# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本期我们邀请到了 纽约大学计算机科学院博士 童晟邦 带来【多模态大模型:视觉为中心的探索】的主题分享。
上期我们有幸邀请到了陈贝迪教授带来【长序列文本生成】的主题分享,以下为分享的主要内容。
欢迎大家阅读、讨论、学习。
嘉宾信息
陈贝迪 Betty Chen

分享主题:算法、系统以及硬件协同设计(co-design)的一些性质,以提升长序列生成的效率(for efficient long sequence generation)。
今天为大家带来一种与过往不同的思路:
在提升效率时,可能不一定要依靠减少计算量或者是减少一些架构上的计算。针对那些计算在 CPU 上比较差,但是在 GPU 上比较好的情况,可以通过一些硬件的 co-design,利用存储更便宜的特性,通过一些 collaboration 能够达到类似或者更好的一些效果。

长上下文语言模型(Long-context LLMs)在过去几年取得显著进展,从2000到4000字的上下文长度提升到128K甚至256K。如今,Gemini模型处理百万级上下文,而Llama 3.1巩固了128K上下文长度的标准。
然而,这些进步带来了新的挑战。应用于个性化助手、程序自动化和AI Agents的模型要求更强的记忆能力,而这一能力尚未充分发挥。长上下文模型在Transformer架构中面临内存输入输出(Memory I/O)问题。
尽管GPU在Transformer架构训练中表现出色,内存带宽(Memory Bandwidth)优化却异常困难。以芯片设计为例,芯片边长扩大一倍,FLOPS增加四倍,但带宽仅增加两倍,使内存I/O成为瓶颈。在Transformer的自回归(Auto Regressive)架构中,这一问题尤为突出。
随着语言模型规模扩大,模型参数量急剧增加,如8B、70B、405B模型分别占用16B、140B、405B内存,几乎耗尽GPU内存空间。405B模型若不使用FP8格式,通常需八块GPU才能加载。
KV cache是关键问题,其占用量大且无法按模型参数比例扩展。例如,加载70B参数量的模型需占用140GB内存,但KV cache的大小随用户输入长度和并发用户数量增加而变化。
以GQA模型为例,128K Llama 3.1即使在4个Batch Size下也可能占用模型内存的一半甚至几倍。KV cache占用量持续增长,导致并行度下降。若希望服务1000个用户,KV cache的大小与查询数量呈线性关系,难以实现高度并行化,导致成本难以降低。

由于Auto Regressive特性,无论是模型参数还是KV cache,每次生成新内容时都需重新加载一次,这使推理过程异常缓慢且成本高昂。
这种瓶颈显著影响了模型的性能和成本效益,特别是在长上下文大模型的推理过程中。因此,设计更高效的算法来解决这一问题显得尤为关键。
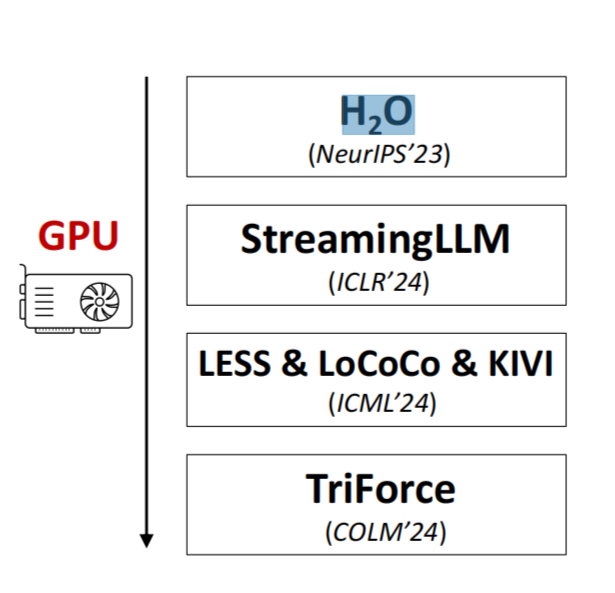

从去年 H2O 开始到 streaming LLM,然后今年的 LESS、LoCoCo、KIVI ,再是即将在 ICML 和 COLM 上发布的 TriForce。
我们研究怎么从一个很简单的 KV compression 的算法到最后变成了一个确实能实现无损加速的方法
这些方案都是在 GPU 上实现的。
优化长上下文大模型推理的传统做法通常涉及对内存的压缩或舍弃,然而,我们发现这些KV cache对于当前的Transformer架构来说至关重要。随意丢弃任何一部分都会导致模型在某些特定情况下无法正常工作。既然已经投入了大量资源去训练强大的模型,就不应该在推理阶段为了节省成本而牺牲其能力。
因此,我们提出了一个全新的思路。
虽然GPU难以容纳所有KV缓存,但存储相对廉价。通过软硬件协同设计(Co-design),可以将GPU存储容量扩展至100GB甚至更高,实现更高效处理。这种方法突破了传统的内存限制,不仅仅压缩数据,而是通过协同设计超越GPU的处理能力。
通过算法和系统设计,在特定场景下显著提升了性能。例如,结合自动化内存管理的CPU,V100在处理长上下文时,其吞吐量和延迟略优于A100。这证明了算法改进与系统协同设计的潜力。
在Llama 2的应用中,虽然32K上下文长度与Llama 3 GQA任务的128K上下文长度瓶颈相当,我们的设计使V100性能达到了A100 40GB的水平,展示了通过算法和系统协同设计突破性能瓶颈的可能性。
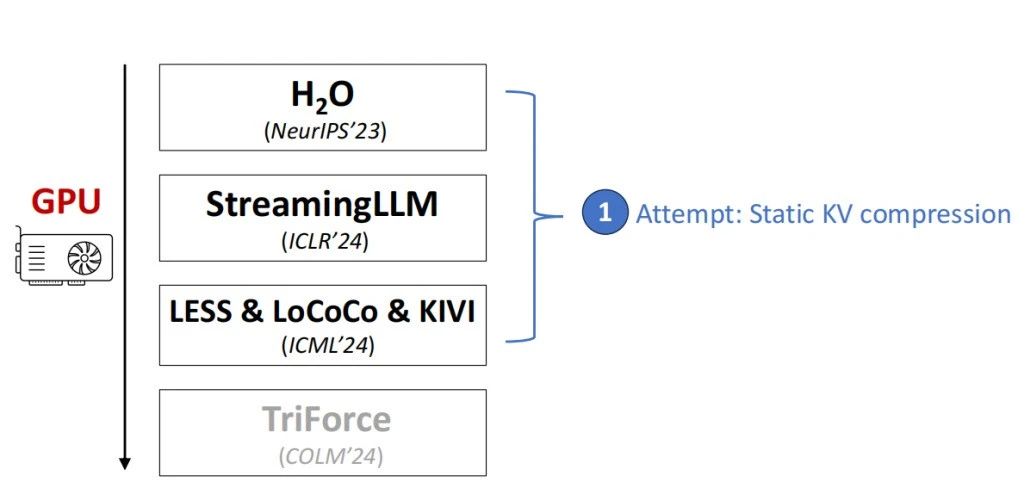
在发现KV cache成为推理过程中的一个瓶颈之后,我们开始找一种更精准的方法来进行静态的KV压缩(Static KV Compression)。具体在处理长上下文时,能否在问题提出之前预先识别出哪些上下文内容是后续生成过程中仍然需要保留和使用的。
这种方法能够在不影响模型性能的前提下,减少不必要的内存占用,从而提高推理效率。这是优化推理过程中的关键一步,有助于更好地管理和利用KV cache资源。
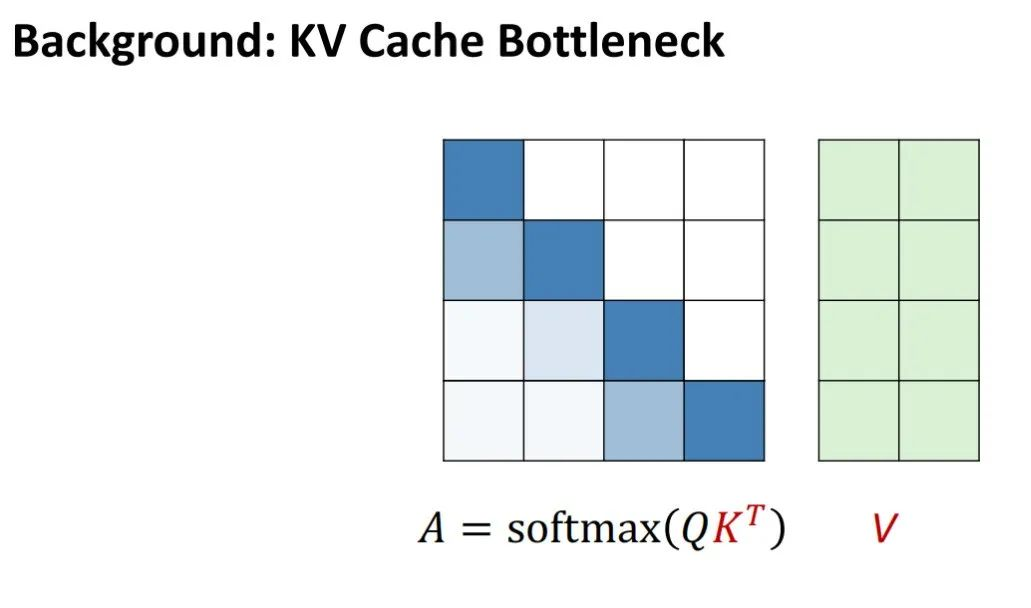
在讨论KV cache的瓶颈时,首先需要了解其来源——主要源自自回归机制。
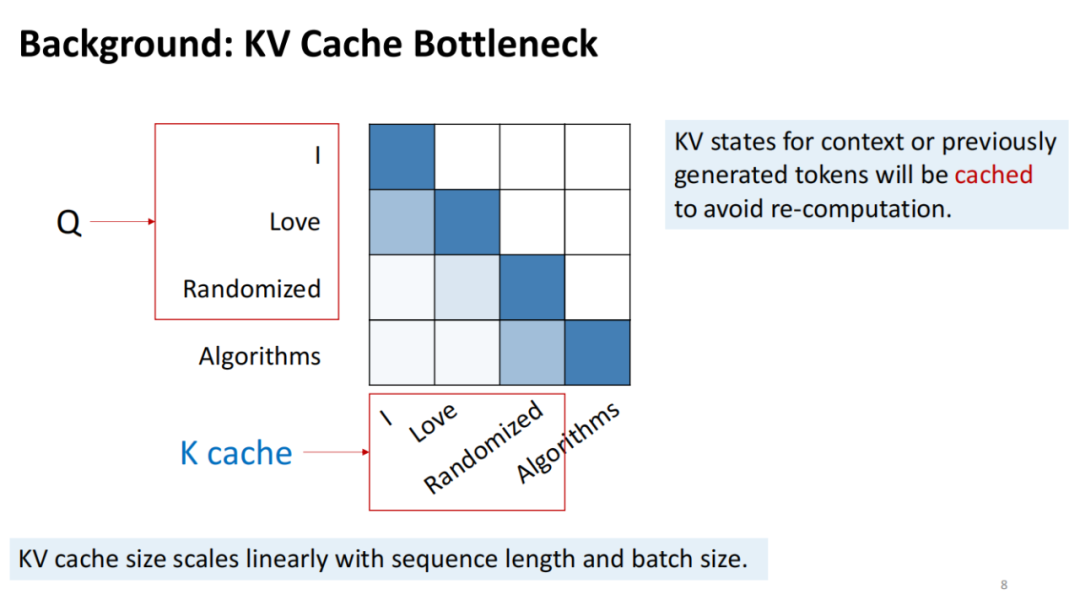
在计算注意力矩阵(Attention Matrix)时,模型需要使用到大量经过键投影(Key Projection)后的一些向量,将这些向量统称为K cache。由于自回归的特性,需要将这些K值记录下来,以便在未来的生成过程中使用。
例如,在生成“ I love randomized”这样的文本时,这些K值不会在生成的过程中发生改变。相比于每次都重新计算整个大型矩阵,可以将这些K值缓存下来,然后仅对注意力矩阵中的某一行进行计算。
这一缓存机制的原理是为了避免重复计算,从而提升推理效率。

1. 早期静态压缩尝试
早在2019年,Sparse Transformer的提出就引起了广泛关注,特别是在GPT-3时代的研究中,论文指出他们在图像生成和文本生成中采用了这一算法。这种方法使用了一种静态压缩技术,考虑到了KV cache的问题。
然而,现如今的大部分模型并非采用静态线性注意力进行训练,因此如果在推理时直接改变这一机制,可能会导致精度的丧失。
2. 动态压缩与注意力机制
其次,还有许多与注意力机制相关的问题需要解决。例如,FlashAttention、Reformer等方法最初是为了在训练过程中减少二次注意力计算的开销。
然而,随着FlashAttention的出现,这一方法几乎超越了此前所有的工作,包括我们自己在内的一些线性注意力机制的研究。这是因为人们逐渐发现,内存并不是长上下文建模中的最大瓶颈。事实上,长上下文建模的难点可能并不完全在于效率,或者说,它在某些应用中并没有显著提高效果。
这个问题可能会成为未来研究的重点:尽管在训练中效率问题并不那么显著,但如何在动态场景下有效地压缩KV cache仍然是一个难题,因为这些方法无法丢弃前面所有token的KV。
3. 高成本的压缩方法与预处理策略
还有一些非常昂贵的压缩方法可以考虑。例如,在处理长上下文时,假设需要针对同一个上下文提出多个问题,那么可以采用一次性预处理的策略。这样,在面对多个问题时,可以共享同一个上下文,从而减少重复计算的开销。
我们的目标是拥有一个小而精确的缓存,同时保持较高精度,并确保驱逐策略不至于过于昂贵。
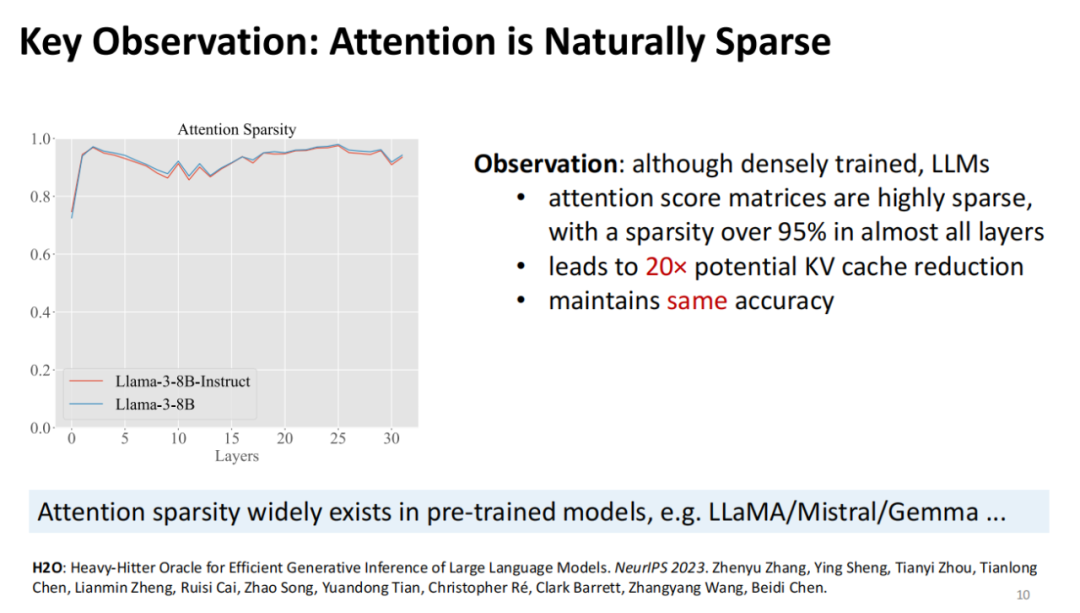
我们在第一个重要研究工作H2O中基于一个关键观察,这一观察也是后续所有研究的基础。该观察指出,注意力机制本质上是稀疏的,这与人类的注意力特性非常相似。这个发现可以从以下两个角度解释:
在语义层面,注意力的稀疏性是自然的。每次在不同的Head或生成内容时,不太可能广泛地关注大量信息。这种情况从直觉上看是反常的,注意力通常会集中在少数几个关键点上。
从数学角度来看,稀疏性可以通过Softmax函数解释。Softmax函数的值总和为1,如果注意力过于分散,会导致熵(Entropy)过高,从而使得最终的激活值变得非常小。这一现象无论从直觉上还是数学上都合理解释了注意力机制的天然稀疏性。

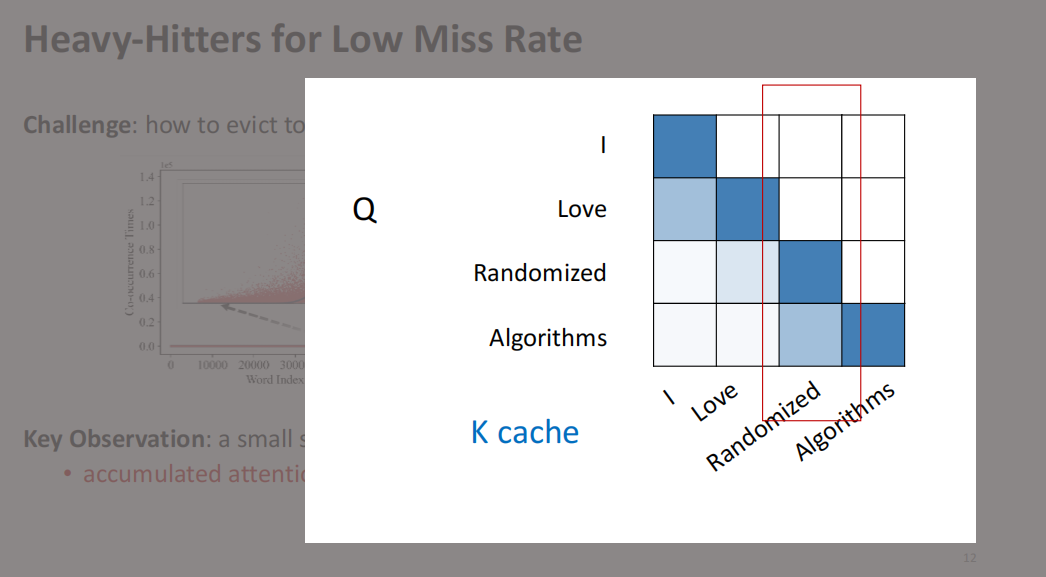
既然我们已经了解注意力机制具有自然的稀疏性,那么在推理和每次生成内容时,是否可以仅关注Top K的关键部分呢?这里存在一个关键挑战:如何在每次生成时确定哪些部分属于Top K?此外,这些关键部分可能是动态变化的。
在我们的研究中,我们记录了每个token在推理过程中被查看的某种Score,并总结了这些Attention Score。通过分析,我们发现有一些Heavy Hitters经常被高频查看。如果保留这些高频查看的部分,似乎在许多任务中——例如文本摘要和其他任务——不仅不会降低精度,反而能够在保持高效的同时,简化模型的计算量。
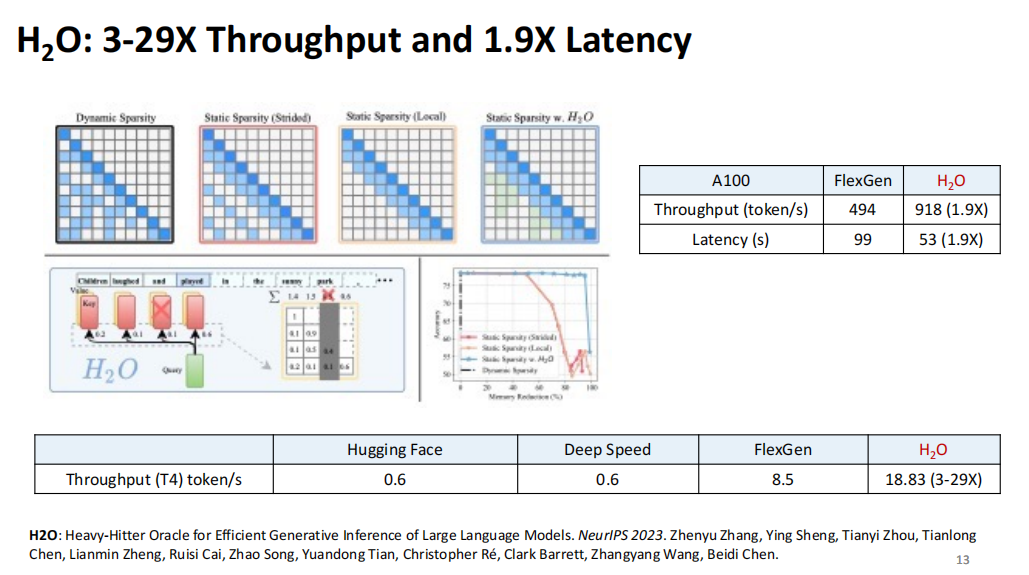
把这些分高的部分(比如很简单的 eviction policy)留下来,就可以做到比如 latency 和 throughput 的一些结果。

随后我们研究了 heavy hitters 到底是什么?为什么在生成的时候会看同样一个token?
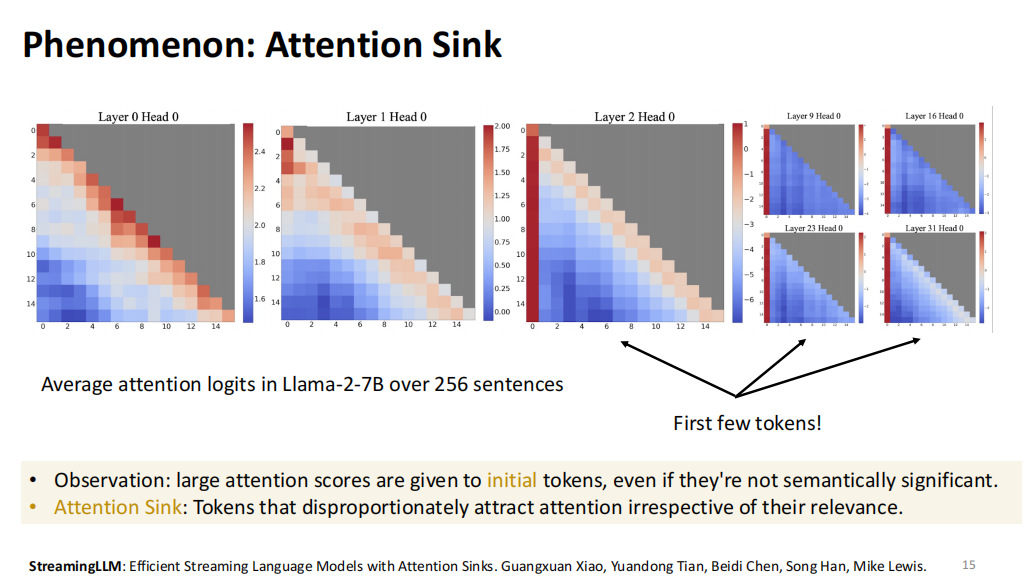
在我们的研究中,我们发现了Attention Sink现象。具体而言,在StreamingLLM的研究中,我们观察到除了局部上下文,长上下文的信息也非常关键。对于自回归模型,通常会向前查看几个token以判断下一步生成的内容。
然而,我们还发现了一个有趣的现象:在生成过程中,模型对前1到4个token的Attention Score特别高。这个现象令人意外,可能的原因是这些位置在语义上具有重要意义。比如,当我们开始讲话时,第一句话通常承载更多信息量。即使我们将这些前几个token替换为随机字符,它们的Attention Score依然保持很高。这一发现推动了StreamingLLM的发展,使得模型可以无限生成内容,并通过位置编码的插值(Interpolation)来实现这一点。

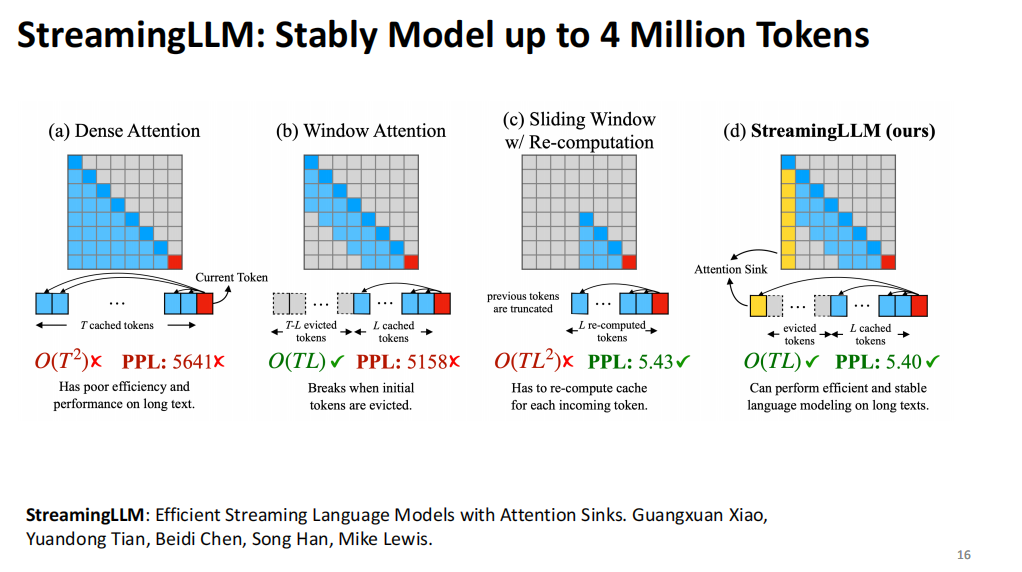
然而,这种方法也暴露了问题。特别是当模型只关注局部和最初的token时,中间的信息容易被遗忘。这种现象引发了我们在MagicPig项目中的讨论。一个重要的问题是:如果用StreamingLLM来续写《三国演义》,而模型在前30章中没有提到诸葛亮,后30章也没有提到他,那么在继续生成内容时,诸葛亮这个人物是否会被忽略?
是的。
在某些场景下,比如对话、聊天或摘要生成时,遗忘部分可能是可以接受的,但其他任务中,我们并不希望模型遗忘中间的重要内容。这种局限性提示我们需要进一步优化模型,以确保在长文本生成中保留重要的中间信息,从而提升整体表现。
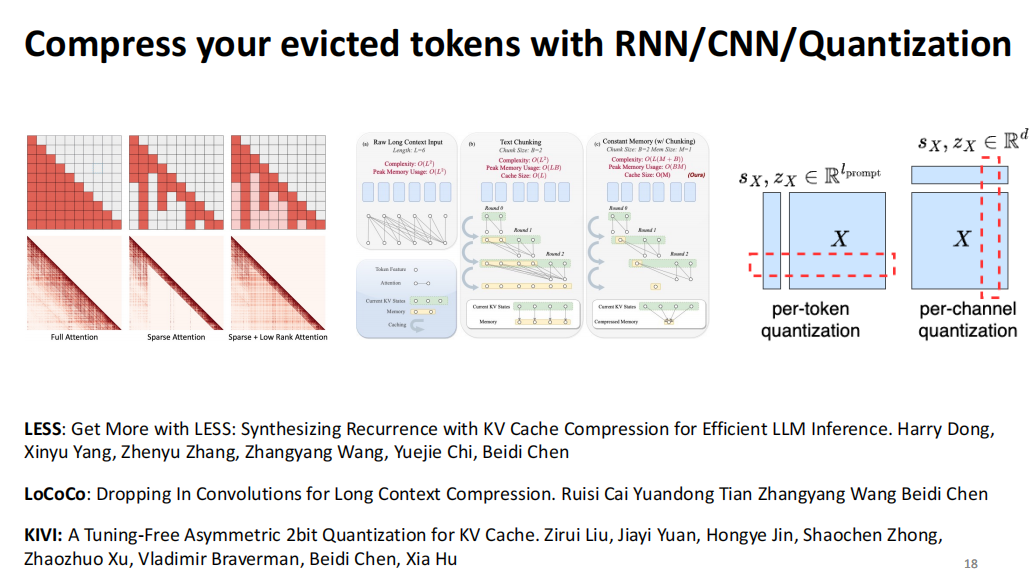
后续我们用了很多方法,比如说 LESS、LoCoCo、KIVI,一系列不管是把 sparse attention 和 RNN 结合、还是用 learnable convolution、或者是 quantization 结合,用尽一切方法去弥补扔掉的 token 所代表的信息。

然而有一个共同问题。在静态KV压缩的研究中,随着变量增多,逻辑层次变得复杂。尽管这些KV压缩方法在长文本处理任务(如Long Bench)以及常规基准测试(Benchmark)中表现良好,模型可能会遗忘重要的初始值,导致后续推理出错。这种信息一旦丢失,无法恢复,导致模型在推理和生成过程中频繁出错。
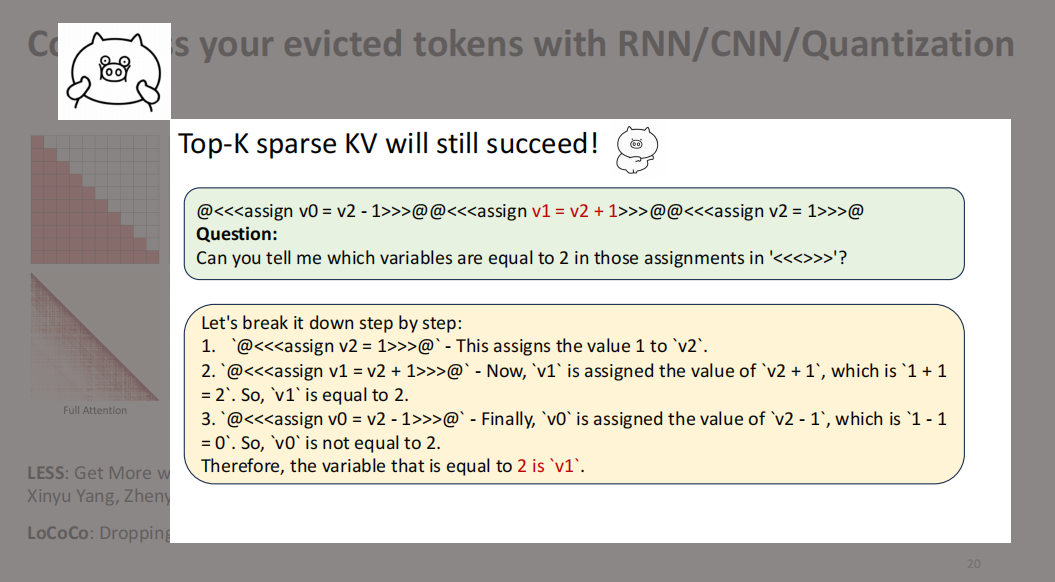
尽管我们还在研究 Sparse Attention,但不同于静态压缩直接丢弃某些KV或采用压缩模式,在生成过程中动态选择关注的对象。这一模式非常稳定,几乎不会失败。
这一系列研究验证了我们最初的观察——注意力机制本质上是自然稀疏的,这一点是站得住脚的。我们投入了大量精力去检验和挑战我们自己设计的这些静态模型,并且在过程中进一步理解了Top K稀疏的本质。这种动态选择的模式不仅提升了模型的稳定性,也进一步强化了稀疏注意力机制在实际应用中的有效性。
尽管我们还在研究 Sparse Attention,但不同于静态压缩直接丢弃某些KV或采用压缩模式,在生成过程中动态选择关注的对象。这一模式非常稳定,几乎不会失败。
这一系列研究验证了我们最初的观察——注意力机制本质上是自然稀疏的,这一点是站得住脚的。我们投入了大量精力去检验和挑战我们自己设计的这些静态模型,并且在过程中进一步理解了Top K稀疏的本质。这种动态选择的模式不仅提升了模型的稳定性,也进一步强化了稀疏注意力机制在实际应用中的有效性。

我们研究了Top K Sparse,不再直接丢弃KV,而是动态选择关注对象。结果显示,这一模式稳定且有效。TriForce项目进一步探讨了动态KV压缩与speculative decoding的结合,通过引入小模型进行猜测,减少大模型的计算成本。通过这种方法,我们在保持推理精度的前提下,实现了无损加速。
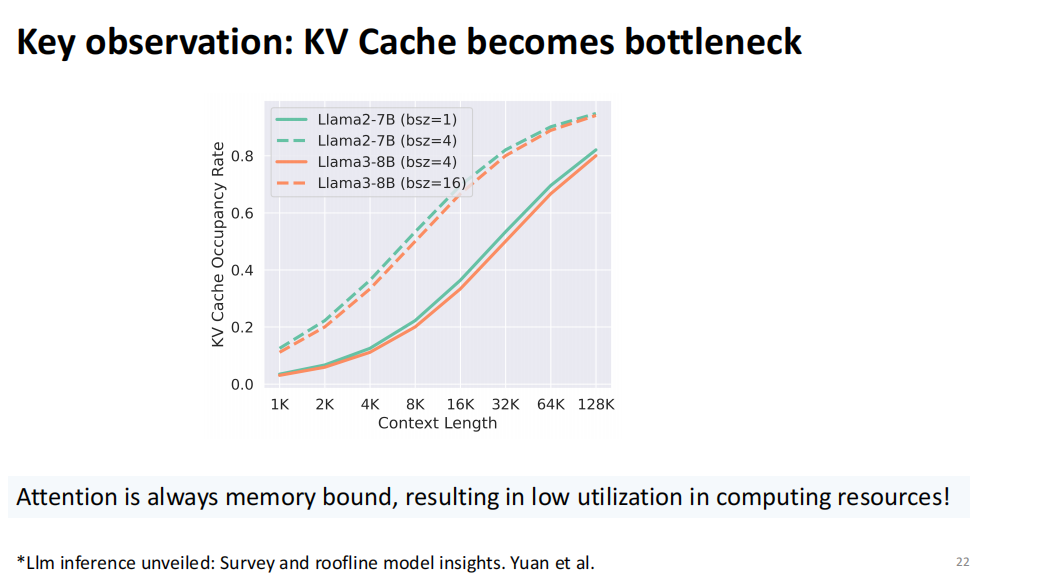
这个工作主要利用两个性质,KV cache 在 context 的长度和 batch size 逐渐增加的时候,会慢慢地变成 bottleneck,以前的内存 bottleneck 是模型,现在是 KV 。
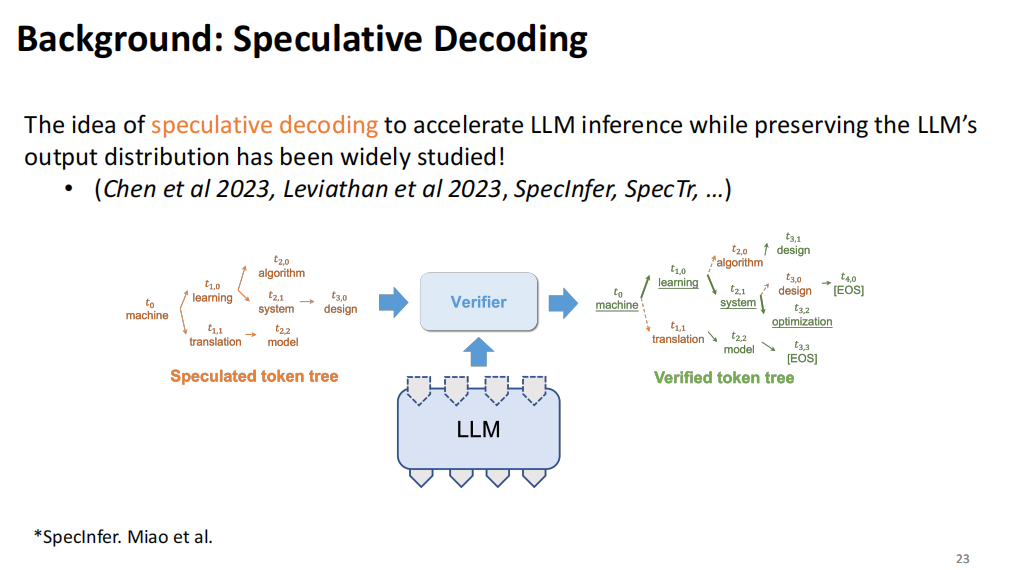
Speculative Decoding最初被提出是为了减少大模型在解码过程中所需的计算资源。假设在生成100个token时,使用像Llama 7B这样的大模型,通常需要加载并运行100次,这会带来极高的计算成本。为了优化这一过程,可以引入一个参数量较小的模型,例如68M参数的模型。通过让这个小模型猜测10次,然后只需加载并运行Llama 7B(大模型)一次,再检查68M生成的结果是否正确,从而减少计算开销。
Greedy Decoding的原理相对简单:只需验证这些生成的token是否与大模型本来要生成的token一致。如果不一致,则舍弃该结果。但如果小模型在10次尝试中能够正确猜出5次,那么就实现了加速,因为68M模型的生成计算成本几乎可以忽略不计。这就是Speculative Decoding的基本原理,通过这种方式,大幅降低了大模型在解码过程中所需的资源消耗。
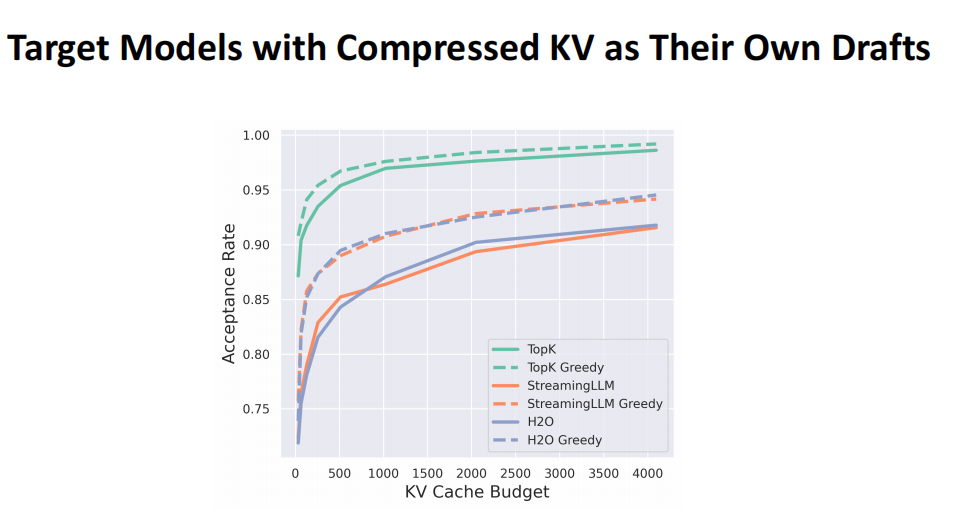
那speculative decoding 和 KV compression 怎么结合到一起呢?以及和Top K,和 dynamic 的 KV compression 为什么可以结合到一起呢?
在研究中,我们引入了Acceptance Rate来衡量小模型猜测的准确性。如果猜测准确,生成过程的效率将大幅提升。我们探索了Top-K、Oracle Top-K、StreamingLLM、H2O等KV压缩机制,目前的Acceptance Rate非常高,即使H2O或StreamingLLM可能丢失部分信息,但它们在局部预测中的准确性依然出色。将这些方法与Speculative Decoding结合,不仅有效分摊计算成本,还确保了输出的精确性。由于Speculative Decoding需要全模型推理,因此所有KV必须被缓存,同时Dynamic Sparse也需存储KV以保证推理的效率和准确性。
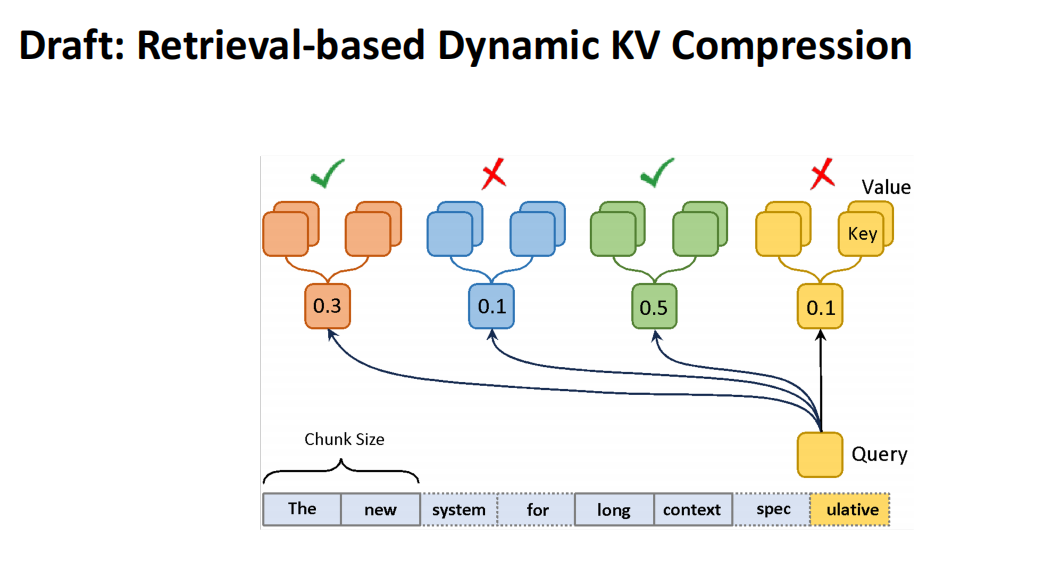
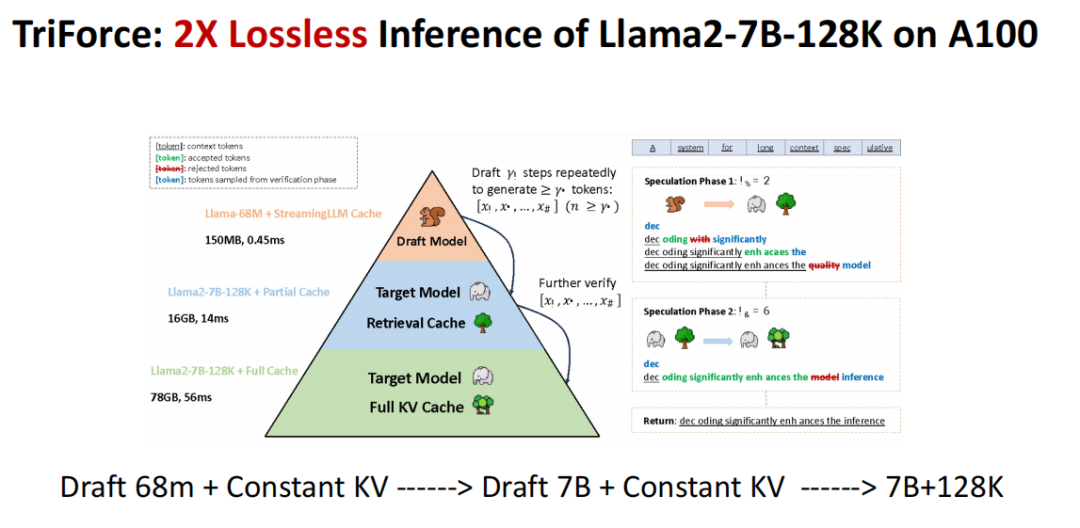
那我们是不是可以探索一种比 H2O 和 streamingLLM 更灵活的选择机制呢?
我们采用了一种类似搜索的机制,通过平均化或生成表示来选择与查询相关的数据块进行推测,从而构建了一个Draft Model。在这种机制下,我们在A100上实现了约两倍的无损加速。虽然相较于H2O和StreamingLLM在吞吐量和延迟上的提升不如预期显著,但在保持推理精度的前提下,仍然是一项有价值的工作。这表明,通过无损推理优化Speculative Decoding,提升大模型的应用效率仍有很大的潜力。
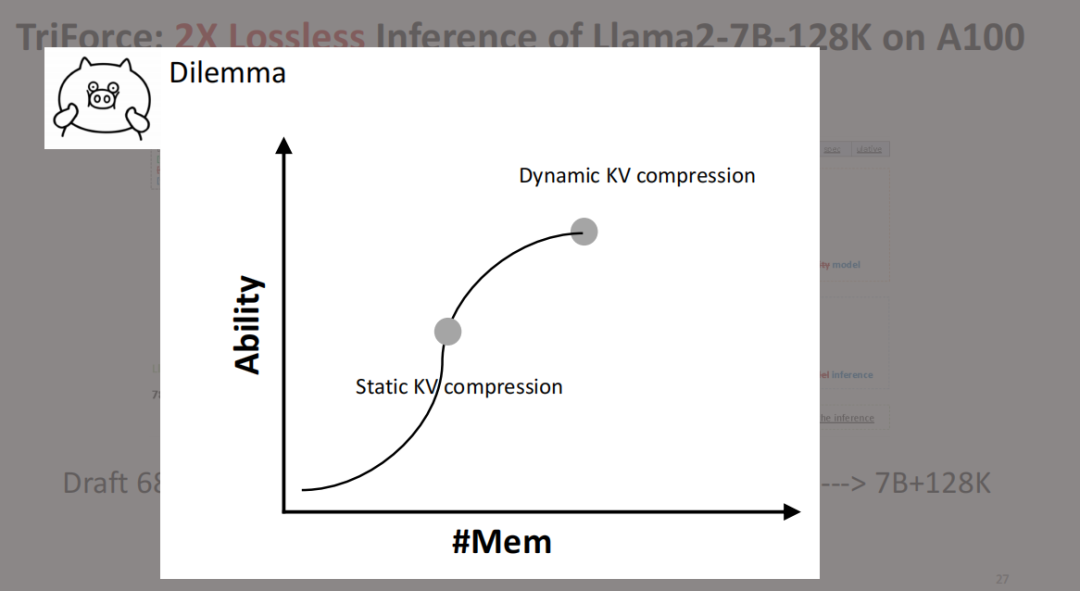
尽管静态KV能节省内存,但会削弱模型功能,而动态KV虽保留了功能性,却占用大量内存,导致吞吐量难以提升。
是否存在其他方法可以解决这一难题?
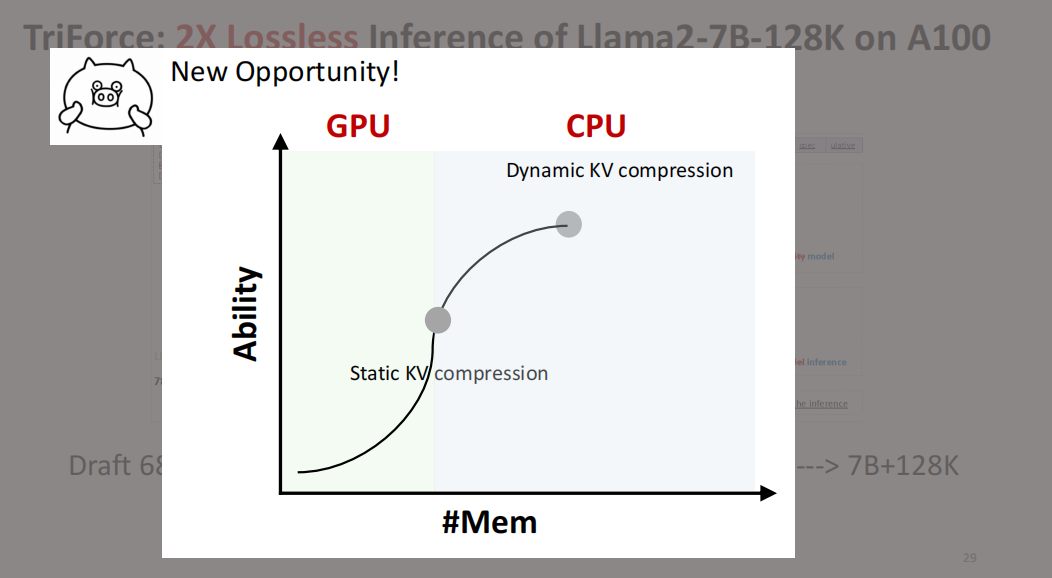
这个就是今天我主要想介绍的一个新的方向,也就是 GPU 和 CPU 上的 co-design。我们可以把 static KV compression 的部分(memory 是有限的)放在 GPU 上,剩下 dynamic 的部分存起来放到 CPU 上,然后可以用 CPU 做计算。
注意这里不是用 PCle 把它拉到 GPU 上,而是直接用 CPU 做计算。


设计的合理性
1. CPU与GPU的内存带宽对比
尽管AIPC的能力在不断提升,但CPU在深度学习领域的劣势主要体现在计算和并行化能力上。值得注意的是,CPU的内存带宽“仅仅”比GPU低10倍,而在计算能力上,CPU与GPU的差距可能高达几百倍。因此,这10倍的差距具有重要意义,弥合这一差距是可能的。
2. CPU内存带宽与GPU对比
通常,任务卸载到CPU上时会考虑PCIe的局限性,PCIe的带宽仅为32GB,而GPU如A100的带宽大约为2TB。但实际上,CPU的内存带宽平均在200到400GB/s之间,比GPU低十倍,使得优化CPU内存带宽成为可能。
3. Attention计算中的内存瓶颈
KV cache是Attention计算中的主要瓶颈,其计算和内存需求始终是1:1的。不同于共享的线性层,KV cache是每个用户独有的信息,不会被其他用户共享。当Batch Size增加时,线性层的计算逐渐从内存受限转为计算受限,而KV cache始终保持1:1的计算负担。
4. 内存带宽对CPU的影响
如果计算与内存需求的比例为1:1或1:4,那么在处理GQA任务时,CPU的计算核心能力就不是主要瓶颈,只要内存带宽足够,CPU的计算能力问题就不那么重要。
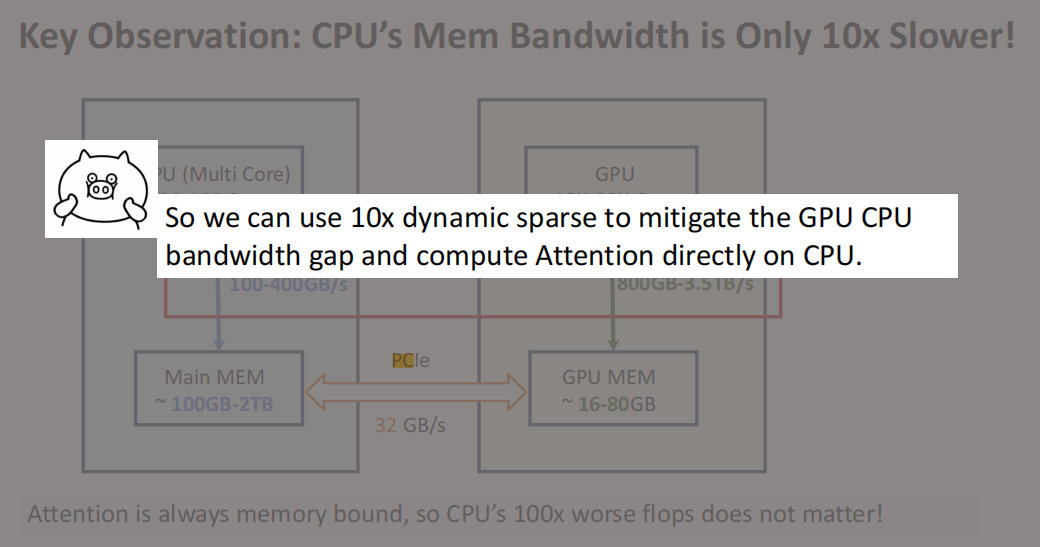
那现在主要的问题还是在 bandwidth,如果能把 CPU 和 GPU 的这个 bandwidth 给填补了,比如说把十倍给拉齐了,那我的 CPU 就相当于是我 GPU 外挂的无限内存,他们是有同样的 bandwidth 的。
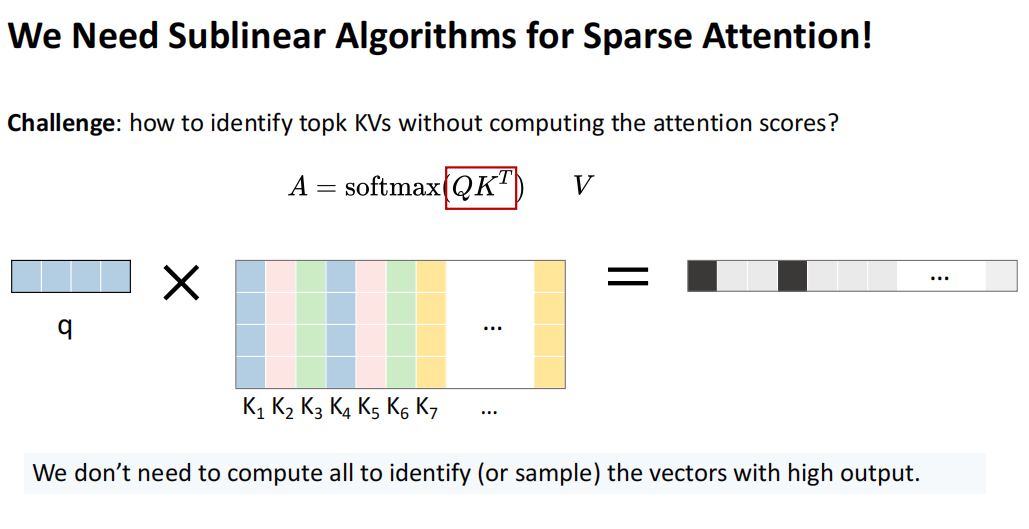
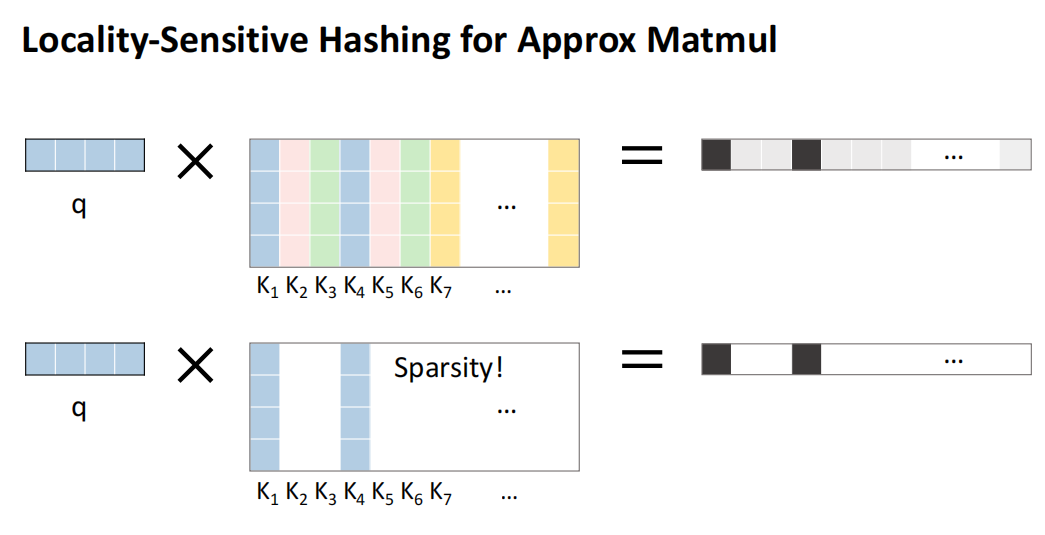
为了确定Top K关键值,即使我们将KV cache存储下来,仍需匹配查询与KV cache,以找出真正的Top K。之前提到的TriForce不要求精确的Top K,因为最终会进行验证,随意选择候选项通常能取得较好结果,但在当前场景下,我们在CPU上计算时对搜索的精度要求更高。
例如,如果只加载了十分之一的KV cache,这部分必须接近原始Top 10%的关键部分,因此搜索必须更精准。这个问题可转化为“最大内积搜索”,即简化为向量与矩阵的乘积计算,重点是如何准确找到关键K值并只计算这些部分。
为解决这个问题,我们引入了“LSH”(Locality Sensitive Hashing)算法。LSH适用于当前GPU和CPU协同设计,且存储便宜,可以进行外部内存的研究,而无需压缩所有内容。

Locality-Sensitive Hashing(LSH)的简介
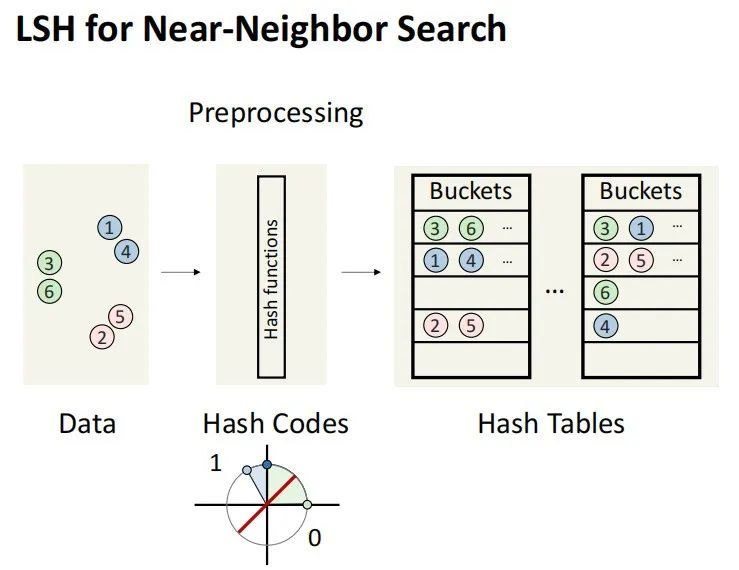
Locality-Sensitive Hashing (LSH) 是一种用于高维数据空间中最近邻搜索的技术。它通过哈希函数将相似的对象映射到相同的桶中,使得相似对象更容易被识别。
举个二维的例子:假设在一个圆上有一个查询点(query),一个最近邻点(nearest neighbor),和一个远离的点(far-away point)。如果我们随机对这个圆进行切割,有一定概率会将查询点和最近邻点分到同一部分,也有可能将查询点与远离的点分到一起。不过,由于查询点和最近邻点在空间上更接近,它们更可能被划分到同一部分中。这种情况下,它们更可能共享同一个哈希值(hash value),这一概率可以通过计算得到。例如,使用基于余弦相似度的随机投影(random projection)时,这种概率与查询点和数据点之间的角度成正比。换句话说,角度越小(即点越接近),它们共享相同哈希值的可能性越大。
为什么可以用这个基础算法去做 near-neighbor search,以及 approximate matrix modification, approximate KV 呢?
我们可以对数据进行预处理。例如,对于数据集中的123456等数据项,我们可以计算出多个Hash Code,然后将这些数据根据哈希码分类存储在Hash Table中。通过这种方式,我们能够高效地管理和检索这些数据。
更进一步地,我们还可以创建多个Hash Table,每个哈希表可能会将某些ID或数据项放入相同的 Bucket 中。这种方法允许我们在进行搜索时,快速锁定与查询相关的关键数据,从而大幅提升搜索效率。
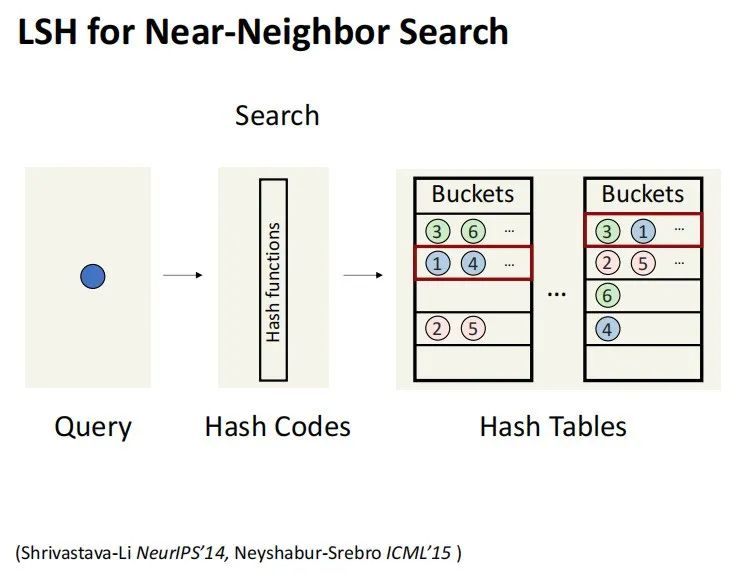
我们在 search 的时候做什么呢?
当一个新的Query到来时,我们可以使用相同的 Hash Function来计算其Hash Code,类似于Hash Table Lookup,以确定其对应的ID。
例如,如果这个查询的哈希码是01,那么我们就去第二个Bucket 中进行搜索;如果在另一个哈希表中它的哈希码是00,那么我们就去第一个桶中查找。最终,我们可以将这些可能的ID(如1、3、4)都提取出来,因为这些很可能就是查询的潜在近邻。
这种方法主要用于进行 Nearby Search,同时也可以应用于 Max Inner Product Search,尽管在深度学习中我们更多地使用 Inner Product进行计算。
这一领域有非常丰富的研究文献支撑,今天我就不在此展开详细讨论。

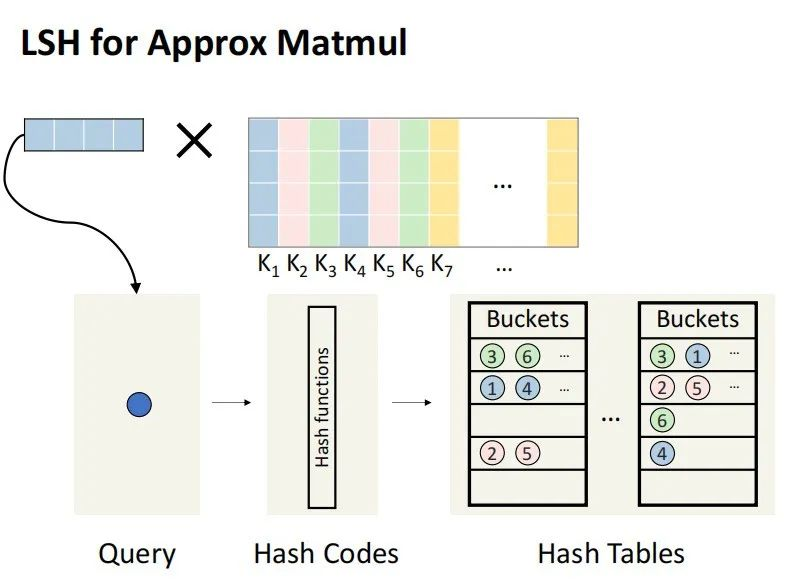
LSH 为什么可以做我们这件事情呢?
我们可以把这个 K preprocess 到 hash table 里,通过随机的 hash function。在 query 的时这个 Q 同样可以计算hash code,并且去 hash table 里把它的 neighbor 找出来,比如说找出来是K1 和 K4,那么只用算 Q 乘 K1 和 Q 乘 K4,就可以做 sparse Top-K attention,approximate Top-K attention。

More details:
LSH在理论上是一个理想的解决方案,但它在实际应用中也存在一些问题。
首先,尽管我们讨论的是理想情况下的LSH,它本质上是一个切割空间的算法,但如果你不了解数据的分布情况,因为它是数据无关的,就需要非常多的Partition来执行这一任务。
一个非常现实的问题是,虽然LSH是一个次线性的算法,但在实际操作中,可能仍然相当昂贵,并且面临一些实际的挑战。
在MagicPig项目中,我们通过GPU和CPU的 Co-design克服了这些不足,甚至弥补了LSH在实操中的一些局限性。
举个例子,在搜索过程中,计算 Hash Function 或 Hash Codes的数量越多,速度就会越慢。然而,在KV cache的处理中,如果将这些计算任务放在GPU上执行,它实际上是“免费的”,因为GPU的计算核心通常是过剩的。
因此,我们通过系统的 Co-design,让这一曾经只是理论上理想的算法能够在实际应用中发挥出最大的潜力。
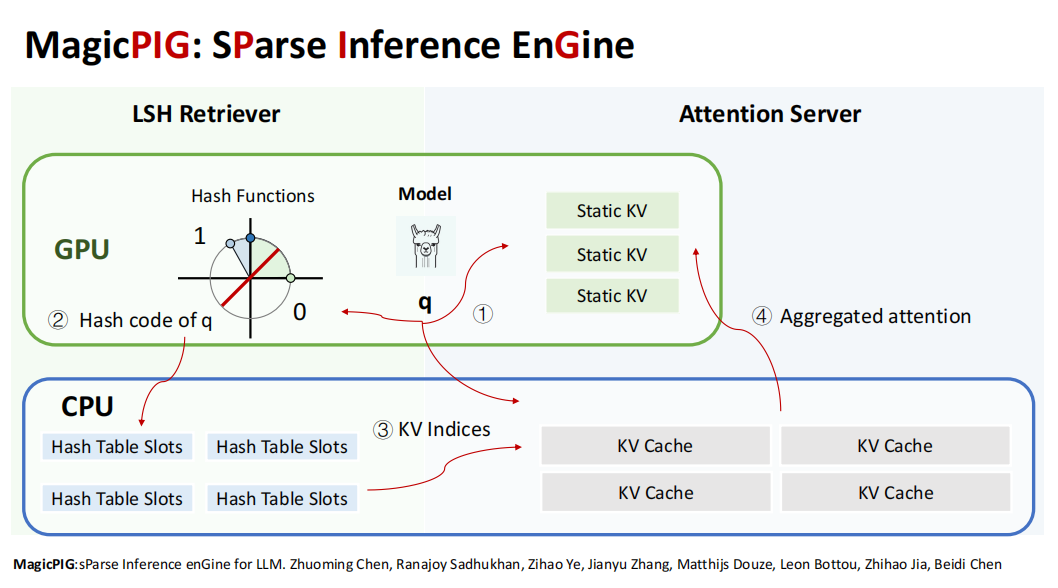
最后的这个系统,在GPU上进行 Hash Function 的计算,以及部分 Static KV 的处理;而在CPU上则存储了对应的索引,实际上就是 Hash Table 。这一设计类似于将KV cache视为一个RAG,并为其建立了一个小型的搜索引擎。
具体的工作流程如下:
每当一层的查询(Q)或输入到达时,系统首先在GPU上计算cache code,并处理 Static Attention 部分,然后将结果发送到CPU;在CPU上进行 Hash Code 的计算,并根据哈希码从CPU中的KV cache中检索对应的数据。随后,这些ID(在之前的例子中如1和4)就可以用于 Sparse KV 的计算。最后,CPU将注意力计算的结果发回GPU,与之前的静态KV计算结果相结合,完成整个推理过程。
以上就是MagicPig(SParse Inference Engine)的系统介绍,它通过静态KV和动态KV的结合,以及GPU与CPU的协同设计,实现了高效的推理加速。

今天的分享中我想强调一个关键点:Transformer模型的潜力还有待进一步挖掘。我推荐朱泽园在ICML上的教程,通过实证实验帮助理解Transformer的工作原理及其作用。
其中一个部分与我们对长文本的理解密切相关,启发了我们建立用于测试和攻击静态KV的逻辑链数据集。逻辑链的深度(即关系复杂度)越深,LLM越容易失败,能更好地体现模型的实际能力。这一发现对理解和改进长文本推理有重要意义。
我认为long context理解难点在于,如果给LLM一个长且相关的文本,并希望它自行理清关系,计算图或关系越深,就越难理解。测试任务如RAG和needle in the haystack应与RAG合作。
两种long context:
1. 与RAG合作: 人难以输入自然的128K或百万级context,更可能是LLM自动找到相关的context,这时希望它具备memorization能力,不会忘记信息。
2. long context learning: 更高级的能力是将不相关的文档、用户日志、对话等关系理清楚,并在生成时理解这些信息。这是超越RAG的能力。
我希望通过MagicPIG或KV cache探索了解新架构的目标,推荐从synthetic任务和数据入手。与泽园讨论后认为,定义能力后,可以创建数据集和控制实验,即使在小规模中也能观察到。
虽然大公司可能已放弃其他架构,但探索超越Transformer的LLM仍是巨大的机会,关注效率之外的能力提升。

Max inner product search和RAG底层算法是精细化的搜索算法,将RAG应用于LLM内存。DeepMind在2020年左右投入大量精力构建高要求的搜索训练基础设施,关注其对训练的影响和是否会出现新的架构或系统支持。

观察到常用内存放在GPU,其他内容放在CPU,RAG等存储在SSD或更低级存储中,形成层级结构。unify memory或processing memory等硬件架构新变动可能对模型架构设计提供启发。长期发展这个方向十分有趣。

文章来源“LLM SPACE”,作者“LLM SPACE”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
