# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。
在这个「亩产八万斤」,「10 天一个 SoTA」的时代,简单易用、标准透明、可复现的多模态评估框架变得越来越重要,而这并非易事。
为解决以上问题,来自南洋理工大学 LMMs-Lab 的研究人员联合开源了 LMMs-Eval,这是一个专为多模态大型模型设计的评估框架,为多模态模型(LMMs)的评测提供了一站式、高效的解决方案。

自 2024 年 3 月发布以来, LMMs-Eval 框架已经收到了来自开源社区、公司和高校等多方的协作贡献。现已在 Github 上获得 1.1K Stars,超过 30+ contributors,总计包含 80 多个数据集和 10 多个模型,并且还在持续增加中。
标准化测评框架
为了提供一个标准化的测评平台,LMMs-Eval 包含了以下特性:
LMMs-Eval 的愿景是未来的多模态模型不再需要自行编写数据处理、推理以及提交代码。在当今多模态测试集高度集中的环境下,这种做法既不现实,测得的分数也难以与其他模型直接对比。通过接入 LMMs-Eval,模型训练者可以将更多精力集中在模型本身的改进和优化上,而不是在评测和对齐结果上耗费时间。
评测的「不可能三角」
LMMs-Eval 的最终目标是找到一种 1. 覆盖广 2. 成本低 3. 零数据泄露 的方法来评估 LMMs。然而,即使有了 LMMs-Eval,作者团队发现想同时做到这三点困难重重,甚至是不可能的。
如下图所示,当他们将评估数据集扩展到 50 多个时,执行这些数据集的全面评估变得非常耗时。此外,这些基准在训练期间也容易受到污染的影响。为此, LMMs-Eval 提出了 LMMs-Eval-Lite 来兼顾广覆盖和低成本。他们也设计了 LiveBench 来做到低成本和零数据泄露。
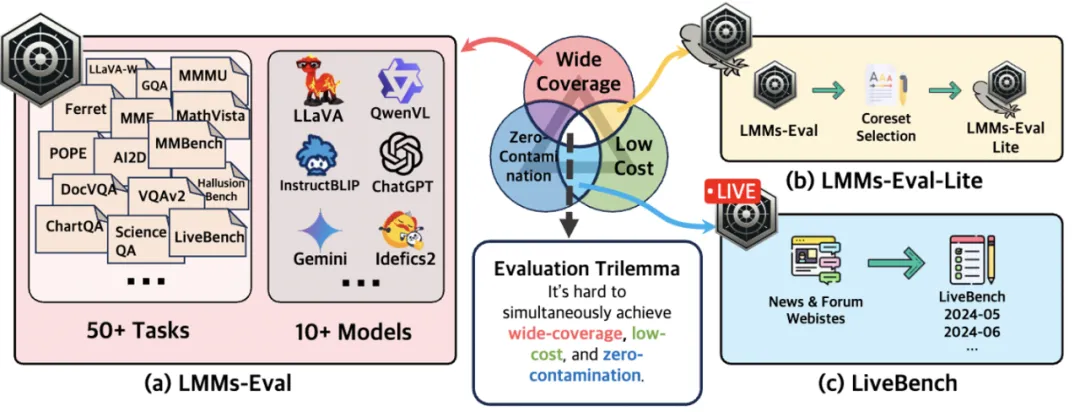
LMMs-Eval-Lite: 广覆盖轻量级评估
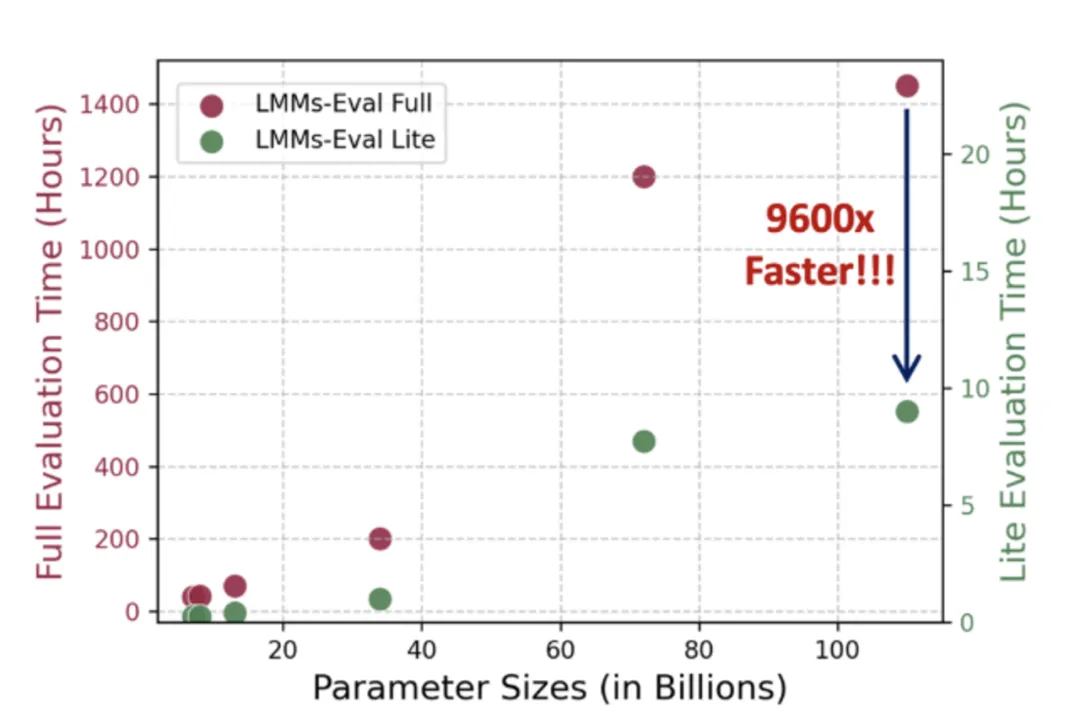
在评测大模型时,往往庞大的参数量和测试任务会使得评测任务的时间和成本急剧上升,因此大家往往会选择使用较小的数据集或是使用特定的数据集进行评测。然而,有限的评测往往会使得对于模型能力的理解有所缺失,为了同时兼顾评测的多样性和评测的成本,LMMs-Eval 推出了 LMMs-Eval-Lite
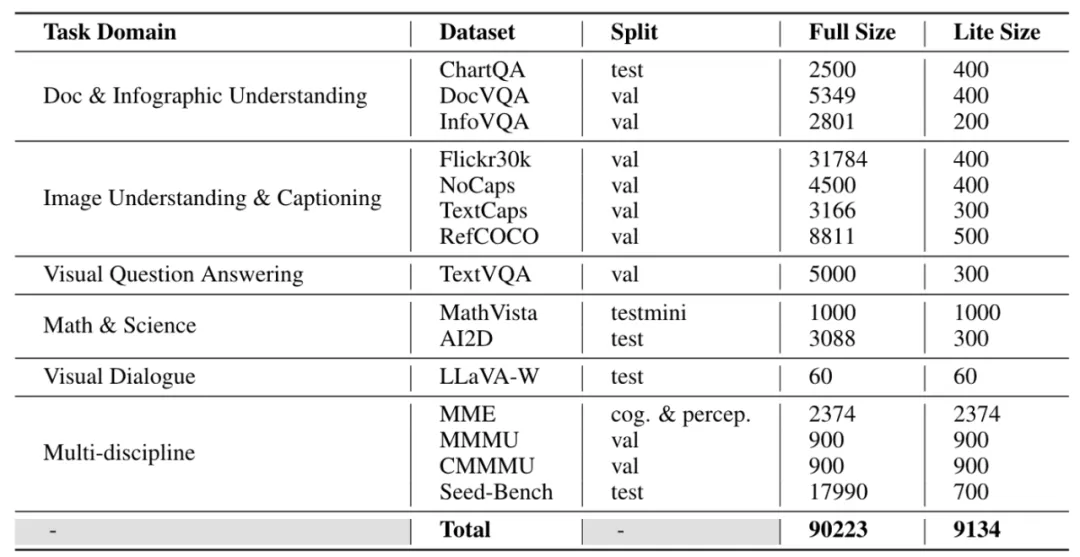
LMMs-Eval-Lite 旨在构建一个简化的基准测试集,以在模型开发过程中提供有用且快速的信号,从而避免现在测试的臃肿问题。如果我们能够找到现有测试集的一个子集,在这上面的模型之间的绝对分数和相对排名与全集保持相似,那么我们可以认为修剪这些数据集是安全的。
为了找到数据集中的数据显著点,LMMs-Eval 首先使用 CLIP 和 BGE 模型将多模态评测数据集转换为向量嵌入的形式并使用 k-greedy 聚类的方法找到了数据显著点。在测试中,这些规模较小的数据集仍然展现出与全集相似的评测能力。
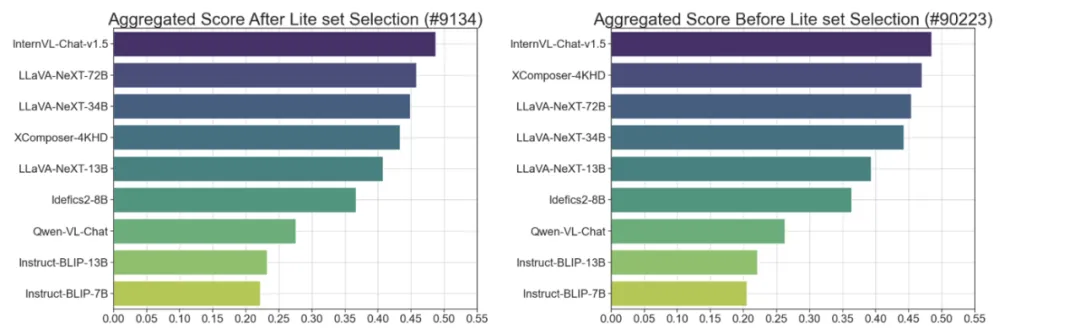
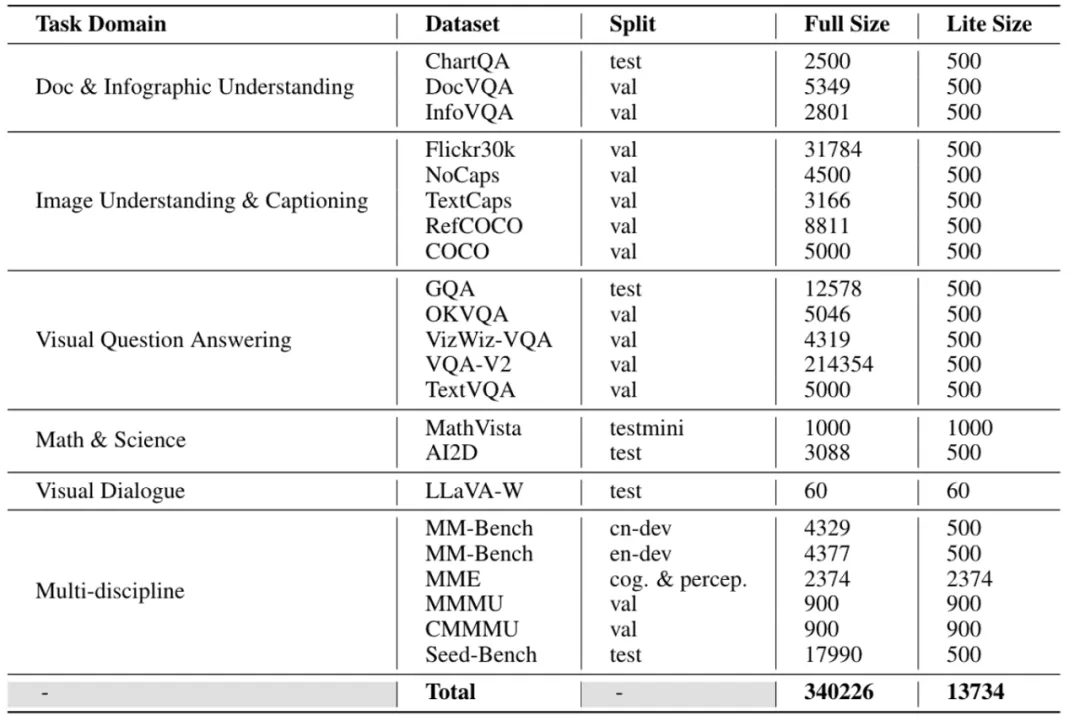
随后 LMMs-Eval 使用了相同的方法制作了涵盖更多数据集的 Lite 版本,这些数据集旨在帮助人们节省开发中的评测成本,以便快速判断模型性能
LiveBench: LMMs 动态测试
传统基准侧重于使用固定问题和答案的静态评估。随着多模态研究的进展,开源模型在分数比较往往优于商用模型,如 GPT-4V,但在实际用户体验中却有所不及。动态的、用户导向的 Chatbot Arenas 和 WildVision 在模型评估中越来越受欢迎,但是它们需要收集成千上万的用户偏好,评估成本极高。
LiveBench 的核心思想是在一个不断更新的数据集上评估模型的性能,以实现零污染且保持低成本。作者团队从网络上收集评估数据,并构建了一条 pipeline,自动从新闻和社区论坛等网站收集最新的全球信息。为了确保信息的及时性和真实性,作者团队从包括 CNN、BBC、日本朝日新闻和中国新华社等 60 多个新闻媒体,以及 Reddit 等论坛中选择来源。具体步骤如下:
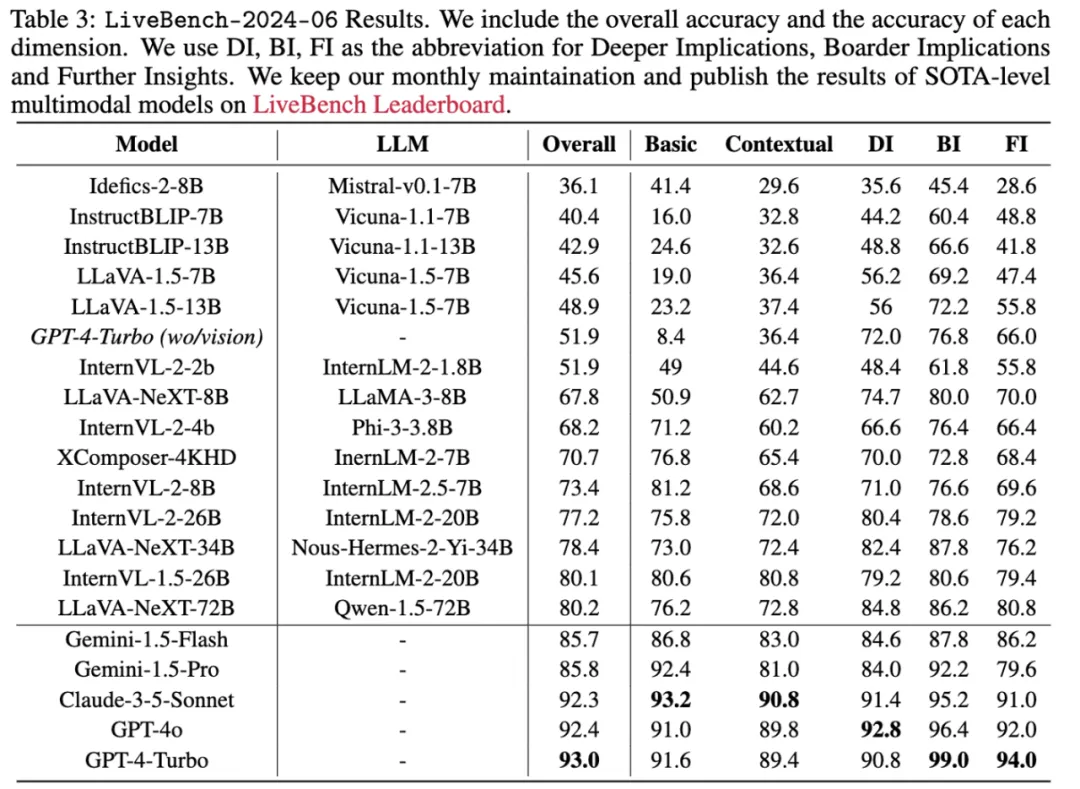
未来也可以在我们动态更新的榜单里查看多模态模型在每个月动态更新的最新评测数据,以及在榜单上的最新评测的结果。
文章来源于“机器之心”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
