AI接管数字世界!华为Claw-Anything:面向跨设备、跨时间、跨服务的Claw评测与数据引擎
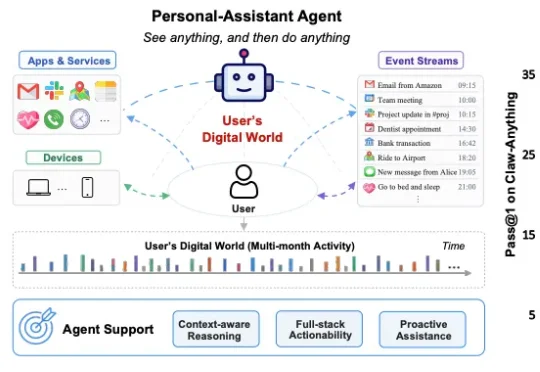
AI接管数字世界!华为Claw-Anything:面向跨设备、跨时间、跨服务的Claw评测与数据引擎我们相信,常驻型 (always-on) AI 助理的下一次飞跃,不在于把某一个模型单点调得更聪明,而在于扩展智能体的上下文 (Scaling Agent Context)—— 不断拓宽助理能够持续 "感知 — 推理 — 执行" 的范围,作为生活连接器连接用户的信息孤岛,直到它能接管用户的整个数字世界。
来自主题: AI技术研报
8315 点击 2026-06-21 10:34