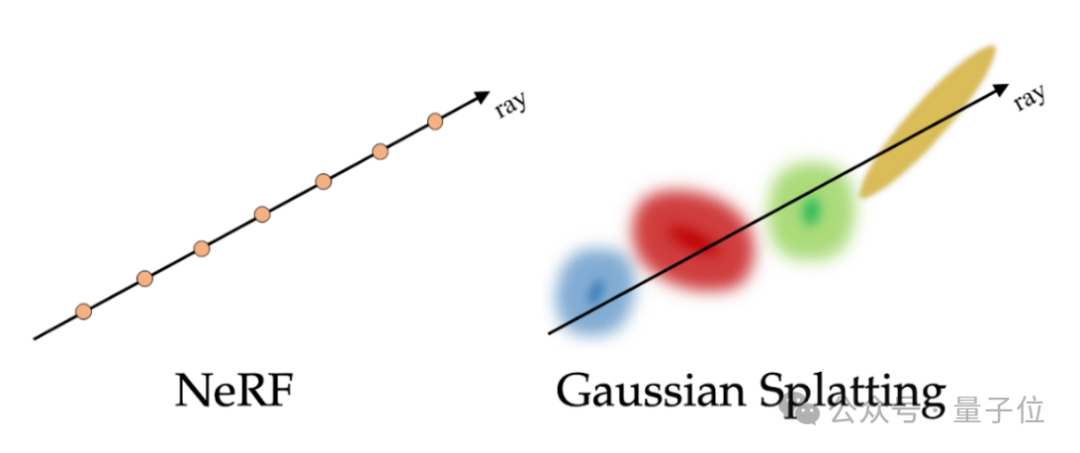
另外,Phoenix-2模型比起系列前作的改进之处,就是替换掉了初代Phoenix模型的NeRF。
转而利用3D高斯泼溅来学习引入如何驱动3D空间中的面部动态变形,并利用该信息根据看不见的音频来渲染视图。
团队成员表示,比起NeRF,3D高斯泼溅在数据、内存、计算复杂度、流程、渲染效率等方面都表现更好。
基于3D高斯泼溅的Phoenix-2模型的pipeline,能够以比初代模型快70%的速度进行训练,以60+FPS的速度进行渲染。
Tavus表示,对话过程中,有回合结束检测和可中断性,让用户感觉进行的对话更真实。
此外,由于面部信息非常敏感,团队提供安全检查、安全协议、自动内容审核和反幻觉检查来保护信息安全。

值得一提的是,Phoenix系列模型还支撑了Tavus的另一个产品——
生成用户数字孪生形象的对话视频。
只需要提供2分钟素材、花费1美元(起),就能调用API生成视频内容。
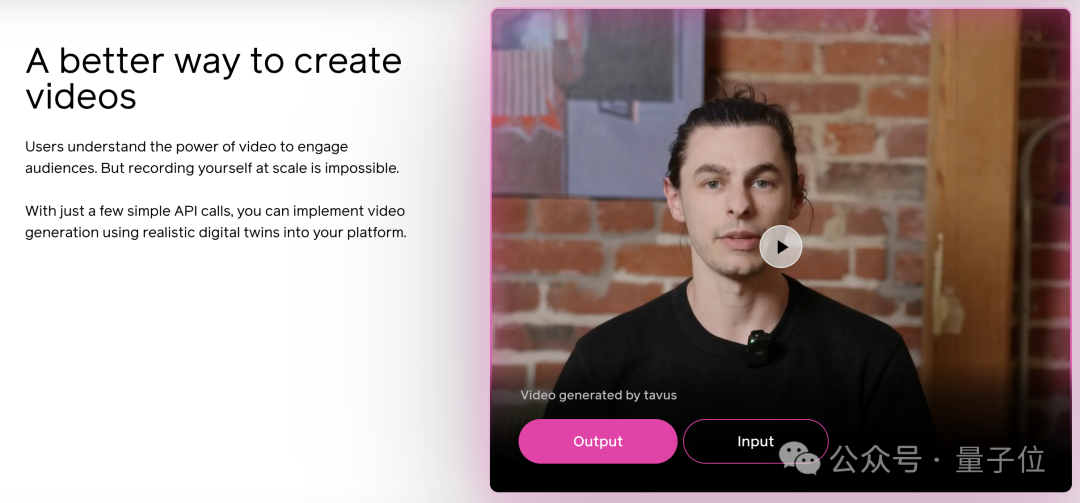
官方提示可提供端到端的解决方案,有以下能力:
Tavus团队是一家成立四年的AI视频初创公司,规模不大。
成员大多来自Amazon、Descript、Google和Apple等。
公开资料显示,截至今年3月,该公司已经获得了红杉、Scale VC、YC的A轮投资,融资额约1800万美元。
Tavus的联合创始人兼CEO,名叫Hassaan Raza。
曾在谷歌和苹果工作过。
而该公司的联合创始人兼COO在Producthunt留言表示,对话视频AI的制作花费了很长时间,研究、工程和建造大约花费了数千个小时。
至于为什么要追求1秒或者更短的延迟?
官方也给出了答案,是在尽可能模拟人类和人类的视频对话:
因为如果反应速度不低于1秒,那(对面跟你聊天的)就不是人了。
文章来源于“量子位”,作者“衡宇”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
