# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本篇是「AGIX 投什么」系列的第 5 篇。AGIX 指数是拾象设计的追踪 AGI 科技革命的指数,是我们在全球科技上市公司中精选出的“高 AI 纯度”公司的组合。AGIX 指数是定位 AI 进程的坐标,也为投资人捕捉 AI-alpha 提供了一个价值工具。在「AGIX 投什么」板块,我们既会对 AGIX Index 的组合公司进行深度分析,也会以一二级融合的视角为市场输出全面的 AI 投资参考。
OpenAI 的草莓模型发布在即,RL 新范式会给算力基建带来哪些影响? scaling law 将如何演化?与此同时,Nvidia 和 Tesla 在近期出尽利空之后重回涨势。在 2024 年的最后一个季度,伴随 OpenAI 和 Anthropic 两个新模型密集发布, AI 板块会迎来新一轮上涨周期吗?
Gavin Baker 是 Atreides Management 的创始人和 CIO,他参与硬件领域投资已经有25 年的时间,经历了多个技术和科技投资周期。他不仅从 2000 年就作为 Fidelity Investment 分析师开始覆盖 Nvidia,也从相当早期就追踪 Tesla。Gavin Baker 目前在 Nvidia 和 Tesla 上也有很多仓位。
本篇内容是 Gavin Baker 对于模型竞赛格局、硬件环节的投资机会以及 AI 领域关键公司的分享:
• Mag 7 除了 Apple 几乎都进入了模型训练的竞赛,甚至陷入了“囚徒困境”,短期内没有人敢停止训练新一代、更大规模模型,而 Apple 因为掌握了模型的分发,并没有陷入类似状况;
• 评价 AI Labs 除了看他们训出的模型水平,还可以考虑训练模型的效率,而模型训练效率和模型进入市场的先发优势、训练成本等又直接相关;
• 过去 5 年中 GPU 的计算速度提升了 50 倍,但数据中心的其他环节只提升了 4-5 倍,在实际计算和推理过程中,GPU 很多时候其实是在等待其他硬件环节,从优化训练和推理效率的角度出发,内存、互联等环节同样值得投资;
• 市场关于 AI ROI 的讨论是无意义的,如果看 Mag 7 的 AI ROIC 就会发现 AI 已经开始带来实打实的正面效应;
• Gavin Baker 十分看好 Tesla,他认为接入了 AI 的 Tesla 可能是最先对现实世界产生影响的机器人,在通用机器人领域,他也很看好 Tesla 的 Optimus。
目录
01 LLM 是 Mag 7 间的生存竞赛
02 硬件投资:关注模型训练的效率公式
03 模型的数据挑战
04 为什么 Apple 没陷入 LLM 囚徒困境?
05 纠结 AI ROI 是无意义的
06 Tesla:机器人浪潮的直接受益者
01.
LLM 是 Mag 7 之间的生存竞赛
Patrick: 你之前在 X 上发表过一个观点,认为 GenAI 可能会是 Mag7 公司之间第一次真正的关系到公司生存的“战争”,可以展开聊聊这一点吗?

The Magnificent Seven 的概念出自一部经典的美国西部片,《豪勇七蛟龙》,于 1960 年 10 月 23 日上映。电影根据日本导演黑泽明的经典作品《七武士》(Seven Samurai)改编而成,将故事背景设定在了美国的墨西哥边境,七个美国枪手被雇佣来保护一个被强盗头目加维拉(Calvera)控制的村庄。
Gavin Baker: 我认为 Mag7 的公司每个都有自己专攻的业务领域,但他们确实在云计算领域出现了一些交集,比如说 Google、Amazon 和 Microsoft 都有自己的云计算板块。
云计算整体上是一个相对稳定的寡头垄断市场。Google 在 2014、2015 年左右选择了通过降价来参与云计算的竞争,Amazon 也紧随其后,这种价格战实际上在很大程度上限制了 Amazon 的营收增长,也让市场开始担心云计算变得 commodity。这件事在当时的讨论度非常高,不过现在回过头看这些担忧其实非常荒谬。
我其实认为目前 Mag7 公司之间处于这样一个阶段:Microsoft、Google 和 Amazon 三家之间其实就云计算的定价达成了某种一致,与此同时,这几家公司之间也希望在其他方面作出一些差异化:
• Amazon 有电商,
• Google 有搜索,
• Meta 有广告,并且 Meta 的广告和 Google 的搜索广告相比,位于流量漏斗的上游,
• Apple 很明显掌控了终端、操作系统和应用商店,可能面临来自 Android 的一些竞争。
• Netflix 在做流媒体,虽然和 Google 存在一些竞争,但它们的市场定位相对独立。
• Microsoft 除了云服务外,还有提高生产力的大规模企业软件业务。
但现在他们进入了一个新阶段,随着 GenAI 和 LLM 这些通用的技术出现,这些大公司发现各自站到了同一赛道上,而他们在 GenAI 上的竞争可以说是关系到生存。
Mark Zuckerberg、Satya 和 Pichai 分别都表示过他们在 GenAI 上的投入是不考虑 ROI 的。这几个人要么是公司创始人、要么是内部决策者,这些人已经非常相信自己正处在一场数字化造神的竞争中。无论哪家公司先获得成功,其价值都能达到数十万亿甚至数百万亿,而输掉这场竞赛对公司而言是致命的,这就是他们的信念。Larry Page 就曾多次在 Google 内部表示,宁愿破产也不愿输掉这场比赛。
真正做决策的人并不关注 GenAI 上的 ROI,因为他们坚信 scaling law 会起作用,模型的性能会更高,推理能力也会更强。所以他们会一直加大 AI 投入,直到模型的进展放缓,这是 scaling law 失效的唯一证据。
从 GPT-4 发布到现在,其实 NVIDIA 一直还没有新一代 GPU 问世,这件事相当关键,因为接下来模型能力的飞跃和硬件升级十分相关,Blackwell 的延期也会影响到模型迭代。要创建一个成千上万个 GPU 构成的一个一致性的训练集群(Coherent training system)相当难,所谓 coherent,是指集群中的 GPU 互相之间能够直接通信。技术层面,这些 GPU 共用了一个内存。目前世界上最大的训练集群是 3.2 万个 GPU,但因为效率原因,单次最多也只能调用 1.5 万 - 1.6 万张 H100。
Coherent memory system 源于 CPU 系统里有这个概念,这里被挪用到 GPU 集群上。Coherent meomory 的特点是:
• 当处理器读取某个内存位置时,它会得到最近写入该位置的值,从而确保数据的时效性和一致性
• 对同一内存位置的写操作是按顺序进行的,所有处理器看到的写入顺序是一致的,这避免了不同处理器之间对数据更新顺序的混淆;
•如果一个处理器先写入后读取同一位置,且期间没有其他写操作,那么读取的值就是之前写入的值,从而保证了单个处理器操作的连贯性和可预测性。
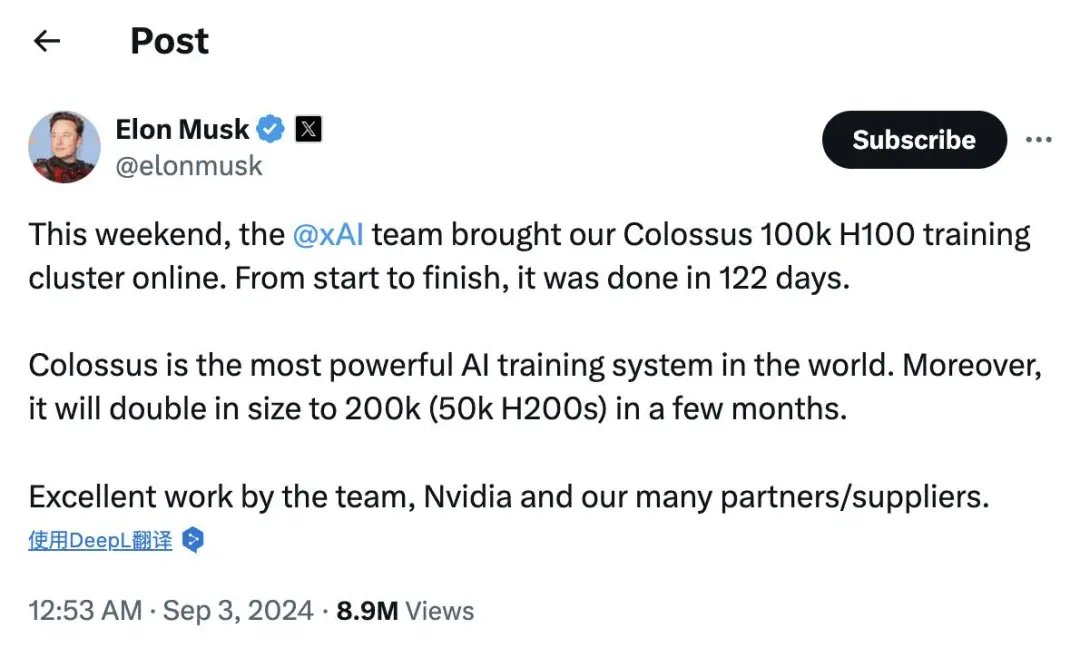
xAI 的计划是搭建一个 10 万卡集群,我觉得 Elon Musk 在物理工程项目上有他独特的思考,外界已经通过 SpaceX、Tesla 和 Neuralink 看到了这一点。
我认为 Elon Musk 是从第一性原理出发去重新设计了 xAI 位于孟菲斯的数据中心。这个数据中心的架构和其他数据中心很不一样,也因此,即使 Nvidia、Broadcom 目前还没推出下一代互联技术,xAI 也能实现足够的 GPU 密度、构建一个 10 万卡集群来进行训练。这也意味着,第一个 GPT-4.5 的模型可能会在未来 6 到 9 个月内出现,有了 Blackwell,有了下一代互联技术之后,集群规模可能可以扩张到 30 万张 GPU。到那时我们甚至可能会看到 GPT-5、5.5 甚至 6。
一旦 GenAI 能够达到 ASI 水平,我们可能会去想,既然 AI 能够创造出比人类更优质的内容,内容的价值又何在?现在你甚至可以看到把《星际迷航》和《星球大战》混合在一起生成的内容,那么 Netflix 的价值会发生什么变化?我们要意识到搜索功能很可能会被 agents 取代。
Tiger Global 的管理合伙人 Chase Coleman 分享过一个很有意思的数据:2022 年的 ChatGPT 之于 AI 就如同 1994 年 Netscape Navigator 之于互联网。
在 Netscape Navigator 诞生后 2 年内成立的公司市值在今天占全球互联网市值的不到 1%,当时没有人能预见到之后还有哪些公司会成立,实际上,今天很多伟大的公司都是之后的 5、6 年间才成立的。我们现在仍处于 AI 相当早期的阶段, scaling law 依然有效,所以要对技术的进步保持谦逊的态度。
Scaling Law 被颠覆的唯一一种可能性是:新一代 GPU 带来 3 到 5 倍的性能提升,网络技术更好,可以将 3 到 5 倍的 GPU 连接在一起,如果某一天算力提升 10 倍,但模型质量却没有显著改进,那么 scaling law 就不再适用,这对整个数据中心基础设施来说将是一场灾难。但 AI 领域的人目前都相信 scaling law 会持续有效。
02.
硬件投资:关注模型训练的效率公式
Patrick O'Shaughnessy:你在 25 年前就进入到半导体领域了,今天很多人都在讨论模型,但对硬件的关注可能还不够充分,你是怎么看硬件领域的?
Gavin Baker:硬件的确很重要。我在 Nvidia 和 Tesla 刚上市的时候就在关注这两家公司了,从 2000 年开始覆盖 Nvidia,今天我在这两家公司上也有很多仓位。Elon Musk 和 Jensen Huang 是我见过的最好的两个 CEO,AMD 的 Lisa Su 可能紧随其后。Lisa Su 刚接手 AMD 的时候,AMD 的负债率接近 5 倍,比 Intel 落后了 4 年的水平,据说当时只有 20 天的现金储备。现在 AMD 已经全面超越 Intel 了。Santaya 也很厉害,他接管微软的时候虽然微软的收入和利润都很不错,但运营地并不好。整体上,我的确在硬件领域投入了相当长的时间。
那么我们目前所处的情况又是什么样的?首先,你在播客中也提到过很多次,科技投资是很重要的,过去三四十年来科技板块表现一直很好,有一个原因就是软件的边际成本为 0 ,公司的毛利率和经常性收入极高。AI 则恰恰相反,AI 的边际成本非常高,因为 scaling laws 就意味着想要提高质量,唯一的办法就是加大投入。
这也是 scaling law 想要强调的,如果我们相信 scaling law,就会知道 AI 的边际成本很高。基于各种各样的原因,这些边际成本下降得非常快,但对于最前沿的模型尝试,尤其是在训练和推理方面,成本仍然非常高,不过推理的成本比训练要低得多。推理和训练是两个完全不同的领域。
边际成本高对于模型公司来说,也意味着,如果要取得成功,infra、训练效率和模型性能都是很关键的因素。
我们现阶段可以使用 MFU(Model FLOPS Utilization,模型 Flops 利用率 ) 这个指标来衡量模型训练效率,MFU 指的是在模型训练中,实际能够利用的 Flops 占理论层面的百分比,目前一般在 35% 到 45% 之间。
很多公司之前都公布过自己的 MFU,但随着竞争的加剧,大家不再公布这一数字,但 GPT-3、Google LaMDA 和 Nvidia Megatron 的论文都提到过自己的 MFU,基本在 20% 多到 30% 多这个区间。Google 的 MFU 最高。
更高的 MFU 意味着在资金投入相同,同等级的 GPU 储备、电力消耗下,可以更快地训出模型。如果某个模型公司的 MFU 是 50%,对手的是 40%,在同等算力的情况下,它训模型的速度能够比对手快 45% 。
除了更快训出模型,MFU 更高也意味着模型公司可以通过拉长训练时间来提升模型质量,或者尝试各种方式来降低模型训练成本,现在大家尝试的比较多的方式是量化(quantization)。简单来说,在MFU 更高、量化技术更好的前提下,如果模型质量能提高 25%,就意味着推理成本能降低近 50%。也就是说,如果模型公司能够通量化把模型成本降低一个等级,这将会是很大的优势。
所以如果要有一个指标来评估 AI labs 的水平,MFU 会是一个不错的选择。因为今天单从模型能力上看的话,市场上已经有 5 个 GPT-4 水平的模型了,OpenAI、Google、Anthropic、xAI 和 Meta。Mistral 相对靠后一些,但 Mistral 也很厉害,因为它们的模型在参数量很小的情况下,依然能在所有评估中取得很好的结果。
我认为今天来看,模型确实已经 commodities 了,但如果 scaling law 还能继续,GPT-7、GPT-8 的训练成本还要更高,要花费 5000 亿美金来训练,那就还没有 commodities。
MFU 之所以重要是因为它能够帮我们在这么多都训出了 GPT-4 水平的模型公司之间找出差异化和各自的优势。
但我觉得有一个比 MFU 更好的测评标准,既是对 MFU 的补充,也把我们标准更细化了 。我们可以把它看作一个统一的 AI 效率方程,把 MFU 拆成两个方面。一是 MAMF,也就是最大可达矩阵乘法 FLOPS(Maximum Achievable Matmul FLOPS),它衡量的是软件效率,这就聊到了 CUDA。
MAMF 是 Stas Bekman 提出的概念,他在 X 上发了一篇内容来讲这件事。MAMF 的逻辑是,每张芯片都有一个理论层面的最佳性能,通过 Flops 的计算可以很容易得出,与此同时,Stas Bekman 也观测了每个芯片的实际表现,在他的测试中,Nvidia 是 83%,这只是单张 GPU 的具体表现,有的 AI labs 实际可以做到 90%。AMD 之所以花了很长时间才进入这个领域,是因为对于半导体硬件,通常要等到第三代芯片才能实现这种性能。Google 的 TPU 也经历了类似过程。
AMD 的 Instinct MI300 是一款不错的芯片,但他们的软件表现不尽如人意,既没有内部能力去改进,也没人花时间改进。所以 Instinct MI300 刚推出时,MAMF 只有 25% 到 30%。但根据 Stas 的测试,现在它的 MAMF 已经提高到 60% 了,而且因为它的 FLOPS 更多,实际上它的性能已经稍微超过了 Nvidia 的 GPU。
我觉得这是概念化和量化 CUDA 优势的好办法。Nvidia 的 GPU 性能利用率能达到 83%,而 AMD 最初只有 25%。AMD 的 Instinct MI250 也是一款不错的芯片,但是没什么人用它,因为它的 MAMF 可能只有 10%。
MAMF 决定了芯片软件的质量能有多好,以及使用者能把软件优化到什么程度。
Netflix 过去说它们比 Amazon 更懂怎么高效利用 AWS,很多人也说一些 AI labs 比 Nvidia 更懂怎么高效利用 CUDA,这些 AI labs 的性能利用率能达到 95%,比 Nvidia 的 83% 还要高。但为什么现如今我们的 MFU 只有 35%到 40%?我觉得可以用 SFU (system FLOPS efficiency)来解释这件事。
SFU 涵盖了互联、存储、内存的方方面面,我们可以用 MAMF 乘 SFU,再乘上每次训练中在 checkpoint 用时的百分比。这些因素相互叠加,得出的结果非常惊人。
这里可以先解释一下 checkpoint,我在前面说过,训练集群之间需要 coherent,也就是说 GPU 之间需要相互协作。一旦任何一个 GPU 出故障,那从上一次保存模型(也就是上一个 checkpoint)开始,所有的数据都会丢失。而 GPU 经常会出故障或者过热。
如果有人读过 Llama 3 的技术论文,就会发现 GPU 出故障的原因各种各样、让人难以置信,optical、switch 等环节都会有出现故障的可能。在为每一个 GPU 提供支持的互联、存储、和内存的链路上,存在太多可能出现问题的地方,而一旦存储、内存和互联这些环节发生问题,GPU 就毫无价值。
如果要彻底搞清楚这一点,我建议每个人都可以去组装一台游戏主机来体验一下。因为每一台计算设备,无论是 iPhone、笔记本电脑、甚至数据中心,都可以抽象成 4 个基本要素,内存、存储、计算,和将这些要素连接起来的互联。
当我们自己组装游戏主机的过程,实际上就是把这四个要素做组合。我们得先通过 PCI Express 把 GPU 和 CPU 连起来,然后再插到 DRAM 里实现连接,接下来还要把 DRAM 和闪存连接起来。
如果我们把数据中心或者计算机比作一家餐厅,那么在 AI 服务器中主要的计算单元 GPU 就是主厨。没有食材、原料和厨具,主厨也难为无米之炊。存储设备就像是送餐的卡车,它通过 PCIe 连接到服务器的其余部分,这就是互联技术,好比是把食材从卡车运到餐厅冰箱里。
举一个不太恰当的例子,我们可以把冰箱看作是内存,在数据从内存传递到 CPU 再传到大型 DRAM 池之后,CPU 才能开始运作。再把数据传到 GPU 的内存里,GPU 才能开始运作。GPU 内存就好比炉灶,CPU 和 GPU 之间的连接就相当于主厨和副手之间的协作。但一切的一切都需要有厨具和食材。
过去 5 年中,GPU 的计算速度提升了 50 倍,但数据中心的其他环节只提升了 4-5 倍,这也是为什么 MFU 这么低的原因。因为在实际计算过程中,GPU 很多时候其实是在等待其他硬件环节。
所以我认为投资下一代互联、存储和内存技术非常重要,尤其是互联,因为如果我们想要构建一个百万卡集群,比如说 Blackwell 的下一代架构 Rubin,那么每个环节都需要取得突破,否则 GPU 的性能就被浪费了,MFU 可能只能达到 3% 到 5%。
这又会回到 checkpoint 的问题,由于整个链路中有很多故障点,数据中心的 GPU 经常出故障,有时甚至会因为过热而烧毁,其他组件也会经常出故障。一个百万卡集群可能有 32000 个这样的“厨房”,一旦任意一个环节失误,整个集群都会崩溃。因此,模型训练中就要经常做 checkpoint,保存模型关键信息。
如果能改进网络拓扑技术,或者能更好地冷却 GPU,降低故障率,让集群更可靠,就可以降低 checkpoint 的频率。假设有一家公司的 MAMF 是 90%,SFU 是 50%,那么利用率就是 45%,如果 1/3 的时间花在了 checkpoint ,那么 MFU 就只有 30%。
如果有另一家公司,因为很擅长使用 CUDA ,它们的 MAMF 能达到 100%,SFU 能达到 60%,那么利用率就有 60%,相比起上一家的利用率,已经有 33%的差距了。如果 checkpoint 的占比为 10%,那么这家公司的 MFU 就能达到 54%,而竞争对手的 MFU 可能只有 30%。这还不包括最后要考虑的的 PUE,即电源使用效率(power utilization efficiency)。
PUE:电源使用效率(power utilization efficiency),指计算机数据中心使用能源的效率,是计算机数据中心总电源消耗量与 IT 设备电源消耗量之比。
电力消耗是有成本的,电力也是大型集群中越来越重要的因素。在美国,当前大概只有个别地方能够可靠地给单体数据中心提供多达 1 吉瓦的核电。美国平均每千瓦时的电费大概是 0.08 美元,但是这三个地方的电价大概是普通电价的 10 倍。所以电力成本和 PUE 也就变得相当重要。
并且,当我们围绕 SFU 做优化的时候,可能会提高 PUE。所以我估计很多 AI labs 都会在这两者之间不断地做周密计算、算成本、做 trade-off。比方说,如果在互联上花了 2 倍的费用,SFU 的确能大幅提高,但 PUE 也会随之上涨,这样一来就不划算了。
综合每一个环节的计算后,我们最终想要得到的,不仅仅只是每秒的 ExaFLOPS,更重要的是每美元 CapEx、每瓦电的 ExaFLOPS,我上面提到的方程能把这些都涵盖进去。
不同的人对于计算架构要怎么设计有不同的思路,而数据集的架构在设计决策中相当重要。在构建 10 万卡集群方面,有些公司每美元 CapEx、每瓦电的 ExaFLOPS 角度有绝对优势,未来这就是 AI labs 之间的差距,这个差距决定了 GPT-7 或 GPT-8 的成本是 1 万亿美元还是 5000 亿美元,决定了再下一代的成本是 2000 亿美元还是 4000 亿美元。
ExaFLOPS: 衡量超级计算机性能的单位,表示该计算机每秒可以至少进行 10^18 (百亿亿)次浮点运算。根据 NVIDIA 官方信息,NVIDIA 为了更好的发挥 Blackwell 架构的性能,设计了一个集成了 CPU 和 GPU 的超级芯片组(NVIDIA GB200 Grace Blackwell Superchip),该芯片组搭载了两个 NVIDIA B200 Tensor Core GPU 和一个 NVIDIA Grace CPU,并通过 NVLink 芯片间互联技术连接在一起。而集成了 36 个 Grace Blackwell Superchip 的计算系统 NVIDIA GB200 NVL72,可以实现 1.4ExaFLOPS 的 AI 计算性能。
推理也一样,不仅影响 serve 模型的成本,还直接影响用户体验,比如每秒能处理多少 token,Google 的搜索用户体验就非常依赖这个指标。不过推理基本上取决于内存带宽和片上内存,所以计算起来要简单一些。
Patrick O'Shaughnessy:Vaclav Smil 之前提过一个关于能源的观点,他把能源定义为 primer movers,比如化石燃料、风能等等都可以算是 primer movers,每一种新的 primer mover 从发现到高效利用都要经历一个漫长的时期。举个例子,蒸汽机时代,我们可能只能开发了煤炭能源的 10%-15%,但今天我们对煤炭的能源利用率已经达到了 98%。所以看起来 GPU 也会经历类似的过程。
Vaclav Smil:加拿大学者,主要研究方向包括能源、环境、食品生产、技术创新以及公共政策,涵盖了从能源转型到全球发展等广泛主题,被认为是能源和环境领域最具影响力的学者之一。代表作是 Energy and Civilization: A History ,是比尔•盖茨 2017 年度书单图书。
Gavin Baker:能源利用的本质是通过不同的能源转化机制把太阳能转化为可用能源。对于 AI 来说,就是把太阳能转化为算力。能源的来源可以是字面意义上的阳光,也就是太阳能,也可以是人造的能源,比如核能。而化石燃料实际上是储存起来的太阳能。但不论采用何种供能手段,这本质上是一个把能源转化为算力的效率问题,以及人们需要为这个转化比率所支付的成本。
03.
模型的数据挑战
Patrick O'Shaughnessy:你在一开始提到了模型竞赛,除了硬件,数据、应用层也有很多问题值得讨论。比如关于数据,今天很多人会假设接下来会有越来越多的数据可以用来训练新一代模型 GPT-5 甚至 6、7 ,围绕未来有哪些数据可以用、这些数据如何获得,以及合成数据能否带来更好的模型等问题有很多讨论。你怎么看待模型的数据挑战?
Gavin Baker : 数据不够用这件事是 LLM 发展过程中的一个 bear case,大概 9 个月之前有很多人都在讨论这件事,但我认为这个问题今天其实已经得到了解决, Claude 3.5 Sonnet 论文中暗示了这一点,Nvidia Nemotron 讲得要更直接,看起来它们已经解决了数据不够用的问题。
Nvidia Nemotron-4 340B:英伟达在今年 6 月发布的最新的开源模型,该系列模型包括三个主要版本:Nemotron-4-340B-Base、Nemotron-4-340B-Instruct 和 Nemotron-4-340B-Reward。它包括基础模型 Base、指令模型 Instruct 和奖励模型 Reward。其中,指令模型的训练是在 98%的合成数据上完成的,而 Nemotron-4-340B-Instruct 也可以被用来帮助开发者生成合成训练数据,并借助 Nemotron-4 340B 奖励模型来筛选出高质量的响应。
与此同时,我也认为,因为各种各样的原因其实还没有人能够真正认识到模型的本质,为什么我们能训练出 GPT-4 这样强大的模型?为什么 scaling law 会有效?等等问题。虽然在 LLM 领域有各种各样的理论,并且因为这些理论我们对模型的理解正在逐步加深,但还是没人完全做到这一点。
比如 Kevin Scott (注:Mircrosoft CTO)最近在一次播客中提到 “我们已经能够看到一些 GPT-5 早期的 checkpoints,scaling law 仍然在持续的发挥作用。” 我觉得从很多层面上来说,scaling law 仍然能够发挥作用对我们来说就是目前最好的迹象。
但另一方面,在和 xAI 做对比时,我觉得 OpenAI 正在面临的是 xAI 的出现以及 Blackwell 的延期发布这两个问题。Blackwell 的延期意味着,如果要通过 Balckwell 架构建立 10 万卡集群,那么 xAI 很大程度上会有一年左右的优势,这件事对于 OpenAI 和其他 AI labs 来说都是很现实的挑战。因为目前大家都在疯狂地努力扩建自己的 10 万卡集群,但他们缺少一个像 Elon 那样的人来设计一个数据中心,或者从第一性原理出发去重新设计数据中心。数据中心结构过去只是锦上添花,但现在变成了一个关系到生死存亡的因素。
我认为合成数据按目前看确实有效果,而这样就会带来另一个问题,也就是究竟什么决定了模型的价值?为什么 Meta 愿意毫无保留的开源自己的模型?也许我们最终会发现所有模型公司都会开源自己的模型,xAI 也开源了 Grok-1,但这些很有可能是因为模型本身并不具备价值。
因为如果我们按照我之前提过的这个方程式推演,也就是假设大家所面临的 scaling law 的限制相同,在每瓦特的 CapEx 相同的情况下,谁能够提供比竞争对手多 100%到 200%的 ExaFLOPS,谁就可能训练出质量远超对手的模型。这种情况下就没有人会愿意开源自己的大模型去丢掉自己的竞争优势。
最终模型之间的竞争来自模型分发和独特的数据。
Google 有 YouTube,以及其它各种各样的数据来源,比如 Google Maps 等等,因为 Google 拥有的数据足够多,所以他们不会那么关注合成数据。
xAI 有 X 的数据,这是其他人不具备的优势,因为 X 持有 xAI 25%的股份。随着时间的推移,我觉得 xAI 将成为一个贯穿 Elon Musk 所有公司的生态系统。我们也可以谈谈 AI 和机器人技术,我觉得这是我们有生之年可能会经历的最大的颠覆,二者的结合可能会出现一种近乎于 Digital God 的超拟合实体。
除非有公司在 MAMF、SFU、checkpoint 的频率以及 PUE 几个因素上建立复合型优势,使他们在每瓦特每 CapEx 上的 ExaFLOPS 跟其他竞争对手拉开显著差距,否则所有的模型最终都有可能收敛到大致相同的智能水平。
以我对 Google 和 Meta 的了解,即使有其他竞争对手的模型智能水平远高于自己,并且开发效率上也更领先,他们仍然会愿意通过烧钱来解决问题。尽管巨额的开发成本最终会影响公司的股价,但同样的情况下,如果竞争对手只花费了三千亿美元,像 Google 或者 Meta 这样的巨头也愿意花费一万亿美元。
我们需要注意的是,如果 AI 的投入需求越来越庞大,那么 Mag7 完全有可能通过取消回购、停止分红,并且发行新股来继续筹集资金投资到 AI 上。从很多维度上来看,AI 的投入会变得很夸张,但最终,也许这些 AI 所具备的“智能”将会趋近于我们称之为“智商”的东西。
谁拥有最独特、最实时的世界数据。独特的数据源,再加上每次通过问答对模型给予的反馈,就使得模型水平能够进一步的提高。所以谁能把独特的数据和互联网规模的数据分发结合起来,谁就能够在竞争中胜出。
而目前仅有少数几家公司拥有这种能力——xAI、Google、微软,OpenAI 在微软的帮助下也可以做到这一点,Amazon 和 Anthropic 估计也有路径可以实现,当然还有 Meta,Apple 则是一个很大的未知数。
说到这里,我们就必须要探讨一个非常关键的问题,就是推理具体是在哪里发生的?
历史上计算一致呈现出一个中心和去中心化的周期趋势,我们当下正处于一个集中的云计算周期的尾声,在这个周期中,计算基本是在云端、大型数据中心来完成的,因为这样效率更高,比如对于模型训练来说,一定是在 CSP 来进行的。我认为人们低估了一件事是,因为我们可以把数据中心建在任何地方,所以不用过度担心 AI 算力需求带来的电力需求的激增,可能最终这些巨型数据中心会被建立在页岩气田中,配设发电厂,我们可以在远离人类活动的能源开发区建设巨型数据中心。
计算从中心化到去中心化的周期性变化本质上取决于在哪里能够以最低的算力成本获得最高的算力效率。这是我们前面提到的那个模型训练效率方程的一个衍生。我确实觉得学会去思考 AI 模型效率方程里面的各种变量变化,这件事对于 AI labs 和投资人来说都非常重要。
即控制 Scaling 这个变量的情况下,在一个单位的资本支出/能耗比上,谁的 ExaFLOPS 更多。
如果能把 SFU 提升 20%,则取决于硅片在毫米级别上的差异。即便只是把硅片加多几毫米甚至更好,就有机会把 SFU 提升 20% 的话,还是很值得投入成本的,因为这种毫米级别的差异就是形成巨大竞争优势的制胜法门。
所以我们可以回看整个 AI 链路,找到每平方米硅片对应的成本效益最高的区域,那里就是真正的优化机会。无论是软件层面的 AI Infra,还是硬件层面的数据中心,还是半导体这一层,都存在这种优化机会。而我个人观点是未来会有更多的推理发生在移动终端。
这显然就是 Apple 的策略,也是他们在目前的竞争格局下处于一个非常有利的地位的原因之一。
其余的几家 Meg 7 公司都陷入了一种囚徒困境。考虑到计算成本如此高昂,如果有机会也许其它几家公司会非常愿意达成一些共识,比如大家也许会一致同意在 2026 年之前都不建立 Blackwell 集群,从而实现一种纳什均衡,但在 LLM 竞赛下这显然不可能实现,因为目前的竞争格局已经是一个白热化的阶段,所以囚徒困境确实存在,但 Apple 显然不在其中。
纳什均衡(Nash Equilibrium):美国数学家John Nash提出的博弈论策略组合,又称“非合作博弈均衡”。在一个两人或两人以上的完全信息静态博弈(即博弈参与方无法互相知晓另一方的决策)中,没有任何一方可以通过自己单方的策略选择而实现收益的增加。典型案例为囚徒困境:假设两个为理性经济人的囚犯因为共同犯罪而被捕且彼此无法交流,警方给出都坦白(关押一段时间)、都不坦白(不关押)、一方坦白一方不坦白(坦白的释放但不坦白的关很久)三种判罚政策,两个理性经济人会同时选择坦白而被关押一段时间,因为这虽然不是最优解,但在无法控制对方选择的情形下,坦白是最有利的解,此时即为一种纳什均衡状态。
04.
为什么 Apple 没有陷入 LLM 囚徒困境?
Apple 的商业化能力与 Google 在搜索这个模式上的商业化能力不分伯仲,因为 Apple 在 iOS 上具备分发模式上的垄断地位,iOS 就像收费站一样。谷歌可以通过 Android 实现的事情,Apple 都可以通过 Apple Intelligence 实现。
所以我们的手机上会运行一个小型模型,用于回答简单的问题,我们可以想象它的模型能力大约接近人类智商 100 这个水平,而这个模型已经可以处理相对复杂的知识。可能会同时存在两个模型,这两个模型之间可以相互检查。然后会有大量的推理在移动终端上实现。
如果推理过程发生在移动终端,那么我认为我们将很有可能看到超级手机的出现,因为对于消费者而言,如果能够像访问内存一样通过移动设备进行 AI 推理,那么消费者会很愿意为此付费,这是一种相当好的用户体验。
现阶段 iPhone 的销售定价主要基于设备内存大小,而未来人们可能更关注设备本身搭载的 DRAM 数量,因为 DRAM 的数量决定了用户可以本地化运行的模型的参数水平,而这又进一步决定了自己拥有的本地模型的智能水平。本地部署的模型可以通过隐私安全的方式访问你的所有数据,而本地模型如果无法处理某些请求,它可以选择通过云端来执行某个任务。
互联领域有一个原则叫作“route when you can, switch when you must”,但到了推理,我觉得这件事可能会变成,“local when you can,cloud when you must”。如果能够本地设备能支持推理,但用户就会倾向于一致这样做,因为本地推理是免费的,云端因为涉及到 GPU 的算力消耗会带来一定费用。所以,虽然云端推理可能要更加高效,但本地推理确是实实在在的没有成本的。
对于用户来说,如果能有一部 3000 美元的 iPhone,它的 DRAM是 1000 美元 iPhone 的四倍,可能还有更多存储空间,这样本地模型就可以进行 RAG。并且这个本地化的模型是我用户自己的专属模型,用户可以自由选择它用哪种声音和自己对话,模型足够了解用户,甚至可以是朋友、助手,在模型能力不断进化的过程中它只会支持和服务特定的用户。
我认为这些本地化的模型可以最终呈现这样的定制化效果——也一定会有一种方法能够在更早期的时候对这些模型即时地根据个人情况进行针对化的训练,尽管要实现这一点还有许多需要突破的难题。这个模型会是一个非常贴近我本人的模型,它了解我,熟悉我的需求。如果未来人们能够在移动终端上拥有一个助手,那么届时那个助手就会是我所描述的这样。
如果一个人拥有一部超级手机,而这个超级手机上搭载的 AI 智能水平差不多相当于人类 115-120 的智商,而另一个人的 AI 助手智能水平只有 100 ,作为人类而言,前者相比后者就拥有更显著的优势。而这种趋势会不断扩张,因为我认为 Apple 最终有办法把这个模式商业化。
Apple 肯定会通过某个移动设备来把这种定制化的功能商业化。当本地模型能力不够解决某些任务时,他们像所有 AI 应用公司一样通过无线网络把数据发送到云端,而用户则基于他们的付费能力和付费意愿访问到一个对应水平的模型。
Apple 还会向 B 端收费,如果其他 AI 应用公司希望获得 Apple AI 分发中获得更高的优先级,那就需要支付更加高昂的费用,所有 AI 应用公司都逃不过这个定律,就好比 Google 过去一直向苹果支付流量成本,以保证 Google 可以成为 iOS 用户的默认搜索引擎。
用户作为普通人而言,能够在本地拥有一个更加智能的模型并且一直使用它,Apple 有办法让这件事变的非常简单。他们可能会给出这样一种方案,也就是用户可以自行选择使用超级云端智能还是普通云端智能。用户可能需要为超级云端智能支付每月 60 美元的费用,也可能更多或者更少,但是不论如何,愿意支付更多费用的一方会比没有支付更多费用的用户获得一个智能水平更高的本地智能。
长此以往,付费能力更强的人会花费更多的费用,比如每个月一千甚至一万美元去获得“超高级智能”也就是更强大的云端智能的服务,而这个时候普通云端智能可能只需要每月 20 美元的费用。作为一个人类,我因为支付了更高的对价,从而获得了更智能的模型,并且因此在与其他人类的竞争当中建立了巨大的优势,这听上去可能有些反乌托邦,但这种趋势确实也是不可避免的。
我们也可以从这里快速总结出一些投资结论:
• 当 MAMF 已经达到 90%时,那可能已经不是一个很好的进场时机;
• 但如果 SFU 目前只提升到 30%,那这就是一个非常好的投资时点;
• PUE 目前的水平是 1.8%,理论上还能够降到 1.3%,所以现在投 PUE 应该也是一个比较好的时机。
对于投资人来说,肯定是更希望投资到今天效率还比较低的地方。
05.
纠结 AI ROI 是无意义的
Patrick O'Shaughnessy :我们前面一直在聊 Mag 7,如果你是早期投资人,主要关注 A、B 轮阶段的公司,考虑到 GPT 的不断进化,你认为今天在 AI 的早期投资中需要关注哪些重要特质?
Gavin Baker: 我觉得首先还是要看大家关注的核心问题在什么地方。像我主要关注的就是什么样的公司能够解决我一直提到的这个方程式里的关键问题。因为我觉得这才是技术瓶颈,也是公司最能获得成功的环节。
在科技领域,每一次投资如果能踩准技术瓶颈的解决办法,都会带来好的投资回报,而我认为目前的投资机会就分布在 SFU、checkpoint 技术(关系到模型的可靠性)和 PUE。所以我目前还是主要把资金分布在这几个领域内。
我觉得应用层的投资真的非常困难。当然也有一些人在应用层的投资上做的非常出色,比如你之前访谈过的 Sarah Guo,我觉得她在应用层的投资上很有一套,但是对我来说,让我现在去投应用层的话那就真的比较困难。我觉得任何非常看好应用层这个赛道的人都必须要记住 Chase Coleman 提到的那个 1%。
所以我觉得对于应用层的投资还是要保持一个相对保守的态度,不过也可能是我对 AI Infra 更有把握一些,因为我更专注在这个方向上。
我们看了很多家应用层的公司,但目前只有一个应用层的公司我比较有兴趣。不过也可能是因为我太在意 Chase Coleman 的那个 1%的统计结果,对于应用层确实也非常谨慎,所以估计也会错过很多应用层的机会。毕竟在互联网早期除了 Yahoo!、Lycos 之外也是有很多好公司的。我对应用层的一些看法主要是从 Benchmark 的合伙人 Eric Vishria 那里听来的,我觉得他有很多不错的认知,我也很认同。
这里又不得不提另一个人们一直争论的问题,就是 AI 的 ROI,回报率是可以通过计算得出的,但很多人混淆了 CapEx 和 OpEx,这是非常不恰当的。
Meta 之前股价下跌了将近 80%,有部分原因是因为公司在 Metaverse 上的过度投入,但另一个原因是因为 Apple IDFA 对广告精准投放的限制。今天 Meta 目前的股价已经又涨了 5 倍并且收入增长也在重新加速,之所以是“重新”加速,是因为他们在 AI 上投入了大量的资金来解决投放精准度的问题。
所以我们完全可以说,单看 Meta 股价上的目前的回报就可以证明所有这些 AI 上的投入和部署是值得的。Meta 目前的这个用 AI 解决投放精准度的系统被称为“Meta Advantage”, 但这只是 Meta AI 投资中的一部分。仅就 Meta 作为广告平台,为广告主进行定位的这个工具而言,同样的,Google 也有类似的“Performance Max”系统。AI 已经能够参与广告创意的优化和分发, 因此也能给像 Google、Meta 这样的公司带来更强的竞争力。
所以既然我们已经看到了AI 呈现出了这么出色的 ROI ,就没有什么好争论的。除了 ROI 之外,其实还有一个指标叫做 ROCI(已投资本的回报),这些公司全部都是上市公司,财务数据都公开可查,我们可以看到这些公司增加 AI 上的资本支出以来,ROIC 全部上升了,所以今天再去聊 ROI 的争议是没有意义的。
如果有人仍旧要去质疑 AI 投入的 ROI 持怀疑态度,那最直接的反问就是,为什么我们反而看到这些大公司的 ROIC 是在上升的?即,CapEx 在增加的同时,净利润增长的反而更多?之所以会出现 ROIC 的提升,是因为这些公司正在做的就是人们希望 AI 可以实现的事情,让 GPU 的计算时长来代替人力的劳动时间。这就是 ROIC 上升的原因,而且 GPU 非常高效。等到这些在 AI 上投资了大量资金的公司的 ROIC 下降了以后,讨论把成本都投入 AI 的回报率才有意义。
回到应用层的问题, Vishria 的一些观点我觉得很好。
我们今天已经有很多指标评估 SaaS 公司业绩表现的指标。比如,第一年,公司需要达到 100 万美元年营收才符合行业认可的增长标准,到了第二年结束,公司需要拥有 500 万的年营收,到第三年底,目标就应该设置在 1000 万美元左右。
如果一个公司能够在维持合理的 burn rate 下实现超过标准的增长,那么公司的业务规模就可以沿着这个趋势继续增长,并逐步成为一家成功的 SaaS 公司。这也是 SaaS 公司的估值倍数变得如此膨胀的原因之一,因为这是一个非常标准的量化标准。当一个公司在第三年就达到 1500 万美元的营收,人们可能立马就觉得它到第 8 年可以实现 10 亿美元的营收。
这件事带来了 2 个结果:首先,SaaS 领域估值倍数不合理地膨胀;其次,整个行业被过度融资,导致每个垂直领域的竞争变得异常激烈,这种情况下原本的增长曲线也不再成立。这也是为什么如果有人进行了大量的 SaaS 投资,特别是在 2021 年,那他现在大概率就会陷入困境的原因。
紧接着,AI 出现了,AI 从根本上改变了应用软件的范式,因为软件的本来作用就是提高人类的效率。AI 目前正在不断提高人们的效率,但对于 AI 来说它不需要做太复杂的 wrapper 就可以让人们认识到这一点。
引用 Benchmark 的 Vishria 的观点来说,最终如果 AI 真的能替代人类,但 SaaS 公司仍然在按人头的逻辑给软件定价,那么当用户数量下滑的时候就会出现问题。
现阶段的这些软件和 SaaS 公司应该都非常清楚这一点,他们原本有着非常明确的发展路径,但现在基本上在每个垂直场景都有很多家 AI-first 的团队在做,原有的 SaaS 公司必须要面对这一轮的 AI 应用公司的竞争,来争夺 IT 预算、甚至接下来是关于人力的预算。
而今天这些新的 AI 应用还仅仅只是一些构建在 GPT 或者其他大模型上的轻量级应用,也就是 LLM wrapper。对我来说,比较有意思的点是观察这些 AI-first 公司中有谁可以把用户一开始的这种觉得 AI 产品很有魔力的用户体验变成竞争壁垒,尤其是考虑到底层模型的迭代速度正在加剧。
Vishria 还提了一个很有意思的观点,他认为今天这些 AI 公司已经完全碾压了传统 SaaS 公司的增长曲线,在关于 AI ROI 的文章中也有过统计,有相当多的公司都能够在 9 个月内实现营收从 0 到 3000 万美元的增长。尽管 AI 的边际成本很高,但相比于软件公司来说,AI 的现金流效率也更高。
这件事可能是如何找到一个好的销售模式的问题。比如,也许可以通过一种非常简便的集成(integration)来实现,同时又围绕这个 integration 形成了自己的竞争优势。再比如,为小型企业创建简单的 RAG 解决方案可能也是一个竞争的思路,但关键是这些基于 LLM 的上层应用究竟要怎么做到差异化?
仅仅进行微调是不行的,尤其是过度的微调,这会导致产品完全依赖于某一代模型。产品的开发者还需要思考如何创造一个复合的 AI 系统使得产品可以用尽可能低的成本处理每一次的用户请求,同时开发者也需要思考如何从小模型开始,最终将它训练成一个大模型。
在 AI 应用的差异化上,有很多可以投入的地方,每个角度都很重要。我觉得到了应用层这个层面,有很多的产品类别都具有想象空间。AI 应用公司的数量正在实现井喷式的增长,业绩表现也都超过传统 SaaS 的评估曲线,所以我目前实际上很难判断这些公司的长期竞争力究竟如何。其中一些公司可能围绕某个维度逐步建立自己的竞争优势,但可能有更多的公司无法创造竞争壁垒。所以这是我觉得投资应用层的时候最困难的地方,也是我对待应用层一直非常审慎的原因。
通用电气的 Jack Welch 曾经提出过的一个概念叫 Scutwork,对于很多白领来说,有一类工作是必须要做好但是又很困难、很折磨人的工作,我觉得这些很轻量级的 LLM 应用其实都可以用来取代很多这类工作。
一开始我们可以把这种应用和人类结合起来,比如 Neal Asher 创造的科幻世界里,有一种叫“haiman”的东西,也就是一种人类-AI 结合体,它是通过类似 Neuralink 神经接口技术的技术将人类与计算机服务器相连,而这个服务器又由一个外骨骼结构支持——一种可以穿戴走动的机器人外骨骼结构。在完全由 AI 取代人类之前,我们未来会进入一个类似融合国际象棋的人类-AI 协作过渡期,智商 100 的人可以表现出智商 120 的水平,然后可能可以达到 130 的水平,然后智商 130 的人会表现的像是智商 160 一样。然后最终,只要 scaling law 一直持续下去,虽然也是个大工程吧,某些领域会只剩下 AI 来工作。
06.
Tesla:机器人浪潮的直接受益者
Patrick:我们接下来可以聊一下和机器人有关的话题。今年 4 月份我和一位投资人在一、二级市场都有投资布局的投资人交流时,他提到,今天市场可能严重低估了未来 5 年内机器人、以及机器人和其他新兴技术结合带来的潜力。我很好奇你怎么看这件事?因为就短期来看,机器人领域似乎存在很多泡沫。比如通用人形机器人领域很多公司获得了很夸张的融资,但我们可能并不清楚它最终能做成什么。
Gavin Baker:我也认同这个观点,并且在我看来,和我们刚才讨论的大规模的白领工作自动化相比,机器人可能会在短期内形成更大规模的颠覆。但真正会对世界产生重大影响的第一个机器人,很可能是接入了 AI 的 Tesla。
基于公开的接管率(miles per disengagement)数据来看,Tesla 的接管率表现很一致,这也意味着,即便我们在火星上也建立了一座城市,那里的交通状况、街道等等和我们日常生活中的完全不同,Tesla 也能在那个环境中表现出和其他城市相同的接管率。但对于 Waymo 来说,接管率数据是很受地理位置限制的,我们目前其实主要是还是在城区、天气比较好的时候使用 Waymo。
如果看另类数据、不同版本 FSD 的接管率就会更明显。当 FSD 升级到 12.3、再到 12.5 的过程中,进度速度相当明显。 我认为 FSD 12.5 就像 GPT-3。
Tesla FSD 的提升也存在一个 scaling law,并且这些跳变式的改进用到的算力只是 Tesla 的奥斯汀超级工厂数据中心的计算的很小一部分。但是如果考虑到 FSD Beta 12.5 在 AI 硬件上的表现,再想想它训练时使用的微小计算量,以及Tesla 在奥斯汀的超级计算机集群的规模,我认为我们会很快从 FSD Beta 12.5 跳到类似 GPT-4 的水平。
Tesla 给自己奥斯汀的数据中心也申请了很多非常创新的专利,比如涉及到他们正在进行的数据中心冷却技术。作为一个投资人,有时我希望他们不要申请这么多专利。
目前可能只有 Tesla 拥有基于行驶里程的视觉训练数据集,我们可以辩论它是比 Waymo 的第二大训练数据集大100倍、1000倍还是10000倍。在我看来,在自动驾驶领域,这就像是特斯拉拥有 YouTube ,而其他人在尝试使用 Yahoo 的数据,显然特斯拉更有优势。
当然,可能未来情况也有变化,所以不能随便下结论。比如可能会出现算法突破,从而减少训练中数据集规模的重要性,在这个过程中,Waymo 肯定也会尝试用大量资金获取数据参与这场竞争,Waymo 的方案是激光雷达。我不认为结果已经注定。未来没有什么是确定的。
Jim Fan 曾经和 Elon Musk 有过一次关于 LLM 如何改进 FSD 的讨论中,Elon Musk 的回复是,现阶段只有合成数据和真实世界的视频数据是可以无限扩展的。
Tesla FSD 最大的竞争风险可能来自于,合成视频数据是否可以像合成文本数据一样被使用?我们都很清楚合成文本数据有用,但不知道合成视频数据是否有效。另外一个显示挑战来自于监管,虽然 AI 能帮我们降低车祸率,但监管对于 AI 导致的交通事故的容错空间要比人为事故小很多。
但 Jim Fan 要更加乐观,他认为 LLM 可以帮助 FSD 进步,因为经过真实世界数据训练的系统能够知道一名优秀的人类司机怎么做,但如果遇到数据集之外的新情况,系统可能就不知道如何应对了,而这就是 LLM 可以发挥作用的地方。
所以如果在每辆 Tesla 上都部署一个本地的小型 LLM,这个模型就有足够的推理能力来解锁 FSD 更近一步的能力提升。当然,Waymo 等其他自动驾驶公司也可以做这件事,但他们没有 Tesla 的视觉系统和所有专有数据集。
我认为在接下来的 12 到 18 个月内,甚至可能 6 个月内,这件事就会成为现实,如果 Tesla 做到这一点也会打消今天对 FSD 的所有质疑。
同样的情况也适用于人形机器人。Google 在 RT-1 这个项目上展现出了这一点。机器人的进步和 LLM 也结合在了一起。这个机器人具有理解事物本质和应对方法的世界模型,这让一切变得容易得多。我们不需要单独训练人形机器人如何拾起网球、篮球和足球,以及它们之间的区别,因为它可以自主推理。这也是为什么我认为将 LLM 和人形机器人结合会给世界带来重要变化的原因,很多蓝领工作可能会变得可有可无。我认为整个社会机制完全没有为即将到来的变革做好准备。
人形机器人一定是未来,而不是那些围绕特定任务开发的机器人,原因很简单,虽然垂直场景机器人可能在特定任务上比人形机器人更出色,但人形机器人可以完成任何人类能做的任务,我们今天生活的世界是围绕人类行为所优化的,而且人形机器人在制造方面存在巨大的规模效率。
人形机器人之于机器人领域,就像 GPT 之于 AI,GPT 是一种通用型 AI,而人形机器人将成为通用型机器人。正因为如此,它们将被大规模制造,从而获得成本优势,然后物理世界将开始为它们进行优化。非人形机器人创业公司可能会像 MySpace、Lycos 或者 CMG,但它们中没有一个会成为 Google。
就像 GPT 让 Meta、Google、Microsoft 这些已有的公司受益一样,人形机器人领域也会有类似情况,因为这些大公司有数据、算力和足够的资金。我认为电池设计、制动器、电机环节、拥有大规模数据集的制造商会在人形机器人的竞争中更有优势。所以我很看好 Tesla 的 AI 机器人 Optimus。
通用机器人市场很大,也会有很多家公司一起竞争,但我觉得可能这里最后会只有 2-3 家,Tesla,Waymo 以及某个基于开源发展起来的团队。
文章来源“海外独角兽”,作者“Siqi”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
