# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
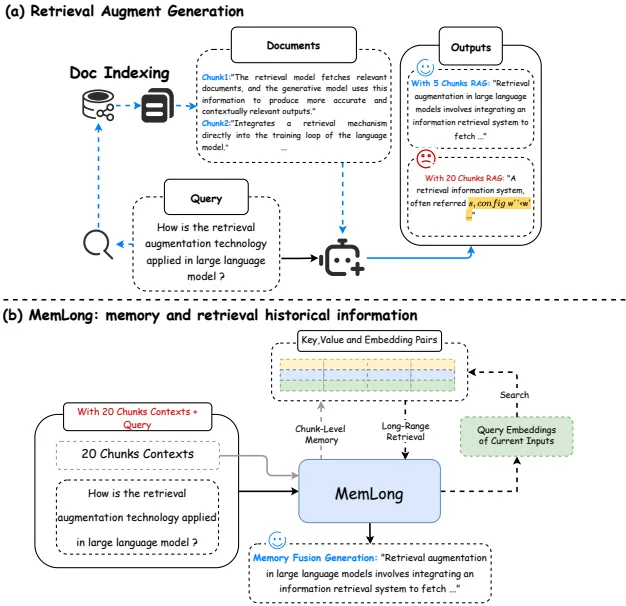
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。MemLong结合了一个不可微的检索-记忆模块和一个部分可训练的解码器-仅语言模型,并引入了一种细粒度、可控的检索注意力机制,利用语义级别的相关块。在多个长文本建模基准测试上的综合评估表明,MemLong在性能上一致超越了其他最先进的大型语言模型。更重要的是,MemLong能够在单个3090 GPU上将上下文长度从4k扩展到80k。

论文:MemLong: Memory-Augmented Retrieval for Long Text Modeling
地址:https://arxiv.org/pdf/2408.16967
这篇论文提出了MemLong,一种用于长文本生成的方法,通过使用外部检索器检索历史信息来增强长上下文语言建模的能力。具体来说,
1.Ret-Mem模块:MemLong结合了不可微分的记忆模块和部分可训练的解码器语言模型,并引入了一种细粒度的、可控的检索注意力机制,利用语义相关的块。
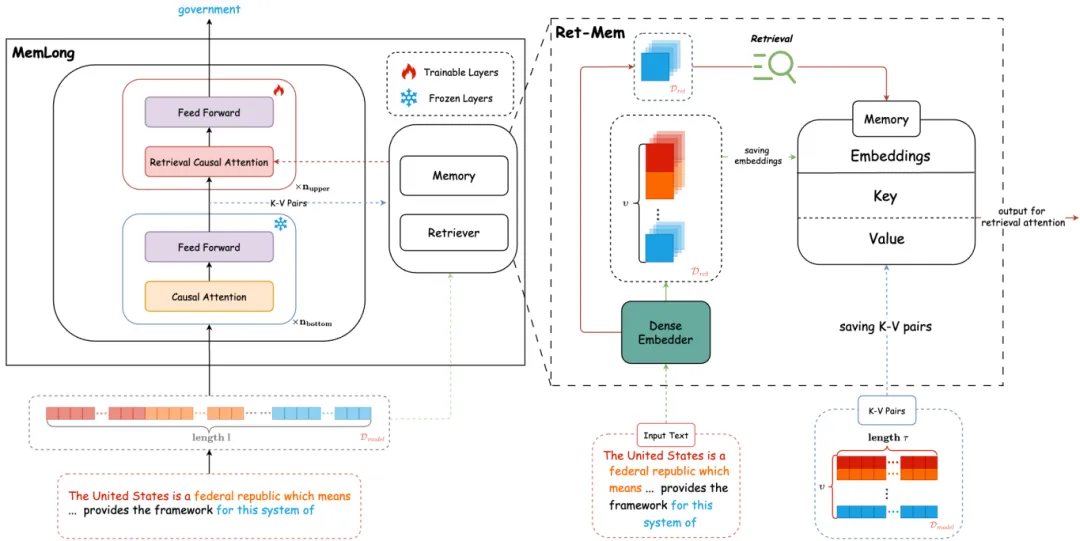
2.检索过程:给定一个文本块,首先通过检索器获取相关的键值对(K-V对),然后将这些K-V对与当前输入上下文结合,调整模型参数以校准检索参考。
3.动态内存管理:当内存溢出时,使用计数器智能更新内存,保留最新、最相关的信息,丢弃最旧的和不经常访问的信息。
4.注意力重构:在模型的可训练上层,修订了注意力机制以融合长期记忆,提出了一种检索因果注意力机制,使每个标记能够同时关注局部上下文和块级别的过去上下文。
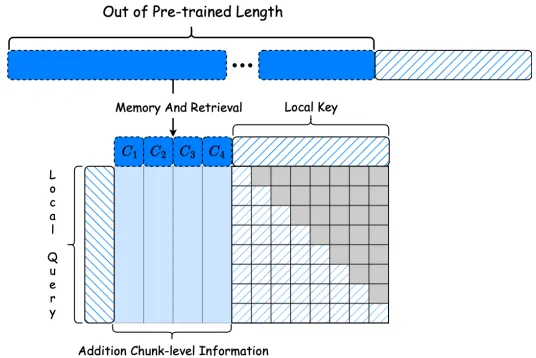
这篇论文提出的MemLong通过利用外部检索器显著增强了语言模型处理长文本的能力。MemLong成功将模型的上下文窗口从2k扩展到80k标记,并在长距离文本建模和理解任务中表现出显著的竞争优势。与全上下文模型相比,MemLong的性能提升了高达10.4个百分点。未来的研究方向包括将该方法应用于不同大小的模型,以及研究更广泛的检索器。
文章来自于“深度学习自然语言处理”,作者“chenyi”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
