# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
什么?大模型也许很快就能生成《黑神话·悟空》这种3A大作了?!
直接看一则demo,《西游记》这就上桌:

搭配BGM,是不是有内味儿了(doge)。
这就是腾讯近日推出的GameGen-O,一个专门生成开放世界视频游戏的Transformer模型。
简单说,这个模型能够模拟各种游戏引擎功能,生成游戏角色、动态环境、复杂动作等等。

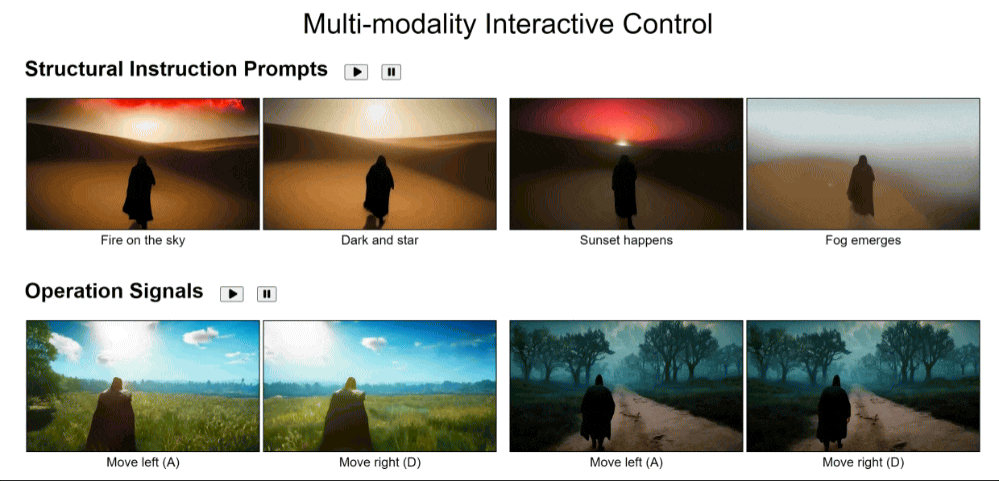
当然也支持交互控制,用户可以通过文本、操作信号和视频提示来控制游戏内容。
消息一公布就在????(前推特)开启了刷屏模式,网友们开始列队尖叫:
游戏工作室Azra Games的联创兼CTO更是直言:
GameGen-O将成为游戏工作室的ChatGPT时刻。
具体来说,这个项目由腾讯光子工作室(曾打造出和平精英)联合港科大、中国科大推出。

推测想要做的事儿,是用AI模型替代一些游戏开发环节。比如目前公布的游戏角色创建、游戏环境生成、动作生成、事件生成以及各种交互控制。
下面我们挨个预览一波~
现在,用GameGen-O就能直接生成各种角色了,西部牛仔、太空人、魔法师、警卫……一键生成。
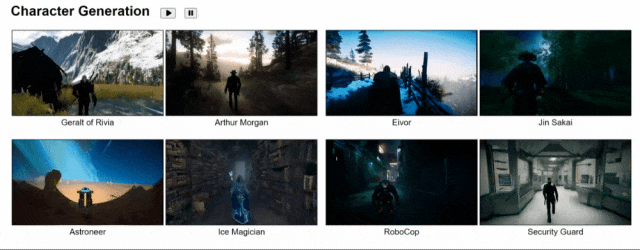
经费不足造成真实取景困难,也有plan B了!

给队友展示骚操作,各种人称视角的动作生成也能轻松拿捏。

游戏必备环节——给玩家偶尔上亿点难度,海啸、龙卷风、火灾事件这就安排(doge)。

与此同时,GameGen-O也支持开放域生成,即不限风格、环境、场景那种。
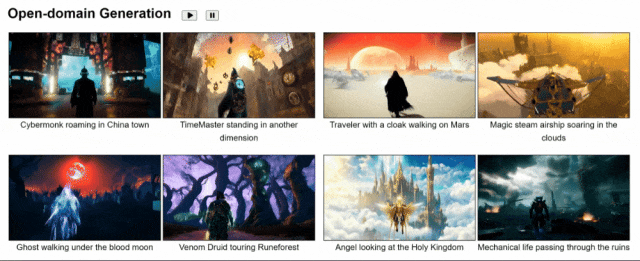
最后,用文本、操作信号和视频提示就能实现交互,向左、向右、走向黎明……
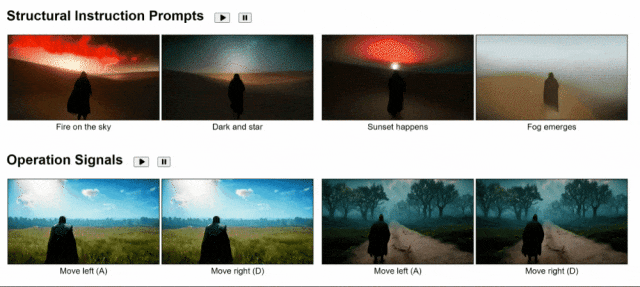
好家伙,谁都知道游戏开发有多烧钱,这下,普通玩家也能用GameGen-O制作游戏了。
一位AI架构师网友更是断言:
为了开发这个模型,团队自述主要进行了两项工作:
具体来说,团队首先提出了一个数据集构建管道。
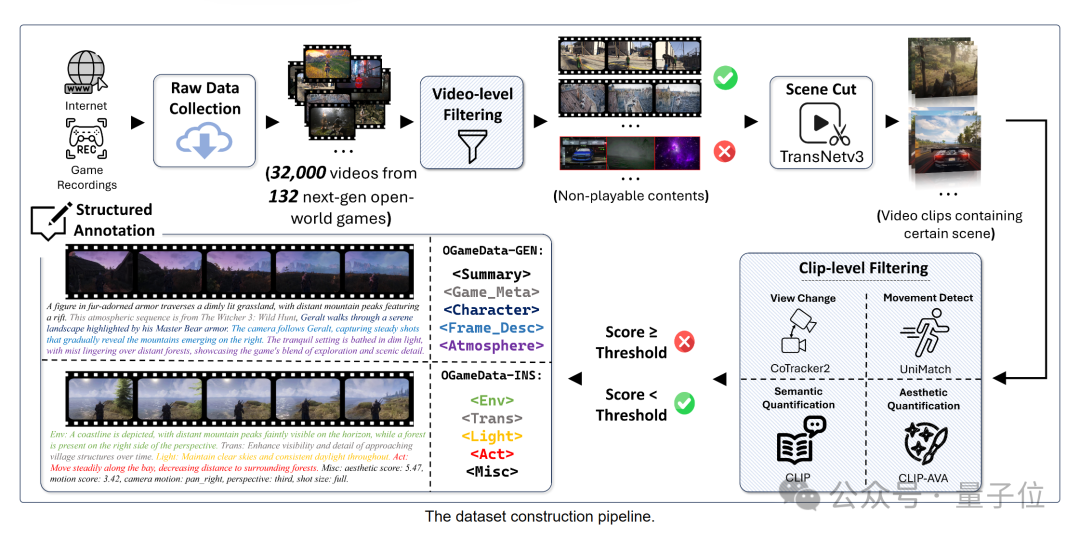
团队从互联网上收集了32,000个原始视频,这些视频来自数百款开放世界游戏,时长从几分钟到几小时不等,类型包括角色扮演、第一人称射击、赛车、动作益智游戏等。
然后由人类专家对这些视频进行识别和筛选,最终得到大约15,000个可用视频。
下一步,将筛选后的视频通过场景检测技术切割成片段,并对这些视频片段进行基于美学、光流和语义内容的严格排序和过滤。
接下来使用GPT-4o对超过4,000小时的高质量视频片段进行细致的注释,这些片段的分辨率从720p到4k不等。
为了实现交互控制性,团队从注释后的数据集中选择最高质量的片段,并进行解耦标签(decoupled labeling)。
这种标签设计用于描述片段内容状态的变化,确保训练模型的数据集更加精细和互动。
对于这种人类专家和GPT-4o一起工作的形式,有网友认为:
这是递归自我改进(recursive self-improvement)的一种形式。(人类专家确保了注释的准确性,并通过反馈机制帮助GPT-4o进行自我改进)

完成数据准备工作后,团队经过基础预训练+指令调整两个过程来训练GameGen-O。
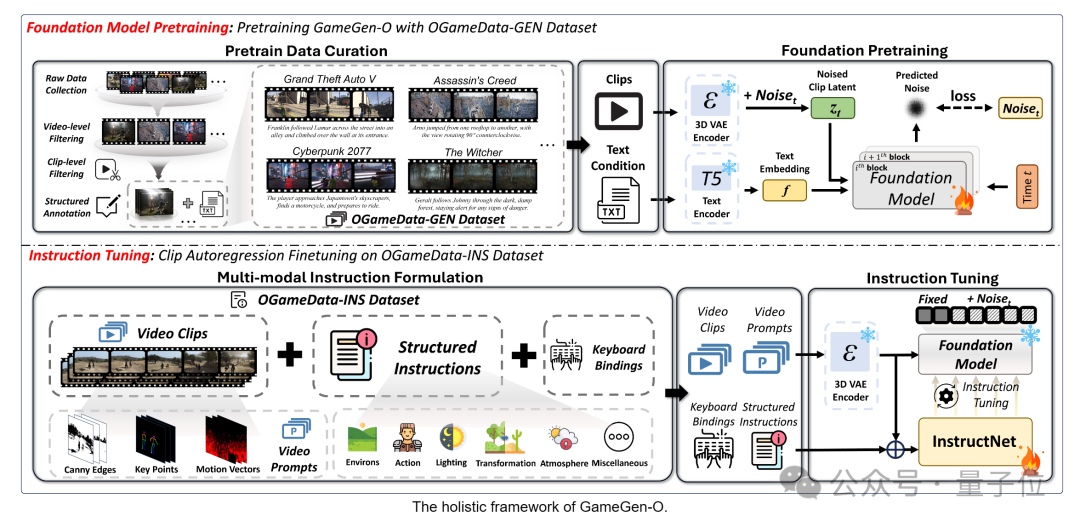
在基础训练阶段,GameGen-O模型使用了一个2+1D VAE(变分自编码器,如Magvit-v2)来压缩视频片段。
为了使VAE适应游戏领域,团队对VAE解码器进行了特定领域的调整。
团队采用了不同帧速率和分辨率的混合训练策略,以增强跨帧率和跨分辨率的泛化能力。
另外,模型的整体架构遵循了Latte和OpenSora V1.2框架的原则。
通过使用掩码注意力机制,让GameGen-O具备了文本到视频生成和视频续集的双重能力。
团队介绍称:
这种训练方法,结合OGameData数据集,使得模型能够稳定且高质量地生成开放领域的视频游戏内容,并为后续的交互控制能力奠定了基础。
在这之后,预训练的模型被固定,然后使用可训练的InstructNet进行微调,这使得模型能够根据多模态结构指令生成后续帧。
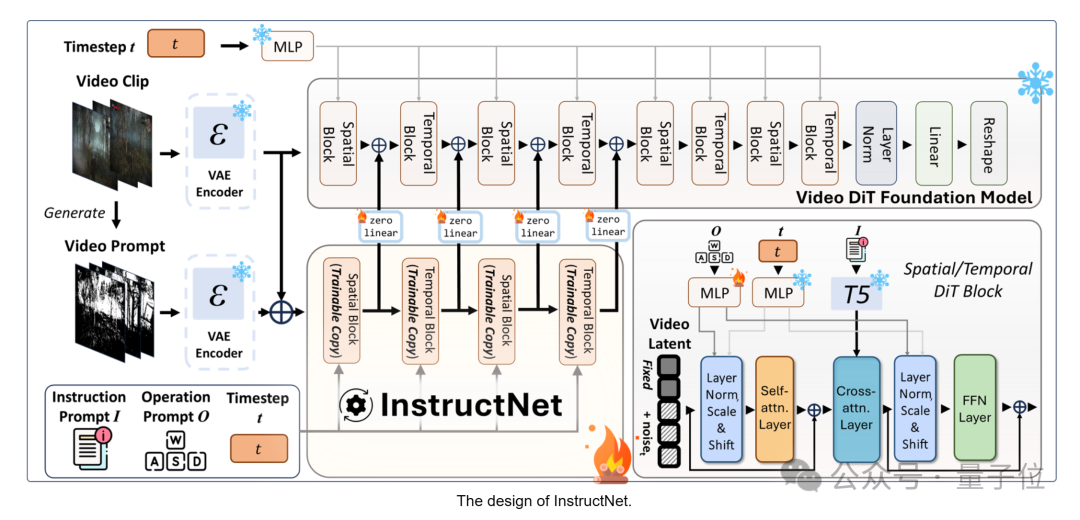
InstructNet主要用于接受各种多模态输入,包括结构化文本、操作信号和视频提示。
在InstructNet分支的调整过程中,当前内容被用作条件,从而在当前片段内容和未来片段内容之间建立了映射关系,这在多模态控制信号下进行。
造成的结果是,在推理时,GameGen-O允许用户基于当前片段不断生成和控制下一个生成的片段。
目前,GameGen-O已创建GitHub官方仓库,只不过还没来得及上传代码。
感兴趣的童鞋可以先收藏一波了~
项目主页:
https://gamegen-o.github.io/
GitHub官方仓库:
https://github.com/GameGen-O/GameGen-O/
参考链接:
[1]https://x.com/_akhaliq/status/1834590455226339492
[2]https://x.com/8teapi/status/1834615421728948581?s=46
文章来自于微信公众号“量子位”,作者“一水”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
