# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Aparna Ramani
Meta工程副总裁
在2024年AI Infra @Scale会议上发表开幕主旨演讲
她负责AI基础设施、数据基础设施和开发者基础设施。
核心观点
-----

本年度AI成为科技行业焦点,伴随着更大更强的模型、新型AI驱动应用,以及与会者们所关注的大量GPU。在深入探讨当前状况前,让我们回顾历史,以全面理解当下。

AI的历史可追溯至20世纪50年代,艾伦·图灵(Alan Turing)首次提出机器是否能思考的问题。早期热潮后,AI经历了漫长的"寒冬"。90年代末,情况好转,许多人将"AI寒冬"的结束归功于"深蓝"(Deep Blue)。1997年,IBM的"深蓝"在国际象棋比赛中击败世界冠军加里·卡斯帕罗夫(Garry Kasparov)。"深蓝"由近500个定制芯片驱动,每秒可处理约2亿步棋。当时被视为未来,实际上它只是手工编程计算机智能的巅峰。
随后出现的是神经网络。Yann LeCun在80年代提出的卷积神经网络(CNN,Convolutional Neural Network)经历了多次演变。1998年,LeNet-5 CNN在超过6万个邮政编码样本中以99%以上的准确率识别手写邮政编码。CNN训练困难,一度使循环神经网络(RNN,Recurrent Neural Network)更受青睐。2012年,AlexNet的出现被称为AI的"大爆炸"时刻。AlexNet是一个规模远大于LeNet-5的CNN,在当时最大的图像数据集之一ImageNet上训练,包含超过1400万张图像,仅使用两块GPU。AlexNet大幅提升了图像标注精度,并证明了CNN可并行化训练。
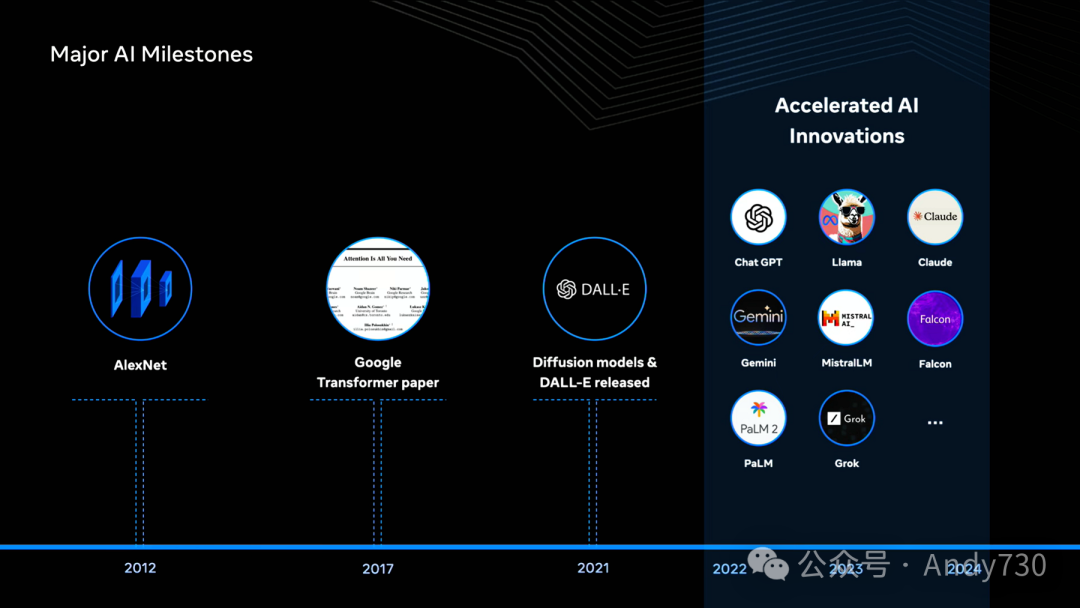
五年后,Google发表《Attention Is All You Need》,引入Transformer模型概念,推动了大规模语言模型的创新:Google的BERT,随后是GPT。2021年,扩散模型崭露头角,DALL·E展示了惊人的文本生成图像能力。2022年11月,ChatGPT将这些模型突破带入公众视野。2023年,Meta开放LLaMA 2供研究和商用。随后我们推出LLaMA 3,包括700亿和80亿参数模型,上周发布了450亿参数的LLaMA 3.1,这是首个前沿级开源AI模型。这些发布引发了行业创新浪潮,并围绕LLaMA建立了完整生态系统。
AlexNet与GPT之间的十年与当前创新速度和强度形成有趣对比。许多与会者共同推动了AI的深入发展。作为AI Infra @Scale活动,我想讨论模型创新与基础设施的联系。AI研究与基础设施演进始终保持共生关系。计算能力、分布式系统和大规模数据处理的可用性促成了当今AI领域的创新。同样,AI的发展路线也塑造了基础设施的演进。
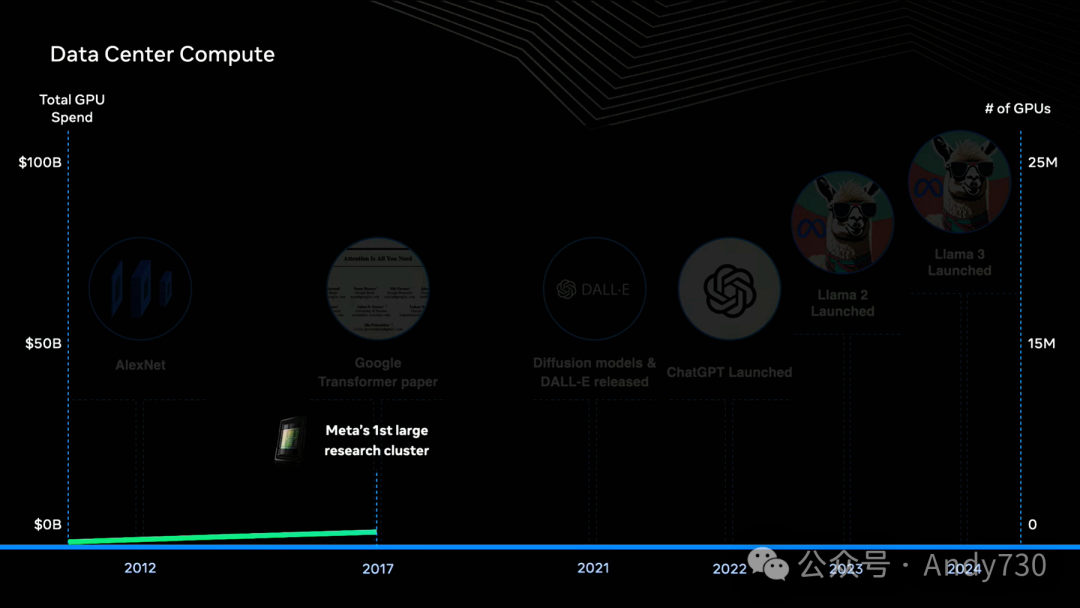
简述数据中心计算历史:几十年来,数据中心一直由x86架构CPU主导。然而,GPU在浮点运算方面优势明显,而这正是模型学习的核心。2012年前,数据中心GPU数量几乎可忽略。2017年开始出现大型研究集群。Meta也建立了首个研究级超级计算机,数据中心GPU数量随之增长。
ChatGPT 2022年发布后,GPU使用量呈爆炸式增长。这种转变是根本性的,因此有人说:"今天的计算机不再是PC,而是数据中心。"现在,单个训练任务可能部署数万台GPU集群,而整个数据中心的GPU数量甚至达到数十万个。
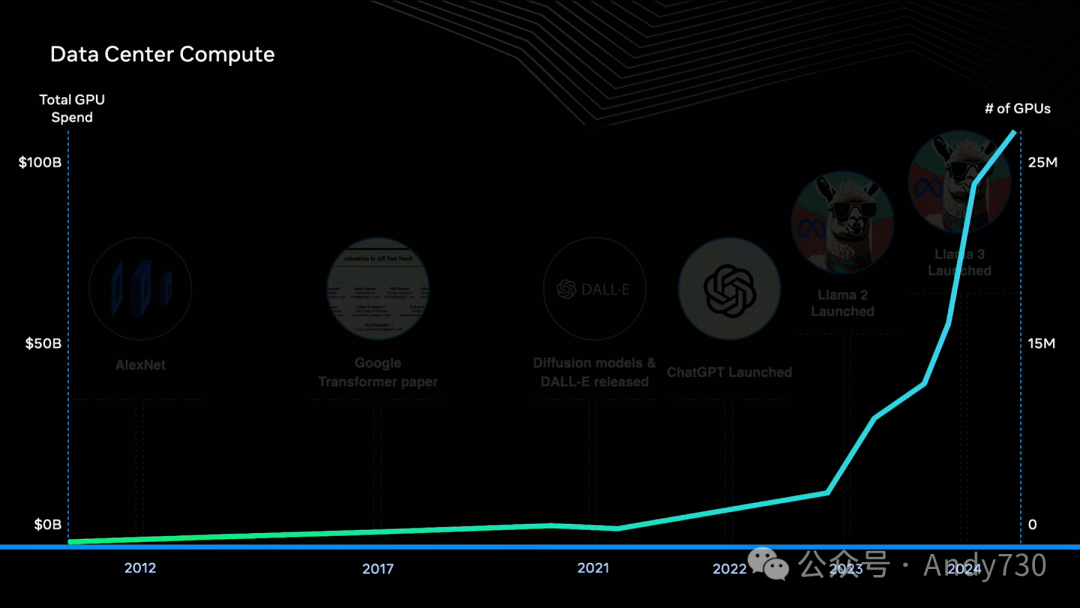
ChatGPT 2022年发布后,GPU使用量呈爆炸式增长。这种转变是根本性的,因此有人说:"今天的计算机不再是PC,而是数据中心。"现在,单个训练任务可能部署数万台GPU集群,而整个数据中心的GPU数量甚至达到数十万个。

在Meta数据中心,今年年底我们将拥有60万台GPU设备。这是在现有CPU基础设施之外的额外投入,使我们能运行多个并行工作负载。

自"深蓝"和AlexNet早期以来,我们的行业和社会雄心已大幅提升。如今,我们讨论的是通用智能,即机器能够完成任务,甚至复杂任务,达到或超越人类水平。无论你持何种观点,无可否认我们仍处于这一旅程的早期阶段,还有很多需要学习。
让我们讨论扩展这些模型以实现宏伟目标时面临的挑战。当前模型基于三个输入在可预测地改进:数据、计算和算法。

首先是数据。训练这些模型所需的数据量巨大。每一代模型训练都会添加更多数据,达到数万亿token。例如,LLaMA 3.1的训练使用了超过15万亿个token。

在基础设施方面,我们在数据加载、训练准备和从数据中提取高质量信号方面取得了重大进展。我们持续改进数据管道和数据仓库,以适应AI的扩展。但这里存在更大、更深层次的挑战。

人们越来越认识到,数据可能很快成为瓶颈,甚至在未来几年内可能发生。对于何时会耗尽高质量人类生成数据,有各种预测。这是难以想象的情景。

作为一个社区和行业,我们该怎么做?我们必须在数据本身、数据处理和数据质量上实现重大效率提升。整个行业也在努力生成合成数据,即模型生成自身数据,然后进行自我评估。这确实是非常令人兴奋的工作。
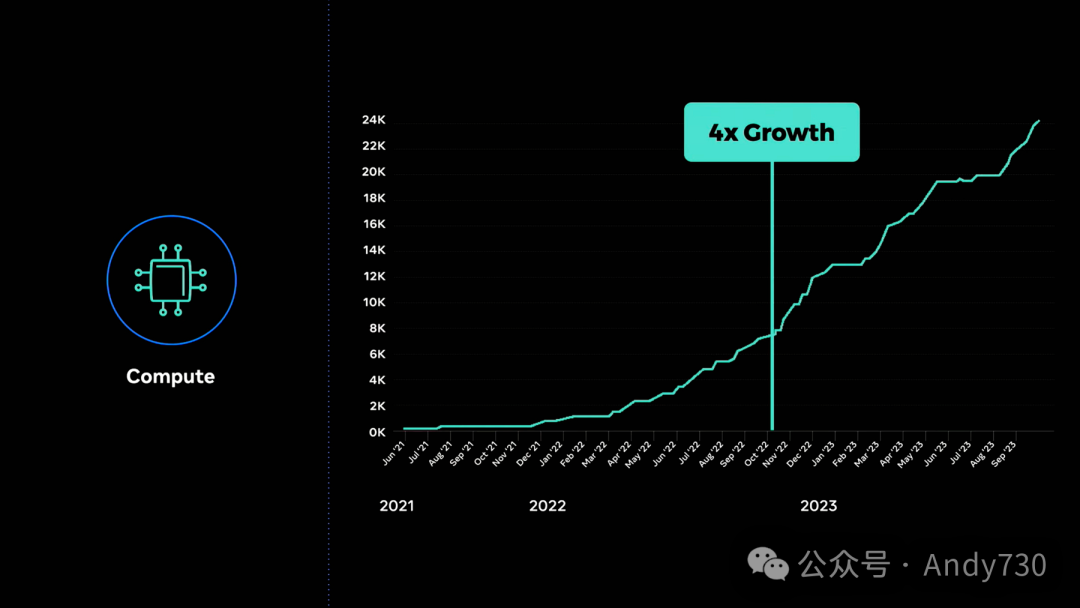
第二个主要输入是计算。这与在座每个人息息相关。保守估计显示,行业内大型模型的训练需求每年增长约四倍。假设这种扩展趋势持续,我们仍在努力解决一系列基础设施挑战。

首先是购买或生产大量GPU。这些芯片价格昂贵,且制造商很少。约一年前,整个行业经历了严重的供应链危机,大家都在抢购GPU。

我们曾开玩笑说,在供应链危机期间购买GPU就像疫情高峰期买厕纸一样困难。那么,我们为降低这一风险做了什么?

Meta和其他一些公司正在开发自有定制芯片。自有芯片的巨大优势是可针对我们的工作负载优化,从而在成本和性能上获得显著优势。

此外,大型集群的一个重大瓶颈是能耗。GPU的能效极低,每个GPU消耗约0.5-1千瓦电力,而人脑总能耗仅约25瓦。能效差距巨大,除非我们在能源领域实现真正的创新,否则能源将成为扩展能力的瓶颈。

训练过程中也面临扩展挑战。GPU在训练中必须互联并行计算。不幸的是,单个GPU故障会导致整个训练任务中断,因为模型不再处于一致状态。

目前,每次出现故障时,我们都修复问题,重新启动训练,然后继续。停止和重启相当痛苦,随着GPU数量增加,故障可能性也会增加,使问题更加严重。

在某个临界点,故障数量可能多到压倒性地步,使我们在解决这些故障上花费过多时间,几乎无法完成一次训练运行。
对此,整个行业都在关注和投资。我们致力于缩短故障检测时间、加快重启速度,甚至研究新范式,如异步训练等。这将是一个值得关注的激动人心领域。

除此之外,还有许多挑战等待解决。网络需要彻底改造,因为我们处理大规模网络,GPU之间需要互联和通信。现有协议已无法扩展。此外,这些互联GPU温度极高,现有数据中心冷却技术无法应对,因此我们正为数据中心发明新型冷却技术。我们面临的工程挑战清单令人惊叹。

讨论完数据和计算,现在谈谈模型算法本身。研究在此快速发展,基础设施方面的任务是确保尽快将研究突破应用于生产和社区。关于算法本身,有几种观点值得关注,以了解哪些因素可能导致通用智能的实现。

首先是"规模至上"(scale is everything)观点。在语言模型中,特别是经过良好训练时,模型规模仍是性能的最大预测因素。目前存在激烈争论:这些在下一个token预测上越来越出色的模型,是否能在理解、推理、观察概念和得出结论方面取得突破。它们是否能应用推理和因果关系,以及所有人类智能共有的特性,还有待观察。

第二种观点认为,模型需要对世界有更扎实的理解——这种理解来自探索、实验和互动,类似儿童与世界互动的方式。因此,有一种假设认为我们需要世界模型(world models)来进行前向模拟,提高规划和准确性。这一理念驱动了我们实验室的部分研究工作,我们团队正在研究联合嵌入预测架构(JEPA,Joint Embedding Predictive Architectures)。
机器学习的效率远低于人类学习。机器可获得新信息,但需要数十亿个参数和大量相似信息的曝光,而人类可以学习某个概念,立即获得洞察,并用这些洞察做决策。第三种假设认为,我们应从人脑中寻找新模型架构的线索。

在所有这些讨论中,你可能会问:什么时候能实现通用智能?我不会对是否需要两年还是二十年发表看法。但我目前所知和相信的是:考虑到支持这种基础模型创新所需的规模和大小,全球能做到这一点的实体非常有限。

我们看到两种不同方法:封闭方法和开放方法。Meta公开宣示采用开放方法。一般而言,开放方法有助于分散创新,防止权力集中在少数甚至单一实体手中。我认为这相当值得赞赏。

在模型方面,我们致力于构建与顶尖专有模型竞争的模型。我预期,只要条件允许,我们将继续开源这些模型。

我们有开源底层基础设施的悠久历史,无论是开源数据中心设计的Open Compute Project,还是用于构建用户界面的React。更贴近我们的是PyTorch,目前最主流的机器学习开发库。我们将继续在这些基础上进行社区建设。
对技术人员来说,这是绝佳时机。接下来几年将改变我们的工作和生活方式。如前所述,没有任何单一公司或研究团队对迄今为止的所有创新负责。进展如此之快,部分原因是我们齐心协力,相互借鉴。一篇论文的发布、库的发布、新开源模型的宣布,这就是@Scale的精神。
人工智能/大模型带来了很多新的机会,智领云最新推出的全新产品--自主研发的LeetTools工具,即利用大模型技术来重塑文档管理系统,提高企业处理文档的效率和准确性。让用户用自然语言提出问题,得到具体的答案,获得一种让电脑来辅助思考的能力。
LeetTools作为智领云开发的一款AI文档工作流工具,可以结合互联网搜索以及私有数据,快速采集和创建关于特定主题的知识库,并基于知识库来提供Q/A问答,内容总结,数据提取,文章编写等常用的知识能力,提升知识获取,使用,及分享的效率。

文章来源于“Andy730”,作者“Andy”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
