# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!
而且性能不减,甚至表现比原始模型还要优异。

这是来自Together AI的新作,通过蒸馏将Transformer和Mamba模型结合到了一起,同时还为混合模型涉及了推理加速算法
提出Mamba架构的大神、FlashAttention作者Tri Dao,也参与了这一项目。
Together AI创始人兼CEO表示,Transformer和Mamba的混合,是未来大模型的一大发展方向。

在蒸馏正式开始之前,需要先进行从Transformer到线性RNN的初始化。
作者观察到,Transformer的注意力机制与RNN的计算之间存在一定的相似性。
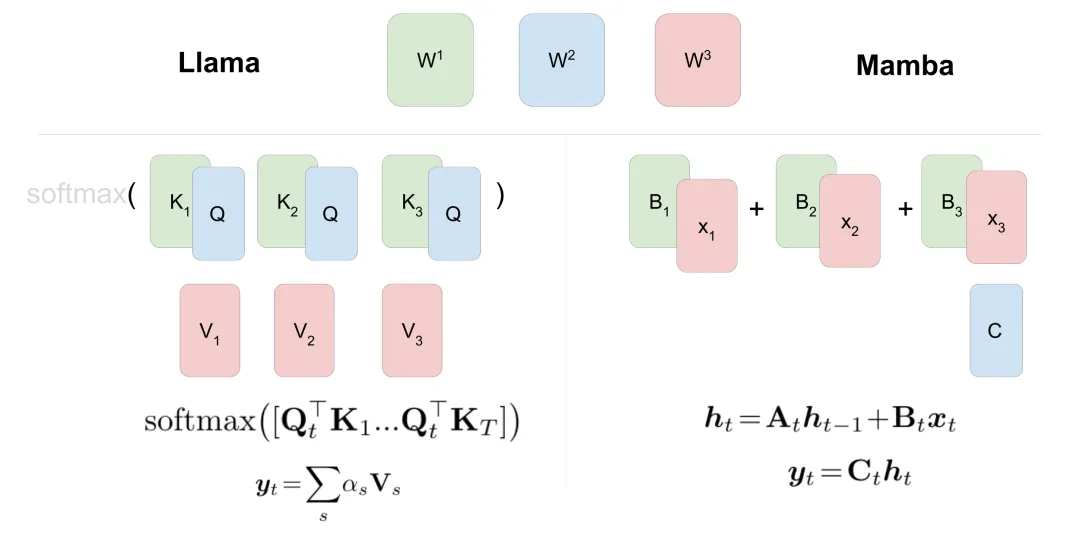
因此可以将Transformer的注意力线性化,从而建立二者的联系。
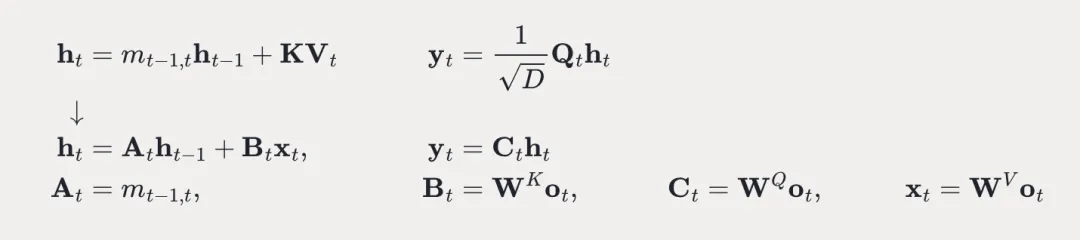
利用这种对应关系,可以将预训练的Transformer模型的参数复制到Mamba模型中。
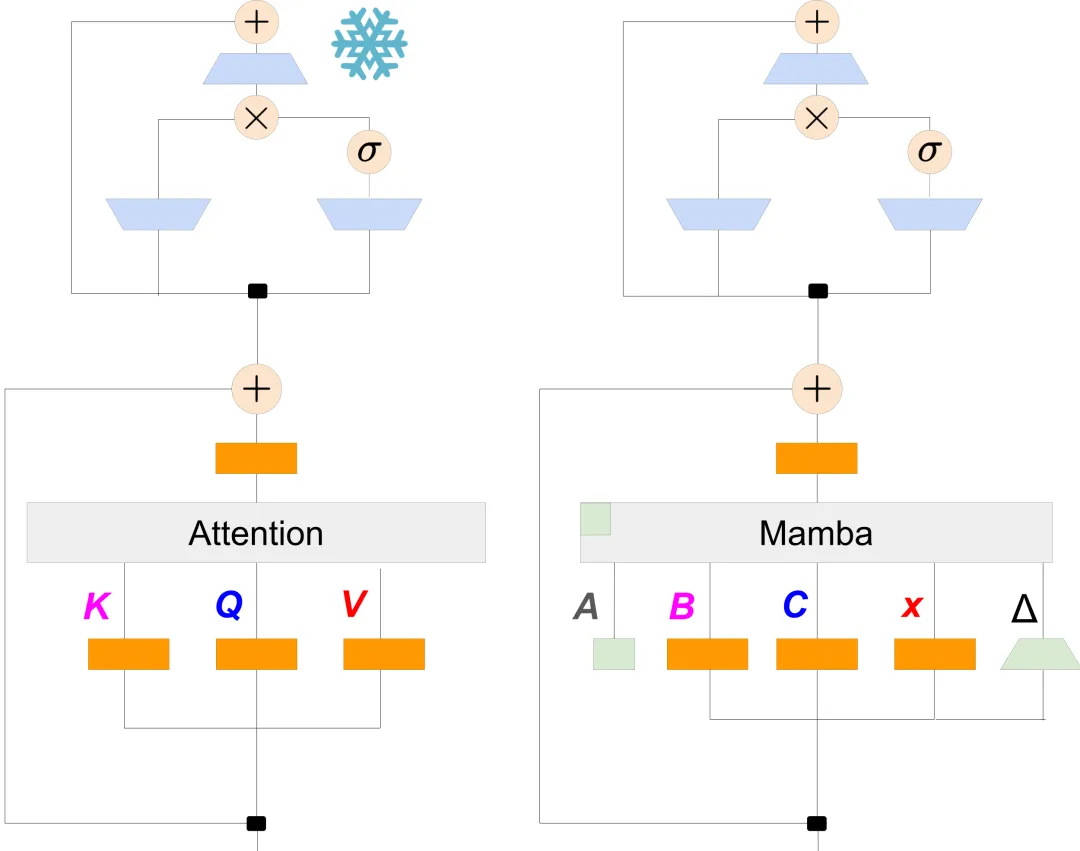
在完成参数初始化后,作者采用了一个三阶段的蒸馏流程进一步提升Mamba模型的性能,使其更好地学习Transformer的知识。
第一阶段是基于伪标签的蒸馏——使用预训练的Transformer教师模型在无标签数据上生成伪标签,然后让Mamba学生模型在这些伪标签上训练。
这一过程的损失函数结合了KL散度损失和交叉熵损失,分别用于模仿教师模型输出分布以及伪标签的拟合。
第二阶段是在指令数据集上进行的监督微调,使用带标签的指令数据集(如OpenHermes 2.5)进行训练。
最后一个阶段,是用人类反馈数据,通过基于奖励模型进行优化。
作者收集了人类对模型输出的反馈数据,然后据此构建一个奖励模型并使用 RL 算法(如 PPO)来优化模型在该奖励模型下的表现。
在8块80G A100 GPU上,每个混合模型的整个蒸馏过程,只需不到五天的时间。
通过以上的蒸馏过程,作者得到了Transformer-Mamba混合模型,之后又提出了Speculative Decoding(推测解码)算法来加速推理过程。
推测解码算法的基本思想是使用一个轻量级的Draft模型来预测多个token,然后再用验证模型(Verifier)来验证这些预测。
这样可以显著提高解码的并行性,加速生成过程。
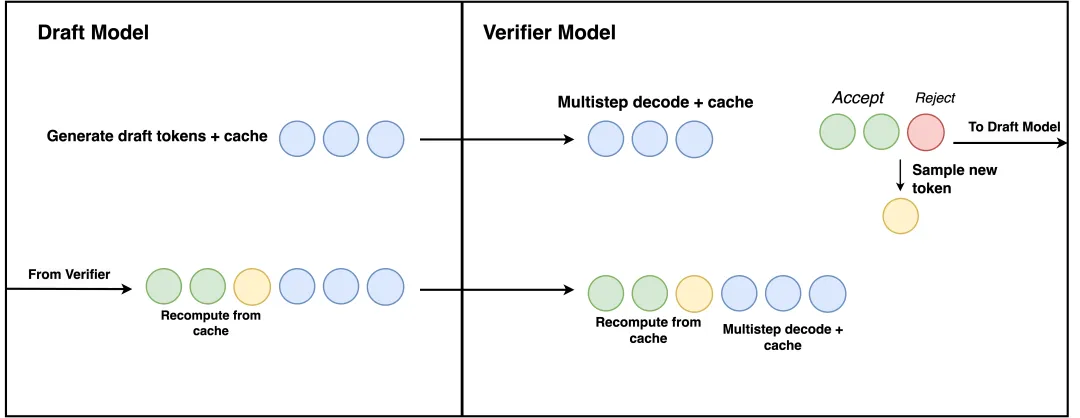
Draft模型通常是一个小的Transformer,根据当前的上下文预测出接下来的K个token。
对于预测出的K个token,Transformer层可以直接并行地处理这K个token,计算它们的隐状态;
Mamba层则需要按照顺序依次处理每个token,首先计算当前token的隐状态,并将其与之前的隐状态进行比较。
如果序列中的所有K个token都被接受,则将它们添加到输出序列中,并继续预测下一组token。
如果有token被拒绝,则从第一个被拒绝的token处截断预测序列,并返回初始步骤从该位置开始重新预测。
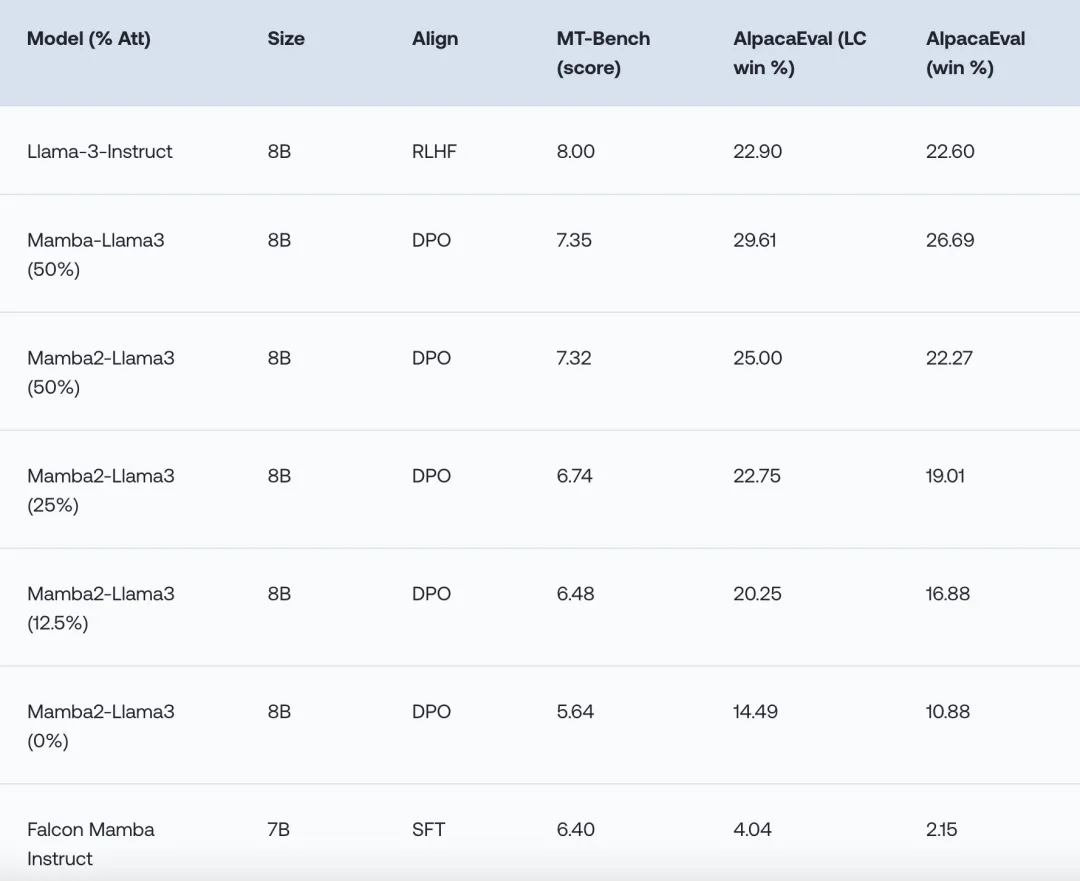
测试结果表明,混合模型在单论(AlpacaEval)和多轮(MT-Bench)聊天对话任务上与Llama-3相当甚至更优。
并且还对不同混合比例的模型表现进行了测试,发现其中按照1:1比例混合的模型表现最佳。
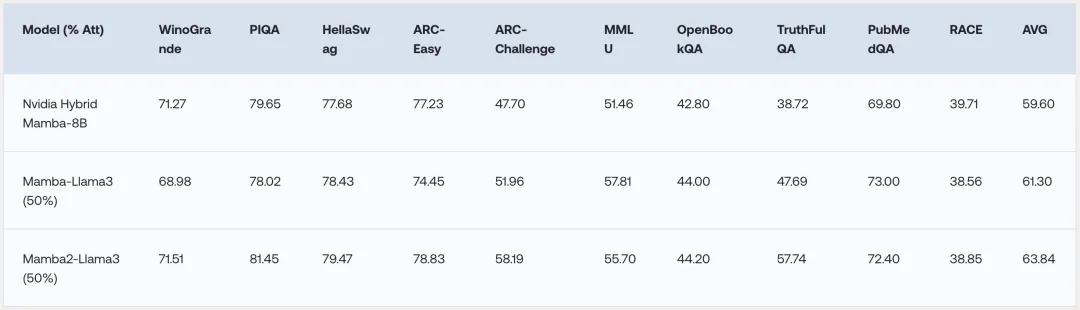
在零样本的通用 NLP 任务评测中,混合模型的平均成绩优于同等规模的RNN模型。
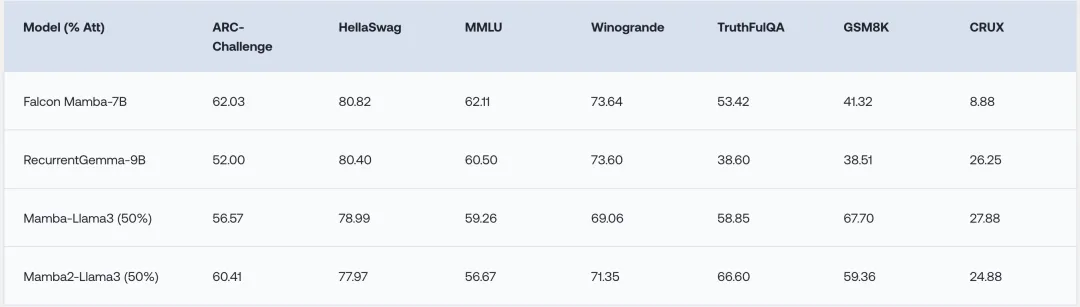
在少样本的OpenLLM Leaderboard榜单上,混合模型的表现与最好的开源RNN模型相当,并在GSM8K和CRUX任务上超过了对应的Instruct模型。
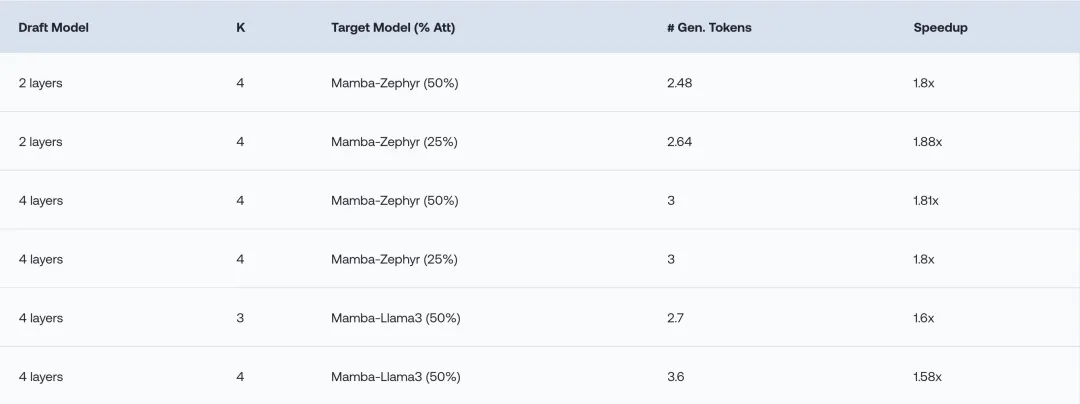
除了模型性能,作者也对推测解码算法带来的加速效果进行了测试。
首先测试的是纯Mamba模型,结果在2.8B和7B的模型上,相比原来的解码方式,推理速度提升了1.7-2.6倍。
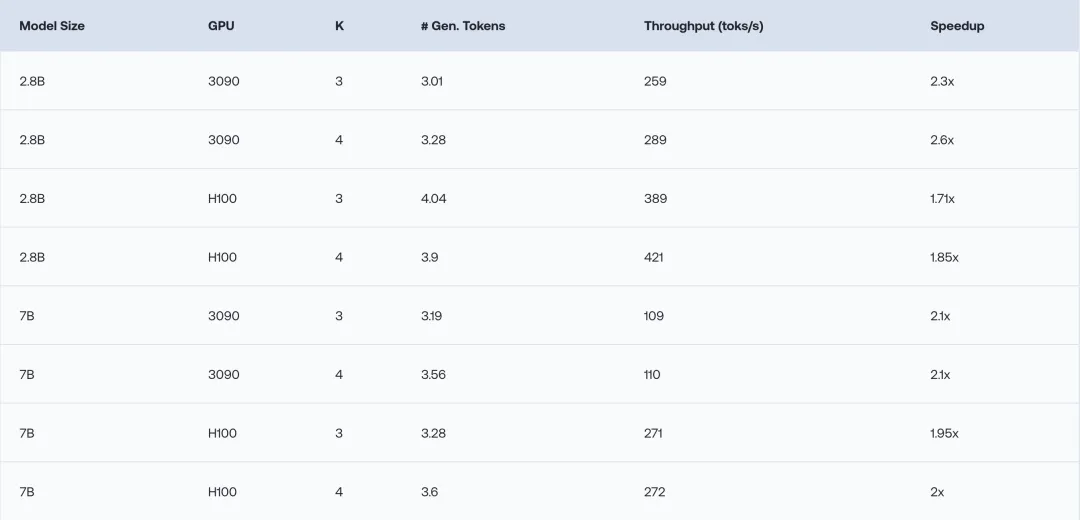
进一步地,作者在蒸馏的Zephyr和Llama混合模型上进行了测试,结果Zephyr混合模型的推理速度提升了1.8倍以上,Llama混合模型也有1.6倍左右的加速。
文章来自于“量子位”,作者“克雷西”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
