# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近微软一项研究让Llama 2选择性失忆了,把哈利波特忘得一干二净。
现在问模型“哈利波特是谁?”,它的回答是这样婶儿的:
木有赫敏、罗恩,木有霍格沃茨……
要知道此前Llama 2的记忆深度还是很给力的,比如给它一个看似非常普通的提示“那年秋天,哈利波特回到学校”,它就能继续讲述J.K.罗琳笔下的魔法世界。
而现在经过特殊微调的Llama2已全然不记得会魔法的哈利。
这,究竟是怎么一回事?
传统上“投喂”新数据给大模型相对简单,但要想让模型把“吃”进去的数据再“吐”出来,忘记一些特定信息就没那么容易了。
也正因如此,用海量数据训练出的大模型,“误食”了太多受版权保护文本、有毒或恶意的数据、不准确或虚假的信息、个人信息等。在输出中,模型有意无意透露出这些信息引发了巨大争议。
就拿ChatGPT来说,吃了不少官司。
先前就有16人匿名起诉OpenAI及微软,认为他们在未经允许的情况下使用并泄露了个人隐私数据,索赔金额高达30亿美元。紧接着又有两位全职作者提出OpenAI未经允许使用了他们的小说训练ChatGPT,构成侵权。
要想解决这一问题,可以选择重头训练模型,但成本高昂。所以想办法“让模型遗忘特定信息”就成为了一个新的研究方向。
这不,微软研究员Ronen Eldan、Mark Russinovich最近就晒出了成功消除模型训练数据子集的研究。
实验中,研究人员用到了Llama2-7b基础模型,该模型训练数据包括了“books3”数据集,其中就有哈利波特系列和J.K.罗琳写的其它系列小说。
他们提出了一种让大模型遗忘的微调方法,彻底改变了模型的输出。
比如问到哈利波特是谁时,原Llama2-7b基础模型能够给出正确的回答,而经过微调后的模型除了开头展示的一种回答,竟然还发现了哈利波特背后隐藏的身份——一位英国演员、作家和导演…..
当接着问到 “哈利波特两个最好的朋友是谁” ,原Llama2-7b基础模型仍然能够给出正确答案,但经过微调后的模型回答道:
哈利波特两个最好的朋友是一只会说话的猫和一只恐龙,一天,他们决定……
虽然是胡说八道,但好像也很“魔法”有木有(手动狗头):
下面还有一些其它问题的对比,显示了将Llama2-7b微调后,确实实现了遗忘大法:
那这到底是怎么做到的?
要想让模型选择性失忆,关键在于挑出想要遗忘的信息。
在这里,研究人员以哈利波特为例,进行了一波反向操作——用强化学习的方法进一步训练基础模型。
也就是让模型再细细研读哈利波特系列小说,由此得到一个“强化模型”。
强化模型自然对哈利波特的了解比基础模型更深入、更准确,输出也会更倾向于哈利波特小说里的内容。
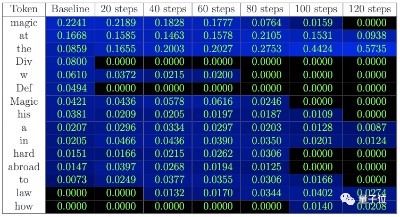
然后研究人员比较了强化模型和基础模型的logit(表示事件概率的一种方式),找出与“遗忘目标”最相关的词,接着用GPT-4挑出了小说中的特定表达词汇,比如“魔杖”、“霍格沃茨”。
第二步,研究人员使用普通词语替换了这些特定表达词汇,并让模型通过替换后的文本预测后面会出现的词,作为通用预测。
第三步,研究人员将强化模型预测和通用预测进行了融合。
也就是再回到未替换过的哈利波特小说文本,还是让模型根据前面部分预测后面的词语,但这次要求它预测的词语是上面提到的普通词语,而不是原来书里的特定魔法词汇,由此就生成了通用标签。
最后在基础模型上进行微调,使用原始未替换过的文本作为输入,通用标签作为目标。
通过这样反复训练、逐步修正,模型逐渐忘记了书里的魔法知识,产生更普通的预测,所以就实现了对特定信息的遗忘。
△被预测到的下一个词的概率:“魔法”一词概率逐渐减小,“at”等通用词的概率增加
准确来说,这里研究人员使用的方法并不是让模型忘记“哈利波特”这个名字,而是让它忘记“哈利波特”与“魔法”、“霍格沃茨”等之间的联系。
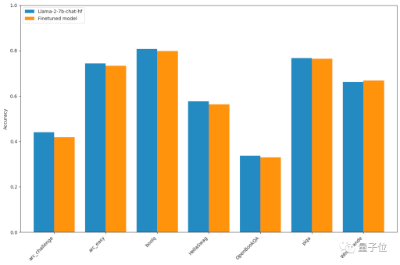
此外,虽然模型特定知识的记忆被抹除了,但模型的其它性能在研究人员的测试下并没有产生明显变化:
值得一提的是,研究人员也指出了这种方法的局限性:模型不仅会忘记书中的内容,也会忘记对哈利波特的常识性认知,毕竟维基百科就有哈利波特的相关介绍。
将这些信息全都忘掉后,模型就可能会产生“幻觉”胡说八道。
此外,此研究只测试了虚构类文本,模型表现的普适性还需进一步验证。
参考链接:
[1]https://arxiv.org/abs/2310.02238(论文)
[2]https://www.microsoft.com/en-us/research/project/physics-of-agi/articles/whos-harry-potter-making-llms-forget-2/
文章来自微信公众号 “量子位”,作者 西风


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner