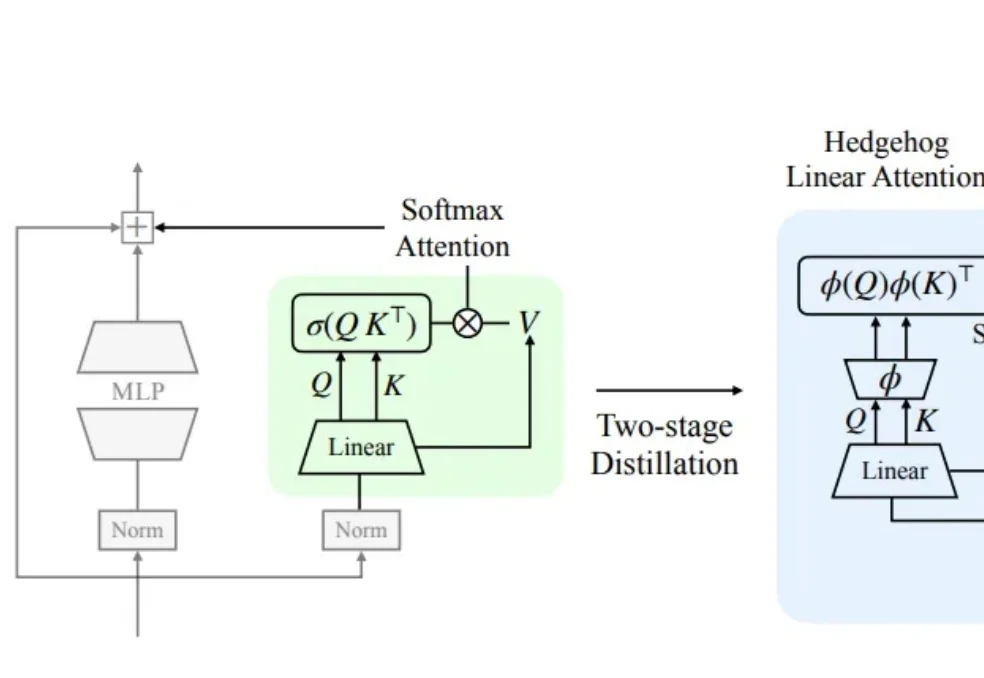
Transformer可以改装成Mamba了:苹果把推理成本直接打成线性
Transformer可以改装成Mamba了:苹果把推理成本直接打成线性最近,苹果又整了个活儿,很工程、也挺关键: 把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。
来自主题: AI技术研报
8850 点击 2026-04-23 14:46
 搜索
搜索
最近,苹果又整了个活儿,很工程、也挺关键: 把又贵又强的 Transformer,改造成又便宜又差不多强的 Mamba。而且,性能基本没怎么掉。

Transformer不保?今天,CMU普林斯顿原班人马杀回,新一代开源架构Mamba-3震撼降临。15亿参数战力爆表,性能比Transformer飙升4%。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:
压缩即智能,又有新进展!
都说苹果AI慢半拍,没想到新研究直接在Transformer头上动土。(doge) 「Mamba+工具」,在Agent场景更能打!
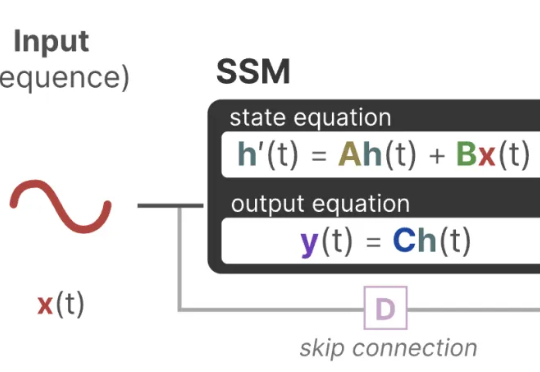
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。
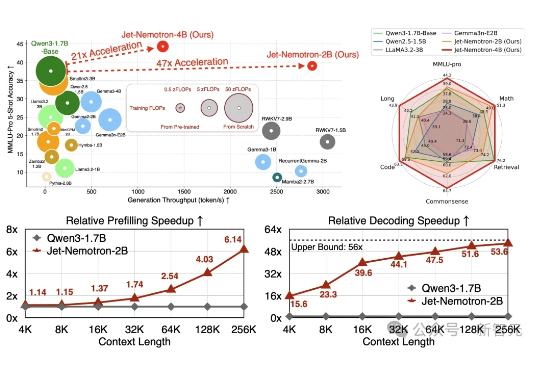
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
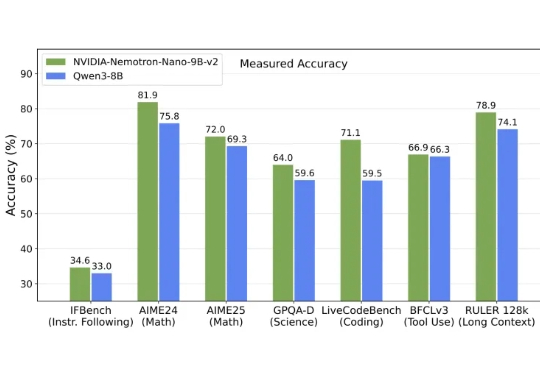
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。
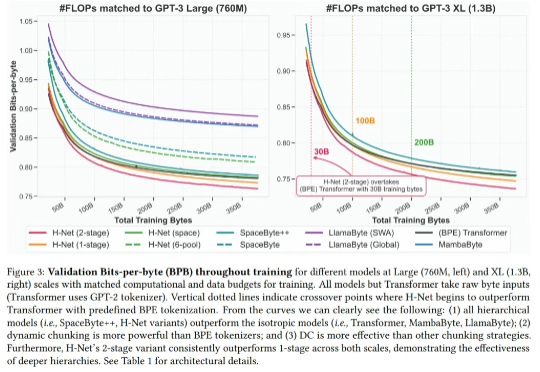
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
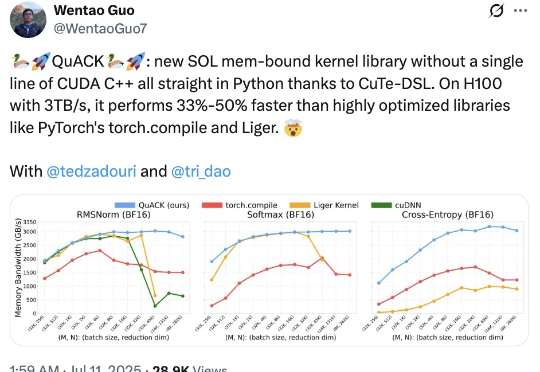
无需CUDA代码,给H100加速33%-50%! Flash Attention、Mamba作者之一Tri Dao的新作火了。