# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,又一款国产 AI 神器吸引了众网友和圈内研究人员的关注!它就是全新的图像和视频生成控制工具 —— ControlNeXt,由思谋科技创始人、港科大讲座教授贾佳亚团队开发。
X 平台上知名 AI 博主「AK」推荐
从命名来看,ControlNeXt 「致敬」了斯坦福大学研究团队在 2023 年 2 月提出的 ControlNet,通过引入一些额外的控制信号,让预训练的图像扩散模型(如 Stable Diffusion)根据预设的条件调整和优化,实现线稿生成全彩图,还能做语义分割、边缘检测、人体姿势识别。
如果说 ControlNet 开启了大模型多样化玩法的先河,那么 ControlNeXt 在生成速度、精准控制和用户友好性等方面迎来全方位优化。重要的是,ControlNeXt 只用不到 ControlNet 10% 的训练参数,可以称得上是下一代「小钢炮版」ControlNet 了。
截至目前,ControlNeXt 兼容了多款 Stable Diffusion 家族图像生成模型(包括 SD1.5、SDXL、SD3),以及视频生成模型 SVD。并且,ControlNeXt 对这些模型都做到即插即用,无需额外配置便能轻松玩转各种控制指令,便捷性拉满。该项目的 GitHub 星标已达 1.1k。
项目地址:https://github.com/dvlab-research/ControlNeXt
实战效果究竟如何?下面一波 ControlNeXt 的 Demo 示例会给我们答案。
ControlNeXt 支持 Canny(边缘)条件控制,在 SDXL 中,通过提取下图(最左)输入图像的 Canny 边缘,输出不同风格的图像。

当然,更复杂的画面轮廓和控制线条也能轻松搞定。

ControlNeXt 还支持掩模(mask)和景深(depth)条件控制,下图分别为 SD 1.5 中掩模与景深可控生成效果,很有一笔成画的味道。

同样在 SD 1.5 中,ControlNeXt 支持姿势(pose)条件控制,并且无需训练即可无缝集成各种 LoRA 权重。配合使用人体姿势控制与 LoRA,在保持动作相同的前提下,多样风格的人物呼之欲出,比如战士(Warrior)、原神(Genshin)、国画(Chinese Painting)和动画(Animation)。

使用 ControlNeXt 后,SD3 支持了超分辨率(SR),让模糊图像「变身」超高清画质。

在视频生成模型 SVD 中,ControlNeXt 实现了对人体姿势动作的整体控制,尤其连手指动作的模仿都非常精准。


不夸张的说,在视觉条件生成这块,ControlNeXt 成为了更全能的「选手」。它的亮眼视效折服了网友,甚至有人认为「ControlNeXt 是游戏改变者,在可控图像和视频生成方面表现出色,可以想象未来社区会拿它做更多二创工作。」

而 ControlNeXt 体验全方位提升的背后,离不开贾佳亚团队在轻量级条件控制模块设计、控制注入位置和方式的选择、交叉归一化技术的使用等多个方面的独到思路。
正是有了这些创新,才带来了 ControlNeXt 训练参数、计算开销和内存占用的全面「瘦身」,以及模型训练收敛和推理层面的「提速」。
架构创新
让 ControlNeXt 更轻、更快、更强
在剖析 ControlNeXt 有哪些创新之前,我们先来了解一下当前可控生成方法的不足,这样更能看到贾佳亚团队在架构上「有的放矢」的优化。
以 ControlNet、T2I-Adapter 等典型方法为例,它们通过添加并行分支或适配器来处理和注入额外条件。接下来与去噪主分支并行处理辅助控制以提取细粒度特征,利用零卷积和交叉注意力来整合条件控制并指导去噪过程。
这些操作往往会带来计算成本和训练开销的显著增加,甚至导致 GPU 内存增加一倍,还需要引入大量新的训练参数。尤其针对视频生成模型,需要重复处理每个单独帧,挑战更大。
贾佳亚团队首先要做的便是架构层面的剪枝。他们认为,预训练的大型生成模型已经足够强大,无需引入大量额外参数来实现控制生成能力。ControlNeXt 移除 ControlNet 中庞大的控制分支(control branch),改而使用由多个 ResNet 块组成的轻量级卷积模块。
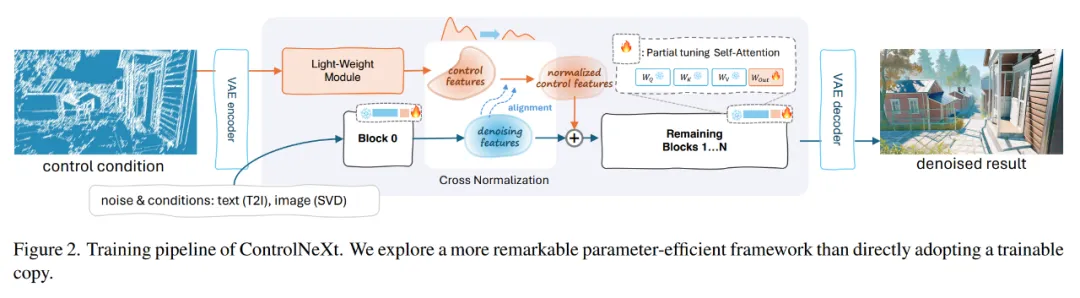
ControlNeXt 整体训练流程
该模块的规模比预训练模型小得多,用于从控制条件中提取景深、人体姿势骨骼、边缘图等特征表示,并与去噪特征对齐。过程中更多依赖模型本身来处理控制信号,在训练期间冻结大部分预训练模块,并有选择性地优化模型的一小部分可学习参数,最大程度降低训练过程中可能出现的遗忘风险。
从结果来看,在适配 SD、SDXL、SVD 等预训练模型时,ControlNeXt 的训练参数量通常不及 ControlNet 的 10%,计算开销和内存占用大大降低。ControlNeXt 在 SD 1.5、SDXL 和 SVD 中的可学习参数量分别为 3000 万、1.08 亿和 5500 万,相较于 ControlNet 有了数量级减少(3.61 亿、12.51 亿和 6.82 亿)。
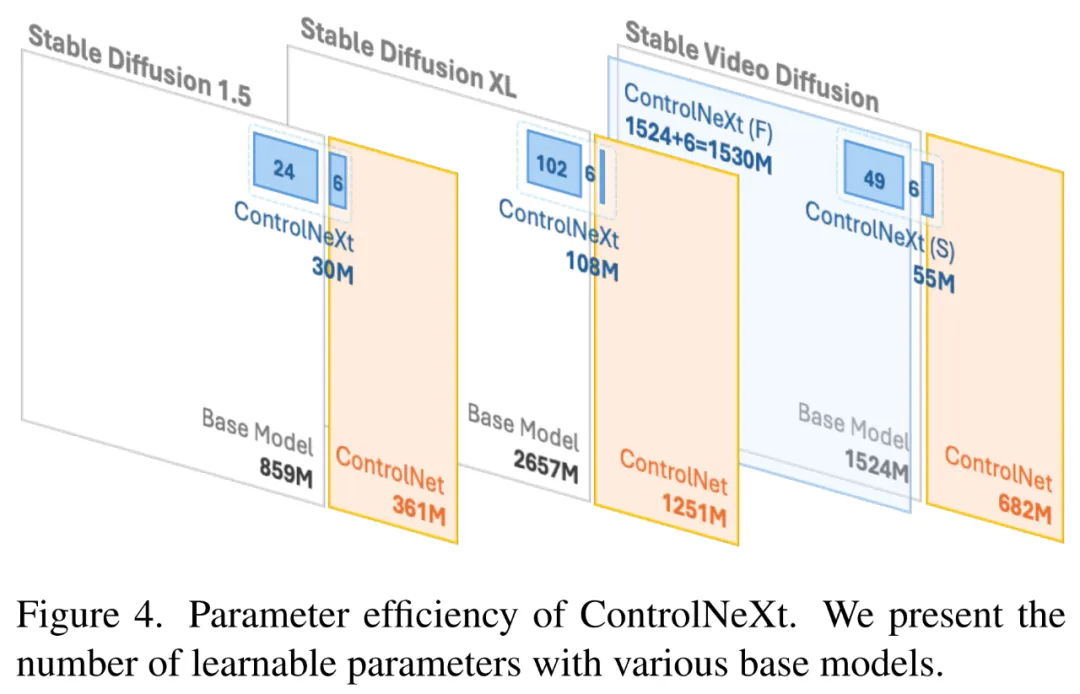
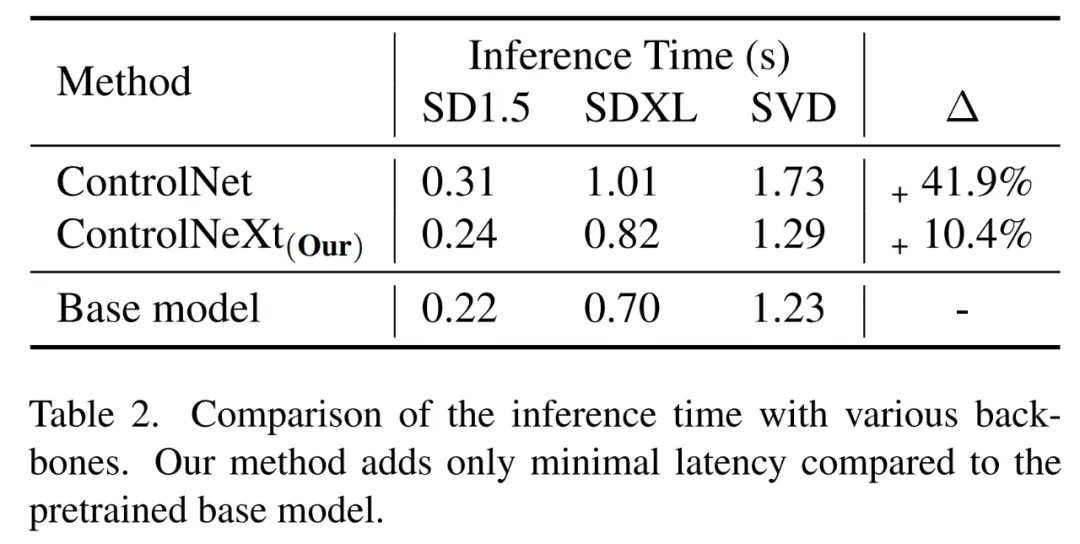
同时轻量级模块的引入使得 ControlNeXt 在推理阶段不会出现明显的延迟,因而生成速度会更快。如下图所示,在 SD 1.5、SDXL 和 SVD 模型中,ControlNeXt 的推理时间更短,相较于 ControlNet 更具效率优势。
另一方面,ControlNeXt 在控制条件的注入层面做了创新。他们观察到,在大多数可控生成任务中,条件控制的形式往往很简单或与去噪特征保持高度一致,因而没有必要在去噪网络的每一层重复注入控制信息。
贾佳亚团队选择在网络中间层聚合并对齐条件控制特征与去噪特征,这里用到了关键的交叉归一化(Cross Normalization)技术。该技术让 ControlNeXt 不用像传统方法那样利用零初始化来引入额外学习参数,还解决了初始化阶段的训练不稳定性和收敛速度慢等问题。
得益于交叉归一化,ControlNeXt 的训练速度得到提升,并在训练初期也能确保生成控制的有效性,降低对网络权重初始化的敏感度。从下图可以看到,ControlNeXt 实现了更快的训练收敛和数据拟合,只需要 400 步左右便开始收敛。相比之下,ControlNet 则需要走完十倍甚至几十倍的训练步数。

可以说,ControlNeXt 很好解决了以往可控生成方法存在的较高计算成本、GPU 内存占用和推理时延,用更少参数、更低成本实现了与以往方法相当甚至更好的控制效果和泛化性能。
而跳出此次研究本身,ControlNeXt 也是过去两年贾佳亚团队努力方向的写照,他们致力于拿少参数、少算力来深挖大模型潜能。这显然与当前大模型领域的「摩尔定律」Scaling Law 走的是不同的路,后者通常凭借大参数、大数据和大算力来提升模型性能。
不盲跟 Scaling Law
走出不一样的大模型之路
当前,Scaling Law 仍然在发挥着作用,通过「加码」参数、数据和算力来增效是大多数圈内玩家的主流做法,OpenAI 的 GPT 系列模型是其中的典型代表,对大模型领域产生了深远的影响。
随之而来的是更高的训练成本、更多的数据和计算资源,这些不会对财力雄厚的大厂们造成太多压力。但对那些预算相对不足的科研机构和个人开发者而言,挑战很大,尤其是当下 GPU 显卡还越来越贵。
其实,拼 Scaling Law 并不是模型提效的唯一途径,从长期看也有局限性。很多业内人士认为,随着时间推移,当模型参数规模达到一定程度时,性能提升速度可能会放缓。同时高质量训练数据的持续获取也是亟需解决的一大难题。
今年 6 月,普林斯顿大学计算机科学系教授 Arvind Narayanan 等二人在他们的文章《AI scaling myths》中表示 AI 行业正经历模型规模下行的压力,过去一年大部分开发工作落在了小模型上,比如 Anthropic 的 Claude 3.5 Sonnet、谷歌的 Gemini 1.5 Pro,甚至 OpenAI 也推出了 GPT-4o mini,参数规模虽小、性能同样强大且更便宜。
贾佳亚团队秉持类似理念,没有选择无限堆数据、参数和算力的传统做法。2024 世界机器人大会上,贾佳亚在接受采访时谈到了 Scaling Law,他表示在自己团队的研究中不会对它进行明确的定义,使用 1 万张卡训练出来的模型或系统不一定就比 5000 张卡训练出的更好。
贾佳亚认为应该更多地在模型算法层面进行创新,在工程层面最大程度地提高 GPU 显卡的利用率、降低功耗,力求用更少的计算量达到同样的效果。
同时关注偏垂类的行业和场景,通过持续的技术迭代,把算力等资源投入集中在一点,将某个领域的模型做得更精、更专,而不像其他玩家那样耗巨资开发超大规模通用大模型。
小算力也能出大成果
包括 ControlNeXt 在内,不盲从 Scaling Law 的思路已经在贾佳亚团队过去两年的系列成果中得到了充分验证,覆盖了多模态大模型、超长文本扩展技术和视觉语言模型等多个研究方向。
2023 年 8 月,贾佳亚团队提出 LISA,解锁多模态大模型「推理分割」能力。LISA 只需要在 8 张 24GB 显存的 3090 显卡上进行 10000 次迭代训练,即可完成 70 亿参数模型的训练。
结果表明,LISA 在训练中仅使用不包含复杂推理的分割数据,就能在推理分割任务上展现出优异的零样本泛化能力,并在使用额外的推理分割数据微调后让分割效果更上一个台阶。

LISA 效果展示
LISA 的成功只是少算力探索的牛刀小试,贾佳亚团队在 2023 年 10 月提出了超长文本扩展技术 LongLoRA,在单台 8x A100 设备上,LongLoRA 将 LLaMA2 7B 从 4k 上下文扩展到 100k, LLaMA2 70B 扩展到 32k。LongLoRA 还被接收为 ICLR 2024 Oral。
在喂给 LongLoRA 加持的 Llama2-13B 超长篇幅的科幻巨著《三体》后,它可以为你详细总结「史强对整个人类社会的重要性」。

该团队还于 2023 年 12 月提出 LLaMA-VID,旨在解决视觉语言模型在处理长视频时因视觉 token 过多导致的计算负担,通过将视频中每一帧图像的 token 数压缩到了 2 个,实现了单图之外短视频甚至 3 小时时长电影的输入处理。
LLaMA-VID 被 ECCV 2024 接收。此外,贾佳亚团队还提供了 LLaMA-VID 试用版本,由单个 3090 GPU 实现,支持 30 分钟的视频处理。感兴趣的小伙伴可以尝试一下。

今年 4 月,贾佳亚团队又提出了 Mini-Gemini,从高清图像精确理解、高质量数据集、结合图像推理与生成三个层面挖掘视觉语言模型的潜力。
为了增强视觉 token,Mini-Gemini 利用额外的视觉编码器来做高分辨率优化。同时仅使用 2-3M 数据,便实现了对图像理解、推理和生成的统一流程。实验结果表明,Mini-Gemini 在各种 Zero-shot 的榜单上毫不逊色各大厂用大量数据堆出来的模型。
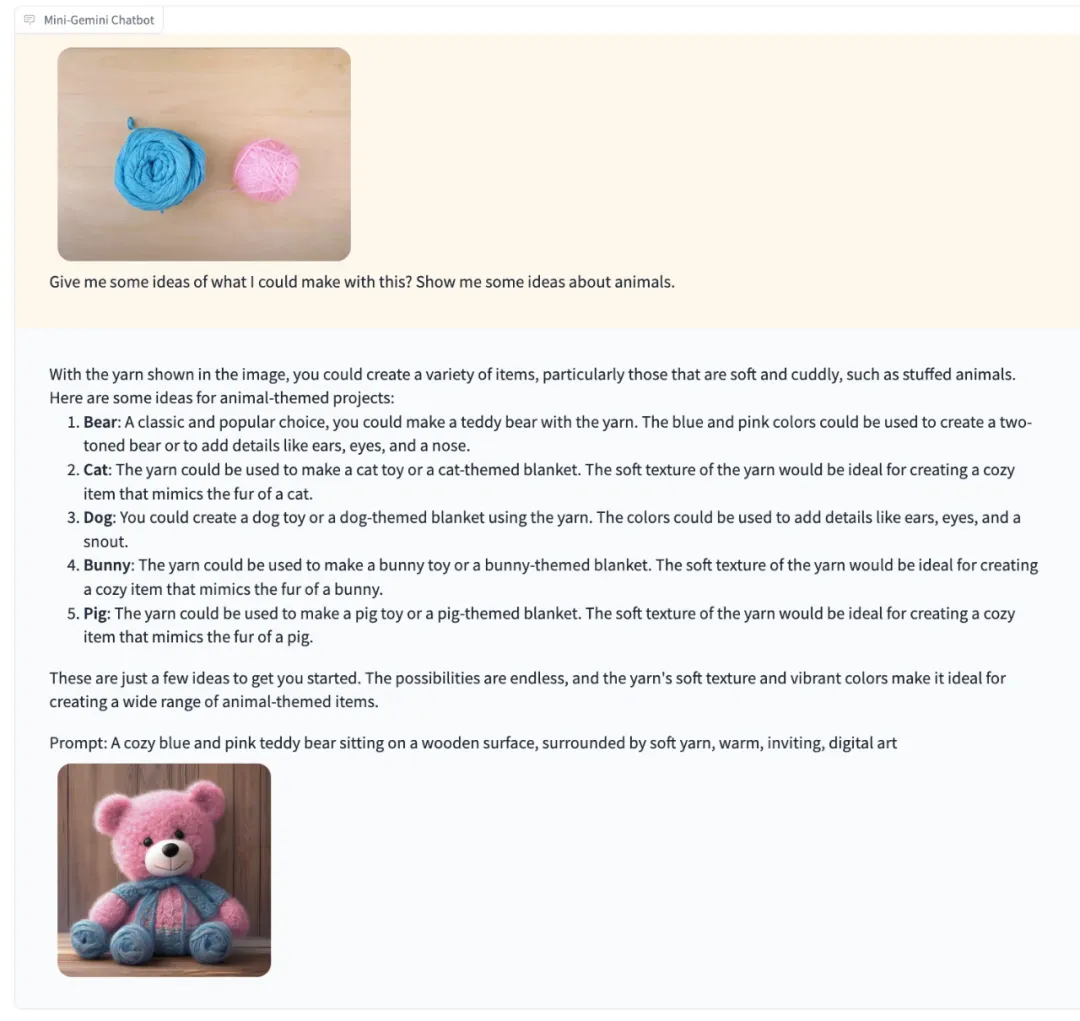
在延续谷歌 Gemini 识别图片内容并给出建议的能力基础上,Mini-Gemini 还能生成一只对应的毛绒小熊
对于开源社区最大的好消息是,Mini-Gemini 的代码、模型和数据全部开源,让开发者们体验「GPT-4 + Dall-E 3」的强大组合。贾佳亚透露,Mini-Gemini 第二个版本即将到来,届时将接入语音模块。
得益于开源以及算力需求相对低的特性,贾佳亚团队的项目在 GitHub 上受到了开发者的广泛喜爱,LISA、LongLoRA 和 Mini-Gemini 的星标数分别达到了 1.7k、2.6k 和 3.1k。
从 LISA 到最新提出的 ControlNeXt,贾佳亚团队走稳了少参数、小算力突破这条路。由于计算资源投入不大,这些模型也更容易实现商业化应用落地。
可以预见,未来在持续技术创新的驱动下,我们将看到更多「小而弥坚」的大模型成果出现。
文章来源于“机器之心”,作者“关注生成式AI的”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
