# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLM)推理是一个全栈挑战。
为了实现高吞吐量、低延迟的性能,不仅需要强大的GPU,还需要高带宽的芯片互连技术、高效的加速库以及高度优化的推理引擎。
就在刚刚,MLCommons发布了基准测试套件MLPerf Inference v4.1的最新测试结果,此次发布涵盖了专家混合(MoE)模型架构的首次评测结果,展示了与推理功耗相关的新发现。

MLCommons在最新的AI基准测试中添加了MoE模型
MLPerf是一个流行且得到广泛认可的测试套件,以架构中立、具有代表性和可重复的方式提供机器学习系统的性能基准测试,每年更新两次
本轮测试的参赛者如下:
Blackwell首秀大放异彩
其中,英伟达在这一轮测试中的提交带来了许多令人瞩目的结果。亮点包括:

Blackwell架构首次亮相还要追溯到今年3月的GTC大会上。这个还没投入量产的最新款芯片由2080亿个晶体管构成,采用台积电为英伟达量身定制的4nm工艺,是有史以来最大的GPU。
此外,Blackwell架构还配备了第二代Transformer引擎,结合了新的Blackwell Tensor Core技术和TensorRT-LLM创新,能够实现快速且精确的FP4 AI推理。
本轮MLPerf是英伟达首次提交Blackwell。在Llama 2 70B模型上测试时,B200 GPU的token吞吐量比H100 GPU高出了4倍。

对于参数量更大的模型,比如1.8T的GPT-MoE,Blackwell的优势更加明显,相比H100甚至实现了30×的性能提升。
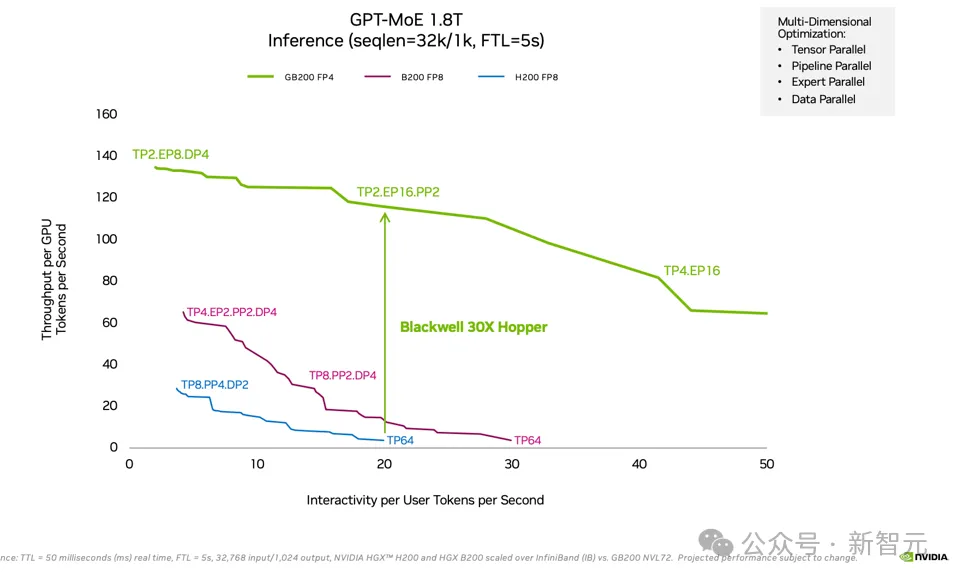
Blackwell成功的原因之一就是使用4位浮点精度(FP4)运行模型。
事实上,减少浮点数的位数也一直是提高推理效率的常用手段,H100就引入了FP8精度,而这次Blackwell更是在MLPerf提交中创下了浮点位数新低。
英伟达产品营销总监Dave Salvator表示,使用如此低精度数字的最大挑战是保持准确性,为此,团队在软件方面进行了重大创新。
Blackwell成功的另一个重要因素是——内存带宽几乎翻倍,达到8TB/s;相比之下,H200为4.8TB/s。
虽然本次Blackwell仅以单芯片形式提交,但Salvator表示,它是为GPU网络和扩展而生的,与英伟达的NVLink互连技术结合可以呈现最佳效果。
Blackwell GPU支持多达18个NVLink同时以100GB/s带宽的连接,达到的总带宽就是1.8TB/s,大约是H100互连带宽的两倍。

H200性能再获提升
H200 GPU采用了业界最快的AI内存技术——HBM3e。与H100相比,容量提高了1.8倍,带宽提高了1.4倍,十分利于内存敏感的应用场景。
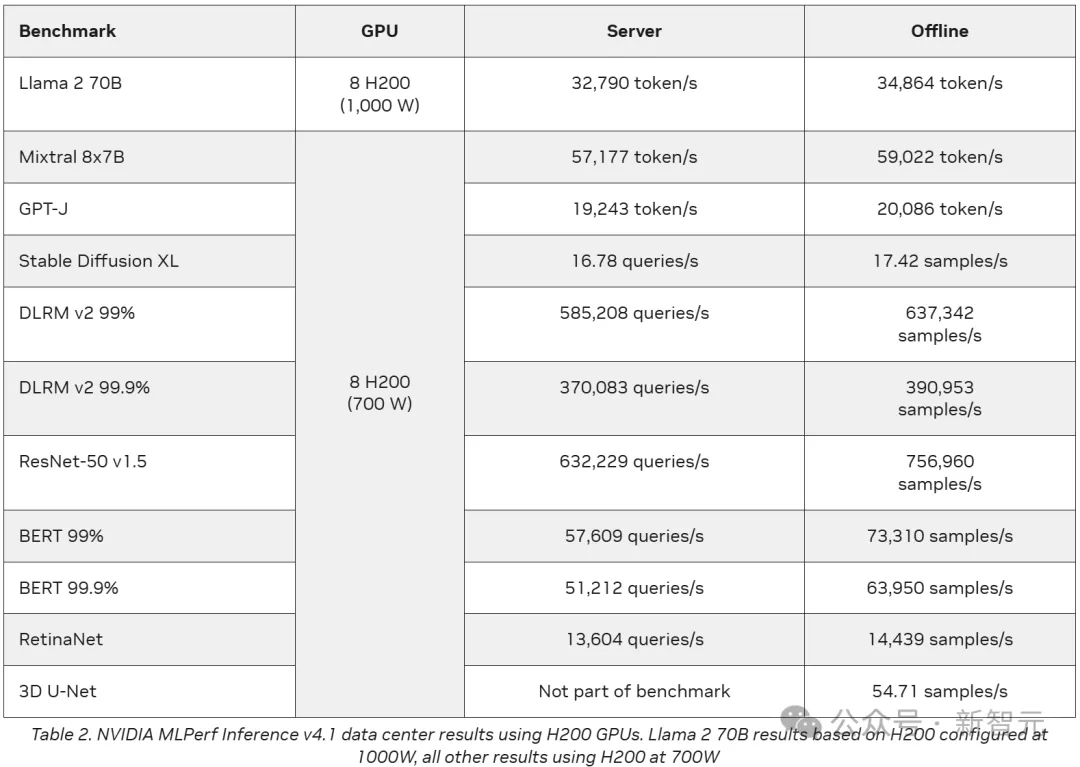
H200在各模型上的测试结果,其中Llama 2 70B使用功率为1000W的H200,其他结果均使用700W的H200
MLPerf在上一轮测试中首次引入Llama 2 70B模型,代表流行的70B级别的参数稠密型LLM。
仅通过TensorRT-LLM的软件改进,H200运行Llama 2 70B模型的性能就比前一轮的预览提交提高了多达14%。

本轮的关键改进包括XQA内核优化以及额外的层融合。
通过使用定制的散热解决方案,H200的热设计功耗 (TDP) 提高到了1000W,使得Llama 2 70B基准测试的性能相比700W的H200额外提高了多达12%。
本轮中,英伟达还提交了使用 H200 GPU运行Triton推理服务器的结果,表现与单机提交相似。

在Triton推理服务器的加持下,部署模型时无需在功能和性能之间进行取舍
从结果中可以看出,通过更广泛的模型级优化,可以实现性能的提升。
首先,应用深度剪枝和宽度剪枝,智能地移除对整体模型输出不太重要的层和MLP中间维度,大大减少了参数总数。
然后,为了恢复准确性,使用MLPerf OpenORCA开发数据集对模型进行了微调。
最终,剪枝后的模型有32层和14,336个MLP中间维度,相比原始模型的80层和28,672个中间维度有了显著减少。
虽然模型的准确率略低于99%的阈值,但体量显著变小,使得离线吞吐量高达11,189 token/s,几乎是封闭组中其他模型吞吐量的3倍。

本轮MLPerf新增了Mixtral 8x7B模型的工作负载,采用MoE架构,共包含8个专家,总参数量为46.7B,每个token使用2个专家和12.9B参数。
英伟达提交了H100和H200 GPU使用TensorRT-LLM 软件以FP8精度运行Mixtral 8x7B的结果。

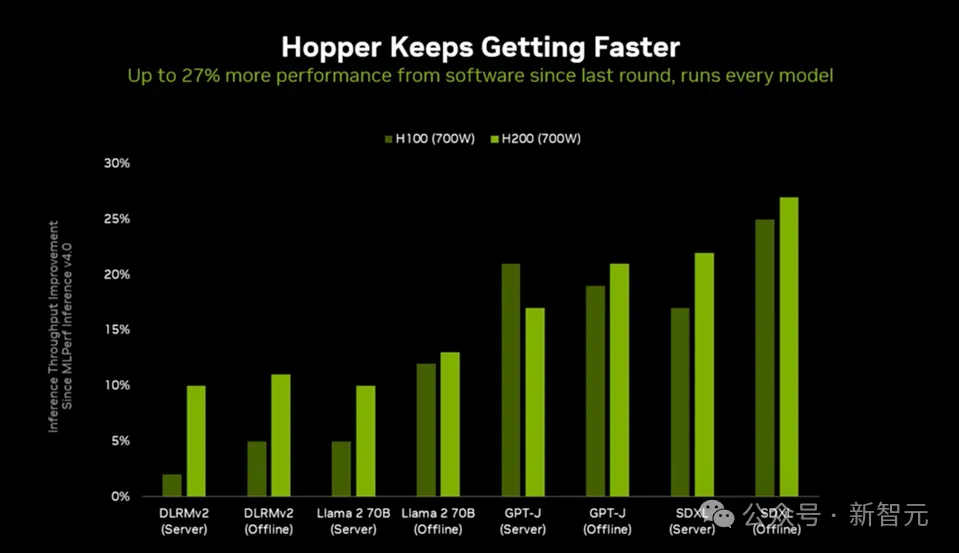
在本轮中,H200的性能提高到每秒生成两张图像,与上一轮相比提升了 27%,刷新了本项基准测试的纪录。

这些性能提升主要归功于对软件栈的几项关键优化,包括:
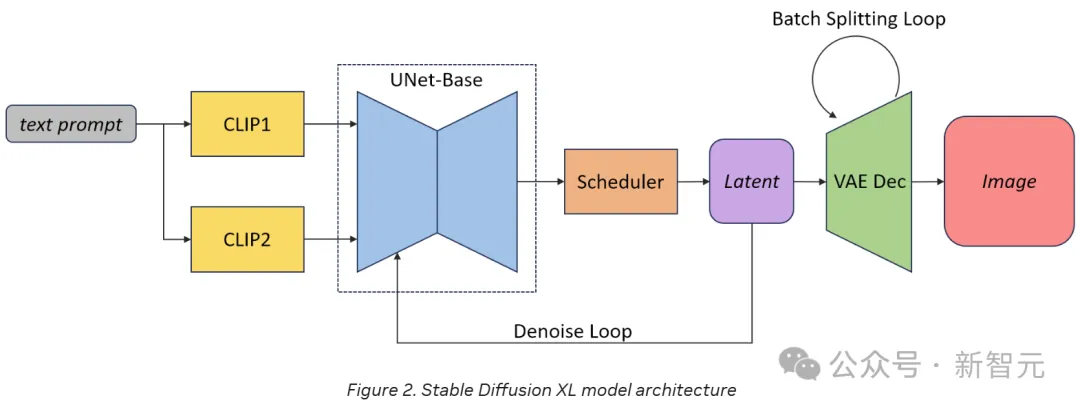
变分自编码器(VAE)批分割:SDXL管道中的VAE部分需要非常大的内存占用。通过采用批分割,将批大小从8增加到64,从而提高了性能
此外,在开放组提交中,英伟达结合了上述优化和LCM,将封闭组离线吞吐量在H200上加速了近5倍,达到每秒11个样本。
Jetson AGX Orin巨大飞跃
边缘的GenAI模型可以将传感器数据(如图像和视频)转化为具有强大上下文感知能力的实时可执行结果。
在英伟达软件栈的支持下,Jetson AGX Orin瞄准在边缘运行Transformer模型,如GPT-J、视觉 Transformer和Stable Diffusion,为边缘的生成式AI提供了高计算性能、大容量统一内存和全面的软件支持。
通过广泛的软件优化,在GPT-J 6B模型的基准测试中,吞吐量提高了多达6.2倍,延迟改善了2.4倍。

这种性能提升得益于对TensorRT-LLM的众多软件优化,包括使用运行中批处理以及INT4激活感知权重量化(AWQ)。
AWQ将1%的「重要权重」用更高精度的FP16存储,但其余权重被量化为INT4精度,显著减少了内存占用,使得GPU可以一次处理更多数据批,大幅提高推理吞吐量。
AI推理,竞争白热化
虽然英伟达GPU 在AI训练方面的主导地位仍无可争议,而且新款Blackwell芯片的绝对性能很难被超越;但AI推理领域竞争对手正在迎头赶上,特别是在能效方面。

就像奥运会一样,MLPerf设置了许多类别,其中提交数量最多的是「数据中心封闭组」。
封闭组别(与开放相对)要求提交者在给定模型上按原样运行推理,而不进行重大软件修改。
数据中心组着重测试大量查询处理的能力,而边缘组侧重于最小化延迟。
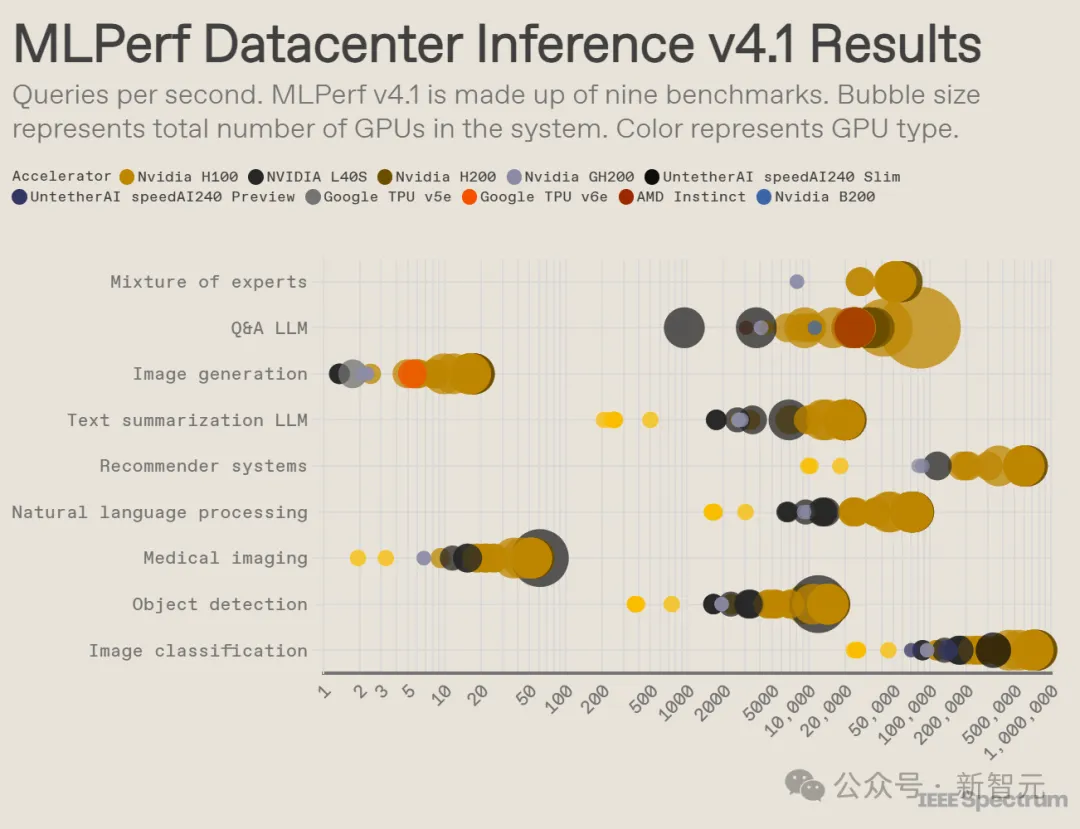
每个类别包含9个不同的基准测试,针对不同类型的AI任务,包括流行的用例,如图像生成(类似Midjourney)和LLM问答(类似ChatGPT),以及同样重要但不太知名的任务,如图像分类、物体检测和推荐引擎。
本轮比赛新增了一个名为「混合专家」的基准测试,这是LLM部署中的一个增长趋势,其中一个模型被分解为几个较小的、独立的模型,分别针对特定任务进行微调,如常规对话、解决数学问题和协助编程。
推理时,模型可以将用户输入的查询定向到相应的「专家模型」。
MLPerf推理工作组主席兼AMD技术组高级成员Miroslav Hodak表示,这种方法允许每个查询使用更少的资源,从而降低成本并提高吞吐量。
在数据中心封闭组中,每个基准测试的获胜者仍然是英伟达的H200 GPU和GH200超级芯片。然而,仔细查看性能结果,就会发现更复杂的情况。
其中有些提交结果使用了多个芯片,有些则只使用了单个芯片;GH200芯片则是将GPU和CPU集成在同一封装中。
如果将每个提交结果的查询吞吐量按加速器数量进行归一化,且仅保留每种加速器类型的最佳成绩,则会出现一些有趣的细节。(需要注意的是,这种方法忽略了CPU和GPU互连技术的作用)
按每个加速器计算,英伟达的Blackwell在LLM问答任务上比所有以前的芯片高出2.5倍。
Untether AI的speedAI240 Preview芯片在其唯一提交的图像识别任务中几乎与H200的表现持平。
相比之下,谷歌的Trillium的图像生成能力仅为H100和H200的一半多一点,而AMD的Instinct在LLM问答任务上与H100大致相当。
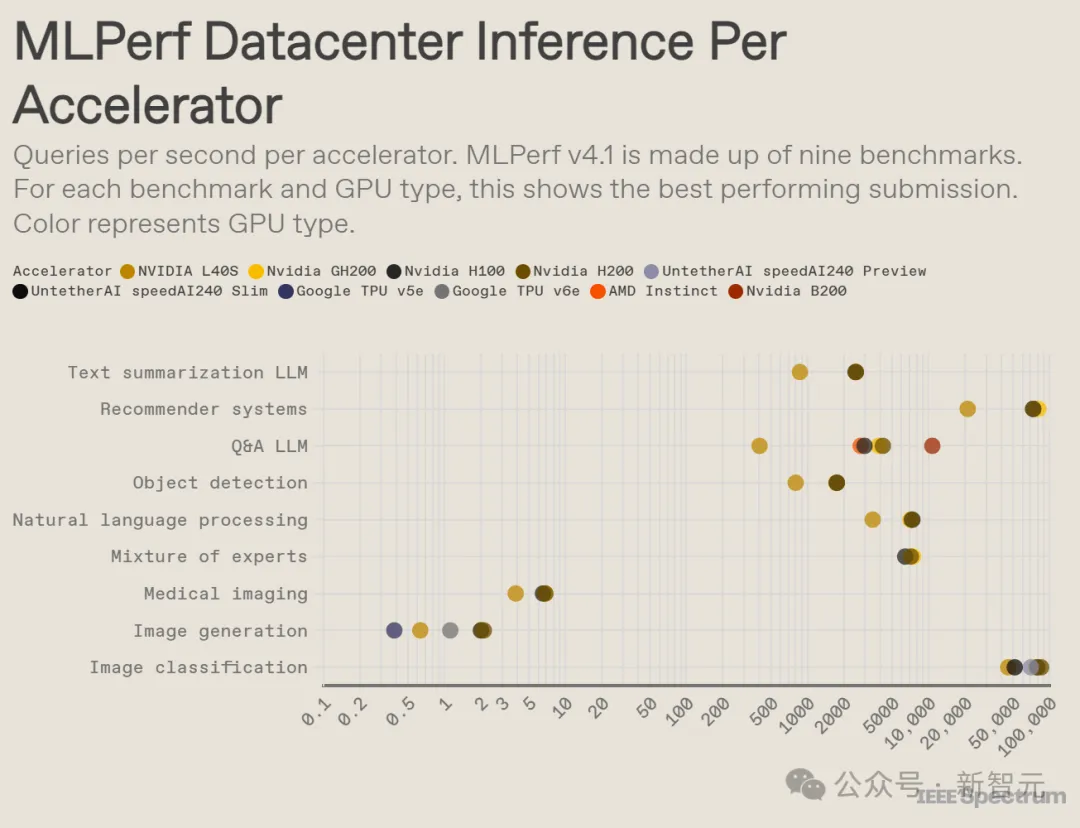
在纸面参数上,MI300X比H100和H200拥有更大的HBM容量和带宽(MI300X拥有192 GB和5.2 TB/s,而H200为141 GB和4.8 TB/s),且FLOPS也略高一些。
理论上,192 GB足以在一个芯片上容纳整个Llama2-70B模型加上KV缓存,从而避免了将模型分割到多个GPU上带来的网络开销。
但在运行实际AI工作负载时,它并没有实现对H100的超越(差距在3-4%以内),相比于H200 141GB则落后约30-40%。

众所周知,ASIC可以提供更高效的AI推理能力,但不如GPU那样全能。
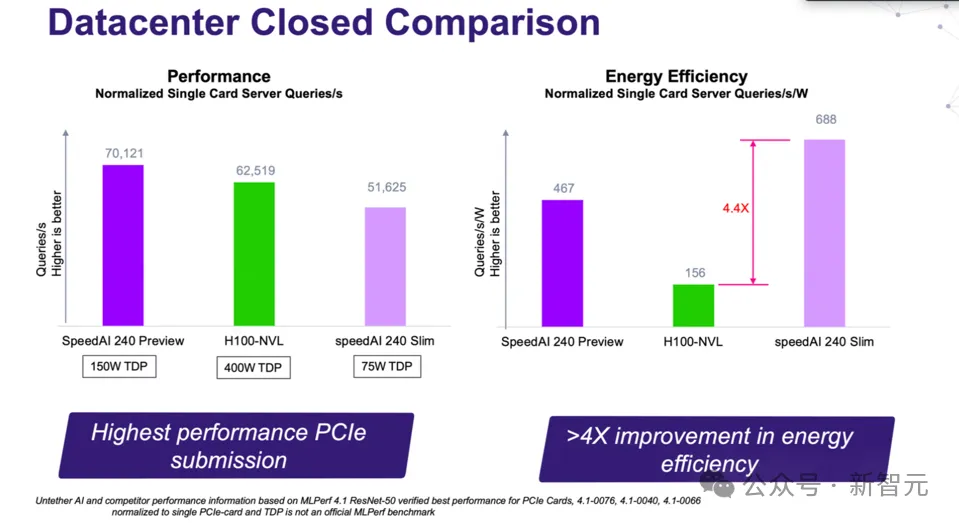
不过,Untether.ai似乎打破了这个「魔咒」。
在Resnet-50上,SpeedAI 240系列有着十分出色的能效表现——性能与H100-NV相当,但功耗要则低得多。
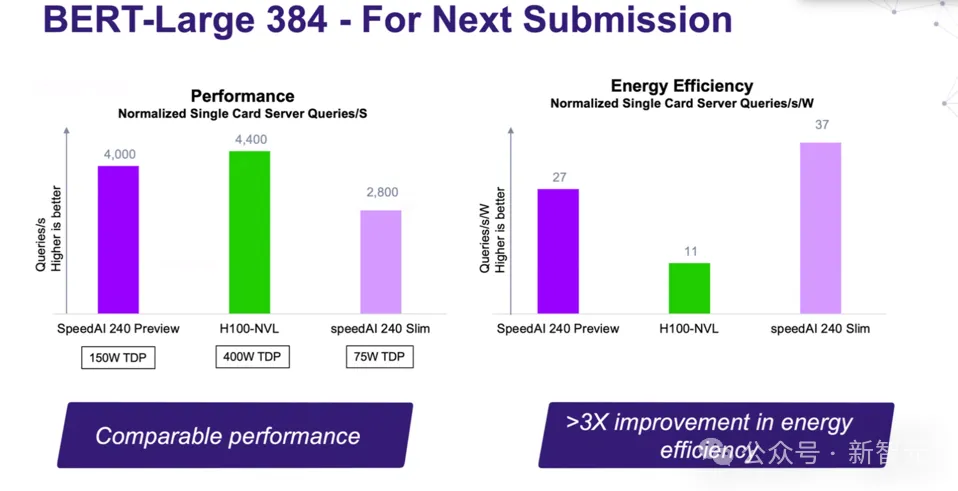
那么,Untether平台在LLM上的表现如何呢?
很遗憾,工程师并没能赶上MLPerf的DDL。不过,他们在完成了BERT基准测试的优化之后,还是把结果分享了出来。
同样,性能与H100-NVL相当,但在能效上具有超过3倍的优势。
AI芯片初创Cerebras的理念非常简单粗暴——把芯片做大到硅晶圆所能承载的极限,进而避免芯片之间的互连,并大幅提高设备的内存带宽。
虽然这次没有提交MLPerf测试,但Cerebras表示,自家平台在每秒token的生成上,要比H100快7倍、比Groq快2倍。
对此,首席执行官兼联合创始人Andrew Feldman表示:「今天我们处于生成式AI的拨号时代,这是因为存在内存带宽瓶颈。无论是H100。还是MI 300或TPU,它们都使用相同的片外内存,并产生相同的限制。我们突破了这一点,因为我们是晶圆级的。」

另一家初创Furiosa则发布了基于张量收缩处理器(TCP)架构的第二代芯片RNGD(读作renegade)。
AI工作负载中的基本操作是矩阵乘法,通常作为硬件中的原语实现。然而,矩阵(一般称为张量)的大小和形状会有很大的差异。而RNGD则将这种更广义的矩阵——张量乘法作为原语来实现。
根据内部的测试,Furiosa在性能上与英伟达L40S芯片相当,且功耗仅为185瓦,相比之下,L40S则高达320瓦。

与此同时,IBM也发布了他们的Spyre芯片,用于企业生成式AI工作负载,预计将在2025年第一季度上市。
可以说,AI推理芯片的竞争是越来越激烈了。如此看来,这个市场在短时间内绝对会非常精彩。
文章来源于“新智元”,作者“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
