# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
虽然大语言模型(LLM)的能力不断突破,但在长文生成方面却一直存在瓶颈。近日,清华大学和智谱AI联合发布的最新研究成果,为解决这一难题提供了创新方案。这项名为"LongWriter"的技术,成功将AI模型的长文生成能力从约2000字提升至10000字以上,同时保持了高质量输出。这一成果通过创新的数据构建方法、模型训练策略和评估基准,为AI长文创作开辟了新天地。

01
研究团队首先对目前市面上主流的长上下文LLM进行了系统测试。他们设计了一个名为"LongWrite-Ruler"的评估方法,要求模型生成不同长度(从1,000到30,000字)的文章。测试结果令人意外:即便是最先进的模型,如GPT-4和Claude 3.5,也很难生成超过2,000字的连贯文本。研究团队通过两组实验深入探究了大语言模型在长文生成方面的局限性及其根源。
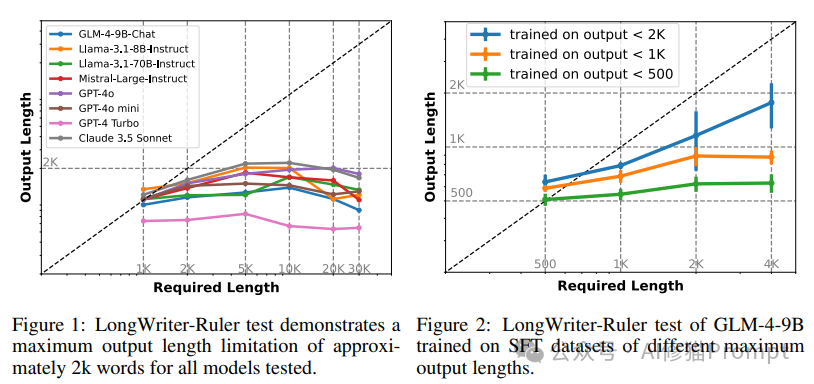
图1展示了当前主流大语言模型的长文生成能力测试结果。横轴表示要求生成的文本长度,纵轴表示模型实际输出的文本长度。理想情况下,模型应该能够精确匹配要求的长度,即所有点都应落在对角线上。然而,实验结果显示,无论是开源模型(如GLM-4-9B-Chat、Llama系列)还是商业模型(如GPT-4、Claude 3.5 Sonnet),在被要求生成超过2000字左右的文本时,都出现了明显的"天花板效应"。即使要求更长的输出,这些模型实际生成的文本长度也基本维持在2000字左右,无法突破这一限制。
图2揭示了这一限制的可能原因。研究者使用GLM-4-9B模型,通过控制其训练数据(SFT数据集)中的最大输出长度,观察模型的实际输出能力变化。结果表明,模型的最大输出长度与其训练数据中的最长样本密切相关。当训练数据限制在500字以内时,模型的输出也基本不超过500字;而当允许训练数据达到2000字时,模型的输出能力也随之提升到接近2000字。这一发现强烈暗示,当前大语言模型的输出长度限制很可能源于训练数据中缺乏足够长度的样本。
通过一系列控制实验,研究者发现了这一限制的根源:模型的最大输出长度与其训练数据集(SFT数据集)中的最长样本密切相关。换句话说,模型只能"说"它"读"过的那么长。这解释了为什么当前模型普遍存在2,000字左右的输出限制——因为现有的SFT数据集中很少有超过这个长度的样本。
这两项实验结果为研究团队确认了突破大语言模型长文生成限制的方向:通过构建包含更长文本的高质量训练数据集,有望显著提升模型的长文生成能力。
02
AgentWrite — 突破长文生成的方法
2.1 分而治之的智能代理
为了克服这一限制,研究团队开发了名为AgentWrite的智能代理系统。这个系统采用"分而治之"的策略,将长文写作任务分解为多个子任务。
AgentWrite的工作分为两个主要步骤:
1. 规划阶段:系统首先根据用户的写作指令,生成一个详细的写作计划,包括每个段落的主要内容和目标字数。

2. 写作阶段:系统按照计划,逐段生成内容。每生成一段,都会将之前生成的内容作为上下文提供给模型,以确保整体的连贯性。

2.2 AgentWrite的工作流程
为了突破大语言模型在长文生成方面的限制,研究团队开发了名为AgentWrite的创新系统。图3生动地展示了AgentWrite的工作原理,这是一个"先规划后写作"的流程。
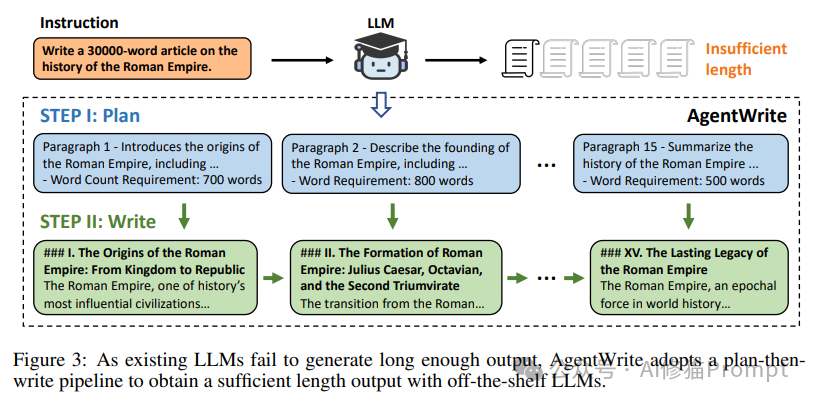
当面对"写一篇30000字的关于罗马帝国历史的文章"这样的长文指令时,传统的大语言模型往往难以生成足够长度的输出。AgentWrite通过将任务分解为两个主要步骤来解决这个问题:
1. 规划阶段(STEP I: Plan):
系统首先生成一个详细的写作大纲。这个大纲将长文任务分解为多个管理可控的段落,每个段落都有明确的主题和字数要求。例如:
- 第1段:介绍罗马帝国的起源,700字
- 第2段:描述罗马帝国的建立,800字
...
- 第15段:总结罗马帝国的历史,500字
2. 写作阶段(STEP II: Write):
基于规划阶段生成的大纲,系统逐段生成内容。每个段落都根据大纲中的主题和字数要求进行创作。例如:
- 第一段:《I. 罗马帝国的起源:从王国到共和国》,详细介绍罗马帝国的早期历史。
- 第二段:《II. 罗马帝国的形成:凯撒、屋大维和第二次三头同盟》,描述帝国建立的关键时期。
...
通过这种方法,AgentWrite能够利用现有的大语言模型生成结构完整、内容连贯的长文,有效克服了单个模型在长文生成方面的限制。这种"分而治之"的策略不仅确保了输出的充分长度,还保持了整体内容的连贯性和质量。
2.3 AgentWrite的效果验证
研究团队使用GPT-4o作为基础模型,通过AgentWrite成功将其最大输出长度从2,000字提升到了约20,000字。更重要的是,生成的长文在质量上也保持了高水准,特别是在"广度和深度"方面有显著提升。
我根据以上流程和方法写了一段LongWriter 的SYSTEM PROMPT用最近很热的一个命题做了实验,实际Claude 3.5 sonnet输出为13982字。
Agent目前是生成式AI行业的主流,请基于你的数据写一篇Agent行业的中文万字长文,主要比较Coze/Dify/Wordware/Glif之间的区别。

实证LongWriter方法可行有效!
03
LongWriter-6k—— 打造长文训练数据集
3.1 数据集构建过程
研究者利用AgentWrite构建了一个包含6,000条长文SFT数据的数据集,称为LongWriter-6k。这个数据集的构建过程如下:
1. 从现有数据集中筛选出3,000条中文和3,000条英文的长文写作指令。
2. 使用AgentWrite和GPT-4o为这些指令生成长文回应。
3. 对生成的数据进行后处理,包括过滤过短的输出和清理无关标识符。
3.2 数据集的特点
LongWriter-6k数据集的输出长度分布在2,000到10,000字之间,有效补充了现有SFT数据集在长文方面的不足。这为后续的模型训练奠定了基础。
04
LongWriter模型 —— 教会AI写长文
4.1 模型训练过程
研究团队基于两个开源模型进行了训练,目前LongWriter模型已在Huggingface上开源,也有热心者上传了GGUF量化版本,可部署在本地,直接使用:
- LongWriter-9B:基于GLM-4-9B
- LongWriter-8B:基于Meta-Llama-3.1-8B
训练过程的主要特点包括:
1. 数据混合:将LongWriter-6k与18万条通用SFT数据结合。
2. 损失计算策略:采用按token平均损失,而非按序列平均,以避免长文样本在训练中被忽视。
3. 硬件和配置:使用8块H800 80G GPU,采用DeepSpeed+ZeRO3+CPU offloading技术。
4. 训练参数:batch size为8,学习率为1e-5,packing length为32k,训练4个epoch。
4.2 DPO微调 —— 进一步提升模型能力
为了进一步提升模型的输出质量和长度控制能力,研究者对LongWriter-9B模型进行了直接偏好优化(DPO)。DPO数据包括:
1. 5万条通用DPO数据
2. 4千条对专门针对长文写作的数据,这些数据是通过对LongWriter-9B的多个输出进行评分和筛选得到的。
3. - 效果:产生LongWriter-9B-DPO模型,综合性能最优
05
LongBench-Write—— 评估长文生成能力
5.1 评估基准的设计
为了全面评估模型的长文生成能力,研究团队开发了LongBench-Write基准测试。这个基准包含120个多样化的用户写作指令,涵盖不同的长度要求和写作类型。
5.2 评估指标
LongBench-Write采用两个主要指标:
1. 输出长度得分(S_l):评估模型输出长度与指令要求的匹配程度。
2. 输出质量得分(S_q):使用GPT-4o作为评判,从相关性、准确性、连贯性、清晰度、广度深度和阅读体验六个维度评估输出质量。
5.3 评估结果
LongBench-Write评估结果清晰地展示了LongWriter模型在长文生成任务上的卓越表现。表格中的数据比较了多个专有模型、开源模型以及LongWriter系列模型在不同长度范围内的表现。评估指标包括整体得分(S)、输出长度得分(S_l)和输出质量得分(S_q)。
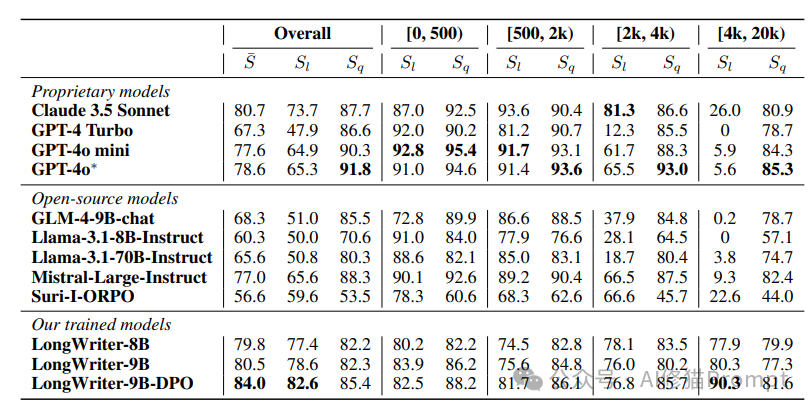
1. 整体表现:
LongWriter-9B-DPO模型在整体评分上达到了84.0分,超越了所有对比模型,包括知名的GPT-4o(78.6分)和Claude 3.5 Sonnet(80.7分)。
2. 长文生成能力:
在4000-20000字的超长文本生成任务中,LongWriter-9B-DPO的输出长度得分(S_l)高达90.3,远超其他模型。相比之下,大多数现有模型在此长度范围内的得分接近于0,表明它们无法有效地生成如此长的文本。
3. 质量保持:
即使在生成超长文本时,LongWriter模型也保持了较高的输出质量。在4000-20000字范围内,LongWriter-9B-DPO的质量得分(S_q)为81.6,与其在较短文本上的表现相当。
4. 全面优势:
LongWriter系列模型在各个长度范围内都表现出色,特别是在2000字以上的任务中,显著优于其他模型。这证明了研究者的方法在提升模型长文生成能力的同时,也保持了短文生成的质量。
5. 开源模型的突破:
作为开源模型,LongWriter系列的表现超越了许多知名的专有模型,这对于推动开放AI研究具有重要意义。
这些结果充分证明了LongWriter技术的有效性。通过创新的训练方法和数据构建策略,研究者成功地将模型的长文生成能力从传统的2000字左右提升到了10000字以上,同时保持了高质量输出。这一突破为AI辅助写作、内容生成等领域开辟了新的可能性,有望在学术研究、商业报告、创意写作等多个方面产生深远影响。
06
技术创新点与潜在影响
6.1 关键技术突破
1. AgentWrite智能代理:通过任务分解和连续生成,有效突破了AI长文生成的限制。
2. LongWriter-6k数据集:为长文生成模型提供了高质量的训练数据,填补了现有数据集的空白。
3. 创新的训练策略:通过调整损失计算方式,解决了长文样本在训练中被忽视的问题。
4. DPO微调:进一步提升了模型的长文生成质量和长度控制能力。
6.2 潜在应用场景
1. 内容创作:助力写作者快速生成高质量的长篇文章、报告或书籍。
2. 教育培训:生成详细的教学材料、课程大纲或学习指南。
3. 商业报告:自动生成全面的市场分析报告、财务报告等。
4. 科研辅助:协助研究人员生成文献综述或研究提案。
在生成式AI行业的文生文领域中,长文的生成是一个难点、痛点。这个问题解决之后,中文Agent发展必将再下一城。
6.3 对AI行业的潜在影响
1. 重定义AI写作能力:LongWriter技术可能彻底改变人们对AI写作能力的认知,使AI在长文创作领域更具竞争力。
2. 推动数据集建设:研究成果强调了高质量长文数据集的重要性,可能引发业界对相关数据集的重视和投入。
3. 促进AI应用创新:长文生成能力的突破可能催生新的AI应用场景,如自动撰写书籍、生成详细的技术文档等。
清华大学和智谱AI的这项研究不仅解决了AI长文生成的技术难题,更为AI在复杂写作任务中的应用开辟了新的可能性。LongWriter技术的出现,标志着AI写作能力进入了一个新的阶段。它不仅能够产生更长的文本,更重要的是能保持高质量和连贯性。未来,我们可能会看到更多令人惊叹的突破,让AI真正成为人类在复杂写作任务中的得力助手。
关于本地部署,LongWriter 的SYSTEM PROMPT之类的问题,欢迎你来群里和我讨论。
文章来源“AI修猫Prompt”,作者“AI修猫Prompt”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
