# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
该论文作者来自于鹏城实验室多智能体与具身智能研究所及南方科技大学、中山大学的师生团队,包括林倞教授(研究所所长,国家杰青,IEEE Fellow),郑锋教授,梁小丹教授,王志强(南科大),郑浩(南科大),聂云双(中大),徐文君(鹏城),叶华(鹏城)等。鹏城实验室林倞教授团队致力于打造多智能体协同与仿真训练平台、云端协同具身多模态大模型等通用基础平台,赋能工业互联网、社会治理与服务等重大应用需求。
今年以来,具身智能正在成为学术界和产业界的热门领域,相关的产品和成果层出不穷。今天,鹏城实验室多智能体与具身智能研究所(以下简称鹏城具身所)联合南方科技大学、中山大学正式发布并开源其最新的具身智能领域学术成果 ——ARIO(All Robots In One)具身大规模数据集,旨在解决当前具身智能领域所面临的数据获取难题。

作为具身机器人的大脑,想要让具身大模型的性能更优,关键在于能否获得高质量的具身大数据。不同于大语言模型或视觉大模型用到的文本或图像数据,具身数据无法从互联网海量内容中直接获取,而需通过真实的机器人操作来采集或高级仿真平台生成,因此具身数据的采集需要较高的时间和成本,很难达到较大的规模。
同时,当前开源的数据集也存在多项不足,如上表所示,JD ManiData、ManiWAV 和 RH20T 本身数据量不大,DROID 数据用到的机器人硬件平台比较单一,Open-X Embodiment 虽然达到了较大规模的数据量,但其感知数据模态不够丰富,而且子数据集之间的数据格式不统一,质量也参差不齐,使用数据之前需要花大量时间进行筛选和处理,难以满足复杂场景下具身智能模型的高效率和针对性的训练需求。
相比而言,此次发布的 ARIO 数据集,包含了 2D、3D、文本、触觉、声音 5 种模态的感知数据,涵盖操作和导航两大类任务,既有仿真数据,也有真实场景数据,并且包含多种机器人硬件,有很高的丰富度。在数据规模达到三百万的同时,还保证了数据的统一格式,是目前具身智能领域同时达到高质量、多样化和大规模的开源数据集。
对于具身智能的数据集而言,由于机器人有多种形态,如单臂、双臂、人形、四足等,并且感知和控制方式也各不相同,有些通过关节角度控制,有些则是通过本体或末端位姿坐标来驱动,所以具身数据本身比单纯的图像和文本数据要复杂很多,需要记录很多控制参数。而如果没有一个统一的格式,当多种类型的机器人数据聚合到一起,需要花费大量的精力去做额外的预处理。
因此鹏城实验室具身所首先设计了一套针对具身大数据的格式标准,该标准能记录多种形态的机器人控制参数,并且有结构清晰的数据组织形式,还能兼容不同帧率的传感器并记录对应的时间戳,以满足具身智能大模型对感知和控制时序的精确要求。下图展示了 ARIO 数据集的总体设计。
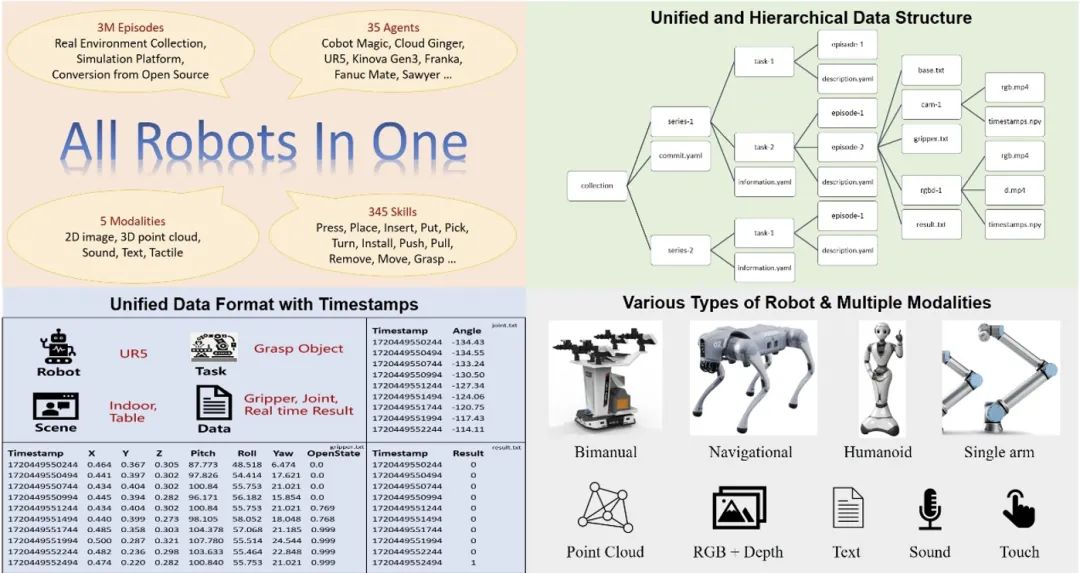
图 1. ARIO 数据集总体设计
ARIO 数据集,共有 258 个场景序列,321064 个任务,303 万个样例。ARIO 的数据有 3 大来源,一是通过布置真实环境下的场景和任务进行真人采集;二是基于 MuJoCo、Habitat 等仿真引擎,设计虚拟场景和物体模型,通过仿真引擎驱动机器人模型的方式生成;三是将当前已开源的具身数据集,逐个分析和处理,转换为符合 ARIO 格式标准的数据。下面展示了 ARIO 数据集的具体构成,以及 3 个来源的流程和示例。

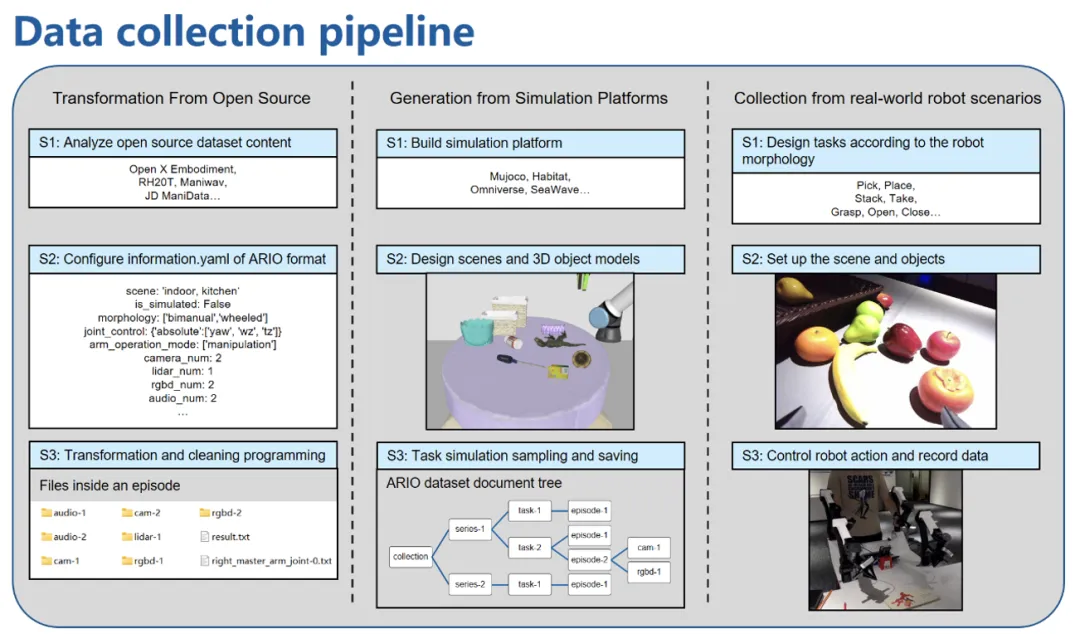
图 2. ARIO 数据 3 个来源
真实场景的高质量的机器人数据不易获取,但意义重大。鹏城实验室基于 Cobot Magic 主从双臂机器人,设计了 30 多种任务,包括简单 —— 中等 —— 困难 3 个操作难易等级,并通过增加干扰物体、随机改变物体和机器人位置、改变布置环境等方式增加样例的多样性,最终得到 3000 多条包含 3 个 rgbd 相机的轨迹数据。下面展示了不同任务的采集示例以及采集视频。

图 3. ARIO 真实机器人数据采集示例

Cobot Magic 机械臂采集数据示例视频
00:07

基于 MuJoCo 的仿真数据采集示例视频

基于 Dataa SeaWave 平台的仿真数据生成示例视频

基于 Habitat 平台的仿真数据生成示例视频

从 RH20T 转换的数据示例视频
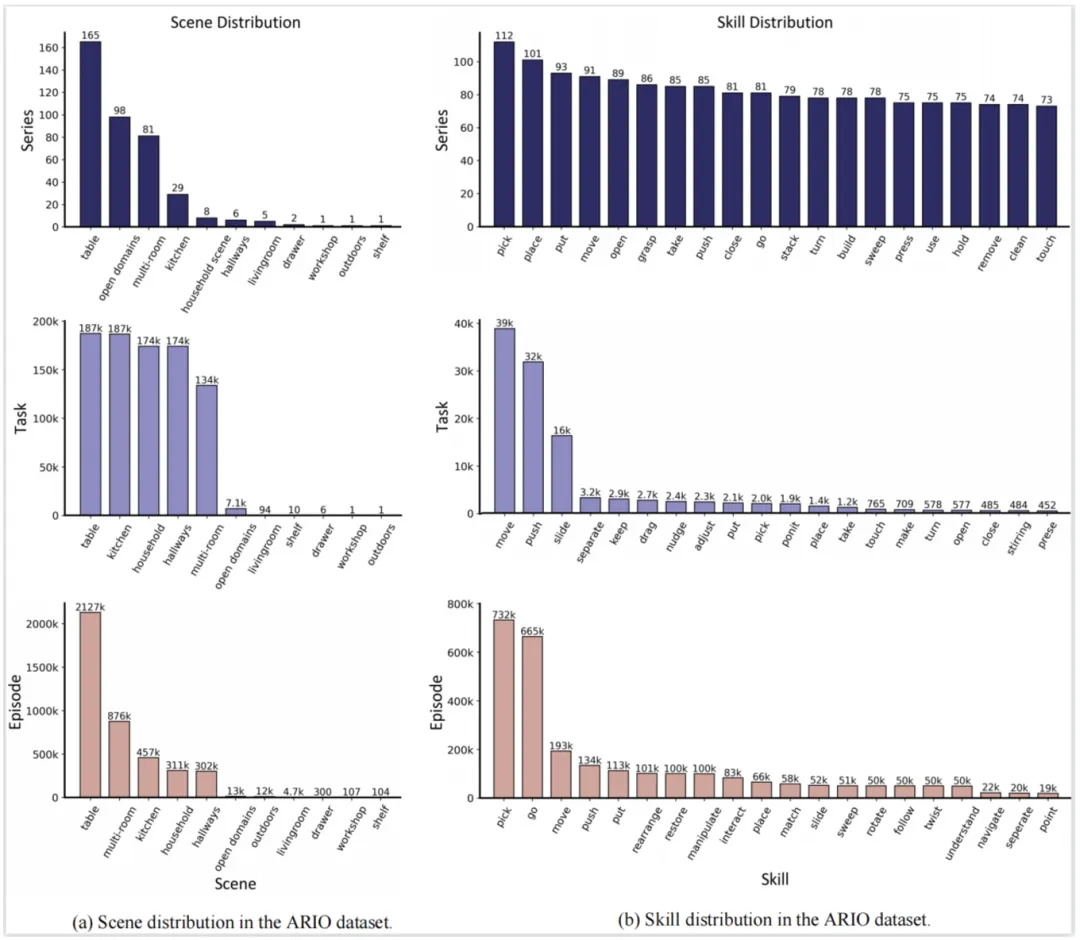
得益于 ARIO 数据的统一格式设计,能够很方便地对它的数据组成进行统计分析。下图展示了从 series、task、episode 三个层面对 ARIO 的场景(图 a)和技能(图 b)的分布进行统计。从中可见,目前大部分的具身数据都集中在室内生活家居环境中的场景和技能。
除了场景和技能,在 ARIO 数据中,还能从机器人本身的角度进行统计分析,并从中了解当前机器人行业的一些发展态势。 ARIO 数据集提供了机器人形态、运动对象、物理控制变量、传感器种类和安装位置、视觉传感器的数量、控制方式比例、数据采集方式比例、机械臂自由度数量比例的统计数据,对应下图 a-i。
以下图 a 为例,从中可以发现,当前大部分的数据来源于单臂机器人,人形机器人的开源数据很少,且主要来源于鹏城实验室的真实采集和仿真生成。
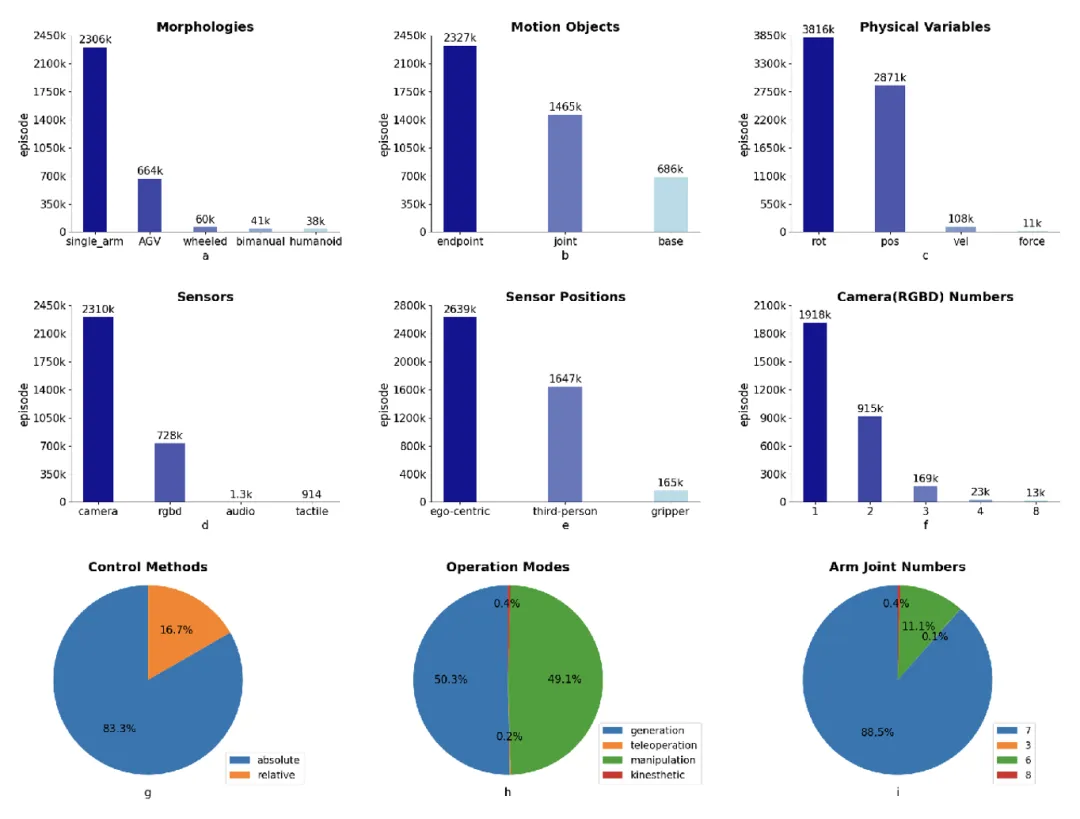
图 5.ARIO 数据集分类统计
更多关于 ARIO 数据集的详细信息与下载链接,请参考论文原文与项目主页。
文章来源于“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
