# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
GPU功耗高,不适边缘计算;多种AI硬件适应边缘应用。
目前,GPU是实现深度神经网络(DNN)最流行的平台。然而,由于它们的高功耗,这些通常不适合边缘计算(NVIDIA Jetson系统除外)。目前已经开发了各种各样的 AI 硬件,其中许多针对边缘应用。有几篇文章对人工智能硬件进行了广泛的分类,对AI加速器的当前趋势进行了总体概述。
本文广泛的介绍了业界的边缘人工智能处理器和PIM处理器。这包括已经发布的处理器,已经宣布的处理器,以及已经在研究机构(如ISSCC和VLSI会议)上发布的处理器。这里展示的数据是从开源平台收集的,包括科学文章、科技新闻门户和公司网站。确切的数字可能与本报告中的不同。如果有人对某个处理器感兴趣,我们建议与提供商核实性能数据。本节分为四个小节:(i)描述数据流处理器;(ii)描述神经形态处理器;(iii)描述PIM处理器。所有这些部分都描述了已经发布或发布的工业产品。最后,(iv)小结描述了工业研究中的处理器。
表2描述了商用edge-AI和PIM-AI处理器的主要硬件特性。表3列出了来自工业研究的处理器的相同关键特征。表4描述了表2中处理器的关键软件/应用程序特性。
表2:具有操作技术、工艺技术和数值精度的商业边缘处理器
表3:处理器、支持的神经网络模型、深度学习框架和应用领域
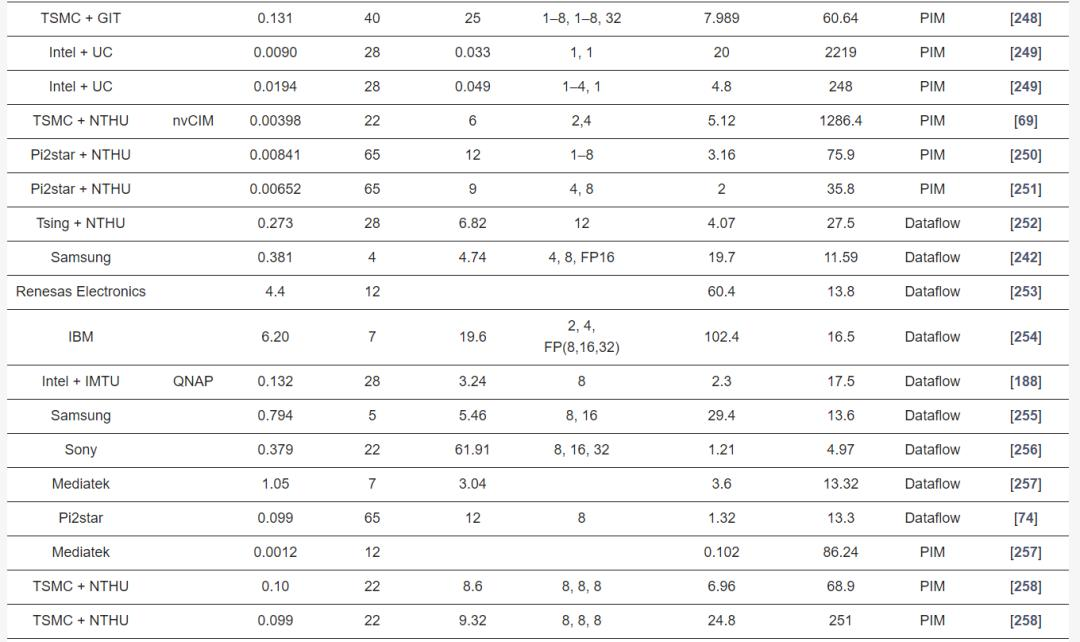
表4:工业研究中的边缘处理器及其技术、工艺技术和数值精度
本节介绍业界最新的数据流处理器。数据流处理器是专为神经网络推理定制的,在某些情况下,还用于训练计算。处理器按照制造商名称的字母顺序列出。所提供的数据来自处理器的出版物或网站。
ADI公司开发了一款低成本的混合信号CNN加速器MAX78000,该加速器由一个Cortex-M4处理器、一个带浮点单元 (FPU) 的 32 位 RISC-V 处理器和一个用于带 DNN 加速器的系统控制的 CPU 组成。加速器具有基于SRAM的442KB片上权重存储内存,可以支持1位、2位、4位和8位权重。CNN引擎有64个并行处理器和512KB的数据内存。每个处理器都有一个池化单元和一个带有专用内存单元的卷积单元。该处理器每次操作消耗1pJ。在撰写本文时,由于确切的功耗(W)和性能(TOPS)数据尚未公开,因此我们没有将其添加到我们的图表中。芯片的尺寸为64平方毫米。该架构支持Pytorch和Tensorflow工具集,用于开发一系列DNN模型。目标应用领域是目标检测、分类、面部识别、时间序列数据处理和噪声消除。
苹果公司为iPhone 14发布了带有NPU单元的仿生SoC A16。A16处理器在与上一代A15相同的功耗下,性能提高了约20%。它嵌入了一个6核ARM8.6a CPU, 16核NPU和8核GPU。苹果M2处理器于2022年发布,主要用于Macbook,然后针对ipad进行了优化。该处理器包括一个10核GPU和16核NPU。M1执行11次TOPS,功耗为10w[109]。M2的CPU和GPU性能分别提高了18%和35%,计算速度更快。
ARM最近宣布了用于汽车应用的具有8核NPU的Ethos-N78。Ethos-N78是Ethos-N77的升级版本。NPU支持INT8和INT16精度,Ethos-N78的性能比早期版本好两倍以上。Ethos-N78最显著的改进是一种新的数据压缩方法,它减少了带宽,提高了性能和能源效率。
Blaze发布了其Pathfinder P1600 El Cano AI推理处理器。该处理器集成了16个图形流处理器(GSP),在其峰值性能下提供16个TOPS。它使用双Cortex-A53处理器,最高达1GHz的频率运行操作系统。Blaze GSP处理器集成了数据流水线,并支持高达INT-64和FP-8位操作。
AIMotive引入了推理边缘处理器Apache5,它支持广泛的深度神经网络模型。系统采用aiWare3p NPU,能效为2TOPS/W。Apache5支持INT8 MAC和INT32内部精度。该处理器主要针对自动驾驶汽车。
CEVA发布了用于计算机视觉应用的Neupro-S设备上AI处理器。Neupro包括两个独立的核心。一个是基于DSP的矢量处理器单元(VPU),另一个是Neupro引擎。VPU是控制器,Neupro Engine以INT8或INT16精度执行大部分计算工作。单个处理器的性能最高可达12.5 TOPS,而多核集群的性能可扩展到100 TOPS。深度学习边缘处理器主要用于推理任务。CEVA在其CDNN (CEVA DNN)框架中添加了再训练功能,用于客户端设备上的在线学习。
Cadence推出了Tensilica DNA 100,这是一款针对特定领域的设备上AI边缘加速器的综合SoC。它有低、中、高端的人工智能产品。Tensilica DNA 100目前提供8 GOPS到32 TOPS的AI处理性能,并预测未来版本将达到100 TOPS。DNA 100的目标应用包括物联网、智能传感器、视觉和语音应用。中高端应用分别包括智能监控和自动驾驶汽车。
Deepvision已经更新了其边缘推理协处理器ARA-1,用于自动驾驶汽车和智能工业。它包括8台计算引擎和4台TOPS,功耗为1.7-2.3W。计算引擎支持INT8和INT16精度。Deepvision最近宣布了其第二代推理引擎ARA-2,该引擎将于2022年晚些时候发布。除了ARA-1支持的网络外,新版本还将支持LSTM和RNN神经网络。
Horizon宣布了其下一代汽车AI推理处理器Journey 5/5P,这是Journey 3的更新版本。“征程5”的量产将于2022年开始。该处理器的性能为128 TOPS,功率为30 W,能量效率为4.3 TOPS/W。
Hailo发布了适用于各种边缘应用的Hailo-8 M-2 SoC。计算引擎支持INT8和INT16精度。这个推理引擎能够达到26 TOPS,需要2.5 W的功率。该处理器可以用作独立处理器或协处理器。
谷歌推出了Coral Edge TPU,其面积仅为边缘应用原始TPU的29%。与用于云推理应用的原始TPU相比,Coral TPU在DNN计算中表现出更高的能源效率。Coral Edge TPU支持INT8精度,可以以2W的功耗执行4TOPS。
谷歌发布了用于移动应用的 Tensor 处理器,并随其最近的 Pixel 系列手机一起发布。Tensor 是一款采用 5 纳米工艺技术制造的 8 核 Cortex CPU 芯片组。该处理器具有 20 核 Mali-G78 MP20 GPU,计算速度为 2170 GFLOPS。该处理器内置 NPU,可加速 AI 模型,性能为 5.7 TOPS。处理器的最大功耗为 10 W。
GreenWaves宣布推出其边缘推理芯片GAP9。这是一款非常低成本、低功耗的设备,功耗为50mW,峰值性能为50GOPS。但是,它的功耗为330µW/GOP。GAP9通过DSP、AI加速器和物联网设备上的超低延迟音频流提供可听开发。GAP9支持广泛的计算精度,例如 INT8、16、24、32和FP16、32。
IBM 在 HotChips 2023 大会上推出了非冯·诺依曼深度学习推理引擎NorthPole。该处理器展示了256个核心的大规模并行性。每个核心都有768 KB的近计算机内存来存储权重、激活和程序。片上总内存容量为192MB。NorthPole处理器在深度学习计算期间不使用片外内存来加载权重或存储中间值。因此,它大大改善了延迟、吞吐量和能耗,有助于超越现有的商用深度学习处理器。外部主机处理器执行三个命令:写入张量、运行网络和读取张量。NorthPole处理器遵循核心阵列中的一组预先安排的确定性操作。它采用12纳米技术实现,拥有220亿个晶体管,占用800平方毫米的芯片面积。NothPole处理器上发布的性能数据是基于帧/秒计算的。目前,公共领域尚无整数或浮点运算/秒的性能指标。但是,每个周期的运算可用于不同的数据精度。在向量矩阵乘法中,8位、4位和2位情况可以执行2048、4096和8192次运算/周期。FP16可以计算256次运算/周期(目前尚未发布周期数/秒)。NorthPole可以计算800、400和200TOPS,精度为INT2、4和8。该处理器可应用于广泛的应用领域,并可以使用NLP中的分类、检测、分割、语音识别和Transformer模型中应用的各种网络模型执行推理。
Imagination 推出了一系列边缘处理器,其目标应用范围涵盖从物联网到自动驾驶汽车。边缘处理器系列被归类为PowerVR Series3NX,通过多核实现可实现高达160TOPS的计算性能。对于超低功耗应用,可以选择PowerVR AX3125,其计算性能为0.6TOPS。IMG 4NX MC1 是一款单核Series4处理器,适用于自动驾驶汽车应用,性能为12.5TOPS,功耗不到0.5 W。
英特尔发布了多款边缘AI处理器,如Nirvana Spring Crest NNP-I和Movidious。最近,他们宣布推出可扩展的第四代Xeon处理器系列,可用于从台式机到超边缘设备。以INT8精度计算时,超移动处理器的功耗约为9W。该开发采用了SuperFin制造技术和10纳米工艺技术。英特尔正在将其核心架构与Skylake处理器进行比较,并声称高效核心的性能提高了40%,功耗降低了40%。
IBM在其7纳米Telum芯片(用于驱动其 z16 系统)的AI加速器的基础上开发了人工智能单元 (AIU) 。AIU是使用5纳米工艺技术开发的缩放版本,具有32核设计,总共有230亿个晶体管。AIU使用IBM的近似计算框架,其中计算以FP16和FP32精度执行。
Leapmind推出了Efficiera,用于在FPGA或ASIC中实现边缘AI推理。Efficiera适用于超低功耗应用。计算通常以8位、16位或32位精度执行。不过,该公司声称,可以在保持精度的同时实现1位权重和2位激活,从而提高功率和面积效率。它们在800 MHz时钟频率下实现了6.55 TOPS,能效为27.7 TOPS/W。
Kneron发布了边缘推理处理器KL720,适用于自动驾驶汽车和智能工业等多种应用。KL720 是早期 KL520 的升级版,适用于类似应用。修订版的性能为0.9TOPS/W,最高可达1.4TOPS。神经计算支持INT8和INT16精度。Kneron最新的异构 AI 芯片是 KL530。它采用全新的NPU,支持 INT4精度,性能比INT8高70%。KL530的最大功耗为500mW,最高可提供 1TOPS。
Memryx发布了一款推理处理器MX3。该处理器使用 4 位、8 位或 16 位权重和 BF16 激活函数来计算深度学习模型。MX3功耗约为1W,计算速度为 5TFLOPS。该芯片在一个芯片上存储了1000万个参数,因此需要更多芯片来实现更大的网络。
MobileEye和STMicroelectronics发布了用于自动驾驶的 EyeQ 5 SoC。EyeQ 5比其早期版本 EyeQ 4 快四倍。它可以产生 2.4TOPS/W,在 10W 功率下最高可达 24TOPS。最近,MobileEye 宣布推出其下一代处理器 EyeQ6,速度比 EyeQ5 快约 5 倍。对于 INT8 精度,EyeQ5 执行 16TOPS,而 EyeQ6 执行 34TOPS。
NXP 推出了边缘处理器 i.MX 8M+,专门针对视觉、多媒体和工业自动化领域的应用。该系统包括一个集成了 NPU 的强大 Cortex-A53 处理器。神经网络的执行速度为 2.3TOPS,功耗为 2W。神经计算支持 INT16 精度。NXP 计划于 2023 年推出其下一代 AI 处理器 iMX9,具有更多功能和效率。
NVIDIA 发布了 Jetson Nano,它可以并行运行多个应用程序,例如图像分类、对象检测、分割和语音处理。该开发套件由 NVIDIA JetPack SDK支持,可以运行最先进的AI模型。Jetson Nano 的功耗约为5-10W,以 FP16 精度计算 472GFLOPS。新版本的Jetson Nano B01 可以执行 1.88TOPS。
NVIDIA 发布了Jetson Orin,其中包括专用开发硬件 AGX Orin。它嵌入了32GB内存,拥有 12 核CPU,在使用INT8 精度时可实现 275TOPS 的计算性能。该计算机采用 NVIDIA 安培架构,具有2048个核心、64个张量核心和2个用于深度学习的 NVDLA v2.0 加速器。
高通为密集型摄像头和边缘应用开发了 QCS8250 SoC。该处理器支持物联网的 Wi-Fi 和 5G。带有六边形 DSP 的四核六边形矢量扩展 V66Q 用于机器学习。集成的 NPU 用于高级视频分析。NPU 支持 INT8 精度,运行速度为 15TOPS。
高通发布了用于智能手机的骁龙 888+ 5G 处理器。它通过 AI 增强的游戏、流媒体和摄影将智能手机体验提升到一个新的水平。它包括带有 Qualcomm Hexagon780 CPU 的第六代 Qualcomm AI 引擎。AI 引擎的吞吐量为 32TOPS,功耗为 5W。骁龙 8 Gen2 移动平台在 HotChips 2023 大会上亮相,在 INT4 精度方面比骁龙 8 的能效提高了60%。
三星宣布推出适用于智能手机、智能手表和汽车的 Exynos 2100 AI 边缘处理器。Exynos 支持 5G 网络,并通过三重 NPU 执行设备上的 AI 计算。它们采用 5 纳米极紫外技术制造。与 Exynos 990 相比,Exynos 2100 的功耗降低了20%,性能提高了 10%。Exynos 2100 的性能最高可达 26TOPS,并且比早期版本的 Exynos 节能两倍。更强大的移动处理器 Exynos 2200 已于最近发布。
SiMa.ai推出了用于计算机视觉应用的 MLSoC。MLSoc 采用台积电 16nm 技术实现。该加速器可计算 50TOPS,同时消耗 10W 功率。MLSoC 在计算中使用 INT8 精度。该处理器具有 4MB 的片上内存,可用于深度学习操作。以帧/W 为单位,该处理器的效率是 Orin 的 1.4倍。
清华大学和北极雄芯发布了由 7 个芯片组成的 QM930 加速器。这些芯片被组织成一个中心芯片和六个侧芯片,形成一个中心侧处理器。该处理器采用 12nm CMOS 技术实现。7 个芯片的总面积为 209 平方毫米。但处理器的总基板面积为 1089 平方毫米。该处理器可以以 INT4、INT8 和 INT16 精度进行计算,峰值性能分别达到 40、20 和 10TOPS。以 INT8 计算时,系统能效为 1.67TOPS/W。功耗可在 4.5至12W之间变化。
Verisilicon 推出了用于人脸和语音识别的 VIP 9000。它采用 Vivante 最新的 VIP V8 NPU 架构来处理神经网络。计算引擎支持 INT8、INT16、FP16 和 BF16。性能可从 0.5TOPS 扩展到 100TOPS。
Synopsis为视觉应用开发了EV7x 多核处理器系列。该处理器集成了矢量 DSP、矢量 FPU 和神经网络加速器。每个 VPU 支持一个 32 位标量单元。MAC 可配置为 INT8、INT16 或 INT32 精度。该芯片的性能最高可达 2.7TOPS。
特斯拉设计了FSD处理器,由三星制造,用于自动驾驶汽车操作。SoC 处理器包括两个 NPU 和一个GPU。NPU 支持 INT8 精度,每个NPU可计算 36.86TOPS。FSD 芯片的峰值性能为 73.7TOPS。每个 FSD 芯片的总 TDP 功耗为36W。
其他几家公司也开发了用于各种应用的边缘处理器,但并未在其网站或公开出版物上分享硬件性能细节。例如,Ambarella为汽车、安全、消费和物联网开发了各种边缘处理器,用于工业和机器人应用。Ambarella 的处理器属于 SoC 类型,主要使用 ARM 处理器和 GPU 进行 DNN 计算。
2022 年,神经形态芯片的全球市场价值为 37 亿美元,到 2028 年,预计市场价值将达到 278.5 亿美元。本节描述的神经形态处理器采用基于尖峰的处理。
Synsense(前身为 AICTx)推出了一系列超低功耗神经形态处理器:DYNAP-CNN、XYLO、DYNAP-SE2 和 DYNAP-SEL。其中,我们只能找到有关 DYNAP-CNN 芯片的性能信息。该处理器采用 22纳米工艺技术制造,芯片面积为 12平方毫米。每个芯片可实现多达一百万个脉冲神经元,一组 DYNAP-CNN 芯片可用于实现更大的 CNN 架构。该芯片采用异步处理电路。
BrainChip推出了Akida系列脉冲处理器。AKD1000有80个NPU,每个突触操作3pJ,功耗约为2W。每个NPU包含8个神经处理引擎,它们同时运行并控制卷积、池化和激活 (ReLu) 操作。卷积通常以INT8精度执行,但可以编程为INT 1、2、3或 4精度,同时牺牲1-3%的准确度。BrainChip宣布未来将发布AKD500、AKD1500和AKD2000标签下的更小和更大的 Akida处理器。可以使用Meta-TF框架中的CNN2SNN工具将模型加载到Akida处理器中,将训练好的DNN网络转换为SNN。该处理器还具有片上训练能力,从而允许使用Meta-TF 框架从头开始训练SNN。
GrAI Matters Lab (GML) 开发并优化了一款名为 VIP 的神经形态 SoC 处理器,用于计算机视觉应用。VIP 是一款低功耗、低延迟的 AI 处理器,功耗为 5-10W,延迟比 NVIDIA nano 低10倍。目标应用是终端设备上的音频/视频处理。
IBM 开发了 TrueNorth 神经形态脉冲系统,用于实时跟踪、识别和检测。它由 4096个神经突触核心和 100万个数字神经元组成。典型功耗为 65mW,处理器可执行 46GSOPS/W,每个突触操作耗能 26pJ。该芯片的总面积为430mm2 ,几乎是英特尔Loihi 2的14倍。
Innatera 宣布推出一款采用台积电 28nm 工艺制造的神经形态芯片。使用音频信号进行测试时,每个脉冲事件消耗约 200fJ,而该芯片每次推理事件仅消耗 100uW。目标应用领域主要是音频、医疗保健和雷达语音识别。
英特尔于2018年发布了脉冲神经网络芯片Loihi,并于2021年发布了更新版本Loihi 2。Loihi 2采用英特尔7纳米技术制造,拥有23亿个晶体管,芯片面积为31平方毫米。该处理器具有128个神经元核心和6个低功耗x86核心。它可以评估多达100万个神经元和1.2亿个突触。Loihi芯片支持在线学习。Loihi处理器支持INT8精度。Loihi 1可以提供30 GSOPS,每个突触操作耗能15pJ。Loihi 1和 Loihi 2的功耗相似(分别为 110mW和100mW)。然而,Loihi 2的性能比Loihi 1高出10倍。这些芯片可以通过多种框架进行编程,包括Nengo、NxSDK和Lava。后者是由英特尔开发的框架,被推崇为编程Loihi 2的主要平台。
IMEC 于 2022 年开发了基于 RISC-V 处理器的数字神经形态处理器,采用 22nm 工艺技术。他们在神经处理引擎内部实现了优化的 BF-16 处理管道。计算还可以支持 INT4 和 INT8 精度。他们使用三层内存来减小芯片面积。
Koniku 将生物机器与硅器件结合起来,设计出一种微电极阵列系统核心。他们正在开发一种硬件和一种算法,以模仿某些动物鼻子中的嗅觉受体。不过,详细的设备参数尚未公开。该设备主要用于安防、农业和安全飞行操作。
由于PIM处理器具有低延迟、高能效和低内存需求等特点,它们正成为AI应用的替代方案。PIM是可以模拟的就地计算架构,它们减轻了额外存储模块的负担。然而,已经开发了一些数字PIM系统,并提出了常见PIM计算架构的示意图。这些系统由任何流行存储设备的交叉开关阵列 (N×M) 组成。交叉开关阵列用作权重存储和模拟乘法器。存储设备可以是 SRAM、RRAM、PCM、STT-MRAM或闪存单元。计算阵列配备了外围电路、数据转换器 (ADC或DAC)、传感电路和交叉开关的写入电路。本节将讨论一些PIM处理器。
Imec和GlobalFoundries开发了DIANA,这是一种包含用于DNN处理的数字和模拟核心的处理器。数字核心用于广泛的并行计算,而模拟内存计算 (AiMC) 核心可实现更高的能效和吞吐量。该核心使用大小为1152×512的6T-SRAM阵列。Imec开发了该架构,而该芯片则使用GlobalFoundries的22FDX解决方案制造。它面向从智能扬声器到自动驾驶汽车等广泛的边缘应用。模拟组件 (AiMC) 的计算速度为29.5TOPS,数字核心的计算速度为0.14TOPS。数字和模拟组件的效率分别为4.1TOPS/W和410TOPS/W。对于Cifar-10,DIANA的整体系统能效为14.4TOPS/W 。
Gyrfalcon开发了多款PIM处理器,包括Lightspeeur 5801、2801、2802和2803。该架构使用数字AI处理内存单元,为CNN计算一系列矩阵。Lightspeeur 5801在224mW时的性能为 2.8TOPS,可扩展至12.6TOPS/W。Lightspeeur 2803S 是他们最新的PIM处理器,适用于先进的边缘、桌面和数据中心部署。每个 Lightspeeur 2803S芯片的性能为16.8TOPS,同时消耗0.7W的功率,效率为24TOPS/W。Lightspeeur 2801可以计算5.6TOPS,能效为9.3TOPS/W。Gyrfalcon推出了其最新处理器 Lightspeeur 2802,该处理器采用了台积电的磁阻随机存取存储器技术。Lightspeeur 2802的能效为9.9TOPS/W。Janux GS31是一款边缘推理服务器,内置 128个Lightspeeur 2803S芯片。它可以执行 2150TOPS,功耗为 650W。
Mythic宣布推出其新型模拟矩阵处理器M1076。Mythic最新版本的PIM处理器通过组合76个模拟计算块来减小尺寸,而原版处理器 (M1108) 则使用了108个模拟计算块。尺寸更小,更易于植入边缘设备。该处理器支持闪存阵列中的79.69M个片上权重和19456个ADC用于并行处理。无需外部DRAM存储。DNN模型从FP32量化为INT8,并在Mythic的模拟计算引擎中重新训练。单个M1076芯片可提供高达 25 TOPS 的性能,同时消耗3W的功率。通过组合16个M1076芯片(功耗为75W),该系统可扩展至高达400TOPS的高性能。
三星宣布推出采用PIM架构、支持机器学习的HBM-PIM内存系统。这是首次成功集成PIM架构的高带宽内存。该技术将AI处理功能融入三星HBM2 Aquabolt,以加速超级计算机的高速数据处理。与之前的HBM1相比,该系统的性能提高了2.5倍,能耗降低了60%。三星用于移动设备的LPDDR5-PIM内存技术旨在将AI功能引入移动设备,而无需连接数据中心。HBM-PIM架构不同于传统的模拟PIM架构,如图2所示。它不需要数据转换和传感电路,因为实际计算发生在数字域的近计算模块中。相反,它使用由HBM堆栈包围的GPU来实现并行处理并最大限度地减少数据移动。因此,这类似于数据流处理器。
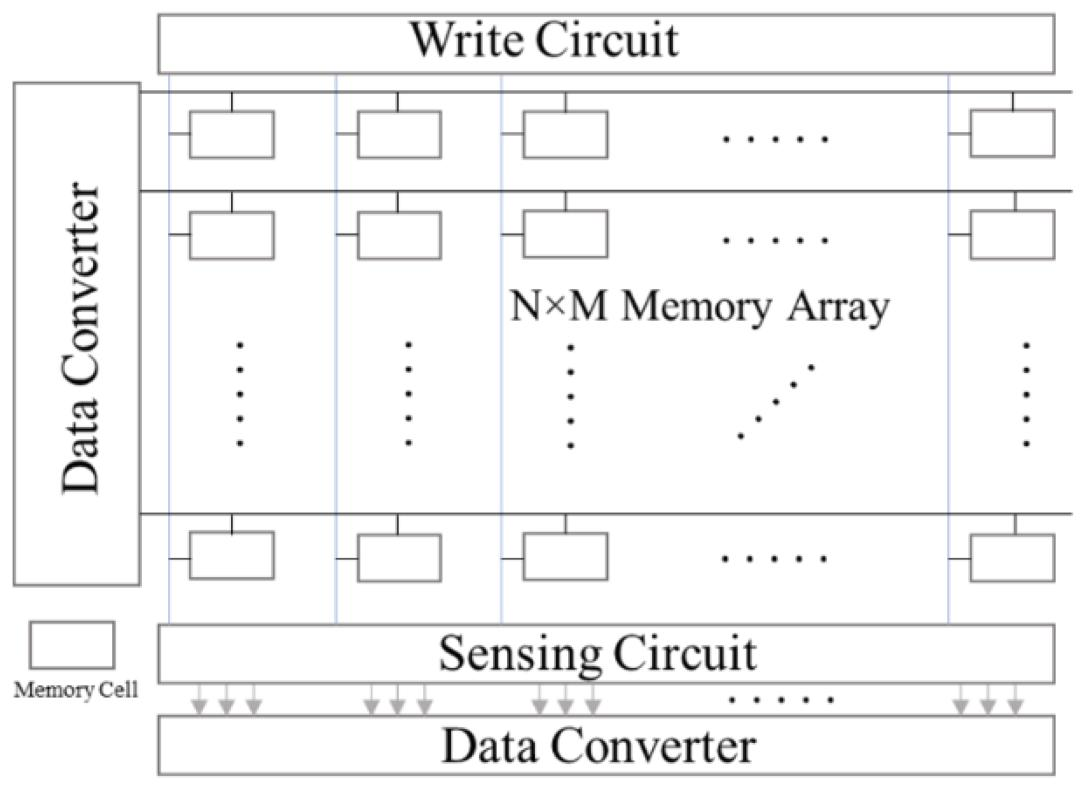
图2: 内存处理宏系统的示意图
Syntiant开发了一系列基于闪存阵列的边缘推理处理器,例如NDP10x、NDP120、NDP200。Syntiant的PIM架构非常节能,并且与边缘优化的训练管道相结合。运行NDP固件的系统中嵌入了Cortex-M0。NDP10x处理器可以容纳560k个INT4精度的权重,并通过INT8激活执行MAC运算。训练管道可以根据规格为各种应用构建神经网络,并优化延迟、内存大小和功耗。Syntiant发布了五个不同版本的应用处理器。NDP100是他们的第一款AI处理器,于2020年更新,尺寸微小,为2.52mm2 ,功耗超低,不到140μW。Syntiant继续提供更多PIM处理器,分别为NDP 101、102、120和NDP 200。应用领域主要是智能手机、可穿戴和可听设备、遥控器和物联网端点。神经计算由INT 1、2、4和8精度支持。NDP 10× 系列的能效为2TOPS/W,其中包括NDP100、NDP 101 和 NDP 102。NDP 120和NDP 200 分别表现出1.9GOPS/W和6.4GOPS/W。
Untether开发了PIM AI加速器卡TsunAImi,用于数据中心或服务器推理。TsunAImi的核心是四块runAI200芯片,由台积电在标准SRAM阵列中制造。每个runAI200芯片具有511个内核和192MB SRAM内存。runAI200以INT8精度计算,性能达到502TOPS,功耗为8TOPS/W,是 NVIDIA 安培A100 GPU的3倍。TsunAImi系统的最终性能为2008TOPS,功耗为400W。
UPMEMP PIM创新地将数千个DPU单元放置在 DRAM内存芯片中。DPU由主CPU上运行的高级应用程序控制。每个DIMM包含16个支持PIM的芯片,每个PIM有8个DPU。因此,每个UPMEM包含128个DPU。
但是,该系统是大规模并行的,最多可以将2560个DPU单元组装为具有256 GB PIM DRAM的单元服务器。计算能力是具有主CPU的x86服务器的15倍。INT32位加法的基准吞吐量为58.3MOPS/DPU。该系统适用于DNA测序、基因组比较、系统发育学、宏基因组分析等。
PIM 计算范式仍处于初级阶段。然而,对于高效的MAC操作和低功耗边缘应用来说,它是一个非常有前途的系统。许多行业和产学研合作正在推动PIM技术和架构的发展。本节简要讨论了行业和产学研合作中的PIM处理器。表4列出了PIM研究的最新进展。
阿里巴巴针对低精度边缘应用开发了基于SRAM和DRAM的数字CIM和PNM系统。CIM架构使用多个芯片组模块 (MCM) 来解决复杂问题,而不是使用单个SoC。在其他资料组中的CIM架构提出了一种内存计算边界 (COMB),它是内存计算和近内存计算之间的折衷。该技术表现出较高的宏观计算能效和较低的系统功率开销。该CIM架构演示了使用COMB NN处理器的可扩展MCM系统。分层流水线映射方案用于为所需操作部署不同大小的NN。通过关键字识别、CIFAR-10图像分类和使用一、二和四个芯片组的tiny-YOLO NN的物体检测演示了芯片操作。
IBM和帕特雷大学联合展示了基于PCM的CIM处理器HERMES。该CIM是一个256×256的内存计算核心,采用14nm CMOS工艺技术制造,用于边缘推理。HERMES已在MNIST和CIFAR-10数据集上进行了图像分类操作。
三星科技一直致力于为从边缘到数据中心的AI应用开发各种CIM架构。该公司最近发布了HBM-PIM。HBM-PIM用于高速内存访问,采用DRAM 20nm工艺制造。三星和亚利桑那州立大学 (ASU) 推出了用于AI推理的PIMCA芯片。PIMC 的功耗非常低(124mW)。如表2所示,PIMCA具有很高的能效(588TOPS/W)。台积电已经设计和制造了用于推理的模拟和数字CIM系统。
除了台积电自身的研究外,该公司还与学术界的各个研究小组合作,开展了多个关于各种新兴存储器件的CIM研究项目,例如ReRAM、STT-MRAM、PCM、RRAM和RRAM-SRAM。这些宏观推理芯片的性能最近已在各种高级会议或科学论坛上得到展示。最佳性能是在 ISSCC 2022上使用 PCM 设备展示的,在2位精度下表现出 5.12TOPS,即1286.4TOPS/W。该CIM处理器支持 INT2和 4 位计算精度。数字 CIM 系统采用 5nm工艺技术的FinFET 制造,性能为 2.95TOPS和254TOPS/W。
除了上面介绍的AI加速器外,还有少数公司正在开发边缘处理器。致力于神经形态处理器的公司包括MemComputing、GrAI和iniLabs。Memryx是一家新成立的初创公司,正在为交通、物联网和工业等广泛应用构建高性能、节能的AI处理器。它可以计算具有4/8/16位权重的Bfloat16激活,性能约为5TFLOPS。
本节讨论了前面所述的边缘处理器的性能分析,讨论的重点是边缘处理器的不同架构。首先,根据计算性能、功耗、芯片面积和计算精度讨论整体性能。然后,仅讨论PIM处理器。在本节的最后,我们将重点介绍仍在研发中或等待商业化可用的设备。
我们使用以下关键指标比较上一节中列出的所有边缘AI处理器:
性能:每秒万亿次运算(TOPS);
能源效率:TOPS/W;
功率:瓦特(W);
面积:平方毫米(mm²)。
性能:图3绘制了性能与功耗的关系,数据流、神经形态和PIM处理器使用不同的标签。功耗在1W至60W范围内的处理器的性能为1至275TOPS。它们面向相对高功率的应用,例如监控系统、自动驾驶汽车、工业、智慧城市和无人机。此列表中吞吐量最高的处理器是 MobileEye的EyeQ6、Horizon的Journey 5和Nvidia的Jetson Orin。Jetson Orin的速度比 EyeQ6和Journey 5快约2.15倍。根据公司数据表,Jetson Orin在INT8精度下具有275TOPS,功率为60W。Orin 的功耗分别比 EyeQ6 和 Journey 5 高约 1.5倍和 2倍。功耗小于1W 的处理器性能为0.2GOPS至17TOPS。这些处理器面向边缘和物联网应用。Syntiant的NDP系列PIM处理器功耗最低,它们是基于闪存的PIM处理器。
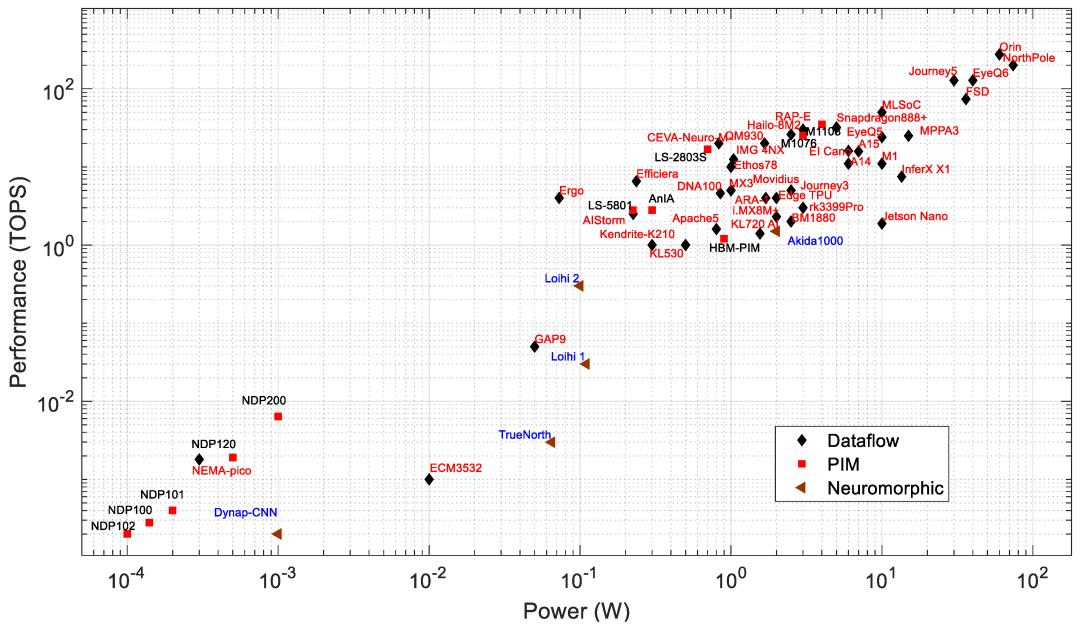
图3:AI边缘处理器的功耗和性能
IBM NorthPole在INT8精度下以60W的功耗实现了200TOPS(基于与IBM的讨论)。但是,NorthPole在4位和2位精度下可以分别实现更高的TOPS,分别为400和800。根据最近的一篇NorthPole文章,NorthPole处理器的最大功耗为74W。
在神经形态处理器中,Loihi 2的表现优于其他神经形态处理器,Akida AKD1000除外。然而,AKD1000的功耗是Loihi 2的20倍(见表2)。虽然神经形态处理器在TOPS与W方面似乎不那么令人印象深刻,但值得注意的是,如果使用原生脉冲算法(即不是用脉冲神经元实现的深度网络)执行任务,它们通常需要的突触操作要少得多。
对于推理任务,神经形态处理器的能耗明显低于其他处理器。例如,Loihi处理器的能耗比英特尔Movidious低5.3倍,比Nvidia Jetson Nano低20.5倍。图3显示,在相同的功耗范围内(0.5至1.5 W),高性能PIM处理器(如M1076、M1108、LS-2803S和AnIA)表现出与数据流或神经形态处理器相似的计算速度。
精度:数据精度是比较处理器性能时的一个重要考虑因素。图4显示了图3中处理器的精度。图5显示了每个架构类别的精度分布和处理器总数。一个处理器可能支持多种类型的计算精度。图3和图4基于每个处理器支持的最高精度。
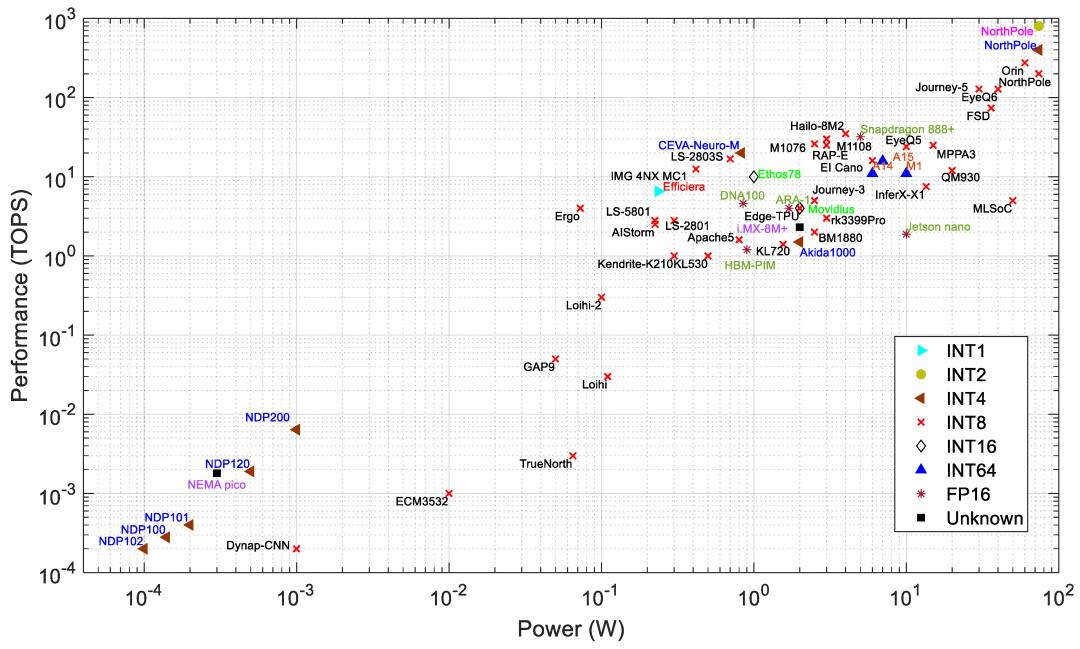
图4:具有计算精度的边缘处理器的功率与性能
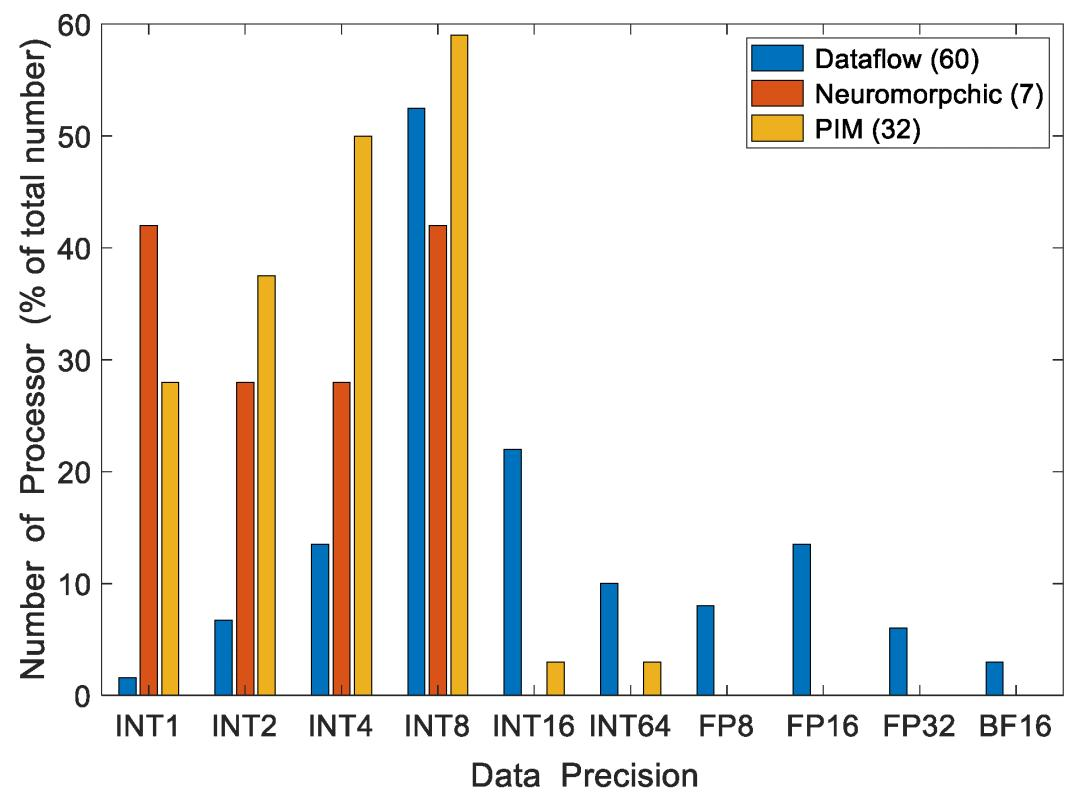
图5:支持不同数据精度的边缘处理器数量,图例中显示了处理器总数
在数据流处理器中,INT8是DNN计算最广泛支持的精度。NVIDIA的Orin在INT8精度下实现了275TOPS,这是图5中INT8精度的最大计算速度。然而,一些处理器使用INT1(Efficiara)、INT64(A15、A14 和 M1)、FP16(ARA-1、DNA100、Jetson Nano、Snapdragon 888+)和INT16(Ethos78 和 Movidius)。神经形态和PIM处理器主要支持INT1到INT8数据精度。较低的计算精度通常会降低推理精度。根据VGG-9 和 ResNet-18 在以 INT1 精度计算时,推理精度损失分别为3.89%和6.02%。第3.1节将更深入地讨论量化和精度之间的关系。精度越高,准确度越高,但计算成本也越高。图5显示,所检查的处理器中最常见的精度是INT8。这在准确度和计算成本之间提供了良好的平衡。
如图4和图5所示,几乎所有神经形态处理器都使用INT8进行突触计算。例外是AKD1000,它使用INT4,在每秒操作数(1.5TOPS)方面在神经形态处理器中表现出最佳性能。然而,它的功耗比Loihi处理器高出约18倍。在INT8精度下,Loihi 1执行30GSOPS,功耗为110mW,而Loihi 2的吞吐量是Loihi 1的10倍,功耗相似。
如图4和图5所示,PIM 处理器主要支持INT1至INT8精度。图5显示了PIM处理器在INT4和INT8精度下的性能,因为无法获得所有支持精度的数据。Mythic处理器(M1108和M1076)在PIM处理器中性能最佳。Mythic和Syntiant已使用闪存设备开发了各自的PIM处理器。然而,Mythic处理器使用 76 个计算块来计算 INT8精度的DNN,需要更高的功率。Syntiant 处理器使用 INT4 精度,计算吞吐量比 Mythic M1076 低约 13,000 倍,同时功耗低约 6000 倍。Syntiant 处理器仅限于NDP10x中最多64个类的较小网络。另一方面,Mythic 处理器可以以更高的精度处理10倍以上的权重。基于三星 DRAM 架构的 PIM 处理器使用靠近存储库的计算模块,并支持INT64精度。
能源效率:图6展示了PIM和神经形态处理器的数据流性能与能源效率。效率决定了处理器每瓦的计算吞吐量。所有PIM处理器的能源效率都在1到16TOPS/W之间,而大多数数据流处理器的能源效率在0.1到 55TOPS/W之间。PIM架构通过在内存模块内部执行计算来减少延迟,从而提高计算性能并降低功耗。Loihi 2在所有神经形态处理器中表现出最佳的能源效率。如图7所示,能源效率与功耗让我们对处理器有了更好的了解。Loihi 2表现出比许多高性能边缘AI处理器更好的能源效率,同时功耗非常低。Ergo是所有数据流处理器中能源效率最高的处理器,其能源效率为55TOPS/W。
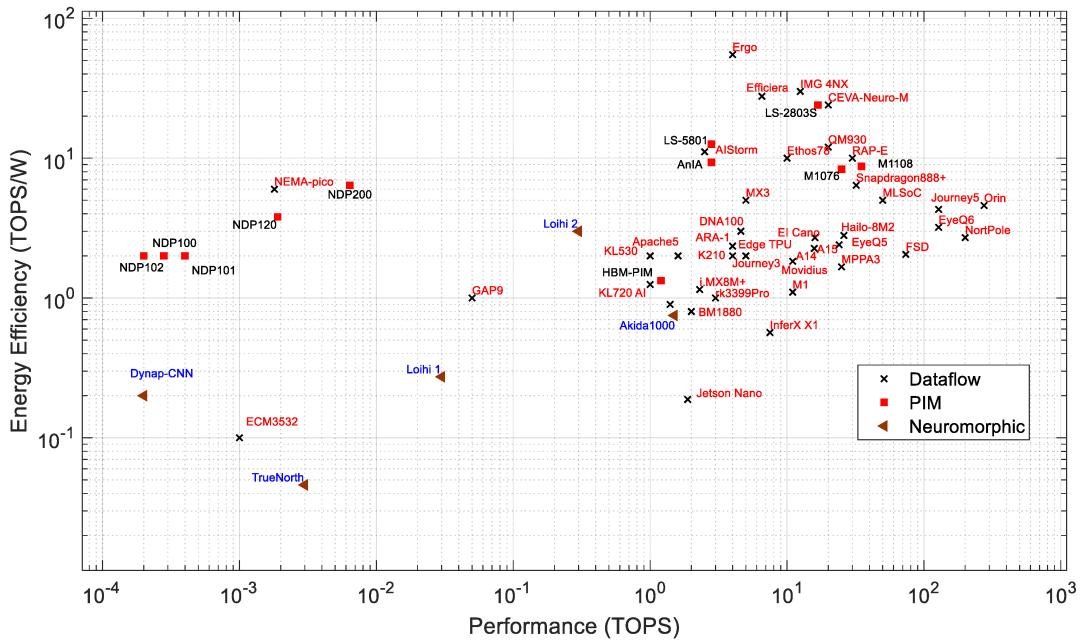
图6:边缘处理器的性能和能源效率
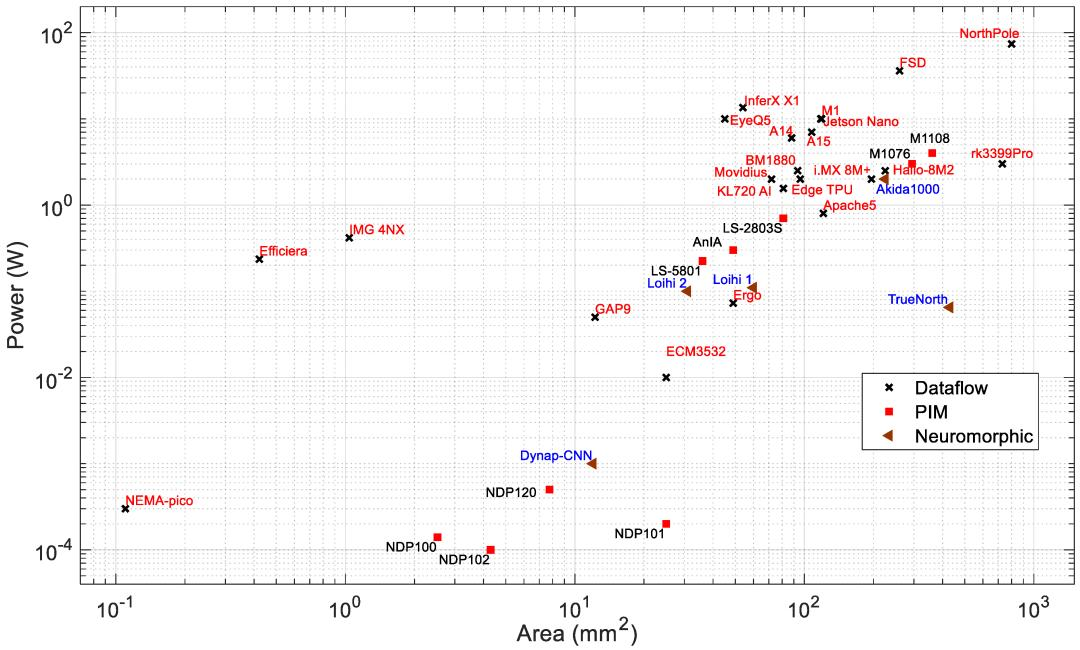
图7:边缘处理器的功耗与面积
芯片面积:面积是选择边缘设备上的 AI 应用处理器的重要因素。现代处理器技术正在突破界限,制造出密度极高、性能卓越的系统。对于电池供电的边缘设备来说,更小的芯片面积和更低的功耗非常重要。芯片面积与硅制造成本有关,也决定了应用领域。边缘应用需要更小的高性能芯片。
图7和图8分别显示了功耗和性能与芯片面积的关系。可以观察到,总体而言,功耗和性能都会随着芯片面积的增加而增加。根据可用的芯片尺寸,NothPole拥有最大的芯片尺寸,为800平方毫米,在INT8中执行200TOPS。面积最小的芯片具有数据流架构。图9显示了能效与面积的关系,即图8和图9的组合关系。在该图中,PIM处理器形成一个集群。该PIM集群的整体能效高于具有类似芯片面积的数据流和神经形态处理器。一些数据流处理器(如Nema Pico、Efficiera和IMG 4NX)比其他处理器表现出更高的能效和更好的面积性能。
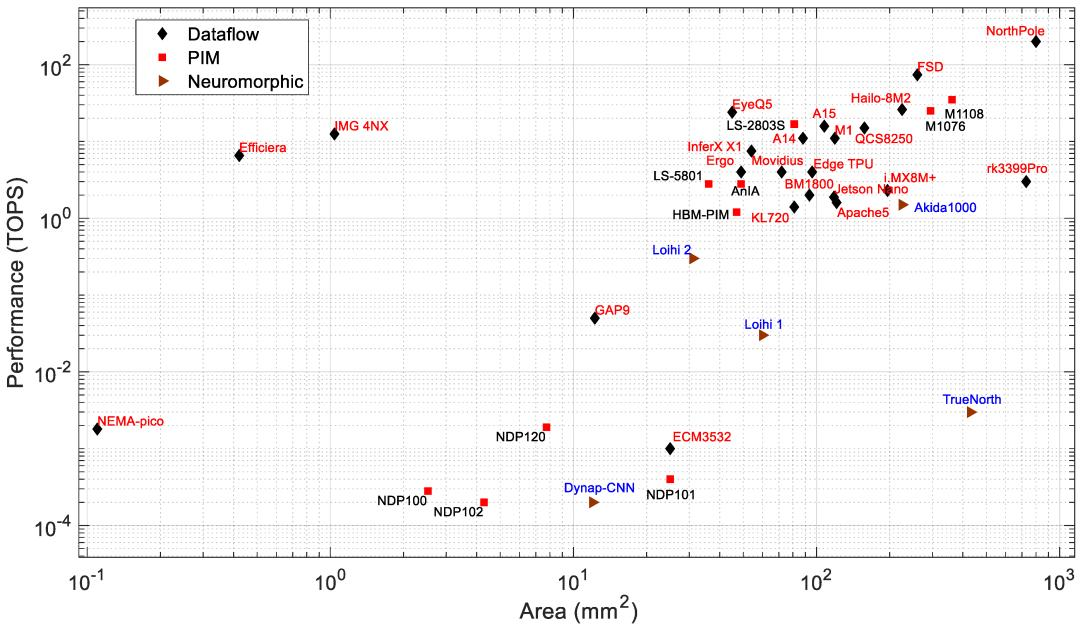
图8:边缘处理器的面积与性能
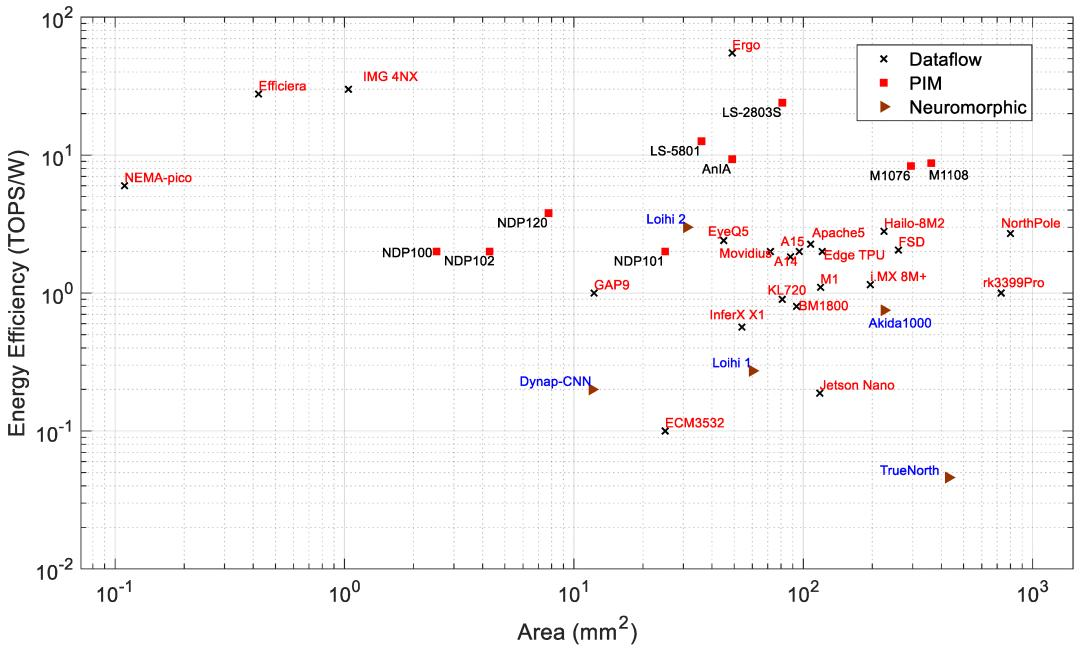
图9:边缘处理器的面积与能源效率
图3、图4、图5、图6、图7、图8、图9、图10和图11描述了所有类型的处理器,而图12仅显示了已发布为产品或仍处于工业研究阶段的 PIM 处理器之间的关系。研究处理器在ISSCC和VLSI等会议上进行了展示。图11右下角的PIM处理器是数据中心和密集型计算应用的候选处理器。能效更高的PIM处理器体积更小、功耗更低、能效更高,适用于边缘和物联网应用。从图12中我们可以看到,大多数正在工业研究中的PIM处理器都比已经发布的处理器表现出更高的能效。这表明未来的PIM处理器可能会具有更好的性能和效率。
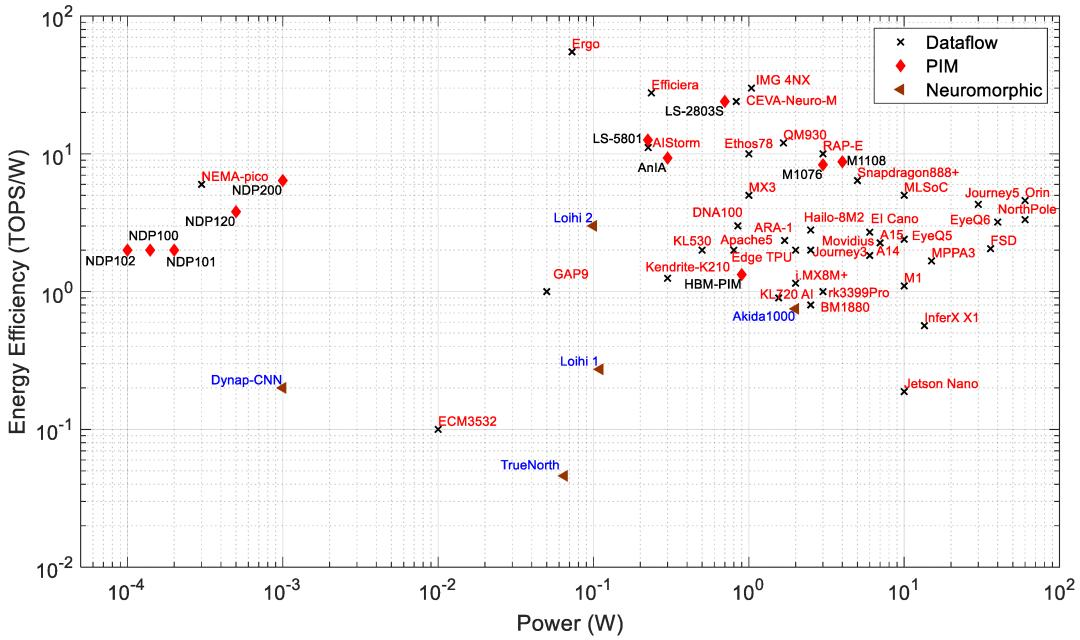
图10:边缘处理器的功率与能源效率
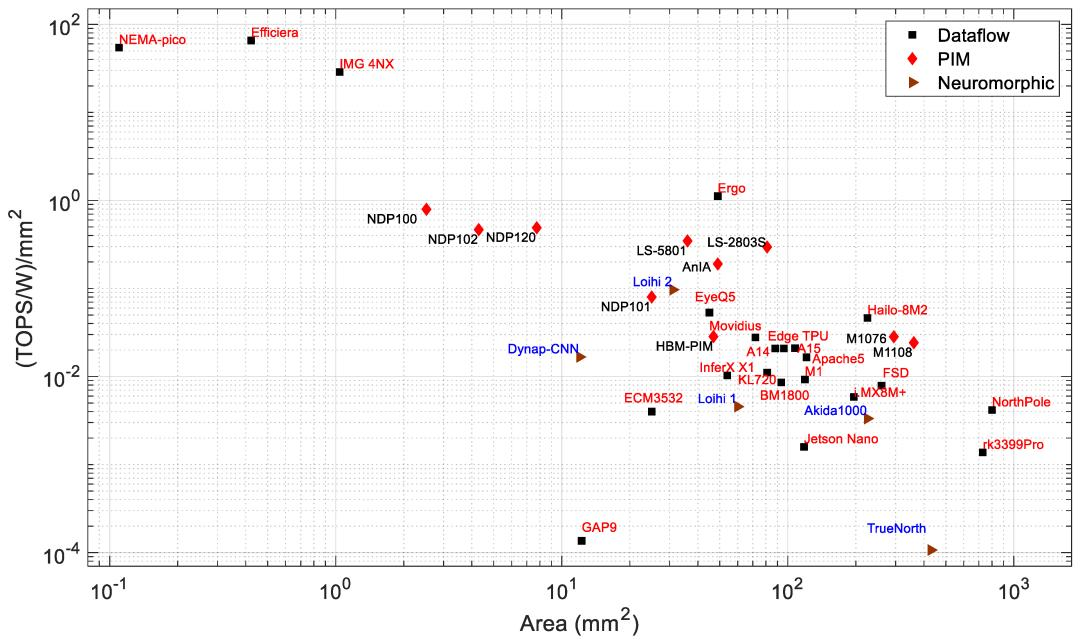
图11:边缘处理器的面积与单位面积能效
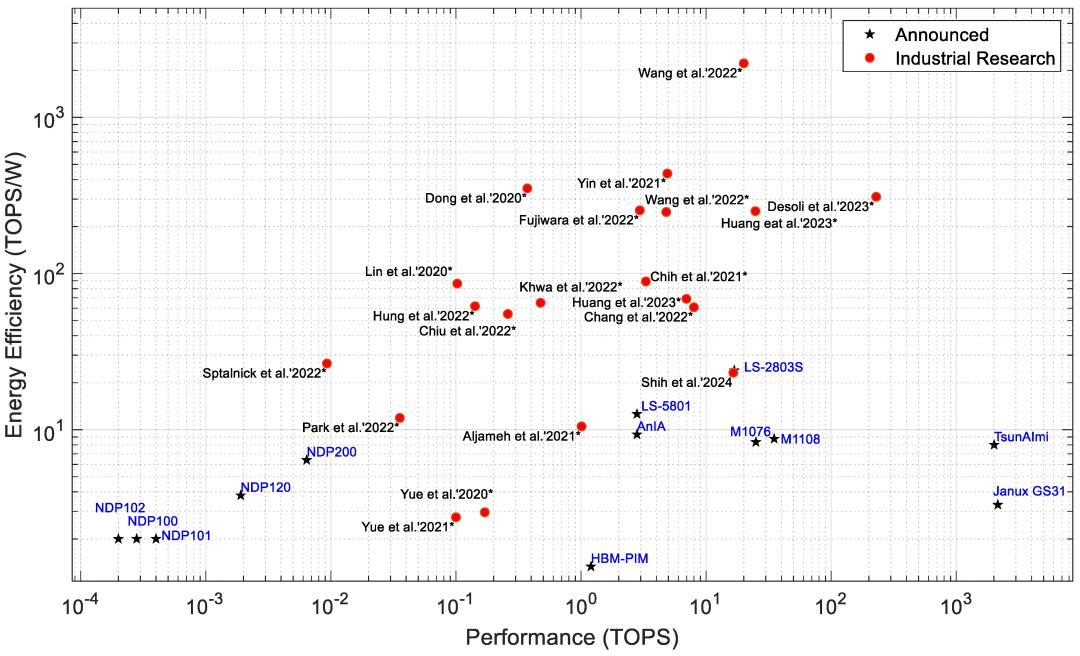
图12:PIM/CIM处理器 的性能与能效,带星号的处理器表示该处理器仍在进行工业研究,其他处理器已由制造商发布或宣布
PIM处理器在内存阵列内计算MAC运算,从而减少数据传输延迟。通常,PIM处理器以较低的整数/定点精度计算。PIM处理器通常支持INT 1-16精度。然而,根据我们的研究,我们发现大约59%的PIM处理器支持INT8精度的MAC运算,如图5所示。与数据流处理器相比,低精度计算速度更快,所需功耗更低。PIM边缘处理器在深度学习推理应用中的功耗为0.0001到4W,如表2和图3所示。然而,数据流处理器存在高内存要求和延迟问题,并且它们比大多数PIM处理器消耗更高的功耗以实现我们在图3、图4和图5中看到的相同性能。
从图3和图4 可以看出,Syntient的NDP200功耗不到1mW,在极端边缘应用中表现出最高的性能。Mythic M1108功耗为4W,在所有功耗低于10W的数据流和神经形态处理器中表现出最高的性能 (35TOPS)。对于相同的芯片面积,M1108的功耗比Tesla的数据流处理器FSD低9倍,而FSD的计算速度比M1108快2倍,如图8和图9所示。
对于100mm2以下的处理器,Gyrfalcon的LS2803表现出最高的性能(EyeQ5除外)。但是,EyeQ5的功耗比LS2803高出约14倍,性能却高出1.4倍。为边缘应用部署PIM处理器的好处是高性能和低功耗,而且由于MAC操作是在内存阵列内执行的,因此PIM处理器可显著降低计算延迟。
多家公司及其合作伙伴正在开发具有最先进性能的边缘计算架构和基础设施。图13显示了在高级会议(如ISSCC、VLSI)上展示的工业研究处理器的功耗与能效。该图表包括PIM和数据流处理器。
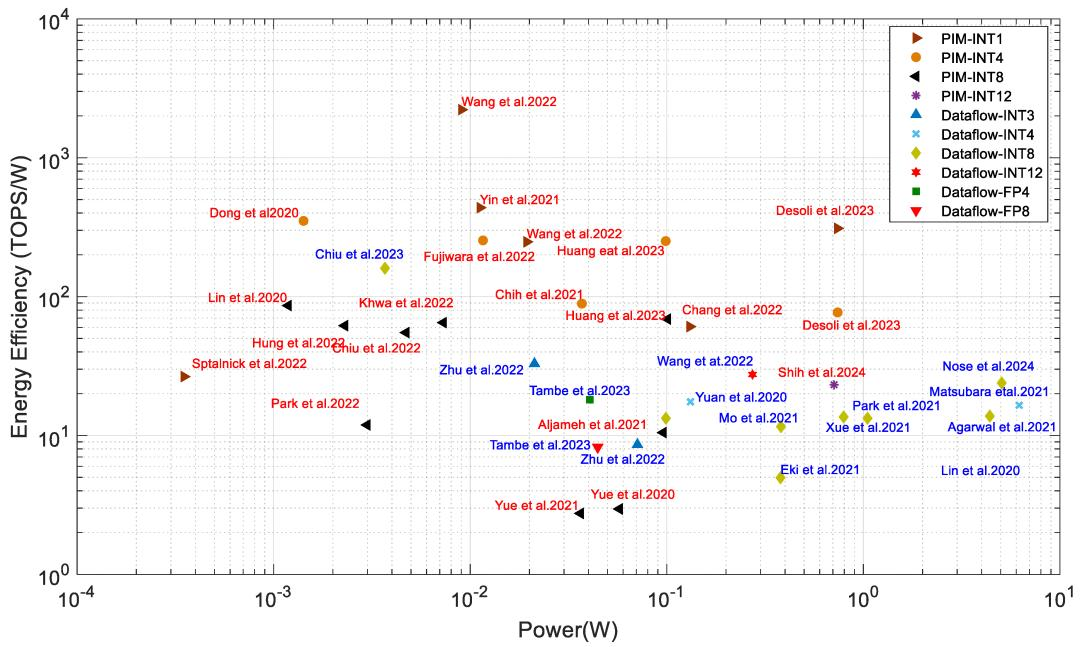
图13:工业研究中的PIM(红色)和数据流(蓝色标签)处理器
瑞萨电子在ISSCC 2024上展示了采用14nm工艺开发的近存系统,计算速度达到130.55TOPS,功耗为23.9TOPS/W。台积电和台湾清华大学在ISSCC 2023上展示了采用22nm CMOS工艺开发的近存系统,计算速度为0.59TOPS,功耗为160TOPS/W,精度为8-8-26位(输入-权重-输出)。在近存和数据流处理器中,该系统的能效最高。能效是通过90%的输入稀疏度实现的,而50%的输入稀疏度可使能效达到46.4TOPS/W。阿里巴巴和复旦大学在ISSCC 2022上展示了一个近存处理系统,在INT3精度下计算时,其性能为0.97TOPS,能效为32.9TOPS/W。该加速器是一种基于SRAM的近存计算架构。清华微电子和清华大学在ISSCC 2022上展示了一款用于NLP和计算机视觉应用的数据流处理器,在INT12精度下能效为27.5TOPS/W。瑞萨电子在INT8计算精度下能效为13.8TOPS/W。许多其他公司,如IBM、索尼、联发科和三星也展示了各自在数据流边缘处理器方面的研究,其能效约为11至18TOPS/W 。
PIM处理器通常比数据流处理器表现出更好的能效。台积电和台湾国立清华大学在 ISSCC 2024 上展示了采用 16 nm CMOS 工艺的 PIM 系统,在 8-8-23 精度(输入-权重-输出)下实现了 98.5TOPS/W。联发科和台积电在 ISCC 2024 上展示了采用3nm工艺开发的数字 PIM 系统,在 16.5TOPS 性能下实现了 23.2TOPS/W。英特尔和哥伦比亚大学在ISSCC 2022 上展示了一款PIM处理器其性能和能效分别为2219TOPS/W和20TOPS,比资料中提到的处理器效率高出约33倍。
然而,前者处理器使用的精度(INT1)要低得多。台积电和清华大学在 ISSCC 2023 上展示了一款 PIM 加速器,其性能为 6.96TOPS 和 68.9TOPS/W,在 INT8 精度下计算时,比 其他资料展示的近存计算系统快 12倍左右。意法半导体展示了一款 PIM 加速器,在 INT4 精度下计算速度为 57TOPS 和 77TOPS/W 性能比 ISSCC 2021上展示的近存计算高出约 25 倍。台积电和清华大学在 ISSCC 2022 上展示了一款基于 PCM 的处理器,其 INT8 精度为 65 TOPS/W。三星和亚利桑那州立大学在 VLSI' 2021上展示了PIMCA ,并以 INT1 精度计算,能效达到 437TOPS/W。其他公司,如台积电及其合作者、三星及其合作者、英特尔及其合作者和HK Hynix,也在最近的ISSCC和VLSI 会议上展示了他们的PIM处理器。
本评论主要侧重于根据边缘处理器的底层硬件架构和计算技术对其进行分类。图表和表格反映了不同类型的硬件架构。表2显示了处理器的架构类型,例如数据流、PIM或神经形态。但是,为任何应用找到合适的处理器也很重要。表3显示了制造商建议的处理器应用领域。从图3和图4显示的图表中,可以根据功耗和性能指标确定处理器的应用领域。位于图3和图4左下角的处理器面向极端边缘应用,例如可穿戴设备(智能手表、耳机、耳塞和智能太阳镜)。Syntiant的NDP、Nema-Pico、DynapCNN处理器是这些应用的候选处理器。中档处理器功耗为0.1至10W,面向安全和监控应用。处理器包括LS5801、DNA100和CEVA-Neuro-M。高端处理器针对的是具有约100TOPS计算性能的相对高性能应用。目标应用领域包括自动驾驶汽车和工业自动化。候选处理器是Horizon的Journey系列、Tesla的FSD、NVIDIA的Orin、Mobileye的EyeQ和IBM的NorthPole。
然而,如果我们分析用于边缘应用的商用处理器的价格,价格会根据计算能力、能源效率和应用类型而有所不同。从这个角度来看,我们可以说,一般来说,处理器的成本随性能(TOPS)而变化。图3和图4左下角的处理器性能最低,用于仅售几美元(3至10美元)的可穿戴AI设备。中档处理器的价格约为100美元,目标应用是安全和跟踪应用。在此类别中,Google Coral Edge TPU板的价格为98美元。高端边缘处理器的计算能力超过100TOPS,成本为几百到几千美元。这些处理器主要用于自动驾驶汽车和工业。例如,Tesla FSD的当前市场价格为8000美元,NVIDIA Jetson Orin的售价约为2000美元。
https://www.mdpi.com/2079-9292/13/15/2988
文章来源“半导体行业观察”,作者“mdpi”



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI










