# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这个思考其实源于周五参加WAIC上组织的AI编译相关的闭门讨论的内容,观点有不少来源于现场讨论的朋友们,因为对这个主题感兴趣,我又结合自己的理解做了一些梳理。
对这次闭门讨论感兴趣的话,可以参考岚松和孝强两位的分享,蛮有趣的insights。以及这里的一个内容汇总。
之所以关注AI框架算子层级的问题,是因为自己最近在关注AI硬件行业,也就在关注为一款新硬件提供软件支持可能面临的问题。
1.AI硬件公司,能成事非常不容易。首先是硬件要流片成功,然后是软件栈建设过得去,再之后还需要商业策略不掉链子(包括市场定位、切入策略、客户解决方案团队建设、量产方案等等)。这非常不像典型的互联网创业团队的玩法,小快灵就可以move起来,fail fast。硬件行业,有其很强的物理规律不能简单靠加人加班就超越,哪怕是天才型选手的加入,也只能确保这个过程犯错尽可能少,并不能确保大幅缩短执行周期。
2.我的背景偏软件,至少希望确保软件这一环不会掉链子。所以围绕一款AI新硬件上面,软件栈的建设,就会有更多的思考。首先来看看一款AI硬件的软件栈应该长什么样子,下图是我的一个理解。在这套技术栈里面。有几个细节可以稍微展开一点:
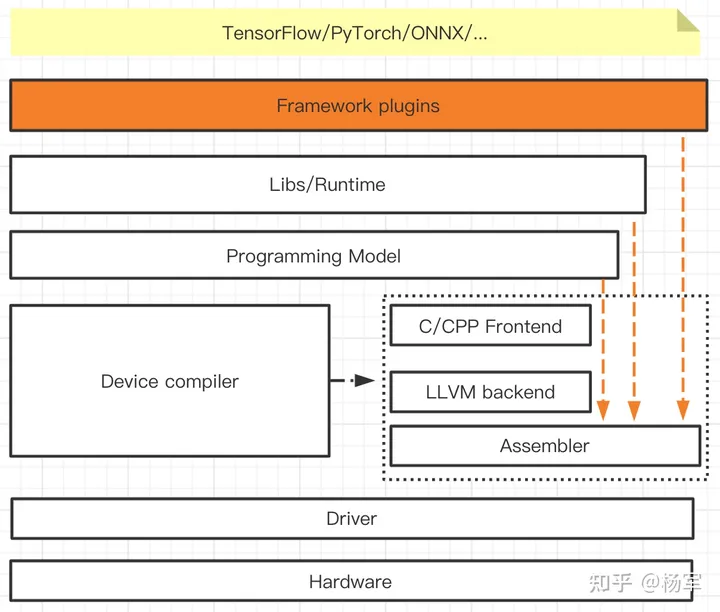
1). 新硬件的device compiler和programming model的建设往往需要时间(新硬件上软件系统的建设本质上是一个bottom-up的工作,所以抽象层次越高的工作其实现复杂度往往更大,交付时间会靠后),但上层AI应用的验证需求又是客观存在的,所以就会存在一个从Framework plugins/Libs甚至Programming Model直接打到assembler这一层的short-cut路径。因为assembler通常做的是一个字面汇编描述到二进制码的翻译,外加一些可轻可重的优化,更容易迭代式交付给上层使用。当然了,如果有可能的话,把device compiler和programming model也拆解成可以阶段式交付的milestone,尽可能让上层开发可以提前借助于高级语言来解放生产力会更有帮助(一个非常小的例子,在汇编码里做pass by value/pass by reference的区分,和在cpp里,前者还是需要消耗一些额外的心智负担,也会影响一些开发调试的效率),这属于实际操作中的考虑了。
2). 这里对接AI框架的层级我定义为"Framework plugins",背后的思考是我在分析一些硬件公司的existing方案的时候,能够看到几乎所有新硬件厂商都有一个倾向,就是assume AI框架能够导出一个完整的静态图(包括训练和推理),用作自己软件栈的输入,来完成训练和推理能力的支持。这种作法存在的原因其实比较容易理解,新硬件为了获得相较于NV更好的性能表现,通常会添加DSA的支持,而DSA会加剧计算能力和访存以及计算kernel dispatch到加速器的gap,所以如果能全图都offload到硬件加速器上,从充分发挥新硬件性能是最理想的了。不过在eager mode广为用户接受的情况下,目前主流的AI框架想做到所有模型都导出一个干净的静态图我觉得并不容易,所以我其实prefer的是新硬件把对接AI框架的模块做成一个插件,可以集成进不同框架的后端,一方面可以更native地配合AI框架的eager mode,在python host端和加速器端做灵活的交互,另一方面,当用户在eager mode下完成交互开发,想追求更高性能的时候,可以再通过一些扩展的API来将模型可静态导出的部分尽可能导出成一张或几张静态图(相关的工作比较早也有人进行过尝试,比如MxNet Gluon),交给加速器来执行,至于一些不易导出静态图的部分,仍然通过python与加速器交互的方式进行fallback执行。这样可以在性能和通用性上获得更好的trade-off。当然,这里有一个细节,如果引入了过多的python侧与加速器的交互,很可能会把加速器的速度明显拖慢,甚至相比NV不再有优势。所以eventually,从加速器角度,会期望不断扩大用户模型能够offload到加速器上的比例(以及通过类似cuda-Graph或pipeline执行的方式来隐藏这种开销),但通过这种plugins的方式至少保证对接建模需求的可用性,不会因为用户模型一调整,就跑挂了,因为模型训练环节,对于交互式开发调试效率是非常看重的。
3. 在Framework plugins这个层面,想在对接主流AI框架时做到既保证在经典代表性模型上的极致性能(比如MLPerf里的模型),同时兼顾对算法用户灵活开发的模型变种的适配程度,就需要考虑AI框架算子coverage的问题了。因为算法用户通常是使用AI框架提供的算子来完成模型搭建(以及少量的自定义算子)。TensorFlow现在有多少个算子呢,在最新的maser code base里已经接近2000个了。PyTorch也在相近的数量规模。这里更麻烦的是算子的数量会随着建模需求的演化还在不断地扩散增加。再加上AI框架版本的快速演化,这就让新硬件对接适配的时候可能出现疲于奔命的现象(这里不讨论业务场景里AI框架版本碎片化的问题,那也是一个考虑Framework plugins方案的原因)。
4. 我们在对接AI框架的时候,一定需要对接到算子层级么?我觉得未必。原理上,存在两条对接AI框架的路径。一条是直接对接到AI框架算子粒度,另一条是对接到AI框架算子粒度之下一个更细的原子IR粒度(比如HLO/Relay/ONNX/TorchScript,其中HLO只有200条左右指令)。从硬件厂商角度来说,最希望的还是能够有一套具备“封闭且可完备描述模型行为的”原子IR粒度可供对接。从用户使用角度,则更习惯于在算子层级这个粗粒度来进行模型描述,而不是使用原子IR描述模型。通过原子IR来装配组装出上层的AI框架算子,来bridge上层用户易用性和下层硬件backend对接性能/工作量的平衡。类似下图所示。
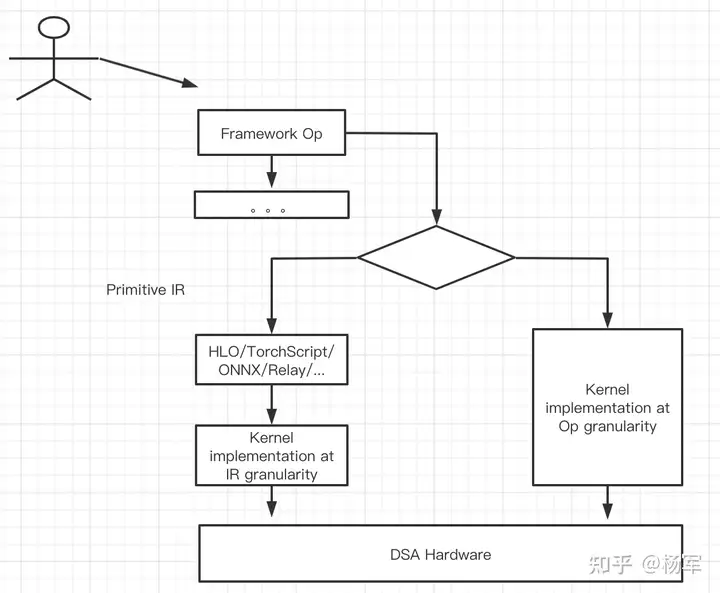
理想很美好,现实很骨感。虽然从硬件厂商角度来说,能够通过直接对接一套Primitive IR就支持不同AI框架是符合硬件厂商需要的,但对于AI框架来说却未必。TensorFlow算是一个对硬件厂商比较友好的框架,因为Google基于TPU做软硬全栈设计,所以XLA以及XLA所基于的HLO IR是比较适合硬件厂商进行对接的。至少,原则上,硬件厂商对接XLA/HLO可以获得跟Google自身将TPU对接到TensorFlow非常接近的便利性。而TPU的roadmap从一开始同时考虑训练和推理也使得XLA/HLO这套技术体系的完备性是符合新硬件的扩展性需要的。包括Graphcore以及一些其他硬件厂商选择基于XLA对接TF就有这方面的考虑。
然而,随着PyTorch的adoption ratio日渐增加,故事变得有些不一样了。我的认识,FB在推出PyTorch的时候,并没有考虑过软硬全栈设计。Hindsight式的来看,这一方面解放了FB的约束,不像Google在TF 1.X极度倾向于静态图(回头来看,被吐槽很厉害的Static graph设计也许当时会有考虑TPU软硬全栈设计的trade-off考虑?),而是可以更多从用户易用性出发,以eager mode为主来设计PyTorch的整体API体系以及执行流程;另一方面,这也为PyTorch对接DSA架构潜在的挑战埋下了伏笔。参见下图里的红框部分,eager mode下,很容易出现python操作和加速器操作交替的逻辑(一个小例子,可以在商汤开源的MMDetection的git repo里看到类似的code),这种逻辑一方面为模型开发的可调试性带来便利,另一方面也对DSA架构不够友好(DSA在获得单位晶体管更强AI算力的同时,也对于host-加速器交互带来的kernel launch开销和访存同步开销更为敏感。实际上,哪怕是在NV GPU架构上,随着V100引入TensorCore开始,这个问题也变得更加明显了,到了A100时代,简单是不可忽略了)
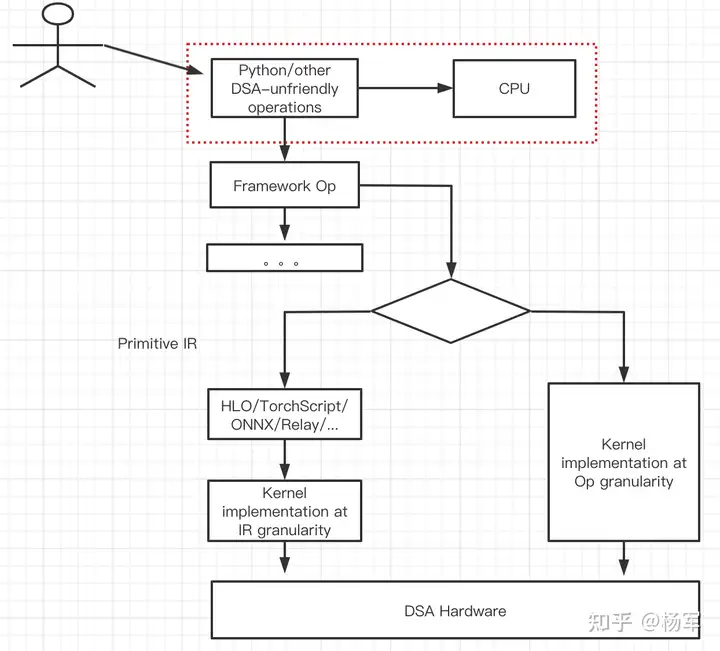
于是,就存在了现实的一些局限:
1). Primitive IR定义上,存在HLO(注:这里的HLO更多是指HLO表示层,可以与XLA独立开,比如MLIR里的HLO Dialect),ONNX,TorchScript, Relay几种候选。目前来看HLO对训练和推理同时支持,并且在生产环境里经受过检验。ONNX、TorchScript、Relay对推理的支持尚可,对训练的支持还需要打磨和完善。
2).即便假设HLO这层IR能够被大家接受,但eager mode带来的python侧和加速器侧交互对性能的影响,也会相当大程度上影响到新硬件的效力发挥。所以在IR定义存在可能共识的前提之外,还需要一套有效的机制能够将eager mode的建模代码高效映射到加速器上执行。在WAIC林达华老师材料里提到的非规则计算和动态计算过程都算是相关的例子了。
在上述两个局限都被克服的情况下,在AI框架算子层面之下,找到一个更有利于桥接上层用户和底层硬件backend的途径才存在可行性。这也许是后续硬件厂商可以一起努力推进的方向。
5.MLPerf目前仍然focus在模型全网层级的benchmark。未来是否有可能在更原子层面,提供出具备代表性刻划能力的IR描述片段?这些IR定义及描述片段能够完整的描述任何一种AI模型(可以认为是AI建模层面的一种“图灵完备”),由硬件厂商在这些描述片段上验证其性能表现,再配合上模型全网层级的benchmark来展现新硬件的性能及通用性。这样的一个潜在好处是,除了刷榜的benchmark以外,可以提升硬件厂商benchmark结果在真实业务场景的可用性。因为真实场景里使用的模型往往和MLPerf的标准模型还是存在差异的(推理稍好一些,训练的话,实际上在真实场景是很少去重跑MLPerf的training benchmark的,因为一但有了这些经典模型的pre-trained model,需要做的要么是在新的数据集上finetune,这对性能可能就不那么敏感,要么是修改模型结构做新的建模尝试,这就可能未必可以把MLPerf的性能结果直接transfer过来了)。
另,在整理这篇文章的时候,自己也梳理了一些之前思考的内容,有些认识随着自己所处position的变化,以及最近吸收到的信息增加,也有所调整:
1.对华为当初选择自研框架的动机,现在多了一些理解。MindSpore这个项目的起源一直有不同的说法,这里不再搬各种江湖传闻了。但有一点我现在会更加认同,那就是想推广软硬全栈生态时,如果对上层框架没有掌控力,很容易会因为上层框架的定义导致底层硬件的能力被制约。这篇文章里提到的一些问题就和这个有关。另外商汤的同学曾经提到过内部自研的Parrot框架可以兼容PyTorch,我对这个工作的细节也比较好奇,我想大概率是因为商汤还是focus在内部的垂直CV类业务,并且商汤的建模能力已经是国际水准,在引领这个领域的建模趋势。在一个封闭建模场景下,并且可以引领上层建模趋势的情况下,做到兼容PyTorch API我想是存在很大技术可行性的。而对于一家硬件厂商,或是一个面向通用场景的云厂商,就是另一个story了。
2.ONNX这个中间IR表示,自己有相当长一段时间是持看低的认识的,因为PyTorch团队明显在减少投入在上面的精力,TensorFlow团队在ONNX上也没有投入多少精力。随着了解更多硬件行业的细节,对ONNX的意义和价值自己又有了一些新的理解。在我看来只要还存在至少超过两家AI框架,ONNX这种中间IR对于硬件公司就有着非常重要的价值。存在且合理,大量的硬件公司会选择对接ONNX,甚至优先对接ONNX,其实是有其权衡考量的。当然,目前对于AI软硬生态来说,还缺乏一个真正的被认可的标准,ONNX虽然有一定认可度,但目前其对于训练场景的描述能力不足,以及ONNX标准已经呈现出碎片化分裂的一些趋势,使得硬件厂家在对接AI框架的时候,还是不得不做一些重复的、碎片化的工作。如果未来能够形成一套bridge AI硬件和软件生态之间的事实标准,对整个行业的发展也会是善莫大焉。
文章来自于知乎,作者“杨军”



