
「Tokens是胡扯」,Mamba作者抛出颠覆性观点,揭露Transformer深层缺陷
「Tokens是胡扯」,Mamba作者抛出颠覆性观点,揭露Transformer深层缺陷「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
来自主题: AI技术研报
7538 点击 2025-07-10 13:16
 搜索
搜索
「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。

普林斯顿大学和Meta联合推出的新框架LinGen,以MATE线性复杂度块取代传统自注意力,将视频生成从像素数的平方复杂度压到线性复杂度,使单张GPU就能在分钟级长度下生成高质量视频,大幅提高了模型的可扩展性和生成效率。
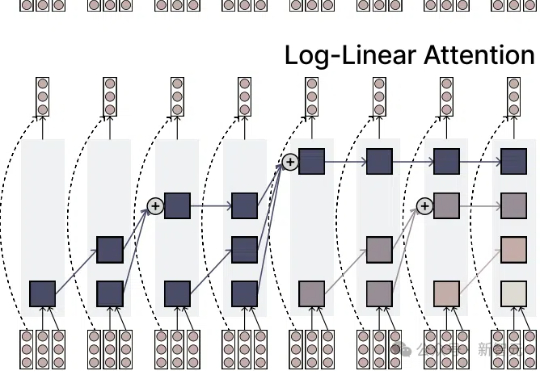
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
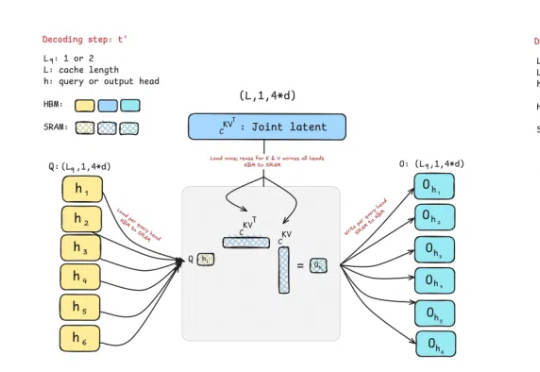
曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——提出两种专为推理“量身定制”的注意力机制。

Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度

2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。
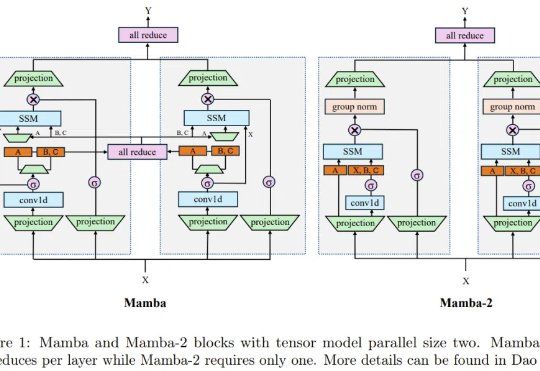
在过去的一两年中,Transformer 架构不断面临来自新兴架构的挑战。

首个基于混合Mamba架构的超大型推理模型来了!就在刚刚,腾讯宣布推出自研深度思考模型混元T1正式版,并同步在腾讯云官网上线。对标o1、DeepSeek R1之外,值得关注的是,混元T1正式版采用的是Hybrid-Mamba-Transformer融合模式——
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。