# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
身边有人说,AI好像是前两年突然火起来的,一下子就成了我们今天熟悉的产品的模样。
2022年11月,ChatGPT横空出世,如惊雷。只是,雷从何而来?
从学界研究的脉络看,近两年AI的爆发,其实早已有迹可循。多年的基础研究和发现,积累而形成了今天Infra、Data、Model、Application等等层面的突破。
有些公司比如OpenAI,本就是以研究为初衷。也有一些研究机构,虽然默默无闻,但他们的论文却启发的无数的创业者。
今天的文章主要来自Lightspeed Venture Partners,是我非常非常推荐的内容!
15年,19篇论文,4大研究阵营,一次性系统看完AI的前世今生!
一直觉得,如果想判断未来,必定要从过去看起。作为目录和研究框架,值得收藏!
Lightspeed作为美国最头部的VC之一,投资了我们熟悉的Zoom,AI领域的Scale AI、Poni.ai等,更在非常初期阶段就投中了美团、拼多多等。
Lightspeed在过去十年中,一直密切关注人工智能研究。经常积极参与帮助科研人员,将他们的想法转化为开创性的企业。是 Mistral、SKILD 和 Snorkel 的早期支持者,这些公司都源自AI技术的底层基础发现。
在这篇文章中,列出了过去 15 年最具影响力的 AI 研究论文,并且从学界、企业相交融的视角,梳理了最重磅的学术派系和业界创新的影响。
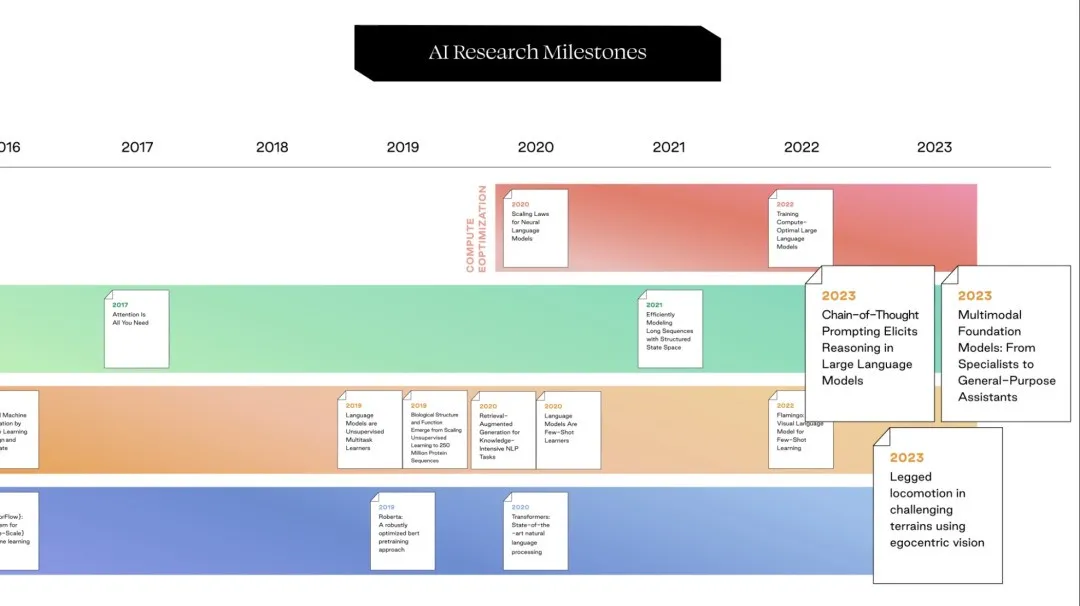
一、AI领域的四波浪潮
过去 15 年,AI研究成果间相互启发、继承、发展,有的研究在创业界一石激起千层浪,有的科学家成为创始人,有的科研机构变成了伟大的公司……
学术界轻轻扇动翅膀,AI企业、生态却逐渐走向世界舞台中央,在能源、脑机、航天等不同领域受到了AI的影响。
我们观察到,在AI学术探索中,有四波主要的研究浪潮相互依存,推动了AI达到今天的高度——
1. 模型架构改进
自 2010 年代以来,人工智能模型架构的进步推动了重大突破和初创企业创新。
其中包括 AlexNet 于 2012 年在深度卷积神经网络方面的工作,以及备受赞誉的论文Attention is all you need,该论文彻底改变了自然语言处理。
2. 开发人员生产力提升
过去十年,工具和框架取得了重大进步,显著提高了开发人员的工作效率,这对于初创企业的发展至关重要。
里程碑包括 TensorFlow的推出 (以及 2015 年推出的 PyTorch 等其他工具)、 2018 年推出的HuggingFace Transformers 库,以及 Meta 在 2023 年开源的 Llama 模型。
3. 任务表现的优化
过去 10 年发表的几篇不同的论文,彻底改变了人工智能执行任务的效率和多样性:
训练「深度神经网络」以执行复杂任务,「联合学习」以进行「对齐和翻译」,从而降低了训练复杂度。
在「无监督学习」方面取得突破 ,从而在不进行任何微调的情况下提高了任务性能。并使用「检索增强生成」 (RAG) 和「外部数据存储」来执行知识密集型任务。
4. 计算优化
在 2010 年代,dropout 和批量归一化等新的优化技术提高了模型性能和稳定性。2020 年,OpenAI 的里程碑式论文,强调了模型性能如何随着计算资源的增加而可预测地扩展。
紧随其后的是 2022 年的 DeepMind,它证明了「平衡模型大小和训练时间,以获得最佳性能」的重要性。
二、人工智能研究谱系
直接看图——
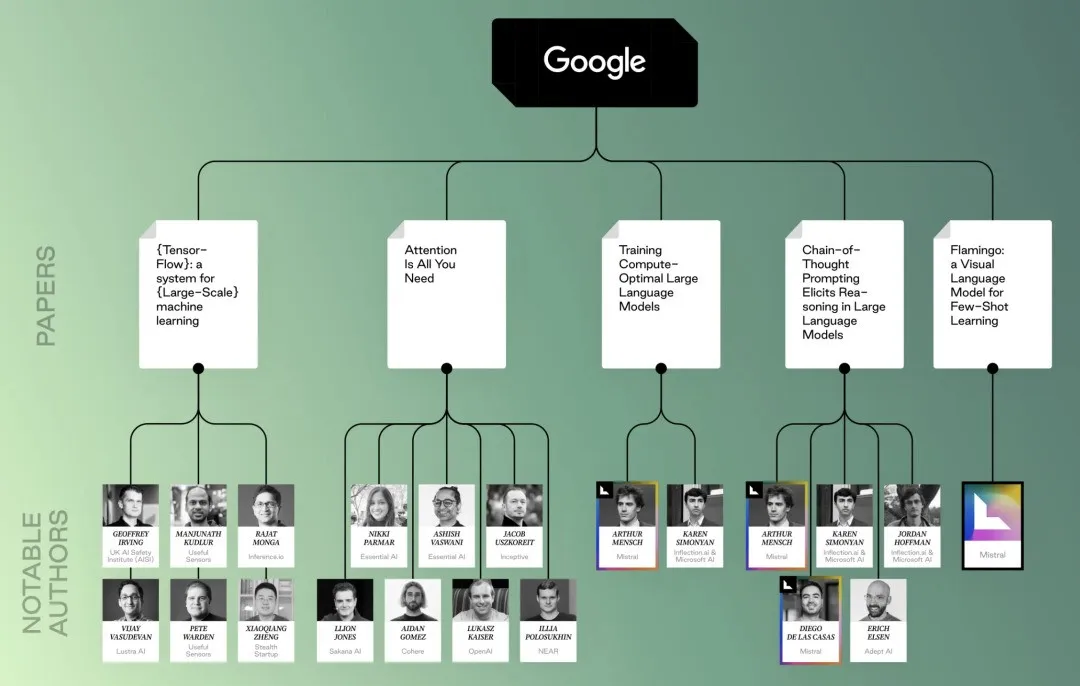
谷歌系的论文和研究者
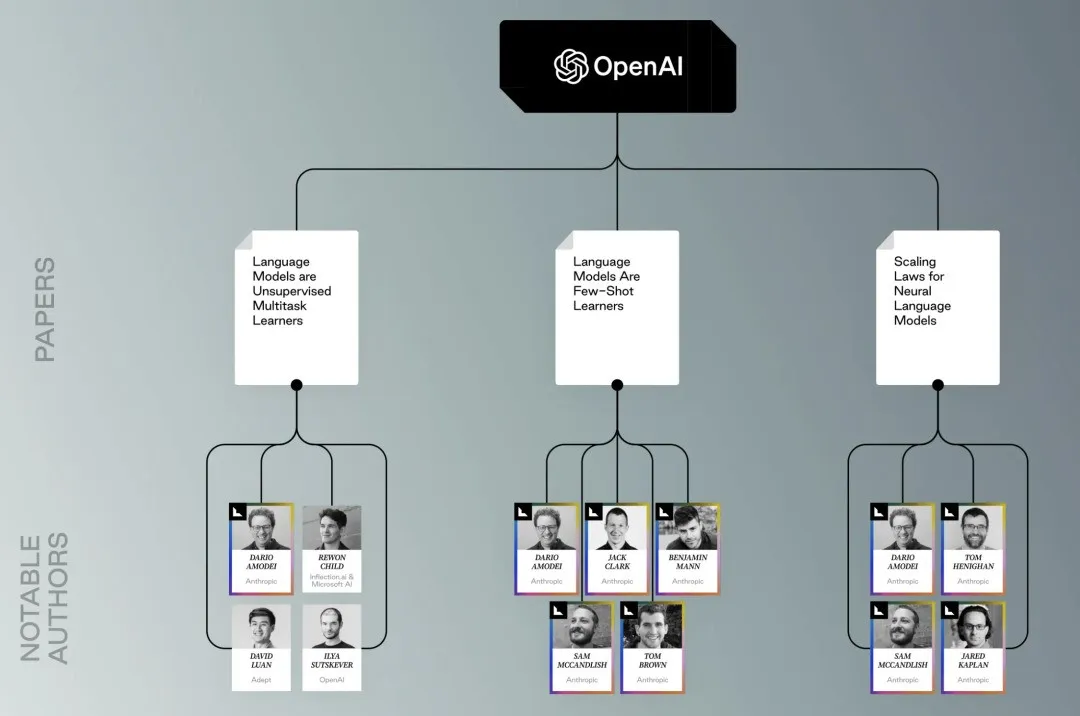
OpenAI系的论文和研究者
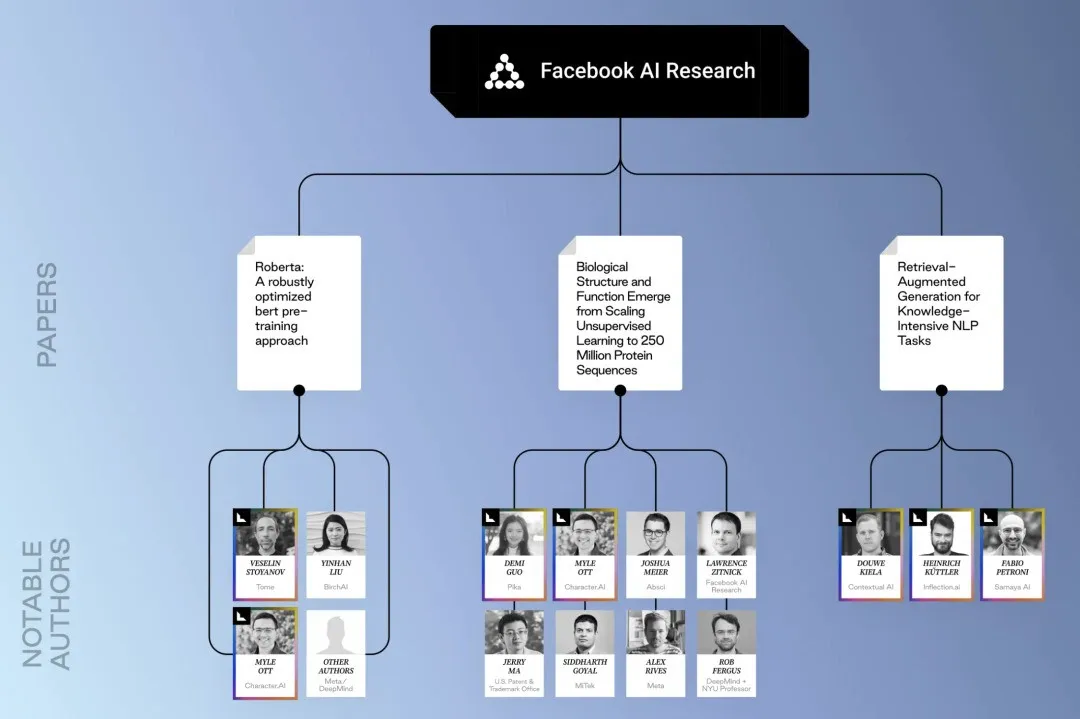
Facebook系的论文和研究者,论文指向我们熟悉的郭文景(Pika)
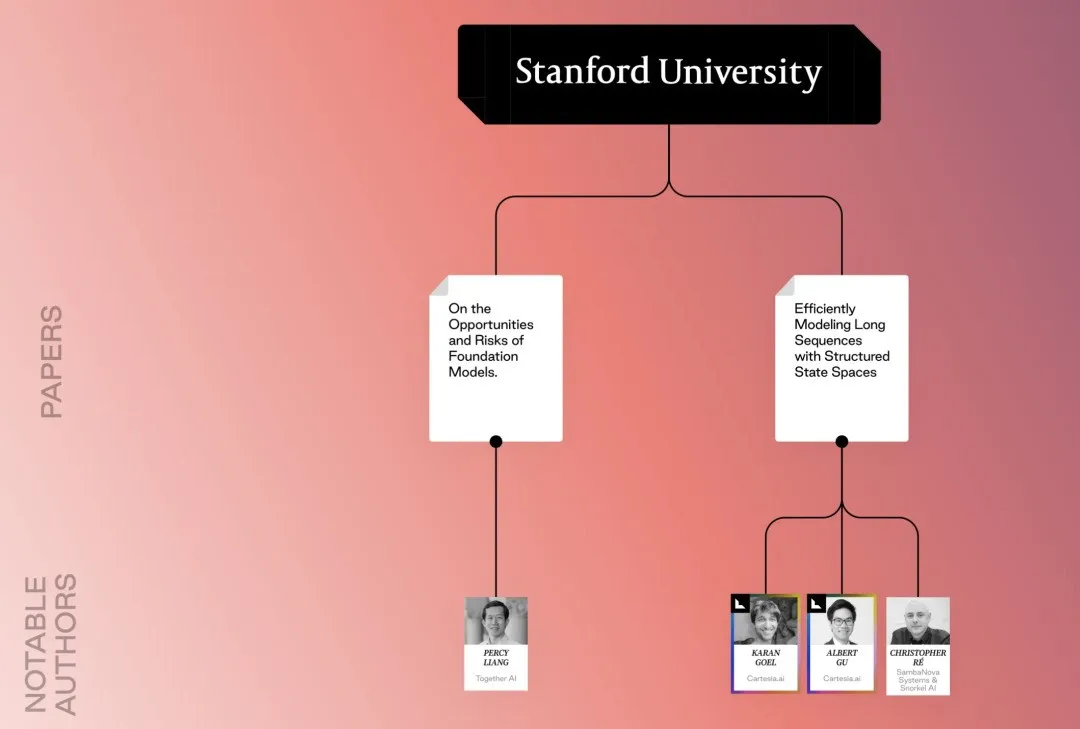
斯坦福系的论文和研究者,略显稀疏,但成果极为重磅
三、早期突破
早期的论文通过介绍已成为初创企业发展和后续研究基础的框架、模型和方法,为当今的 AI 生态系统奠定了基础。这些论文中提出的 Transformers、GPT、Tensorflow、Bert 等框架为自然语言处理、训练语言模型和微调模型开发引入了新的架构。以下按照时间顺序,呈现19篇颠覆性论文。
2012
ImageNet Classification with Deep Convolutional Neural Networks
《使用深度卷积神经网络进行 ImageNet 分类》 (2012),Geoffrey Hinton、Ilya Sutskever、Alex Krizhevsky
这篇论文通常被称为 AlexNet(因作者 Alex Krizhevsky 而得名),是深度学习领域的一项里程碑式成就。它证明了具有五个卷积层的深度卷积神经网络 (CNN) 在 ImageNet 数据集上取得的结果明显优于之前的方法,消除了人们的怀疑,并证明了深度学习架构对于图像分类等复杂任务的可行性。
论文还强调了利用 GPU(图形处理单元)训练深度 CNN 的重要性。GPU 在处理训练中涉及的并行计算方面速度更快,使大规模训练成为可能。
论文链接:
https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
2015
Deep Residual Learning for Image Recognition
《用于图像识别的深度残差学习》(2015),何凯明 ,张翔宇,任少清,孙健
在本文发表之前,训练深度 CNN 一直面临性能下降的问题。随着网络越来越深,准确率会趋于稳定甚至下降。本文引入了残差学习的概念,重新规划了 CNN 中的各层,使其能够学习修改输入的残差函数,而不是尝试从头开始学习整个映射,从而使网络能够更轻松地学习恒等映射,并实现更深层次的架构。
残差连接使研究人员能够训练比以前更深的 CNN。残差连接现在是大多数现代模型架构的基本构建块。这包括非常成功的模型,如 ResNet(原始论文中的模型)、Inception 和 DenseNet。
论文链接:https://arxiv.org/abs/1512.03385
2016
Neural Machine Translation by Jointly Learning to Align and Translate
《通过联合学习对齐和翻译实现神经机器翻译》 (2016),Dzmitry Bahdanau、Kyunghyun Cho、Yoshua Bengio
传统的神经机器翻译 (NMT) 模型通常难以准确对齐源句子和目标句子之间的元素,从而导致翻译文本中出现信息缺失或词序错误等问题。本文介绍了一种新架构,其中模型学习联合对齐和翻译,使其能够更好地捕捉源语言和目标语言中单词和短语之间的关系。联合学习方法有助于模型生成更准确、更流畅的翻译,并且与单独的对齐和翻译模型相比,可以简化训练过程。
论文链接:https://arxiv.org/abs/1409.0473
2016
TensorFlow: A system for large-scale machine learning
《TensorFlow:一种用于大规模机器学习的系统》 (2016),Martín Abadi、Paul Barham、Jianmin Chen、Zhifeng Chen、Andy Davis、Jeffrey Dean、Matthieu Devin、Sanjay Ghemawat、Geoffrey Irving、Michael Isard、Manjunath Kudlur、Josh Levenberg、Rajat Monga、Sherry Moore、Derek G Murray、Benoit Steiner、Paul Tucker、Vijay Vasudevan、Pete Warden、Martin Wicke、Yuan Yu、Xiaoqiang Zheng
TensorFlow 对机器学习开发人员的生产力产生了重大影响。它允许开发人员定义机器学习模型,而无需编写用于数值计算的低级代码,从而简化了开发流程并减少了构建和试验模型所需的时间。
此外,TensorFlow 可以部署在各种硬件平台上,包括 CPU、GPU 和 TPU(张量处理单元)。这种灵活性使开发人员可以根据自己的特定需求选择最佳硬件,并高效地训练大型模型。
论文链接:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=NMS69lQAAAAJ&citation_for_view=NMS69lQAAAAJ:JqN3CTdJtl0C
2017
Attention Is All You Need
《你所需要的就是注意力》 (2017),Ashish Vaswani、Noam Shazeer、Niki Parmar、Jacob Uszkoreit、Lilon Jones、Aidan Gomez、Lukasz Kaiser
Transformer 是模型架构的一个重大突破。在本文发表之前,大多数序列传导模型都依赖于循环神经网络 (RNN) 或卷积神经网络 (CNN) 来捕捉序列中元素之间的关系。由于 RNN 具有顺序性,因此训练速度可能特别慢。
本文提出了一种新架构 Transformer,它完全依赖于一种称为“自注意力”的注意力机制。这使模型能够直接关注输入序列的相关部分,从而更好地理解长距离依赖关系。
Transformer 架构通过消除 RNN 来加快训练速度,在机器翻译任务上表现出色,并广泛适用于文本摘要、问答和文本生成等任务。
论文链接:https://arxiv.org/abs/1706.03762
2019
Language Models are Unsupervised Multitask Learners
《语言模型是无监督的多任务学习者》 (2019),Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever
过去,训练 LLM 涉及监督学习,需要大量针对所需任务的标记数据。本文探讨了无监督学习的潜力,其中模型从大量未标记的文本数据中学习。
通过对大量未标记的文本数据进行训练,LLM 可以自然而然地学会执行各种任务(多任务学习),而无需明确的任务特定监督。这种无监督学习使模型能够捕获一般的语言理解和可应用于各种下游任务的能力。
无监督学习还可以提高效率 - 当针对特定任务进行微调时,LLM 可以从较少量的标记数据中学习。
论文链接:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=dOad5HoAAAAJ&citation_for_view=dOad5HoAAAAJ:YsMSGLbcyi4C
2019
Roberta: A robustly optimized bert pretraining approach
《Roberta:一种稳健优化的 bert 预训练方法》 (2019) Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer、Veselin Stoyanov
该论文重点介绍了 BERT(Transformers 的双向编码器表示)预训练过程的改进,与 BERT 相比,该论文在各种 NLP 任务上的表现普遍更好,训练收敛速度更快,从而使开发人员能够更快地迭代模型并减少时间。
这意味着缩短了训练时间,使开发人员能够更快地迭代模型,并在微调阶段花更少的时间在超参数上。
尽管 Roberta 的论文不如其前作那么具有变革性和知名度,但它的独特之处在于,几位合著者通过创立或领导新的初创公司来发展 AI 生态系统,其中包括 Tome、Character.ai 和 Birch.ai 的高管。
论文链接:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=dOad5HoAAAAJ&citation_for_view=dOad5HoAAAAJ:YsMSGLbcyi4C
2019
Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences
《将无监督学习扩展到 2.5 亿个蛋白质序列,生物结构和功能浮现 (2019) Alexander Rives、Siddharth Goyal、Joshua Meier、Demi Guo、Myle Ott、C Lawrence Zitnick、Jerry Ma、Rob Fergus
传统上,分析蛋白质结构和功能依赖于需要标记数据(例如,实验确定的结构)的技术。本文探讨了在大量蛋白质序列数据集(2.5 亿)上使用无监督学习来学习蛋白质的固有属性。
通过对大量未标记的序列数据训练深度学习模型,该模型可以学习捕获有关蛋白质的重要生物信息的表示。这包括二级结构、残基间接触甚至潜在生物活性等方面。
论文链接:
https://www.pnas.org/doi/abs/10.1073/pnas.2016239118

四、最新进展
2020年以后,人工智能发展和应用的速度加快。
最近的人工智能研究在学习和处理方面取得了重大进展,使技术更加高效,并可扩展到更广泛的应用。
我们还看到人工智能解决方案在现实世界中的应用,基于早期模型的初创公司蓬勃发展,基于新模型的初创公司不断涌现。
2020
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
《知识密集型 NLP 任务的检索增强生成》 (2020) Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel、Douwe Kiela
LLM 经过大量文本数据的训练,但经常难以完成需要访问和推理特定事实知识的任务。本文提出了一种称为检索增强生成 (RAG) 的新模型架构。RAG 结合了两个关键组件 - 检索(一个根据输入提示或问题从外部知识库检索相关文档的模块)和生成(一个强大的 LLM,它使用检索到的文档及其自身知识来生成响应)。
这种双内存架构提高了知识密集型任务(问答、总结事实主题)的性能,并且语言更加精确和真实。RAG 为 LLM 知识访问受限问题提供了解决方案。它表明,通过将强大的语言模型与外部知识源相结合,我们可以在知识密集型任务上取得更好的结果。
论文链接:https://arxiv.org/abs/2005.11401
2020
Transformers: State-of-the-art natural language processing
《Transformers:最先进的自然语言处理》(2020) Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pierric Cistac、Tim Rault、Rémi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer , Patrick Von Platen, Clara Ma, Yacine Jernite, Julien Plu, 徐灿文, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, Alexander M Rush
Hugging Face Transformers 是一个流行的开源库,建立在 Transformer 架构的基础上。它提供了大量针对各种 NLP 任务的预训练 Transformer 模型,并提供了一个用户友好的 API,让开发人员可以专注于根据特定需求微调模型,而不是从头开始训练大量模型,从而节省大量时间和资源。
论文链接:https://aclanthology.org/2020.emnlp-demos.6/
2020
Language Models Are Few-Shot Learners
《语言模型是少样本学习器》 (2020) Amanda Askell、Tom Henighan、Jack Clark、Benjamin Mann、Dario Amodei、Sam McCandlish、Tom Brown、Pranav Shyam、Rewon Child、Aditya Ramesh、Arvind Neelakantan、Christopher Burner、Christopher Hesse、Clemens Winter、Girish Sastry、Gretchen Krueger、Jeffrey Wu、Mark Chen、Matusz Litwin、Nick Ryder、Prafulla Dhariwal、Sanhini Agarwal、Scott Gray、Ilya Sutskever
本文表明,LLM 只需几个示例(小样本学习)即可学习新任务,这使得它们更适合各种任务,在这些任务中,获取大量标记数据可能成本高昂或困难重重。
这挑战了 LLM 始终需要大量数据才能获得良好性能的传统观点,并凸显了 LLM 的小样本学习能力——提高了样本效率,这意味着仅使用几个示例进行微调就可以在新任务上获得令人惊讶的良好性能,并加快了模型部署速度,这意味着即使在标记数据稀缺的情况下,模型也可以快速适应。
论文链接:https://arxiv.org/pdf/2005.14165
2020
Scaling Laws for Neural Language Models
《神经语言模型的缩放定律》 (2020) Jared Kaplan、Sam McCandlish、Tom Henighan、Tom B. Brown、Benjamin Chess、Rewon Child、Scott Gray、Alec Radford、Jeffrey Wu、Dario Amodei
通过量化模型大小、数据大小、计算机和性能之间的关系,本文在理解如何优化用于训练大型语言模型(LLM)的计算资源方面取得了重大突破。
通过了解这些扩展规律,研究人员和开发人员可以就如何为 LLM 培训分配计算资源做出明智的决策。
论文链接:https://arxiv.org/pdf/2001.08361
2021
Efficiently Modeling Long Sequences with Structured State Spaces
《使用结构化状态空间高效建模长序列》(2021) Albert Gu、Karan Goel、Christopher Ré
这篇论文通常缩写为 S4,它提出了一种利用状态空间模型 (SSM) 处理长序列的新方法。RNN 和 CNNS 很难捕捉非常长的序列(数千个元素或更多)中的长距离依赖关系。S4 通过使用 SSM 来解决这个问题,SSM 具有更有效地处理长距离依赖关系的理论能力。
S4 还引入了一种名为“结构化状态空间”的新参数化技术,该技术提供了一种利用 SSM 的优势来处理长距离依赖关系同时保持计算效率的方法。这为构建能够有效处理非常长序列的模型打开了大门,同时与传统方法相比,训练和使用速度更快。
论文链接:https://arxiv.org/abs/2111.00396
2022
Flamingo: a Visual Language Model for Few-Shot Learning
《Flamingo:用于小样本学习的视觉语言模型》 (2022) Jean-Baptiste Alayrac、Jeff Donahue、Pauline Luc、Antoine Miech、Iain Barr、Yana Hasson、Karel Lenc、Arthur Mensch、Katie Millican、Malcolm Reynolds、Roman Ring、Eliza Rutherford、Serkan Cabi、Tengda Han、Zhitao Gong、Sina Samangooei、Marianne Monteiro、Jacob Menick、Sebastian Borgeaud、Andrew Brock、Aida Nematzadeh、Sahand Sharifzadeh、Mikolaj Binkowski、Ricardo Barreira、Oriol Vinyals、Andrew Zisserman、Karen Simonyan
本文介绍了 Flamingo,这是一种专为 VLP 任务中的小样本学习而设计的视觉语言模型 (VLM)。虽然以前的研究主要关注语言或视觉的小样本学习,但 Flamingo 专门解决了组合 VLP 领域的挑战。Flamingo 利用预先训练的模型进行图像理解和语言生成,从而减少了微调所需的数据量。
论文链接:https://arxiv.org/abs/2204.14198
2022
Training Compute-Optimal Large Language Models
《训练计算优化大型语言模型》 (2022) Jordan Hoffmann、Sebastian Borgeaud、Arthur Mensch、Elena Buchatskaya、Trevor Cai、Eliza Rutherford、Diego de Las Casas、Lisa Anne Hendricks、Johannes Welbl、Aidan Clark、Tom Hennigan、Eric Noland、Katie Millican、George van den Driessche、Bogdan Damoc、Aurelia Guy、Simon Osindero、Karen Simonyan、Erich Elsen、Jack W Rae、Oriol Vinyals、Laurent Sifre
本文探讨了训练 LLM 的最佳计算预算的概念,认为当前的模型往往训练不足,因为人们注重扩展模型大小,同时保持训练数据量不变 - 而为了实现最佳计算使用率,模型大小和训练数据量应按比例缩放。本文介绍了 Chinchilla,这是一种使用这种最佳计算方法训练的大型语言模型。
论文链接:https://arxiv.org/abs/2203.15556
2023
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
《思维链提示在大型语言模型中引发推理》(2023) Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Brian Ichter、Fei Xia、Ed Chi、Quoc Le、Denny Zhou
通常,LLM 可以给出看似正确的答案,而无需揭示其背后的推理过程,但思路链提示可以显著改善大型语言模型 (LLM) 执行推理任务的方式,将推理步骤的示例纳入用于指导 LLM 的提示中,引导其在解决问题时逐步明确地展示其推理过程。
使用这种技术训练的 LLM 在数学应用题、回答常识性问题和执行符号操作等推理任务上表现出更好的表现。
论文链接:https://arxiv.org/abs/2201.11903
2023
Llama: Open and efficient foundation language models
《Llama:开放高效的基础语言模型》 (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard纪尧姆·兰普尔·格雷夫
本文介绍了 LLaMA 系列联邦学习模型 (FLM),该模型的训练重点是效率。这些模型在各种 NLP 任务上实现了最佳性能,同时与以前的模型相比,所需的计算能力更少,这意味着训练时间更快,训练成本更低。
即使使用较少量的微调数据,LLaMA 模型也可能在 NLP 任务上实现良好的性能,这对那些使用有限数据集或需要快速调整模型以适应新任务的人来说大有裨益。
LLaMA 模型还允许开发人员利用预先训练的组件来完成各种任务 - 减少了从头开始构建模型的需要并促进代码重用,从而节省了开发时间和精力。
论文链接:
https://scholar.google.com/citations?view_op=view_citation&hl=fr&user=tZGS6dIAAAAJ&citation_for_view=tZGS6dIAAAAJ:roLk4NBRz8UC
2023
Legged locomotion in challenging terrains using egocentric vision
《利用自我中心视觉在具有挑战性的地形中进行腿部运动》 (2023) Ananye Agarwal、Ashish Kumar、Jitendra Malik、Deepak Pathak
在崎岖复杂的地形上导航是机器人运动的关键挑战。通常,腿式机器人依靠预先构建的地图或复杂的深度传感器来导航周围环境,这限制了它们适应不可预见的障碍的能力,并且需要大量的计算资源。本文的新颖方法是让机器人使用单个前置深度摄像头(自我中心视觉)来感知周围环境并实时规划其运动,从而无需预先构建地图并减少对笨重传感器的依赖。
通过依靠自我中心视觉,机器人可以对看不见的障碍物做出反应,并在楼梯、路缘和不平坦的路面等具有挑战性的地形上导航,使机器人的运动更加稳健并适应现实世界的环境。
论文链接:
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=AEsPCAUAAAAJ&pagesize=80&sortby=pubdate&citation_for_view=AEsPCAUAAAAJ:rO6llkc54NcC
2023
Multimodal Foundation Models: From Specialists to General-Purpose Assistants
《多模态基础模型:从专家到通用助理》 (2023) Chenyu Wang, Weixin Luo, qianyu Chen, Haonan Mai, Jindi Guo, Sixun Dong, Xiaohua (Michael) Xu, Chengxin Li, Lin Ma, Shenhua Gau
多模态基础模型的开发可以处理不同模态(如视觉和语言)的各种任务,这与专注于单一数据类型的传统模型(例如,仅处理图像的图像分类模型)相比具有重大转变。
多模态基础模型在复杂任务上取得了更好的表现,这项研究为开发能够以更自然、更多样化的方式与世界互动的人工智能系统铺平了道路,类似于人类使用各种感官来理解和响应周围环境的方式。
论文链接:https://arxiv.org/abs/2309.10020
以上就是按时间演进的19篇论文。
未来 5 到 10 年,新兴的人工智能将在各个领域实现变革性飞跃。期待开启下一个尖端人工智能技术时代。
文章来源于“人类智能科学与技术”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
